Usuwanie fragmentacji indeksów i zapobieganie jej od dawna jest częścią normalnych operacji konserwacji bazy danych, nie tylko w SQL Server, ale na wielu platformach. Fragmentacja indeksu wpływa na wydajność z wielu powodów, a większość ludzi mówi o skutkach losowych małych bloków we/wy, które mogą fizycznie wystąpić w pamięci dyskowej, jako coś, czego należy unikać. Ogólna obawa dotycząca fragmentacji indeksu polega na tym, że wpływa ona na wydajność skanowania poprzez ograniczenie rozmiaru operacji we/wy odczytu z wyprzedzeniem. Opiera się na tym ograniczonym zrozumieniu problemów, jakie powoduje fragmentacja indeksu, że niektórzy ludzie zaczęli rozpowszechniać pogląd, że fragmentacja indeksu nie ma znaczenia w przypadku urządzeń pamięci masowej SSD (SSD) i że można po prostu ignorować fragmentację indeksu w przyszłości.
Tak jednak nie jest z wielu powodów. W tym artykule wyjaśnimy i zademonstrujemy jeden z tych powodów:fragmentacja indeksu może niekorzystnie wpłynąć na wybór planu wykonania zapytań. Dzieje się tak, ponieważ fragmentacja indeksu zazwyczaj prowadzi do tego, że indeks ma więcej stron (te dodatkowe strony pochodzą z podziału stron operacji, jak opisano w tym poście na tej stronie), a zatem użycie tego indeksu jest uważane za wyższy koszt przez optymalizator zapytań SQL Server.
Spójrzmy na przykład.
Pierwszą rzeczą, którą musimy zrobić, jest zbudowanie odpowiedniej testowej bazy danych i zestawu danych do wykorzystania do zbadania, jak fragmentacja indeksu może wpłynąć na wybór planu zapytań w SQL Server. Poniższy skrypt utworzy bazę danych z dwiema tabelami z identycznymi danymi, jedną mocno i minimalnie pofragmentowaną.
USE master;
GO
DROP DATABASE FragmentationTest;
GO
CREATE DATABASE FragmentationTest;
GO
USE FragmentationTest;
GO
CREATE TABLE GuidHighFragmentation
(
UniqueID UNIQUEIDENTIFIER DEFAULT NEWID() PRIMARY KEY,
FirstName nvarchar(50) NOT NULL,
LastName nvarchar(50) NOT NULL
);
GO
CREATE NONCLUSTERED INDEX IX_GuidHighFragmentation_LastName
ON GuidHighFragmentation(LastName);
GO
CREATE TABLE GuidLowFragmentation
(
UniqueID UNIQUEIDENTIFIER DEFAULT NEWSEQUENTIALID() PRIMARY KEY,
FirstName nvarchar(50) NOT NULL,
LastName nvarchar(50) NOT NULL
);
GO
CREATE NONCLUSTERED INDEX IX_GuidLowFragmentation_LastName
ON GuidLowFragmentation(LastName);
GO
INSERT INTO GuidHighFragmentation (FirstName, LastName)
SELECT TOP 100000 a.name, b.name
FROM master.dbo.spt_values AS a
CROSS JOIN master.dbo.spt_values AS b
WHERE a.name IS NOT NULL
AND b.name IS NOT NULL
ORDER BY NEWID();
GO 70
INSERT INTO GuidLowFragmentation (UniqueID, FirstName, LastName)
SELECT UniqueID, FirstName, LastName
FROM GuidHighFragmentation;
GO
ALTER INDEX ALL ON GuidLowFragmentation REBUILD;
GO Po przebudowie indeksu możemy spojrzeć na poziomy fragmentacji za pomocą następującego zapytania:
SELECT
OBJECT_NAME(ps.object_id) AS table_name,
i.name AS index_name,
ps.index_id,
ps.index_depth,
avg_fragmentation_in_percent,
fragment_count,
page_count,
avg_page_space_used_in_percent,
record_count
FROM sys.dm_db_index_physical_stats(
DB_ID(),
NULL,
NULL,
NULL,
'DETAILED') AS ps
JOIN sys.indexes AS i
ON ps.object_id = i.object_id
AND ps.index_id = i.index_id
WHERE index_level = 0;
GO Wyniki:

Tutaj widzimy, że nasza GuidHighFragmentation tabela jest w 99% podzielona i zajmuje o 31% więcej miejsca na stronie niż GuidLowFragmentation tabeli w bazie danych, mimo że mają te same 7 000 000 wierszy danych. Jeśli wykonamy podstawowe zapytanie agregujące względem każdej z tabel i porównamy plany wykonania w domyślnej instalacji (z domyślnymi opcjami konfiguracji i wartościami) SQL Server za pomocą SentryOne Plan Explorer:
-- Aggregate the data from both tables SELECT LastName, COUNT(*) FROM GuidLowFragmentation GROUP BY LastName; GO SELECT LastName, COUNT(*) FROM GuidHighFragmentation GROUP BY LastName; GO


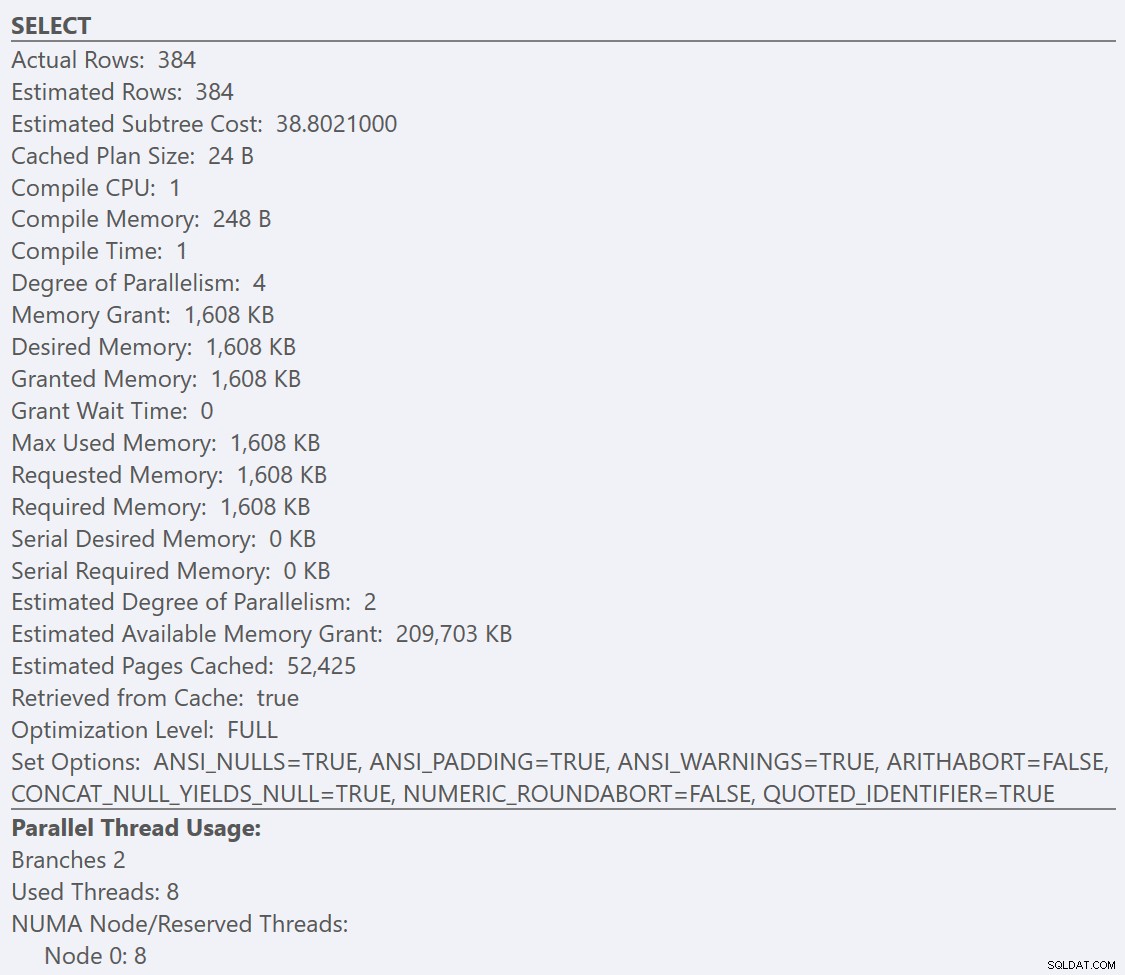

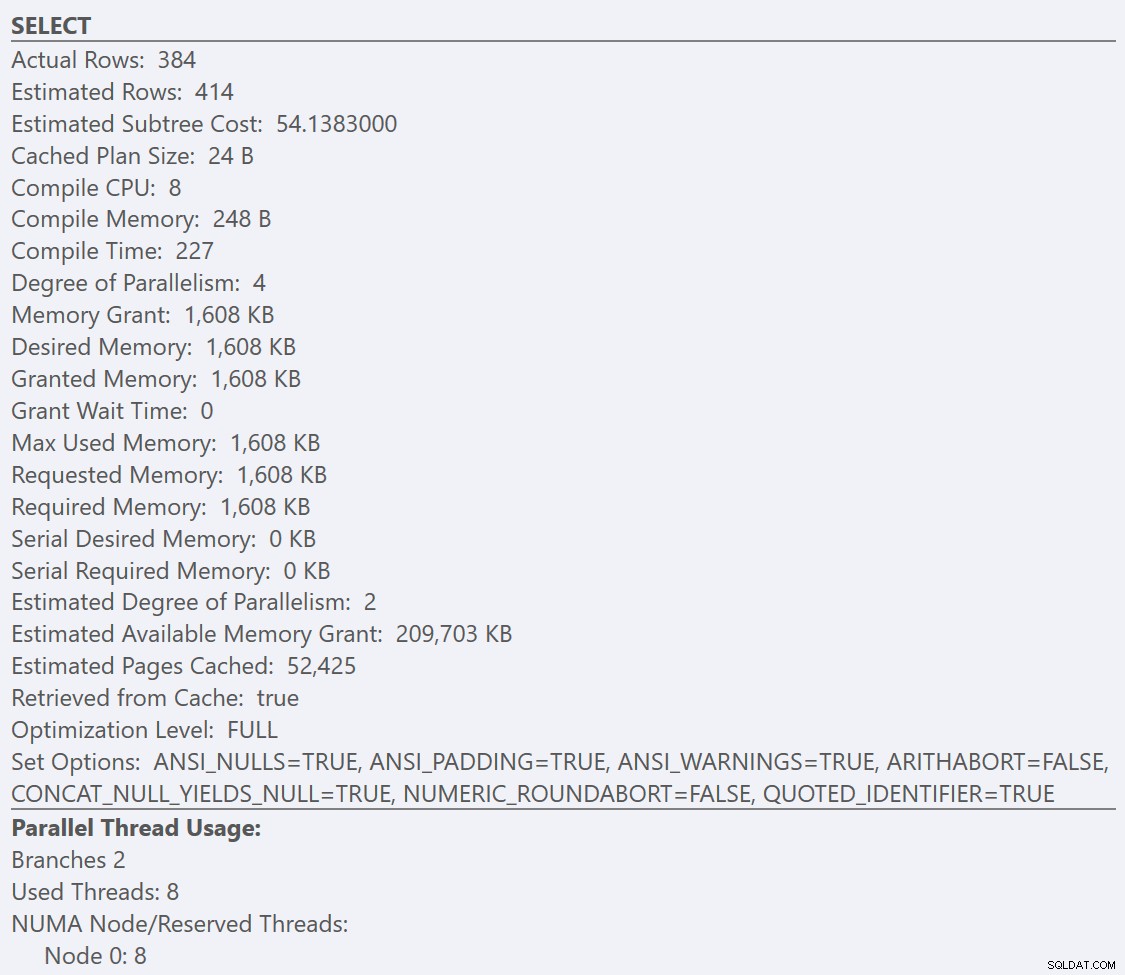
Jeśli spojrzymy na podpowiedzi z SELECT operatora dla każdego planu, plan dla GuidLowFragmentation Tabela ma koszt zapytania 38,80 (trzeci wiersz od góry podpowiedzi) w porównaniu z kosztem zapytania 54,14 dla planu dla planu GuidHighFragmentation.
W domyślnej konfiguracji programu SQL Server oba te zapytania generują plan wykonania równoległego, ponieważ szacowany koszt zapytania jest wyższy niż wartość domyślna opcji sp_configure „koszt dla równoległości” wynosząca 5. Jest to spowodowane tym, że optymalizator zapytań najpierw generuje szereg plan (który może być wykonany tylko przez jeden wątek) podczas kompilowania planu zapytania. Jeśli szacowany koszt tego planu szeregowego przekracza skonfigurowaną wartość „próg kosztów dla równoległości”, wówczas zamiast tego generowany jest plan równoległy i buforowany.
Co jednak, jeśli opcja sp_configure „próg kosztu dla równoległości” nie jest ustawiona na domyślną wartość 5 i jest ustawiona wyżej? Dobrą praktyką (i poprawną) jest zwiększenie tej opcji z niskiego domyślnego 5 do dowolnego miejsca z 25 do 50 (lub nawet znacznie więcej), aby zapobiec narażaniu małych zapytań na dodatkowe obciążenie wynikające z równoległego działania.
EXEC sys.sp_configure N'show advanced options', N'1'; RECONFIGURE; GO EXEC sys.sp_configure N'cost threshold for parallelism', N'50'; RECONFIGURE; GO EXEC sys.sp_configure N'show advanced options', N'0'; RECONFIGURE; GO
Po zastosowaniu się do wytycznych dotyczących najlepszych praktyk i zwiększeniu „próg kosztów równoległości” do 50, ponowne uruchomienie zapytań skutkuje tym samym planem wykonania dla GuidHighFragmentation tabeli, ale GuidLowFragmentation koszt seryjny zapytania, 44,68, jest teraz poniżej wartości „próg kosztu dla równoległości” (pamiętaj, że jego szacowany koszt równoległy wynosił 38,80), więc otrzymujemy plan wykonania szeregowego:
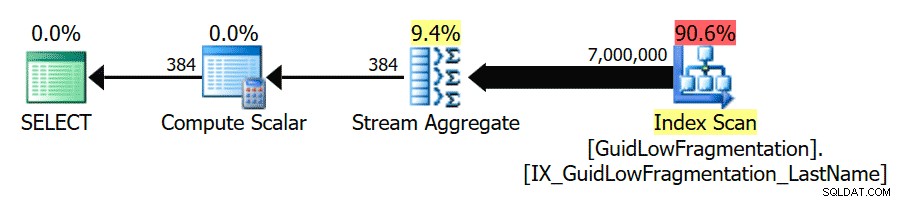
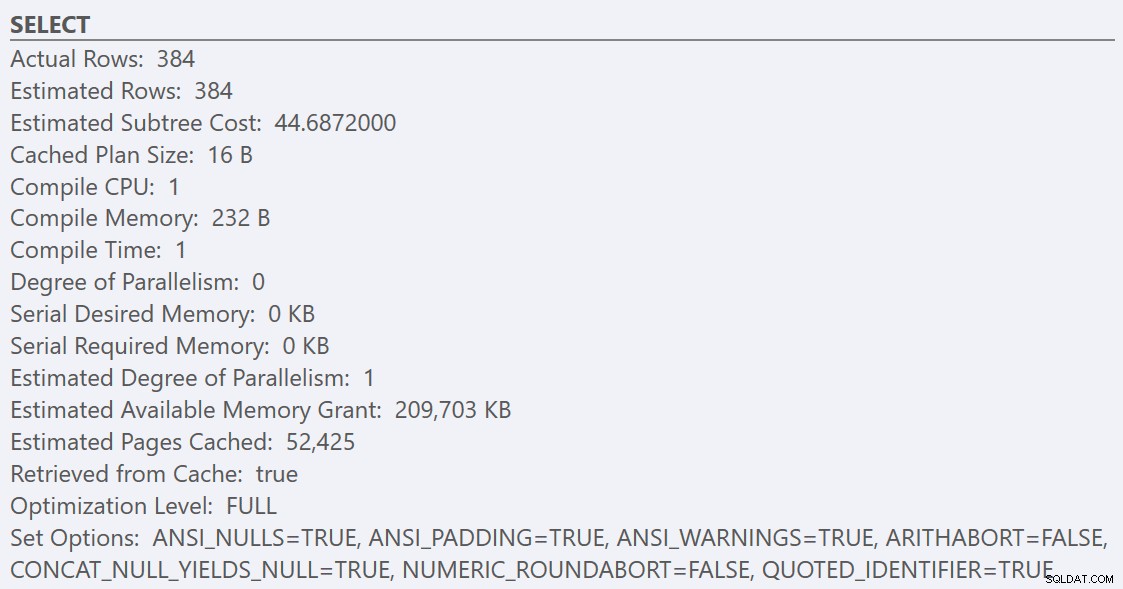
Dodatkowa przestrzeń strony w GuidHighFragmentation indeks klastrowy utrzymywał koszt powyżej ustawienia najlepszych praktyk dla „próg kosztów dla równoległości” i skutkował równoległym planem.
Teraz wyobraź sobie, że był to system, w którym postępowałeś zgodnie z najlepszymi praktykami i początkowo skonfigurowałeś „próg kosztowy dla równoległości” na wartość 50. Później zastosowałeś się do błędnej rady, by po prostu całkowicie zignorować fragmentację indeksu.
Zamiast być podstawowym zapytaniem, jest bardziej złożone, ale jeśli jest również wykonywane bardzo często w twoim systemie, a w wyniku fragmentacji indeksu liczba stron przerzuca koszt na plan równoległy, będzie zużywał więcej procesora i w rezultacie wpływają na ogólną wydajność obciążenia.
Co robisz? Czy zwiększasz „próg kosztów dla równoległości”, aby zapytanie utrzymało plan wykonania szeregowego? Czy podpowiadasz zapytanie za pomocą OPTION(MAXDOP 1) i po prostu wymuszasz wykonanie planu seryjnego?
Pamiętaj, że fragmentacja indeksu prawdopodobnie nie wpływa tylko na jedną tabelę w Twojej bazie danych, teraz, gdy całkowicie ją ignorujesz; jest prawdopodobne, że wiele indeksów klastrowanych i nieklastrowanych jest pofragmentowanych i ma większą niż to konieczne liczbę stron, więc koszty wielu operacji we/wy rosną w wyniku powszechnej fragmentacji indeksów, co prowadzi do potencjalnie wielu nieefektywnych zapytań plany.
Podsumowanie
Nie możesz po prostu całkowicie zignorować fragmentacji indeksu, jak niektórzy mogą chcieć, abyś uwierzył. Wśród innych wad tego działania, skumulowane koszty wykonania zapytania dogonią cię, wraz ze zmianami planu zapytań, ponieważ optymalizator zapytań jest optymalizatorem opartym na kosztach, a więc słusznie uważa, że te pofragmentowane indeksy są droższe w użyciu.
Zapytania i scenariusze tutaj są oczywiście wymyślone, ale widzieliśmy zmiany planu wykonania spowodowane fragmentacją w prawdziwym życiu w systemach klienckich.
Musisz upewnić się, że zajmujesz się fragmentacją indeksów dla tych indeksów, w których fragmentacja powoduje problemy z wydajnością obciążenia, bez względu na używany sprzęt.