Zaangażowanie w dostrajanie wydajności może zająć wiele tur, gdy nad nim pracujesz – wszystko zależy od tego, co pojawia się jako problem i co mówią dane. W niektóre dni trafia na konkretne zapytanie lub zestaw zapytań, które można ulepszyć za pomocą indeksów – albo nowych, albo modyfikacji istniejących indeksów. Jedną z moich ulubionych części dostrajania jest praca z indeksami i gdy myślałem o tym poście, kusiło mnie, aby nazwać dostrajanie indeksów „łatwiejszym” zadaniem… ale tak naprawdę nie jest.
Myślę o strojeniu indeksów jako o sztuce i nauce. Musisz próbować myśleć jak optymalizator i musisz zrozumieć schemat tabeli oraz zapytanie (lub zapytania), które próbujesz dostroić. Oba są oparte na danych, a zatem należą do kategorii nauki. Gdy myślisz o innych, w grę wchodzi grafika indeksy w tabeli i wszystkie inne zapytania, które dotyczą tabeli, na którą mogą mieć wpływ zmiany indeksu.
Krok 1:Zidentyfikuj zapytanie i przejrzyj plan
Kiedy zidentyfikuję zapytanie, które może skorzystać z indeksu, natychmiast otrzymuję jego plan. Często otrzymuję plan wykonania z pamięci podręcznej planu lub magazynu zapytań, a następnie używam programu SSMS, aby uzyskać plan wykonania oraz statystyki czasu wykonywania (czyli rzeczywisty plan wykonania). Wielokrotnie kształt tych dwóch planów jest taki sam; ale to nie jest gwarancja, dlatego lubię widzieć oba.
Plan może mieć brakujące zalecenie dotyczące indeksu, może mieć skanowanie indeksu klastrowego (lub skanowanie sterty, jeśli nie ma indeksu klastrowanego), może używać indeksu nieklastrowanego, ale następnie mieć wyszukiwanie w celu pobrania dodatkowych kolumn. Naprawianie każdego z tych problemów z osobna brzmi całkiem łatwo. Po prostu dodaj brakujący indeks, prawda? Jeśli istnieje skan klastrowego indeksu lub sterty, utwórz indeks, którego potrzebuję dla zapytania, i gotowe? Lub jeśli jest używany indeks, ale trafia on do tabeli, aby uzyskać dodatkowe kolumny, po prostu dodaj kolumny do tego indeksu?
Zwykle nie jest to takie proste, a nawet jeśli tak jest, nadal przechodzę przez proces, który tutaj opisuję.
Krok 2:Określ, które tabele do sprawdzenia
Teraz, gdy mam moje zapytanie, muszę dowiedzieć się, które tabele nie są poprawnie indeksowane. Oprócz przeglądu planu włączam również statystyki IO i TIME w SSMS. Jest to prawdopodobnie moja stara szkoła, ponieważ plany wykonania zawierają coraz więcej informacji – w tym czas trwania i numery we/wy na operatora – w każdym wydaniu, ale podobają mi się statystyki we/wy, ponieważ mogę szybko zobaczyć odczyty dla każdej tabeli. W przypadku zapytań, które są złożone z wieloma sprzężeniami, podzapytaniami, CTE lub widokami zagnieżdżonymi, zrozumienie, gdzie we/wy i/lub czas są spędzane na dyskach zapytań, w których spędzam swój czas. Kiedy tylko jest to możliwe od tego momentu, biorę większe, złożone zapytanie i sprowadzam je do części, która powoduje największy problem.
Na przykład, jeśli istnieje zapytanie, które łączy się z 10 tabelami i zawiera dwa zapytania podrzędne, plan (wraz z informacjami o zamówieniu i czasie trwania) pomaga mi określić, gdzie występuje problem. Następnie wyciągnę tę część zapytania – problematyczną tabelę i może kilka innych, z którymi się łączy – i skupię się na tym. Czasami to tylko podzapytanie, więc od tego zaczynam.
Krok 3:Spójrz na istniejące indeksy
Po zdefiniowaniu zapytania (lub części zapytania) skupiam się na istniejących indeksach dla zaangażowanych tabel. W tym kroku korzystam z wersji sp_helpindex firmy Kimberly. Zdecydowanie wolę jej wersję od standardowej sp_helpindex, ponieważ zawiera ona również listę INCLUDEd kolumn i definicję filtra (jeśli taka istnieje). W zależności od liczby indeksów, które pojawiają się w tabeli, często kopiuję to i wklejam do Excela, a następnie porządkuję na podstawie klucza indeksu, a następnie dołączonych kolumn. To pozwala mi szybko znaleźć nadmiarowe.
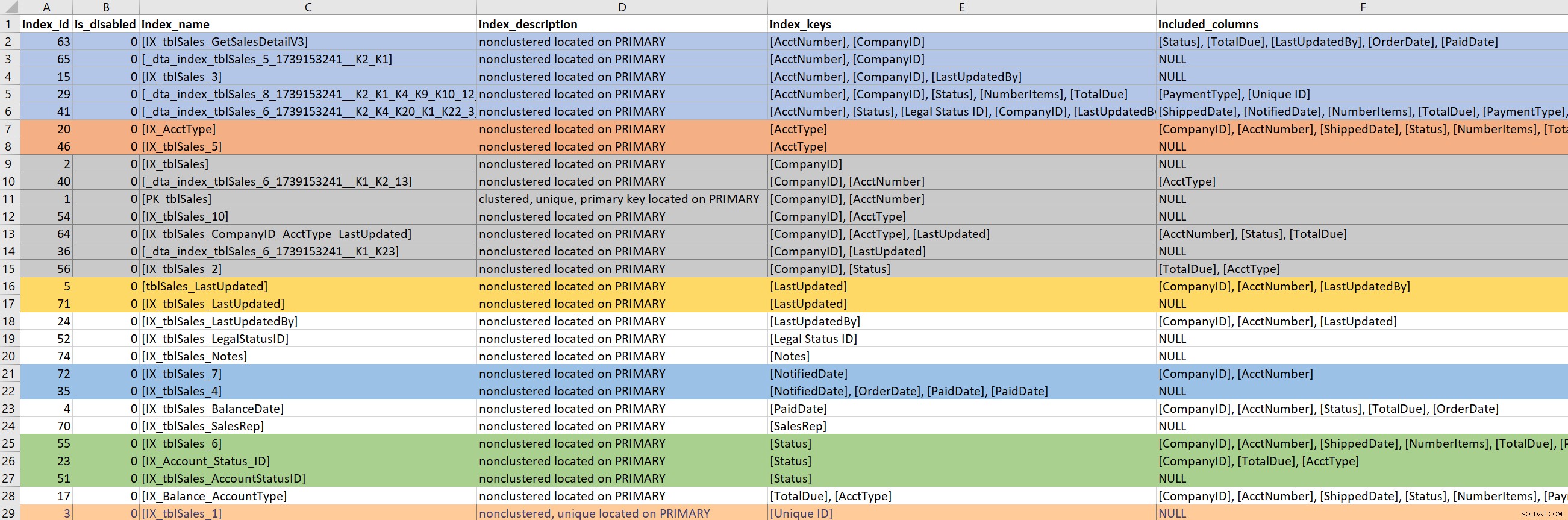
W oparciu o powyższe przykładowe dane wyjściowe istnieje siedem indeksów rozpoczynających się od CompanyID, pięć rozpoczynających się od numeru konta i kilka innych potencjalnych nadmiarowości. Chociaż idealne wydaje się mieć tylko jeden indeks prowadzący do określonej kolumny (np. CompanyID), dla niektórych wzorców zapytań, które nie wystarczają.
Kiedy patrzę na istniejące indeksy, bardzo łatwo jest znaleźć się w króliczej norce. Patrzę na powyższe dane wyjściowe i od razu zaczynam pytać, dlaczego istnieje siedem indeksów, które zaczynają się od CompanyID i chcę wiedzieć, kto je utworzył, dlaczego i dla jakiego zapytania. Ale… jeśli moje problematyczne zapytanie nie korzysta z CompanyID, czy powinno mnie to obchodzić? Tak… ponieważ generalnie jestem po to, aby poprawić wydajność, a jeśli oznacza to przeglądanie po drodze innych indeksów na stole, to niech tak będzie. Ale tutaj łatwo jest stracić poczucie czasu (i prawdziwego celu).
Jeśli moje problematyczne zapytanie wymaga indeksu prowadzącego na PaidDate, mam do czynienia tylko z jednym istniejącym indeksem. Jeśli moje problematyczne zapytanie wymaga indeksu prowadzącego do numeru konta, staje się to trudne. Kiedy istniejące indeksy w pewnym sensie pokrywają zapytanie, a ja chcę rozszerzyć indeks (dodać więcej kolumn) lub skonsolidować (scalić dwa, a może trzy indeksy w jeden), muszę się zagłębić.
Krok 4:Statystyki wykorzystania indeksu
Uważam, że wiele osób nie rejestruje na bieżąco statystyk wykorzystania indeksu. To niefortunne, ponieważ uważam, że te dane są pomocne przy podejmowaniu decyzji, które indeksy zachować, a które porzucić lub scalić. W przypadku, gdy nie mam historycznych statystyk użytkowania, sprawdzam przynajmniej, jak wygląda obecnie użycie (od ostatniego restartu usługi):
SELECT
DB_NAME(ius.database_id),
OBJECT_NAME(i.object_id) [TableName],
i.name [IndexName],
ius.database_id,
i.object_id,
i.index_id,
ius.user_seeks,
ius.user_scans,
ius.user_lookups,
ius.user_updates
FROM sys.indexes i
INNER JOIN sys.dm_db_index_usage_stats ius
ON ius.index_id = i.index_id AND ius.object_id = i.object_id
WHERE ius.database_id = DB_ID(N'Sales2020')
AND i.object_id = OBJECT_ID('dbo.tblSales');
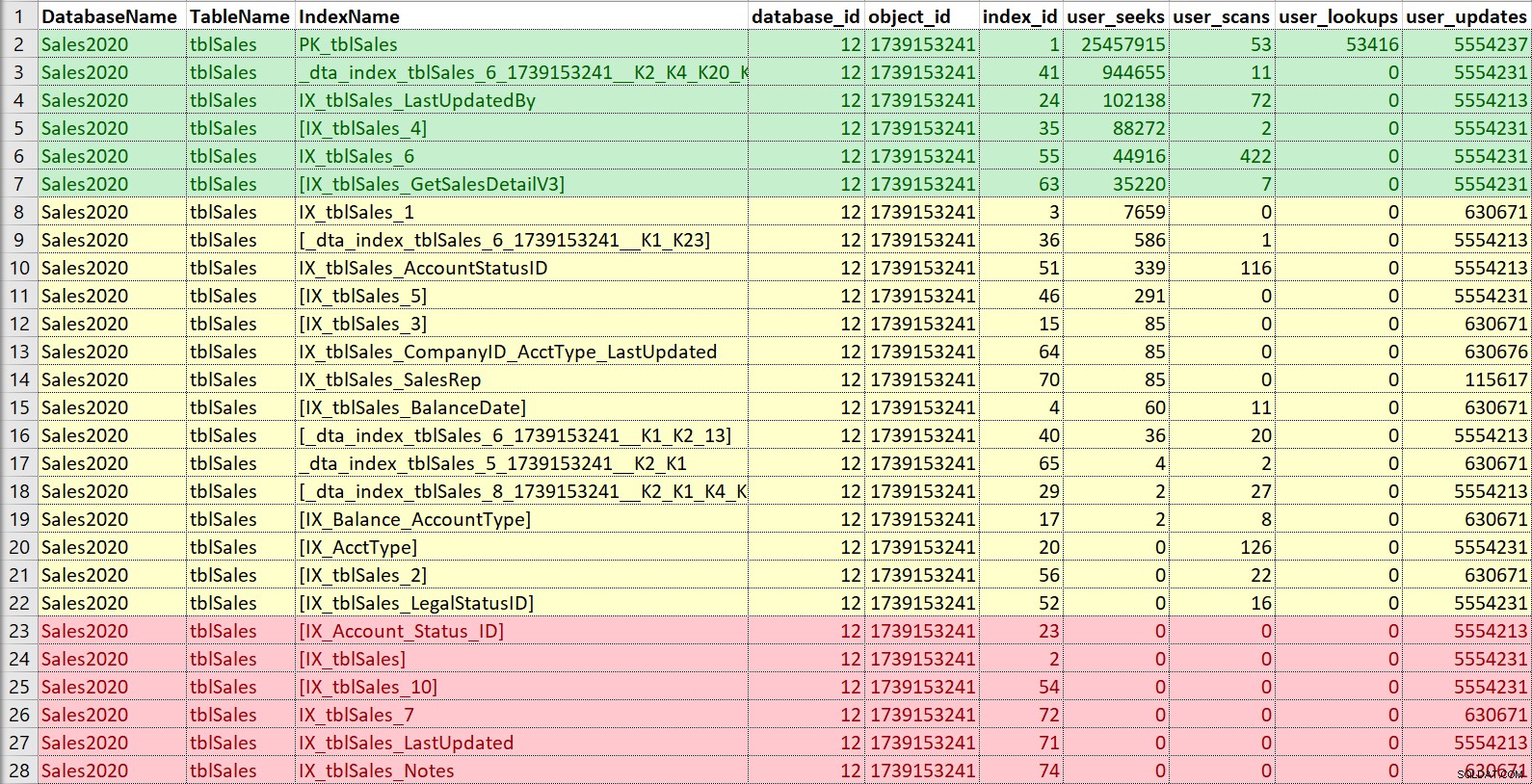
Znowu lubię umieścić to w Excelu, sortować według wyszukiwań, a następnie skanów, a także notować aktualizacje. W tym przykładzie indeksy zaznaczone na czerwono to te, które nie mają wyszukiwania, skanowania ani wyszukiwania… tylko aktualizacje. Są to kandydaci do wyłączenia i potencjalnie porzuceni, jeśli naprawdę nie są używane (ponownie, pomocne byłoby posiadanie historii użytkowania). Indeksy w kolorze zielonym są zdecydowanie używane, chcę je zachować (choć być może w niektórych przypadkach można je poprawić). Te w kolorze żółtym… niektóre są używane, inne ledwo używane. Ponownie, przydałaby się tutaj historia lub kontekst od innych — czasami indeks może mieć kluczowe znaczenie dla raportu lub procesu, który nie jest uruchamiany przez cały czas.
Jeśli chcę tylko zmodyfikować lub dodać nowy indeks, a nie prawdziwe czyszczenie i konsolidację, to głównie interesują mnie indeksy podobne do tego, co chcę dodać lub zmienić. Jednak dopilnuję, aby wskazać klientowi informacje o użytkowaniu i, jeśli pozwoli na to czas, pomogę w ogólnej strategii indeksowania tabeli.
Co dalej?
Jeszcze nie skończyliśmy! To jest część 1 mojego podejścia do dostrajania indeksów, a moja następna część zawiera listę pozostałych kroków. W międzyczasie, jeśli nie rejestrujesz statystyk wykorzystania indeksu, możesz to wprowadzić za pomocą powyższego zapytania lub innej odmiany. Zalecałbym przechwytywanie statystyk użycia dla wszystkich baz danych użytkowników, a nie tylko określonej tabeli i bazy danych, jak to zrobiłem powyżej, więc zmodyfikuj predykat w razie potrzeby. I wreszcie, w ramach zaplanowanego zadania polegającego na zrzuceniu tych informacji w tabeli, nie zapomnij o kolejnym kroku, aby wyczyścić tabelę po tym, jak dane będą tam przez jakiś czas (przechowuję je przez co najmniej sześć miesięcy; niektórzy mogą powiedzieć, że rok jest konieczny).



