[ Część 1 | Część 2 | Część 3 | Część 4 ]
Halloweenowy problem może mieć wiele ważnych skutków dla planów egzekucyjnych. W ostatniej części serii przyjrzymy się sztuczkom, które optymalizator może zastosować, aby uniknąć problemu Halloween podczas kompilowania planów zapytań, które dodają, zmieniają lub usuwają dane.
Tło
Przez lata próbowano różnych sposobów uniknięcia problemu Halloween. Jedną z wczesnych technik było po prostu unikanie tworzenia jakichkolwiek planów wykonania, które obejmowały odczytywanie i zapisywanie kluczy tego samego indeksu. Nie było to zbyt udane z punktu widzenia wydajności, nie tylko dlatego, że często oznaczało skanowanie tabeli bazowej zamiast używania selektywnego indeksu nieklastrowego w celu zlokalizowania wierszy do zmiany.
Drugie podejście polegało na całkowitym oddzieleniu faz odczytu i zapisu zapytania aktualizującego, najpierw lokalizując wszystkie wiersze, które kwalifikują się do zmiany, przechowując je gdzieś, a dopiero potem rozpoczynając wprowadzanie zmian. W SQL Server ta pełna separacja faz osiąga się poprzez umieszczenie znanej już szpuli tabeli Chętni po stronie wejściowej operatora aktualizacji:
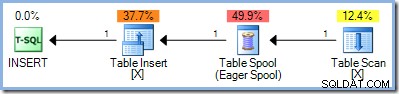
Bufor odczytuje wszystkie wiersze ze swojego wejścia i przechowuje je w ukrytym tempdb stół roboczy. Strony tej tabeli roboczej mogą pozostać w pamięci lub mogą wymagać fizycznego miejsca na dysku, jeśli zestaw wierszy jest duży lub jeśli serwer jest pod presją pamięci.
Pełna separacja faz może być mniej niż idealna, ponieważ generalnie chcemy uruchomić jak największą część planu jako potok, w którym każdy wiersz jest w pełni przetwarzany przed przejściem do następnego. Pipelining ma wiele zalet, w tym unikanie potrzeby tymczasowego przechowywania i dotykanie każdego rzędu tylko raz.
Optymalizator SQL Server
SQL Server idzie znacznie dalej niż dwie opisane do tej pory techniki, choć oczywiście zawiera obie jako opcje. Optymalizator zapytań SQL Server wykrywa zapytania, które wymagają ochrony Halloween, określa ile ochrona jest wymagana i używa opartej na kosztach analiza, aby znaleźć najtańszą metodę zapewnienia tej ochrony.
Najłatwiejszym sposobem zrozumienia tego aspektu problemu Halloween jest przyjrzenie się kilku przykładom. W kolejnych sekcjach zadaniem jest dodanie zakresu liczb do istniejącej tabeli – ale tylko liczb, które jeszcze nie istnieją:
CREATE TABLE dbo.Test
(
pk integer NOT NULL,
CONSTRAINT PK_Test
PRIMARY KEY CLUSTERED (pk)
); 5 rzędów
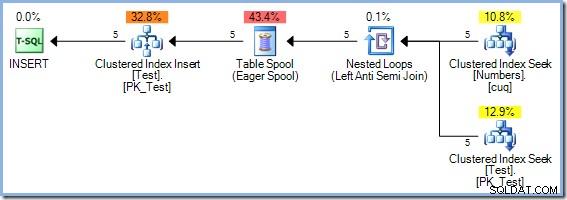
Pierwszy przykład przetwarza zakres liczb od 1 do 5 włącznie:
INSERT dbo.Test (pk)
SELECT Num.n
FROM dbo.Numbers AS Num
WHERE
Num.n BETWEEN 1 AND 5
AND NOT EXISTS
(
SELECT NULL
FROM dbo.Test AS t
WHERE t.pk = Num.n
); Ponieważ to zapytanie odczytuje i zapisuje klucze tego samego indeksu w tabeli Test, plan wykonania wymaga ochrony Halloween. W takim przypadku optymalizator wykorzystuje pełną separację faz przy użyciu bufora tabeli Chętnych:
50 wierszy
Mając teraz pięć wierszy w tabeli Test, ponownie uruchamiamy to samo zapytanie, zmieniając WHERE klauzula dotycząca przetwarzania liczb od 1 do 50 włącznie :
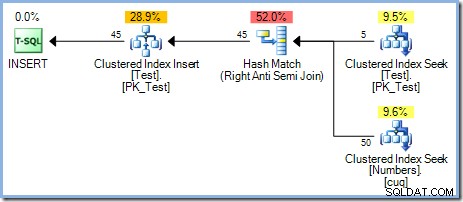
Ten plan zapewnia właściwą ochronę przed Halloweenowym Problemem, ale nie zawiera Chętnej Szpuli Stołowej. Optymalizator rozpoznaje, że operator łączenia Hash Match blokuje dane wejściowe kompilacji; wszystkie wiersze są wczytywane do tablicy mieszającej, zanim operator rozpocznie proces dopasowywania przy użyciu wierszy z danych wejściowych sondy. W konsekwencji plan ten w naturalny sposób zapewnia separację faz (tylko dla stołu testowego) bez potrzeby stosowania szpuli.
Optymalizator wybrał plan łączenia Hash Match zamiast łączenia zagnieżdżonych pętli widocznych w planie 5-wierszowym z powodów związanych z kosztami. 50-wierszowy plan Hash Match ma szacowany całkowity koszt 0,0347345 jednostki. Możemy wymusić stosowany wcześniej plan zagnieżdżonych pętli, podając wskazówkę, dlaczego optymalizator nie wybrał zagnieżdżonych pętli:
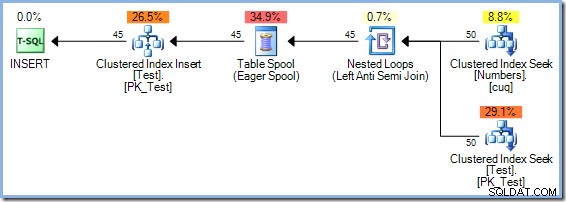
Ten plan ma szacunkowy koszt 0,0379063 jednostek, w tym szpula, nieco więcej niż plan Hash Match.
500 wierszy
Mając teraz 50 wierszy w tabeli Test, dodatkowo zwiększamy zakres liczb do 500 :
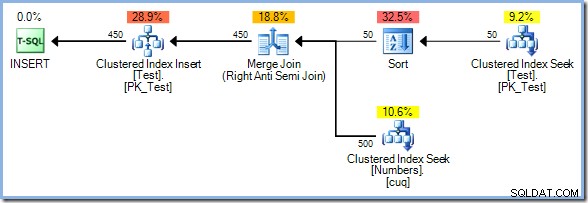
Tym razem optymalizator wybiera łączenie scalające i ponownie nie ma buforowania tabeli Chętni. Operator Sort zapewnia niezbędną separację faz w tym planie. W pełni zużywa swoje dane wejściowe przed zwróceniem pierwszego wiersza (sortowanie nie może wiedzieć, który wiersz sortuje się jako pierwszy, dopóki wszystkie wiersze nie zostaną wyświetlone). Optymalizator zdecydował, że sortowanie 50 wiersze z tabeli Test byłyby tańsze niż szybkie buforowanie 450 wiersze tuż przed operatorem aktualizacji.
Plan Sort plus Merge Join ma szacunkowy koszt 0,0362708 jednostki. Alternatywne plany Hash Match i Nested Loops są dostępne pod adresem 0,0385677 jednostki i 0,112433 jednostki odpowiednio.
Coś dziwnego w sortowaniu
Jeśli sam uruchamiałeś te przykłady, być może zauważyłeś coś dziwnego w tym ostatnim przykładzie, szczególnie jeśli spojrzałeś na podpowiedzi narzędzi Eksplorator planów dla tabeli Testuj Szukaj i sortuj:
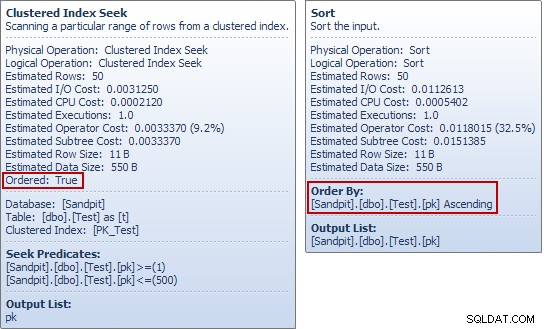
Seek produkuje zamówione strumień pk wartości, więc jaki jest sens sortowania w tej samej kolumnie zaraz potem? Aby odpowiedzieć na to (bardzo rozsądne) pytanie, zaczynamy od spojrzenia tylko na SELECT część INSERT zapytanie:
SELECT Num.n
FROM dbo.Numbers AS Num
WHERE
Num.n BETWEEN 1 AND 500
AND NOT EXISTS
(
SELECT 1
FROM dbo.Test AS t
WHERE t.pk = Num.n
)
ORDER BY
Num.n;
To zapytanie generuje poniższy plan wykonania (z lub bez ORDER BY Dodałem, aby rozwiązać pewne techniczne zastrzeżenia, które możesz mieć):
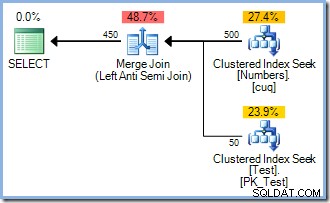
Zwróć uwagę na brak operatora Sort. Dlaczego więc INSERT plan zawiera sortowanie? Po prostu po to, by uniknąć Halloweenowego Problemu. Optymalizator uznał, że wykonywanie sortowania nadmiarowego (z wbudowaną separacją faz) był najtańszym sposobem wykonania zapytania i zagwarantowania poprawnych wyników. Sprytny.
Poziomy i właściwości ochrony Halloween
Optymalizator programu SQL Server ma określone funkcje, które pozwalają mu wnioskować o poziomie ochrony Halloween (HP) wymaganym w każdym punkcie planu zapytania oraz o szczegółowym efekcie, jaki ma każdy operator. Te dodatkowe funkcje są włączone do tej samej struktury właściwości, której optymalizator używa do śledzenia setek innych ważnych informacji podczas działań wyszukiwania.
Każdy operator ma wymagany Własność HP i dostarczone Własność HP. wymagane Właściwość wskazuje poziom HP potrzebny w danym punkcie drzewa do uzyskania prawidłowych wyników. dostarczone właściwość odzwierciedla HP podaną przez obecnego operatora i skumulowaną Efekty HP zapewniane przez jego poddrzewo.
Optymalizator zawiera logikę określającą, w jaki sposób każdy operator fizyczny (na przykład skalar obliczeniowy) wpływa na poziom HP. Badając szeroką gamę alternatywnych planów i odrzucając plany, w których dostarczone HP jest mniejsze niż HP wymagane przez operatora aktualizacji, optymalizator ma elastyczny sposób na znalezienie poprawnych, wydajnych planów, które nie zawsze wymagają Chętnego buforowania tabeli.
Zmiany planu dotyczące ochrony Halloween
Widzieliśmy, jak optymalizator dodaje nadmiarowe sortowanie dla ochrony Halloween w poprzednim przykładzie Merge Join. Jak możemy być pewni, że jest to bardziej wydajne niż zwykła szpula stołu Chętna? A skąd możemy wiedzieć, które funkcje planu aktualizacji są dostępne tylko dla ochrony Halloween?
Na oba pytania można odpowiedzieć (oczywiście w środowisku testowym) za pomocą nieudokumentowanej flagi śledzenia 8692 , co zmusza optymalizator do użycia bufora tabeli Chętni w celu ochrony Halloween. Przypomnij sobie, że plan łączenia scalającego z nadmiarowym sortowaniem miał szacunkowy koszt 0,0362708 magiczne jednostki optymalizujące. Możemy porównać to z alternatywą Chętnego buforowania tabeli, ponownie kompilując zapytanie z włączoną flagą śledzenia 8692:
INSERT dbo.Test (pk)
SELECT Num.n
FROM dbo.Numbers AS Num
WHERE
Num.n BETWEEN 1 AND 500
AND NOT EXISTS
(
SELECT 1
FROM dbo.Test AS t
WHERE t.pk = Num.n
)
OPTION (QUERYTRACEON 8692);
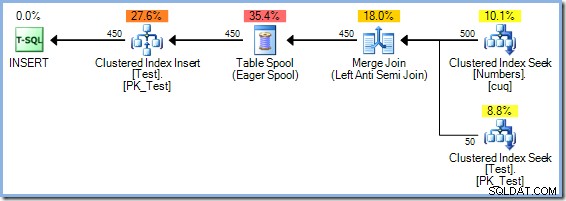
Plan Eager Spool ma szacunkowy koszt 0,0378719 jednostki (wzrost z 0,0362708 z redundantnym sortowaniem). Przedstawione tu różnice kosztów nie są bardzo znaczące ze względu na banalny charakter zadania i niewielki rozmiar rzędów. Zapytania aktualizujące w świecie rzeczywistym ze złożonymi drzewami i większą liczbą wierszy często tworzą plany, które są znacznie wydajniejsze dzięki zdolności optymalizatora SQL Server do głębokiego przemyślenia funkcji Halloween Protection.
Inne opcje bez buforowania
Optymalne umieszczenie operatora blokującego w planie nie jest jedyną strategią dostępną dla optymalizatora, aby zminimalizować koszty zapewnienia ochrony przed problemem Halloween. Może również uzasadniać zakres przetwarzanych wartości, jak pokazuje poniższy przykład:
CREATE TABLE #Test
(
pk integer IDENTITY PRIMARY KEY,
some_value integer
);
CREATE INDEX i ON #Test (some_value);
-- Pretend the table has lots of data in it
UPDATE STATISTICS #Test
WITH ROWCOUNT = 123456, PAGECOUNT = 1234;
UPDATE #Test
SET some_value = 10
WHERE some_value = 5; Plan wykonania nie wskazuje na potrzebę ochrony Halloween, mimo że czytamy i aktualizujemy klucze wspólnego indeksu:
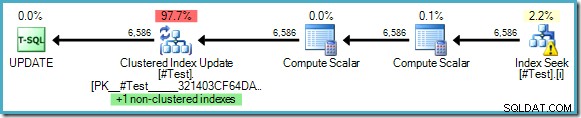
Optymalizator widzi, że zmiana „jakaś_wartość” z 5 na 10 nigdy nie spowoduje, że zaktualizowany wiersz zostanie wyświetlony po raz drugi przez funkcję wyszukiwania indeksu (które szuka tylko wierszy, w których jaka_wartość wynosi 5). To rozumowanie jest możliwe tylko wtedy, gdy w zapytaniu są używane wartości literałowe lub gdy zapytanie określa OPTION (RECOMPILE) , umożliwiając optymalizatorowi wywęszenie wartości parametrów dla jednorazowego planu wykonania.
Nawet w przypadku wartości literalnych w zapytaniu optymalizator może nie mieć możliwości zastosowania tej logiki, jeśli opcja bazy danych FORCED PARAMETERIZATION jest ON . W takim przypadku wartości literalne w zapytaniu są zastępowane parametrami, a optymalizator nie może być już pewien, że Ochrona Halloween nie jest wymagana (lub nie będzie wymagana, gdy plan zostanie ponownie użyty z innymi wartościami parametrów):

Jeśli zastanawiasz się, co się stanie, jeśli FORCED PARAMETERIZATION jest włączony i zapytanie określa OPTION (RECOMPILE) , odpowiedź jest taka, że optymalizator kompiluje plan dla wyszukanych wartości, a więc może zastosować optymalizację. Jak zawsze w przypadku OPTION (RECOMPILE) , plan zapytań o określonej wartości nie jest buforowany do ponownego wykorzystania.
Góra
Ten ostatni przykład pokazuje, jak Top operator może usunąć potrzebę ochrony Halloween:
UPDATE TOP (1) t SET some_value += 1 FROM #Test AS t WHERE some_value <= 10;

Ochrona nie jest wymagana, ponieważ aktualizujemy tylko jeden wiersz. Wyszukiwanie indeksu nie może napotkać zaktualizowanej wartości, ponieważ potok przetwarzania zatrzymuje się natychmiast po zaktualizowaniu pierwszego wiersza. Ponownie, tę optymalizację można zastosować tylko wtedy, gdy w TOP zostanie użyta stała wartość literału , lub jeśli zmienna zwracająca wartość „1” jest sniffowana przy użyciu OPTION (RECOMPILE) .
Jeśli zmienimy TOP (1) w zapytaniu do TOP (2) , optymalizator wybiera klastrowe skanowanie indeksu zamiast wyszukiwania indeksu:

Nie aktualizujemy kluczy indeksu klastrowego, więc ten plan nie wymaga ochrony Halloween. Wymuszanie użycia indeksu nieklastrowego z podpowiedzią w TOP (2) zapytanie pokazuje koszt ochrony:

Optymalizator oszacował, że klastrowe skanowanie indeksu będzie tańsze niż ten plan (z dodatkową ochroną Halloween).
Szanse i zakończenia
Jest kilka innych kwestii, które chciałbym poruszyć na temat Ochrony Halloween, które do tej pory nie znalazły naturalnego miejsca w serii. Pierwszym z nich jest kwestia ochrony przed Halloween, gdy używany jest poziom izolacji wersjonowania wierszy.
Wersjonowanie wierszy
SQL Server zapewnia dwa poziomy izolacji, READ COMMITTED SNAPSHOT i SNAPSHOT ISOLATION które używają magazynu wersji w tempdb aby zapewnić spójny widok bazy danych na poziomie instrukcji lub transakcji. SQL Server może całkowicie uniknąć Halloween Protection na tych poziomach izolacji, ponieważ magazyn wersji może dostarczać dane, na które nie mają wpływu żadne zmiany, które mogły do tej pory wprowadzić aktualnie wykonywane instrukcje. Ten pomysł nie jest obecnie zaimplementowany w wydanej wersji SQL Server, chociaż Microsoft złożył patent opisujący, jak to będzie działać, więc być może przyszła wersja będzie zawierać tę technologię.
Stosy i przekazane rekordy
Jeśli jesteś zaznajomiony z wewnętrznymi strukturami sterty, możesz się zastanawiać, czy podczas generowania przekazywanych rekordów w tabeli sterty może wystąpić konkretny problem Halloween. Jeśli jest to dla Ciebie nowe, rekord sterty zostanie przekazany, jeśli istniejący wiersz zostanie zaktualizowany w taki sposób, że nie mieści się już na oryginalnej stronie danych. Silnik pozostawia fragment przekierowania i przenosi rozwinięty rekord na inną stronę.
Problem może wystąpić, jeśli plan zawierający skanowanie sterty aktualizuje rekord w taki sposób, że jest on przekazywany dalej. Skanowanie sterty może ponownie napotkać wiersz, gdy pozycja skanowania osiągnie stronę z przekazanym rekordem. W programie SQL Server można uniknąć tego problemu, ponieważ aparat magazynu gwarantuje, że zawsze będzie natychmiast podążał za wskaźnikami przekazywania. Jeśli skanowanie napotka rekord, który został przekazany, ignoruje go. Dzięki temu zabezpieczeniu optymalizator zapytań nie musi się martwić o ten scenariusz.
SCHEMABINDING i funkcje skalarne T-SQL
Jest bardzo niewiele przypadków, w których użycie funkcji skalarnej T-SQL jest dobrym pomysłem, ale jeśli musisz jej użyć, powinieneś zdawać sobie sprawę z ważnego wpływu, jaki może ona mieć na Halloween Protection. Chyba że funkcja skalarna jest zadeklarowana z SCHEMABINDING Opcja SQL Server zakłada, że funkcja uzyskuje dostęp do tabel. Aby to zilustrować, rozważ poniższą prostą funkcję skalarną T-SQL:
CREATE FUNCTION dbo.ReturnInput
(
@value integer
)
RETURNS integer
AS
BEGIN
RETURN @value;
END;
Ta funkcja nie ma dostępu do żadnych tabel; w rzeczywistości nie robi nic poza zwróceniem przekazanej do niego wartości parametru. Teraz spójrz na następujące INSERT zapytanie:
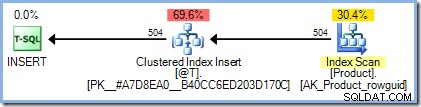
DECLARE @T AS TABLE (ProductID integer PRIMARY KEY); INSERT @T (ProductID) SELECT p.ProductID FROM AdventureWorks2012.Production.Product AS p;
Plan wykonania jest dokładnie taki, jak byśmy się spodziewali, bez konieczności ochrony Halloween:
Dodanie funkcji „nic nie rób” ma jednak dramatyczny efekt:
DECLARE @T AS TABLE (ProductID integer PRIMARY KEY); INSERT @T (ProductID) SELECT dbo.ReturnInput(p.ProductID) FROM AdventureWorks2012.Production.Product AS p;

Plan egzekucji zawiera teraz Chętną Szpulę Stołu na Halloweenową Ochronę. SQL Server zakłada, że funkcja uzyskuje dostęp do danych, co może obejmować ponowne odczytywanie z tabeli Produkt. Jak być może pamiętasz, INSERT plan, który zawiera odniesienie do tabeli docelowej po stronie do czytania planu, wymaga pełnej ochrony Halloween i, o ile wie optymalizator, może tak być w tym przypadku.
Dodawanie SCHEMABINDING Opcja definicji funkcji oznacza, że SQL Server sprawdza treść funkcji, aby określić, do których tabel uzyskuje dostęp. Nie znajduje takiego dostępu, więc nie dodaje żadnej ochrony Halloween:
ALTER FUNCTION dbo.ReturnInput
(
@value integer
)
RETURNS integer
WITH SCHEMABINDING
AS
BEGIN
RETURN @value;
END;
GO
DECLARE @T AS TABLE (ProductID int PRIMARY KEY);
INSERT @T (ProductID)
SELECT p.ProductID
FROM AdventureWorks2012.Production.Product AS p;
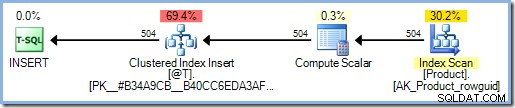
Ten problem z funkcjami skalarnymi T-SQL wpływa na wszystkie zapytania aktualizacyjne — INSERT , UPDATE , DELETE i MERGE . Wiedza o tym, kiedy napotkasz ten problem, jest trudniejsza, ponieważ niepotrzebna Ochrona Halloween nie zawsze pojawi się jako dodatkowy bufor tabeli Chętni, a wywołania funkcji skalarnych mogą być ukryte na przykład w widokach lub definicjach kolumn obliczeniowych.
[ Część 1 | Część 2 | Część 3 | Część 4 ]