[ Część 1 | Część 2 | Część 3 | Część 4 ]
MERGE Instrukcja (wprowadzona w SQL Server 2008) pozwala nam wykonać mieszankę INSERTs , UPDATE i DELETE operacje przy użyciu pojedynczej instrukcji. Problemy ochrony Halloween dla MERGE są w większości kombinacją wymagań poszczególnych operacji, ale jest kilka ważnych różnic i kilka interesujących optymalizacji, które dotyczą tylko MERGE .
Unikanie Halloweenowego problemu dzięki MERGE
Zaczynamy od ponownego spojrzenia na przykład Demo i Staging z części drugiej:
CREATE TABLE dbo.Demo
(
SomeKey integer NOT NULL,
CONSTRAINT PK_Demo
PRIMARY KEY (SomeKey)
);
CREATE TABLE dbo.Staging
(
SomeKey integer NOT NULL
);
INSERT dbo.Staging
(SomeKey)
VALUES
(1234),
(1234);
CREATE NONCLUSTERED INDEX c
ON dbo.Staging (SomeKey);
INSERT dbo.Demo
SELECT s.SomeKey
FROM dbo.Staging AS s
WHERE NOT EXISTS
(
SELECT 1
FROM dbo.Demo AS d
WHERE d.SomeKey = s.SomeKey
);
Jak być może pamiętasz, ten przykład został użyty do pokazania, że INSERTs wymaga ochrony Halloween, gdy docelowa tabela wstawiania jest również przywoływana w SELECT część zapytania (EXISTS w tym przypadku). Poprawne zachowanie INSERTs powyższe oświadczenie to próba dodania obie 1234 wartości i w konsekwencji niepowodzenie z PRIMARY KEY naruszenie. Bez separacji faz INSERTs błędnie doda jedną wartość, kończąc bez wyrzucenia błędu.
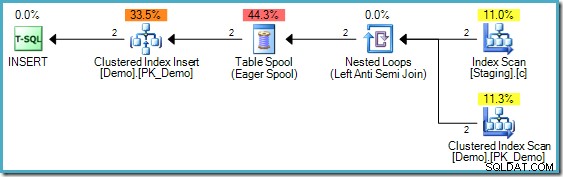
Plan wykonania INSERT
Powyższy kod różni się od tego użytego w części drugiej; dodano indeks nieklastrowy w tabeli Staging. INSERTs plan wykonania nadal wymaga jednak ochrony Halloween:
Plan wykonania MERGE
Teraz wypróbuj tę samą logiczną wstawkę wyrażoną za pomocą MERGE składnia:
MERGE dbo.Demo AS d
USING dbo.Staging AS s ON
s.SomeKey = d.SomeKey
WHEN NOT MATCHED BY TARGET THEN
INSERT (SomeKey)
VALUES (s.SomeKey);
Jeśli nie znasz składni, logika polega na porównywaniu wierszy w tabelach Staging i Demo w wartości SomeKey, a jeśli w tabeli docelowej (Demo) nie zostanie znaleziony pasujący wiersz, wstawimy nowy wiersz. Ma dokładnie taką samą semantykę jak poprzednie INSERT...WHERE NOT EXISTS kod oczywiście. Plan wykonania jest jednak zupełnie inny:
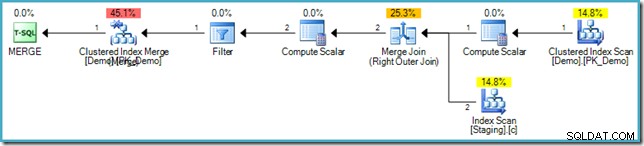
Zwróć uwagę, że w tym planie brakuje opcji Eager Table Spool. Mimo to zapytanie nadal generuje poprawny komunikat o błędzie. Wygląda na to, że SQL Server znalazł sposób na wykonanie MERGE planować iteracyjnie, z poszanowaniem logicznej separacji faz wymaganej przez standard SQL.
Optymalizacja wypełniania dziur
W odpowiednich okolicznościach optymalizator SQL Server może rozpoznać, że MERGE oświadczenie zapełnia dziury , co jest po prostu innym sposobem powiedzenia, że instrukcja dodaje tylko wiersze, w których istnieje luka w kluczu tabeli docelowej.
Aby ta optymalizacja została zastosowana, wartości użyte w WHEN NOT MATCHED BY TARGET klauzula musi dokładnie dopasuj ON część USING klauzula. Ponadto tabela docelowa musi mieć unikalny klucz (wymaganie spełnione przez PRIMARY KEY w niniejszej sprawie). Jeśli te wymagania są spełnione, MERGE oświadczenie nie wymaga ochrony przed problemem Halloween.
Oczywiście MERGE oświadczenie jest logicznie nie mniej lub bardziej wypełnianie dziur niż oryginalny INSERT...WHERE NOT EXISTS składnia. Różnica polega na tym, że optymalizator ma pełną kontrolę nad implementacją MERGE oświadczenie, natomiast INSERTs składnia wymagałaby wnioskowania o szerszej semantyce zapytania. Człowiek może łatwo zauważyć, że INSERTs również wypełnia dziury, ale optymalizator nie myśli o rzeczach w taki sam sposób, jak my.
Aby zilustrować dokładne dopasowanie wymaganie, o którym wspomniałem, rozważ następującą składnię zapytania, która nie skorzystaj z optymalizacji wypełniania otworów. Rezultatem jest pełna ochrona na Halloween zapewniana przez gorącą szpulę stołu:
MERGE dbo.Demo AS d
USING dbo.Staging AS s ON
s.SomeKey = d.SomeKey
WHEN NOT MATCHED THEN
INSERT (SomeKey)
VALUES (s.SomeKey * 1);

Jedyną różnicą jest mnożenie przez jeden w VALUES klauzula – coś, co nie zmienia logiki zapytania, ale wystarczy, aby zapobiec zastosowaniu optymalizacji wypełniania dziur.
Wypełnianie otworów za pomocą zagnieżdżonych pętli
W poprzednim przykładzie optymalizator wybrał łączenie tabel za pomocą łączenia scalającego. Optymalizacja wypełniania dziur może być również zastosowana w przypadku wybrania złączenia zagnieżdżonych pętli, ale wymaga to dodatkowej gwarancji unikalności w tabeli źródłowej i wyszukiwania indeksu po wewnętrznej stronie złączenia. Aby zobaczyć to w akcji, możemy wyczyścić istniejące dane tymczasowe, dodać unikatowość do indeksu nieklastrowanego i wypróbować MERGE ponownie:
-- Remove existing duplicate rows
TRUNCATE TABLE dbo.Staging;
-- Convert index to unique
CREATE UNIQUE NONCLUSTERED INDEX c
ON dbo.Staging (SomeKey)
WITH (DROP_EXISTING = ON);
-- Sample data
INSERT dbo.Staging
(SomeKey)
VALUES
(1234),
(5678);
-- Hole-filling merge
MERGE dbo.Demo AS d
USING dbo.Staging AS s ON
s.SomeKey = d.SomeKey
WHEN NOT MATCHED THEN
INSERT (SomeKey)
VALUES (s.SomeKey); Wynikowy plan wykonania ponownie wykorzystuje optymalizację wypełniania dziur, aby uniknąć Halloween Protection, używając łączenia zagnieżdżonych pętli i wyszukiwania wewnętrznej strony w tabeli docelowej:
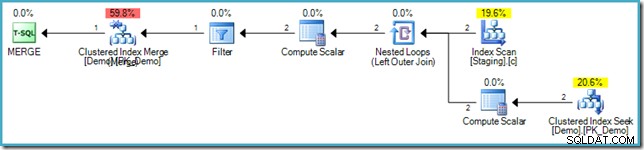
Unikanie niepotrzebnego przechodzenia przez indeks
Tam, gdzie ma zastosowanie optymalizacja wypełniania dziur, silnik może również zastosować dalszą optymalizację. Zapamiętuje aktualną pozycję indeksu podczas czytania tabeli docelowej (przetwarzając jeden wiersz na raz, pamiętaj) i ponownie użyj tych informacji podczas wykonywania wstawiania, zamiast szukać w dół drzewa b, aby znaleźć lokalizację wstawiania. Rozumowanie jest takie, że bieżąca pozycja do czytania najprawdopodobniej znajduje się na tej samej stronie, na której należy wstawić nowy wiersz. Sprawdzenie, czy wiersz rzeczywiście należy do tej strony, jest bardzo szybkie, ponieważ obejmuje sprawdzenie tylko najniższego i najwyższego klucza, który jest tam aktualnie przechowywany.
Połączenie wyeliminowania buforowania tabeli Chętni i zapisania nawigacji po indeksie na wiersz może zapewnić znaczne korzyści w obciążeniach OLTP, pod warunkiem, że plan wykonania jest pobierany z pamięci podręcznej. Koszt kompilacji dla MERGE instrukcje są raczej wyższe niż dla INSERTs , UPDATE i DELETE , więc ponowne wykorzystanie planu jest ważnym czynnikiem. Pomocne jest również zapewnienie, że strony mają wystarczającą ilość wolnego miejsca, aby zmieścić nowe wiersze, unikając podziałów stron. Zwykle osiąga się to poprzez normalną konserwację indeksu i przypisanie odpowiedniego FILLFACTOR .
Wspominam o obciążeniach OLTP, które zazwyczaj zawierają dużą liczbę stosunkowo niewielkich zmian, ponieważ MERGE optymalizacje mogą nie być dobrym wyborem, gdy w instrukcji przetwarzana jest duża liczba wierszy. Inne optymalizacje, takie jak minimalnie rejestrowane INSERTs obecnie nie można łączyć z wypełnianiem otworów. Jak zawsze, charakterystyka wydajności powinna być porównana, aby zapewnić osiągnięcie oczekiwanych korzyści.
Optymalizacja wypełniania dziur dla MERGE wstawki można łączyć z aktualizacjami i usuwaniem za pomocą dodatkowego MERGE klauzule; każda operacja zmiany danych jest oceniana osobno dla Problemu Halloween.
Unikanie dołączenia
Ostateczną optymalizację, którą przyjrzymy się, można zastosować tam, gdzie MERGE instrukcja zawiera operacje aktualizacji i usuwania, a także wstawkę wypełniającą dziury, a tabela docelowa ma unikalny indeks klastrowy. Poniższy przykład pokazuje typowy MERGE wzorzec, w którym wstawiane są niepasujące wiersze, a pasujące wiersze są aktualizowane lub usuwane w zależności od dodatkowego warunku:
CREATE TABLE #T
(
col1 integer NOT NULL,
col2 integer NOT NULL,
CONSTRAINT PK_T
PRIMARY KEY (col1)
);
CREATE TABLE #S
(
col1 integer NOT NULL,
col2 integer NOT NULL,
CONSTRAINT PK_S
PRIMARY KEY (col1)
);
INSERT #T
(col1, col2)
VALUES
(1, 50),
(3, 90);
INSERT #S
(col1, col2)
VALUES
(1, 40),
(2, 80),
(3, 90);
MERGE oświadczenie wymagane do wprowadzenia wszystkich wymaganych zmian jest wyjątkowo zwięzłe:
MERGE #T AS t USING #S AS s ON t.col1 = s.col1 WHEN NOT MATCHED THEN INSERT VALUES (s.col1, s.col2) WHEN MATCHED AND t.col2 - s.col2 = 0 THEN DELETE WHEN MATCHED THEN UPDATE SET t.col2 -= s.col2;
Plan wykonania jest dość zaskakujący:

Bez ochrony Halloween, bez łączenia między tabelą źródłową i docelową, a nieczęsto zobaczysz operator wstawiania indeksu klastrowego, po którym następuje scalanie indeksu klastrowego z tą samą tabelą. To kolejna optymalizacja ukierunkowana na obciążenia OLTP z wysokim ponownym wykorzystaniem planów i odpowiednim indeksowaniem.
Pomysł polega na odczytaniu wiersza z tabeli źródłowej i natychmiastowej próbie wstawienia go do celu. Jeśli dojdzie do naruszenia klucza, błąd jest pomijany, operator Insert wyświetla znaleziony wiersz powodujący konflikt, który jest następnie przetwarzany w celu przeprowadzenia operacji aktualizacji lub usunięcia przy użyciu operatora planu scalania w normalny sposób.
Jeśli oryginalne wstawienie się powiedzie (bez naruszenia klucza), przetwarzanie będzie kontynuowane od następnego wiersza ze źródła (operator scalania przetwarza tylko aktualizacje i usunięcia). Ta optymalizacja przynosi przede wszystkim korzyści MERGE zapytania, w których większość wierszy źródłowych powoduje wstawienie. Ponownie, wymagana jest staranna analiza porównawcza, aby upewnić się, że wydajność jest lepsza niż przy użyciu oddzielnych stwierdzeń.
Podsumowanie
MERGE oświadczenie zapewnia kilka unikalnych możliwości optymalizacji. W odpowiednich okolicznościach może uniknąć konieczności dodawania wyraźnej ochrony Halloween w porównaniu z równoważnym INSERTs operacja, a może nawet kombinacja INSERTs , UPDATE i DELETE sprawozdania. Dodatkowe MERGE -specyficzne optymalizacje mogą uniknąć przechodzenia przez indeks b-drzewa, które jest zwykle potrzebne do zlokalizowania pozycji wstawiania dla nowego wiersza, a także mogą uniknąć konieczności całkowitego łączenia tabel źródłowych i docelowych.
W końcowej części tej serii przyjrzymy się, w jaki sposób optymalizator zapytań uzasadnia potrzebę ochrony przed Halloween, i zidentyfikujemy kilka innych sztuczek, które może zastosować, aby uniknąć konieczności dodawania Chętnych buforów tabel do planów wykonania, które zmieniają dane.
[ Część 1 | Część 2 | Część 3 | Część 4 ]