W 2014 roku zacząłem tutaj serię wpisów na blogu, aby porozmawiać o konkretnych typach oczekiwania oraz o tym, co one robią, a czego nie oznaczają. To podsunęło mi pomysł stworzenia bibliotek wait i latch, które opiekuję (więcej o nich później).
Jeśli to czytasz i myślisz „o czym on mówi?” to ten post jest dla Ciebie. Przedstawię statystyki oczekiwania i wyjaśnię, jak ważne są one dla rozwiązywania problemów z wydajnością obciążenia w SQL Server.
Planowanie
Wykonanie wewnętrznego kodu SQL Server odbywa się za pomocą mechanizmu o nazwie wątki . Każdy wątek może wykonywać kod SQL Server, a wiele wątków koordynuje się razem, gdy zapytanie jest wykonywane równolegle. Te wątki są tworzone podczas uruchamiania SQL Server, w zależności od liczby rdzeni procesorów dostępnych dla SQL Server.
Wątki są umieszczane w harmonogramie gdy zapytanie się rozpoczyna, z jednym harmonogramem na rdzeń procesora i nie odchodź od tego harmonogramu, dopóki zapytanie nie zostanie zakończone. Harmonogram składa się z trzech podstawowych „części”:
- procesor , który ma dokładnie jeden wątek wykonujący kod.
- Lista kelnerów , który zawiera wszystkie wątki, które w zasadzie utknęły, czekając na udostępnienie określonego zasobu.
- kolejka, którą można uruchomić , który zawiera wszystkie wątki, które są w stanie wykonać, ale czekają na procesor.
Wątki przechodzą ze stanu 1 do 2 do 3 do 1, w kółko i w kółko, aż do zakończenia zapytania.
Czekaj
Z naszej perspektywy najciekawszą częścią planowania jest sytuacja, w której wątek musi czekać na zasób, zanim będzie mógł kontynuować. Oto kilka przykładów:
- Wątek musi odczytać stronę, a strona nie znajduje się w pamięci, więc wątek wykonuje asynchroniczne fizyczne operacje we/wy, a następnie musi czekać poza procesorem na zakończenie operacji we/wy.
- Wątek musi uzyskać blokadę udziału w wierszu, aby go odczytać, ale inny wątek już posiada blokadę na wyłączność powodującą konflikt podczas aktualizowania wiersza.
Gdy wątek napotka zapotrzebowanie na zasób, którego nie może uzyskać, nie ma innego wyjścia, jak zatrzymać się i poczekać, aż zasób stanie się dostępny (mechanizm powiadamiania wątku o dostępności zasobu wykracza poza zakres tego artykułu). Kiedy tak się dzieje, SQL Server odnotowuje, dlaczego wątek musiał czekać i nazywa się to typem oczekiwania . Oto kilka przykładów:
- Gdy wątek czeka na wczytanie strony do pamięci, aby można było ją odczytać, typ oczekiwania to PAGEIOLATCH_SH (jeśli wątek czeka na stronę, którą zmieni, typ oczekiwania to PAGEIOLATCH_EX ).
- Gdy wątek czeka na blokadę udziału w wierszu, typ oczekiwania to LCK_M_S (udostępnianie w trybie blokady)
SQL Server śledzi również, jak długo wątek musi czekać. Nazywa się to czasem oczekiwania na zasoby i jest zwykle nazywany po prostu czasem oczekiwania .
Statystyki oczekiwania
Ogólny zestaw metryk tego, ile wątków czekało na jakie zasoby i jak długo, nazywa się statystyką oczekiwania . Informacje te są niezwykle przydatne przy rozwiązywaniu problemów z wydajnością obciążenia, ponieważ można łatwo sprawdzić, gdzie mogą znajdować się wąskie gardła wydajności.
Podstawowa idea polega na tym, że SQL Server posiada informacje o tym, dlaczego wątki muszą się zatrzymywać i czekać oraz na co czekają. Dlatego zamiast zgadywać, od czego zacząć rozwiązywanie problemów, dokładna analiza statystyk oczekiwania może zwykle wskazać kierunek, w którym należy podążać.
Na przykład, jeśli większość czasów oczekiwania na serwerze to PAGEIOLATCH_SH , może to wskazywać, że na serwerze występuje presja pamięci lub że występują zapytania wykonujące skanowanie dużych tabel zamiast korzystania z indeksów nieklastrowanych, lub że występuje problem z podstawowym podsystemem we/wy lub z wielu innych przyczyn.
Istnieje wiele typów oczekiwania, ale większość z nich nie pojawia się zbyt często, więc istnieje zestaw podstawowy, który będziesz widzieć w kółko na swoich serwerach. Zrozumienie, co to znaczy i jak je zbadać, ma kluczowe znaczenie, aby nie ulegać temu, co nazywam „dostrajaniem wydajności pod kątem szarpnięcia za kolano” i tracić czas i wysiłek na naprawienie problemu, który w rzeczywistości nie jest problemem. Napisałem tutaj serię wpisów na blogu, które tam opisują szczegóły, a Aaron Bertrand napisał również wpis podsumowujący 10 najlepszych statystyk oczekiwania w zeszłym roku.
Śledzenie czeka
Istnieje wiele sposobów śledzenia oczekiwania. Najprościej jest sprawdzić, co aktualnie czeka na serwerze za pomocą skryptu, który bada sys.dm_os_waiting_tasks DMV. Możesz znaleźć skrypt, który to zrobi tutaj, i który ma automatycznie wygenerowane adresy URL w bibliotece czekania.
Innym sposobem jest przyjrzenie się zbiorczym statystykom oczekiwania dla całego serwera za pomocą skryptu, który bada sys.dm_os_wait_stats DMV. Możesz znaleźć skrypt, który to zrobi tutaj, i który ma automatycznie wygenerowane adresy URL w bibliotece czekania. Musisz jednak uważać na tę metodę, ponieważ pokaże ona wszystkie oczekiwania, które miały miejsce od momentu uruchomienia serwera. Lepszym sposobem jest śledzenie oczekiwania w krótkich odstępach czasu, powiedzmy pół godziny, a skrypt, który to zrobi, jest tutaj.
Możesz również uzyskać statystyki oczekiwania, korzystając z dodatku Server Reports do nowego narzędzia Azure Data Studio i korzystając z Query Store od SQL Server 2017 i nowszych.
Pamiętaj, że po zebraniu danych nadal musisz zrozumieć, co oznaczają typy oczekiwania.
Zasoby czekania
Aby w tym pomóc, a ponieważ Microsoft nie ma dokumentacji na temat interpretowania statystyk oczekiwania, w 2016 roku wydałem bibliotekę typów oczekiwania, zawierającą szczegółowe informacje o setkach typowych typów oczekiwania i sposobach ich rozwiązywania. Możesz dostać się do biblioteki pod adresem https://www.SQLskills.com/help/waits. A potem w 2017 roku SentryOne stworzył zautomatyzowany system dostarczający infografikę dla każdej strony w bibliotece, który można szybko wykorzystać, aby sprawdzić, czy typ oczekiwania, który Cię interesuje, jest naprawdę powszechny, czy nie (szczegóły w tym poście) . Przykładowa infografika znajduje się poniżej, dla PAGEIOLATCH_SH typ oczekiwania:
Na osi poziomej znajduje się skala (przełączana między liniową i logarytmiczną) procentu instancji (monitorowanych zdalnie przez SentryOne) doświadczyło tego oczekiwania w poprzednim miesiącu kalendarzowym, a na osi pionowej jest procent czasu, przez który te instancje doświadczyły tego wait faktycznie miał wątek oczekujący na ten typ oczekiwania.
Innym źródłem pomocy w zrozumieniu czekania jest kurs szkoleniowy online, który nagrałem dla Pluralsight – zobacz tutaj.
Przynajmniej powinieneś przeczytać różne posty na blogu w powyższych sekcjach Statystyki oczekiwania i Śledzenie oczekiwania.
Śledzenie czeka za pomocą narzędzi SentryOne
SQL Sentry automatycznie śledzi oczekiwania na poziomie instancji w czasie, dzięki czemu nie musisz łapać wysokich oczekiwań „w akcji”. Ktoś skarżył się wczoraj po południu na powolny system lub raport, który wygasł w zeszły wtorek? Nie ma problemu. Możesz zagłębić się we wszystkie oczekiwania na dowolny punkt w czasie lub w zakresie i skorelować je z różnymi innymi metrykami wydajności zebranymi w tym czasie – czy to innymi trendami na pulpicie nawigacyjnym, takimi jak tworzenie kopii zapasowych lub aktywność we/wy bazy danych, przeskakiwanie do wszystkich Polecenia Top SQL, które działały w tym samym oknie, badając długotrwałe blokowanie lub użyj linii bazowych, aby porównać profil oczekiwania z innymi okresami.
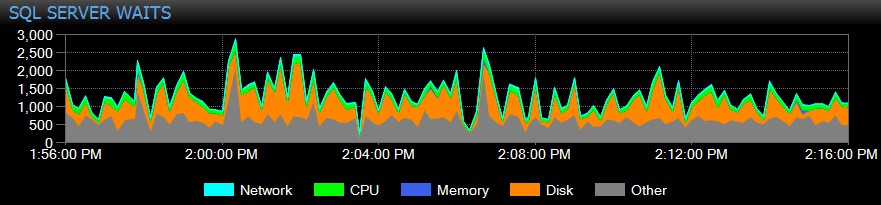
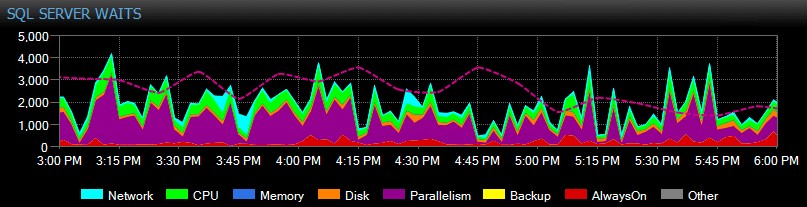
Możesz nawet dostosować oczekiwania, które są zbierane lub nie, zmieniać kategorie, które są prezentowane wizualnie, oraz tworzyć inteligentne alerty i/lub odpowiedzi na określone scenariusze oczekiwania. Wielu naszych klientów używa SQL Sentry, aby skupić się na rzeczywistych problemach z wydajnością związanych z oczekiwaniem, ponieważ pozwala im to zignorować wiele szumów, które są po prostu normalną aktywnością wątków SQL Server.
Podsumowanie
Jak widać z powyższych informacji, oczekiwania zawsze występują w SQL Server, ponieważ tak właśnie działa planowanie wątków i systemy wielowątkowe. Są jednym z najpotężniejszych narzędzi w zestawie narzędzi do rozwiązywania problemów, więc jeśli jeszcze ich nie używasz, nadszedł czas, aby zacząć. Krzywa uczenia się jest krótka i stroma – po kilkukrotnym uruchomieniu różnych zapytań i narzędzi szybko zrozumiesz, a potem jest to przypadek przeczytania przewodników dotyczących czekania, które widzisz i ustalenie, czy jest to problem, czy nie.
Miłego rozwiązywania problemów!