Wprowadzenie
Osiągnięcie minimalnego rejestrowania z INSERT...SELECT może być skomplikowanym biznesem. Rozważania wymienione w Przewodniku wydajności ładowania danych są nadal dość wyczerpujące, chociaż należy również przeczytać SQL Server 2016, Minimalne rejestrowanie i Wpływ rozmiaru wsadowego na operacje ładowania zbiorczego autorstwa Parikshit Savjani z zespołu SQL Server Tiger, aby uzyskać zaktualizowany obraz dla SQL Server 2016 i nowsze podczas ładowania zbiorczego do klastrowanych tabel magazynu wierszy. To powiedziawszy, ten artykuł dotyczy wyłącznie dostarczania nowych szczegółów o minimalnym logowaniu podczas zbiorczego ładowania tradycyjnych (nie „zoptymalizowanych pod kątem pamięci”) tabel stosu przy użyciu INSERT...SELECT . Tabele z indeksem klastrowym b-drzewa są omówione osobno w drugiej części tej serii.
Tabele sterty
Podczas wstawiania wierszy za pomocą INSERT...SELECT do sterty bez indeksów nieklastrowanych, dokumentacja powszechnie stwierdza, że takie wstawki będą rejestrowane w minimalnym stopniu tak długo, jak TABLOCK podpowiedź jest obecna. Jest to odzwierciedlone w tabelach podsumowujących zawartych w Przewodniku po wydajności ładowania danych i post Tiger Team. Wiersze podsumowania tabel sterty bez indeksów są takie same w obu dokumentach (bez zmian dla SQL Server 2016):

Wyraźny TABLOCK wskazówka nie jest jedynym sposobem na spełnienie wymogu blokowania na poziomie tabeli . Możemy również ustawić „blokadę tabeli przy ładowaniu zbiorczym” opcja dla tabeli docelowej przy użyciu sp_tableoption lub przez włączenie udokumentowanej flagi śledzenia 715. (Uwaga:te opcje nie są wystarczające do włączenia minimalnego rejestrowania przy użyciu INSERT...SELECT ponieważ INSERT...SELECT nie obsługuje blokad aktualizacji zbiorczej).
„możliwe równoczesne” kolumna w podsumowaniu dotyczy tylko metod ładowania zbiorczego innych niż INSERT...SELECT . Jednoczesne ładowanie tabeli sterty nie jest możliwe z INSERT...SELECT . Jak wspomniano w Przewodniku wydajności ładowania danych , ładowanie zbiorcze za pomocą INSERT...SELECT bierze na wyłączność X zablokować na stole, a nie aktualizację zbiorczą BU blokada wymagana do równoczesnych ładunków masowych.
Pomijając to wszystko — i zakładając, że nie ma innego powodu, aby nie oczekiwać minimalnego rejestrowania podczas zbiorczego ładowania niezindeksowanej sterty za pomocą TABLOCK (lub odpowiednik) — wstawka nadal może nie być minimalnie zalogowanym…
Wyjątek od reguły
Poniższy skrypt demonstracyjny należy uruchomić na instancji programistycznej w nowej testowej bazie danych ustaw na używanie SIMPLE model odzyskiwania. Ładuje kilka wierszy do tabeli sterty za pomocą INSERT...SELECT z TABLOCK , oraz raporty dotyczące wygenerowanych rekordów dziennika transakcji:
CREATE TABLE dbo.TestHeap
(
id integer NOT NULL IDENTITY,
c1 integer NOT NULL,
padding char(45) NOT NULL
DEFAULT ''
);
GO
-- Clear the log
CHECKPOINT;
GO
-- Insert rows
INSERT dbo.TestHeap WITH (TABLOCK)
(c1)
SELECT TOP (897)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV;
GO
-- Show log entries
SELECT
FD.Operation,
FD.Context,
FD.[Log Record Length],
FD.[Log Reserve],
FD.AllocUnitName,
FD.[Transaction Name],
FD.[Lock Information],
FD.[Description]
FROM sys.fn_dblog(NULL, NULL) AS FD;
GO
-- Count the number of fully-logged rows
SELECT
[Fully Logged Rows] = COUNT_BIG(*)
FROM sys.fn_dblog(NULL, NULL) AS FD
WHERE
FD.Operation = N'LOP_INSERT_ROWS'
AND FD.Context = N'LCX_HEAP'
AND FD.AllocUnitName = N'dbo.TestHeap'; Dane wyjściowe pokazują, że wszystkie 897 wierszy zostało w pełni zarejestrowane pomimo pozornego spełnienia wszystkich warunków minimalnego rejestrowania (tylko próbka zapisów dziennika jest pokazana ze względu na brak miejsca):
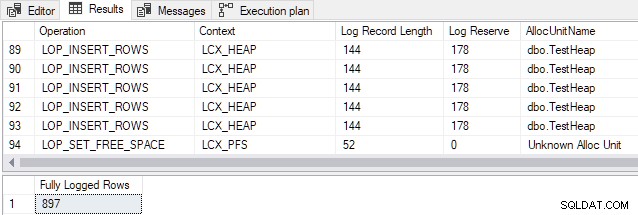
Ten sam wynik jest widoczny, jeśli wstawianie jest powtarzane (tj. Nie ma znaczenia, czy tablica sterty jest pusta, czy nie). Ten wynik jest sprzeczny z dokumentacją.
Minimalny próg rejestrowania dla stert
Liczba wierszy, które należy dodać w jednym INSERT...SELECT oświadczenie o osiągnięciu minimalnego logowania do niezindeksowanej sterty z włączoną blokadą tabeli zależy od obliczeń wykonywanych przez SQL Server podczas szacowania całkowitego rozmiaru danych do wstawienia. Dane wejściowe do tego obliczenia to:
- Wersja SQL Server.
- Szacowana liczba wierszy prowadzących do Wstaw operator.
- Rozmiar wiersza tabeli docelowej.
Dla SQL Server 2012 i wcześniejszych , punkt przejściowy dla tej konkretnej tabeli to 898 wierszy . Zmiana numeru w skrypcie demonstracyjnym TOP klauzula od 897 do 898 daje następujące dane wyjściowe:
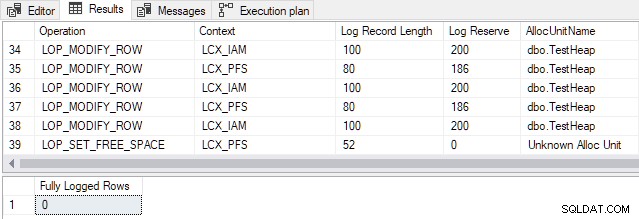
Wygenerowane wpisy dziennika transakcji dotyczą alokacji stron i utrzymania Mapy alokacji indeksów (IAM) i Wolne miejsce na stronie (PFS) struktury. Pamiętaj, że minimalne logowanie oznacza, że SQL Server nie rejestruje każdego wstawienia wiersza osobno. Zamiast tego rejestrowane są tylko zmiany w metadanych i strukturach alokacji. Zmiana z 897 na 898 wierszy włącza minimalne rejestrowanie dla tej konkretnej tabeli.
Dla SQL Server 2014 i nowszych , punkt przejścia to 950 wierszy dla tej tabeli. Uruchamianie INSERT...SELECT z TOP (949) użyje pełnego logowania – zmiana na TOP (950) spowoduje minimalne logowanie .
Progi nie zależne od oszacowania kardynalności używany model lub poziom zgodności bazy danych.
Obliczanie rozmiaru danych
Czy SQL Server zdecyduje się na zbiorcze ładowanie zestawu wierszy — a zatem czy minimalne logowanie jest dostępny lub nie — zależy od wyniku serii obliczeń wykonanych metodą o nazwie sqllang!CUpdUtil::FOptimizeInsert , który zwraca prawdę dla minimalnego rejestrowania lub fałsz do pełnego logowania. Przykładowy stos wywołań pokazano poniżej:
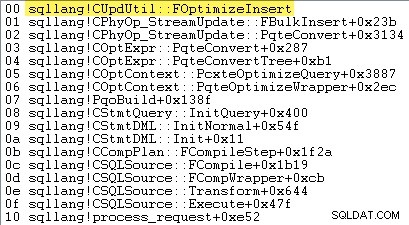
Istotą testu jest:
- Wstawka musi obejmować więcej niż 250 wierszy .
- Całkowity rozmiar wstawianych danych musi być obliczony jako co najmniej 8 stron .
Czek dla więcej niż 250 wierszy zależy wyłącznie od szacowanej liczby wierszy docierających do Wstawka do tabeli operator. Jest to pokazane w planie wykonania jako „Szacowana liczba rzędów” . Bądź z tym ostrożny. Łatwo jest stworzyć plan z niską szacowaną liczbą wierszy, na przykład używając zmiennej w TOP klauzula bez OPTION (RECOMPILE) . W takim przypadku optymalizator odgaduje 100 wierszy, które nie osiągną progu, zapobiegając w ten sposób zbiorczemu ładowaniu i minimalnemu rejestrowaniu.
Obliczenie całkowitego rozmiaru danych jest bardziej złożone i nie pasuje „Szacowany rozmiar wiersza” wpada do wstawki tabeli operator. Sposób wykonywania obliczeń jest nieco inny w SQL Server 2012 i wcześniejszych wersjach w porównaniu z SQL Server 2014 i nowszymi. Mimo to, oba dają wynik rozmiaru wiersza, który różni się od tego, co widać w planie wykonania.
Obliczanie rozmiaru wiersza
Całkowity rozmiar wstawianych danych jest obliczany przez pomnożenie szacowanej liczby wierszy o oczekiwany maksymalny rozmiar wiersza . Obliczanie rozmiaru wiersza to punkt, który różni się między wersjami SQL Server.
W SQL Server 2012 i wcześniejszych obliczenia są wykonywane przez sqllang!OptimizerUtil::ComputeRowLength . Dla tabeli sterty testowej (celowo zaprojektowanej z prostymi kolumnami o stałej długości, niezerowymi, przy użyciu oryginalnej FixedVar format przechowywania wierszy) zarys obliczeń to:
- Zainicjuj FixedVar generator metadanych.
- Uzyskaj informacje o typie i atrybutach dla każdej kolumny w Wstawie tabeli strumień wejściowy.
- Dodaj wpisane kolumny i atrybuty do metadanych.
- Sfinalizuj generator i zapytaj go o maksymalny rozmiar wiersza.
- Dodaj narzut dla pustej mapy bitowej i liczbę kolumn.
- Dodaj cztery bajty dla wiersza bity stanu i przesunięcie wiersza do liczby kolumn danych.
Fizyczny rozmiar wiersza
Można oczekiwać, że wynik tego obliczenia będzie zgodny z fizycznym rozmiarem wiersza, ale tak nie jest. Na przykład przy wyłączonym wersjonowaniu wierszy dla bazy danych:
SELECT
DDIPS.index_type_desc,
DDIPS.alloc_unit_type_desc,
DDIPS.page_count,
DDIPS.record_count,
DDIPS.min_record_size_in_bytes,
DDIPS.max_record_size_in_bytes,
DDIPS.avg_record_size_in_bytes
FROM sys.dm_db_index_physical_stats
(
DB_ID(),
OBJECT_ID(N'dbo.TestHeap', N'U'),
0, -- heap
NULL, -- all partitions
'DETAILED'
) AS DDIPS; …daje rekordową wielkość 60 bajtów w każdym wierszu tabeli testowej:

Jest to opisane w Oszacuj rozmiar sterty:
- Całkowity rozmiar w bajtach wszystkich stałej długości kolumny =53 bajty:
id integer NOT NULL=4 bajtyc1 integer NOT NULL=4 bajtypadding char(45) NOT NULL=45 bajtów.
- Bitmapa zerowa =3 bajty :
- =2 + int((Liczba_kolumn + 7) / 8)
- =2 + wewn.((3 + 7) / 8)
- =3 bajty.
- Nagłówek wiersza =4 bajty .
- Łącznie 53 + 3 + 4 =60 bajtów .
Pasuje również do szacowanego rozmiaru wiersza pokazanego w planie wykonania:

Szczegóły obliczeń wewnętrznych
Wewnętrzne obliczenia używane do określenia, czy używane jest ładowanie zbiorcze, dają inny wynik na podstawie następującego wstaw strumień informacje o kolumnach uzyskane za pomocą debugera. Użyte numery typów pasują do sys.types :
- Łączna stała długość rozmiar kolumny =66 bajtów :
- Wpisz id 173
binary(8)=8 bajtów (wewnętrzne). - Wpisz identyfikator 56
integer=4 bajty (wewnętrzne). - Identyfikator typu 104
bit=1 bajt (wewnętrzny). - Wpisz identyfikator 56
integer=4 bajty (idkolumna). - Wpisz identyfikator 56
integer=4 bajty (c1kolumna). - Wpisz id 175
char(45)=45 bajtów (paddingkolumna).
- Wpisz id 173
- Bitmapa zerowa =3 bajty (jak poprzednio).
- Nagłówek wiersza narzut =4 bajty (jak poprzednio).
- Obliczony rozmiar wiersza =66 + 3 + 4 =73 bajty .
Różnica polega na tym, że strumień wejściowy zasilający wstawkę tabeli operator zawiera trzy dodatkowe kolumny wewnętrzne . Są one usuwane podczas generowania showplanu. Dodatkowe kolumny tworzą lokalizator wstawiania tabeli , który zawiera zakładkę (identyfikator RID lub lokalizator wierszy) jako pierwszy składnik. To są metadane do wstawienia i nie zostanie dodany do tabeli.
Dodatkowe kolumny wyjaśniają rozbieżności między obliczeniami wykonanymi przez OptimizerUtil::ComputeRowLength i fizyczny rozmiar wierszy. Może to być postrzegane jako błąd :SQL Server nie powinien liczyć kolumn metadanych w strumieniu wstawiania do ostatecznego fizycznego rozmiaru wiersza. Z drugiej strony, obliczenia mogą być po prostu oszacowaniem dot. najlepszych starań przy użyciu ogólnej aktualizacji operatora.
Obliczenia nie uwzględniają również innych czynników, takich jak 14-bajtowy narzut wersjonowania wierszy. Można to przetestować, ponownie uruchamiając skrypt demonstracyjny z jedną z izolacji migawki lub przeczytaj izolację zatwierdzonej migawki włączone opcje bazy danych. Fizyczny rozmiar wiersza wzrośnie o 14 bajtów (z 60 bajtów do 74), ale próg minimalnego rejestrowania pozostaje bez zmian przy 898 rzędach.
Obliczanie progów
Mamy teraz wszystkie szczegóły, których potrzebujemy, aby zobaczyć, dlaczego próg wynosi 898 wierszy dla tej tabeli w SQL Server 2012 i wcześniejszych:
- 898 wierszy spełnia pierwsze wymaganie dla ponad 250 wierszy .
- Obliczony rozmiar wiersza =73 bajty.
- Szacowana liczba wierszy =897.
- Całkowity rozmiar danych =73 bajty * 897 wierszy =65481 bajtów.
- Łączna liczba stron =65481 / 8192 =7,9932861328125.
- To jest tuż poniżej drugiego wymagania dla>=8 stron.
- Dla 898 wierszy liczba stron wynosi 8.002197265625.
- To jest >=8 stron więc minimalne logowanie jest aktywowany.
W SQL Server 2014 i nowszych , zmiany to:
- Rozmiar wiersza jest obliczany przez generator metadanych.
- Wewnętrzna kolumna liczb całkowitych w lokatorze tabeli nie jest już obecny w strumieniu wstawiania. To reprezentuje unikacz , który dotyczy tylko indeksów. Wydaje się prawdopodobne, że zostało to usunięte jako naprawa błędu.
- Oczekiwany rozmiar wiersza zmienia się z 73 do 69 bajtów ze względu na pominiętą kolumnę liczb całkowitych (4 bajty).
- Rozmiar fizyczny nadal wynosi 60 bajtów. Pozostała różnica 9 bajtów jest uwzględniana przez dodatkowe 8-bajtowe kolumny RID i 1-bajtowe kolumny wewnętrzne w strumieniu wstawiania.
Aby osiągnąć próg 8 stron z 69 bajtami w wierszu:
- 8 stron * 8192 bajtów na stronę =65536 bajtów.
- 65535 bajtów / 69 bajtów na wiersz =949,9771014492754 wierszy.
- Dlatego spodziewamy się co najmniej 950 wierszy aby włączyć zbiorcze ładowanie zestawu wierszy dla tej tabeli od SQL Server 2014.
Podsumowanie i końcowe przemyślenia
W przeciwieństwie do metod ładowania zbiorczego, które obsługują rozmiar partii , jak opisano w poście przez Parikshita Savjani, INSERT...SELECT w niezindeksowaną stertę (pustą lub nie) nie zawsze skutkuje minimalnym rejestrowaniem, gdy określone jest blokowanie tabeli.
Aby włączyć minimalne logowanie za pomocą INSERT...SELECT , SQL Server musi oczekiwać więcej niż 250 wierszy o łącznym rozmiarze co najmniej jednego zasięgu (8 stron).
Podczas obliczania szacowanego całkowitego rozmiaru wstawiania (w celu porównania z progiem 8 stron) SQL Server mnoży szacowaną liczbę wierszy przez obliczony maksymalny rozmiar wiersza. SQL Server zlicza kolumny wewnętrzne obecne w strumieniu wstawiania podczas obliczania rozmiaru wiersza. W przypadku SQL Server 2012 i wcześniejszych dodaje to 13 bajtów na wiersz. W przypadku SQL Server 2014 i nowszych dodaje 9 bajtów na wiersz. Ma to wpływ tylko na obliczenia; nie wpływa to na ostateczny fizyczny rozmiar wierszy.
Gdy aktywne jest masowe ładowanie sterty z minimalnym rejestrowaniem, SQL Server nie wstawiaj wiersze pojedynczo. Zakresy są przydzielane z wyprzedzeniem, a wiersze do wstawienia są gromadzone na zupełnie nowych stronach przez sqlmin!RowsetBulk przed dodaniem do istniejącej struktury. Przykładowy stos wywołań pokazano poniżej:
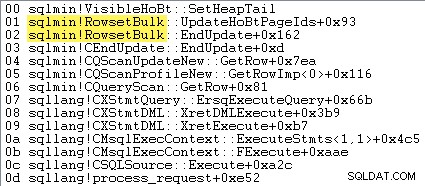
Odczyty logiczne nie są zgłaszane dla tabeli docelowej, gdy używane jest ładowanie zbiorcze sterty z minimalnym logowaniem — wstawka tabeli operator nie musi czytać istniejącej strony, aby zlokalizować punkt wstawiania dla każdego nowego wiersza.
Plany wykonania obecnie nie są wyświetlane ile wierszy lub stron zostało wstawionych przy użyciu ładowania zbiorczego zestawu wierszy i minimalne logowanie . Być może te przydatne informacje zostaną dodane do produktu w przyszłej wersji.