Ten post zawiera nowe informacje o warunkach wstępnych minimalnie rejestrowanego ładowania zbiorczego podczas używania INSERT...SELECT do indeksowanych tabel .
Wewnętrzna funkcja, która umożliwia takie przypadki, nazywa się FastLoadContext . Można go aktywować od SQL Server 2008 do 2014 włącznie za pomocą udokumentowanej flagi śledzenia 610. Od SQL Server 2016 i nowszych, FastLoadContext jest domyślnie włączone; flaga śledzenia nie jest wymagana.
Bez FastLoadContext , jedyne wstawki indeksowe, które można minimalnie rejestrować czy te są w puste indeks skupiony bez indeksów wtórnych, jak opisano w drugiej części tej serii. minimalne logowanie warunki dla nieindeksowanych tabel stosu zostały omówione w części pierwszej.
Aby uzyskać więcej informacji, zobacz Przewodnik ładowania wydajności danych i zespół Tiger uwagi dotyczące zmian w zachowaniu SQL Server 2016.
Kontekst szybkiego ładowania
Jako szybkie przypomnienie, RowsetBulk funkcja (opisana w częściach 1 i 2) umożliwia minimalne logowanie ładunek zbiorczy dla:
- Pusty i niepusty sterta tabele z:
- Blokowanie tabeli; i
- Brak wtórnych indeksów.
- Puste tabele klastrowe , z:
- Blokowanie tabeli; i
- Brak indeksów wtórnych; i
DMLRequestSort=truena wstawce z indeksem klastrowym operator.
FastLoadContext ścieżka kodu dodaje obsługę minimalnie rejestrowanych i równoczesne ładunek zbiorczy na:
- Pusty i niepusty zgrupowany indeksy b-drzewa.
- Pusty i niepusty niezgrupowany indeksy b-drzewa utrzymywane przez dedykowane Wstawka indeksująca operator planu.
FastLoadContext wymaga również DMLRequestSort=true we wszystkich przypadkach na odpowiednim operatorze planu.
Być może zauważyłeś nakładanie się między RowsetBulk i FastLoadContext dla pustych tabel klastrowych bez indeksów wtórnych. TABLOCK podpowiedź nie jest wymagana z FastLoadContext , ale nie musi być nieobecne zarówno. W konsekwencji odpowiednia wstawka z TABLOCK może nadal kwalifikować się do minimalnego logowania przez FastLoadContext jeśli nie powiedzie się, szczegółowy RowsetBulk testy.
FastLoadContext można wyłączyć na SQL Server 2016 przy użyciu udokumentowanej flagi śledzenia 692. Kanał debugowania Extended Event fastloadcontext_enabled może być używany do monitorowania FastLoadContext użycie na partycję indeksu (zestaw wierszy). To zdarzenie nie uruchamia się dla RowsetBulk ładunki.
Mieszane rejestrowanie
Pojedynczy INSERT...SELECT instrukcja przy użyciu FastLoadContext może w pełni zalogować kilka wierszy podczas minimalnego logowania inne.
Wiersze są wstawiane jeden na raz przez wstawkę indeksującą operator i w pełni zalogowany w następujących przypadkach:
- Wszystkie wiersze dodane do pierwszego strona indeksu, jeśli indeks był pusty na początku operacji.
- Wiersze dodane do istniejących indeksuj strony.
- Wiersze przeniesione między stronami według podziału strony.
W przeciwnym razie wiersze z uporządkowanego strumienia wstawiania są dodawane do nowej strony przy użyciu zoptymalizowanego i minimalnie rejestrowanego ścieżka kodu. Po zapisaniu jak największej liczby wierszy na nowej stronie jest ona bezpośrednio połączona z istniejącą docelową strukturą indeksu.
Nowo dodana strona niekoniecznie być pełny (choć oczywiście jest to idealny przypadek), ponieważ SQL Server musi uważać, aby nie dodawać wierszy do nowej strony, które logicznie należą do istniejącego strona indeksu. Nowa strona zostanie „włączona” do indeksu jako jednostka, więc nie możemy mieć żadnych wierszy na nowej stronie, które należą do innego miejsca. Jest to głównie problem podczas dodawania wierszy w istniejącego zakresu kluczy indeksu, a nie przed początkiem lub po końcu istniejącego zakresu kluczy indeksu.
To nadal możliwe dodawać nowe strony w istniejący zakres kluczy indeksu, ale nowe wiersze muszą być sortowane wyżej niż najwyższy klucz w poprzednim istniejąca strona indeksu i sortuj niżej niż najniższy klucz w następujących istniejąca strona indeksu. Aby uzyskać największą szansę na osiągnięcie minimalnego rejestrowania w takich okolicznościach upewnij się, że wstawione wiersze nie pokrywają się z istniejącymi wierszami, o ile to możliwe.
Warunki DMLRequestSort
Pamiętaj, że FastLoadContext można aktywować tylko wtedy, gdy DMLRequestSort ma wartość prawda dla odpowiedniej wstawki indeksu operatora w planie wykonania.
Istnieją dwie główne ścieżki kodu, które można ustawić DMLRequestSort do prawdy na płytki indeksowe. Każda ścieżka zwracanie prawdy wystarczy.
1. FOptimizeInsert
sqllang!CUpdUtil::FOptimizeInsert kod wymaga:
- Ponad 250 wierszy szacowany do wstawienia; i
- Więcej niż 2 strony szacowany wstaw rozmiar danych; i
- Indeks docelowy musi mieć mniej niż 3 strony liści .
Te warunki są takie same jak w przypadku RowsetBulk na pustym indeksie klastrowym, z dodatkowym wymaganiem nie więcej niż dwóch indeksowanych stron na poziomie liścia. Zwróć uwagę, że odnosi się to do rozmiaru istniejącego indeksu przed wstawką, nie szacowany rozmiar danych do dodania.
Poniższy skrypt jest modyfikacją wersji demonstracyjnej używanej we wcześniejszych częściach tej serii. Pokazuje minimalne logowanie gdy mniej niż trzy strony indeksu są wypełnione przed test INSERT...SELECT biegi. Schemat tabeli testowej jest taki, że 130 wierszy może zmieścić się na jednej stronie o wielkości 8 KB, gdy wersja wierszy jest wyłączona dla bazy danych. Mnożnik w pierwszym TOP klauzulę można zmienić, aby określić liczbę istniejących stron indeksowych przed test INSERT...SELECT jest wykonywany:
IF OBJECT_ID(N'dbo.Test', N'U') IS NOT NULL
BEGIN
DROP TABLE dbo.Test;
END;
GO
CREATE TABLE dbo.Test
(
id integer NOT NULL IDENTITY
CONSTRAINT [PK dbo.Test (id)]
PRIMARY KEY,
c1 integer NOT NULL,
padding char(45) NOT NULL
DEFAULT ''
);
GO
-- 130 rows per page for this table
-- structure with row versioning off
INSERT dbo.Test
(c1)
SELECT TOP (3 * 130) -- Change the 3 here
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV;
GO
-- Show physical index statistics
-- to confirm the number of pages
SELECT
DDIPS.index_type_desc,
DDIPS.alloc_unit_type_desc,
DDIPS.page_count,
DDIPS.record_count,
DDIPS.avg_record_size_in_bytes
FROM sys.dm_db_index_physical_stats
(
DB_ID(),
OBJECT_ID(N'dbo.Test', N'U'),
1, -- Index ID
NULL, -- Partition ID
'DETAILED'
) AS DDIPS
WHERE
DDIPS.index_level = 0; -- leaf level only
GO
-- Clear the plan cache
DBCC FREEPROCCACHE;
GO
-- Clear the log
CHECKPOINT;
GO
-- Main test
INSERT dbo.Test
(c1)
SELECT TOP (269)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV;
GO
-- Show log entries
SELECT
FD.Operation,
FD.Context,
FD.[Log Record Length],
FD.[Log Reserve],
FD.AllocUnitName,
FD.[Transaction Name],
FD.[Lock Information],
FD.[Description]
FROM sys.fn_dblog(NULL, NULL) AS FD;
GO
-- Count the number of fully-logged rows
SELECT
[Fully Logged Rows] = COUNT_BIG(*)
FROM sys.fn_dblog(NULL, NULL) AS FD
WHERE
FD.Operation = N'LOP_INSERT_ROWS'
AND FD.Context = N'LCX_CLUSTERED'
AND FD.AllocUnitName = N'dbo.Test.PK dbo.Test (id)';
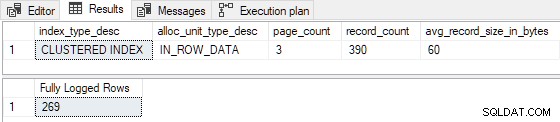
GO Gdy indeks klastrowy jest wstępnie załadowany 3 stronami , wkładka testowa jest w pełni zarejestrowana (rekordy szczegółów dziennika transakcji pominięte z powodu zwięzłości):
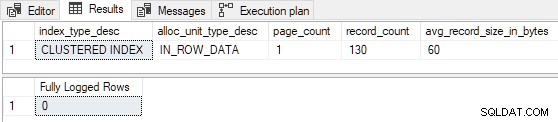
Gdy tabela jest wstępnie załadowana tylko 1 lub 2 stronami , wkładka testowa jest minimalnie rejestrowana :
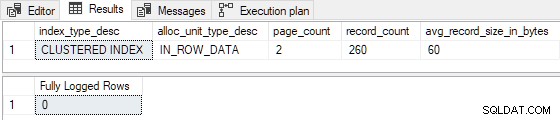
Gdy tabela nie jest wstępnie załadowana z dowolnymi stronami test jest równoważny uruchomieniu demonstracji pustej tabeli klastrowej z części drugiej, ale bez TABLOCK wskazówka:
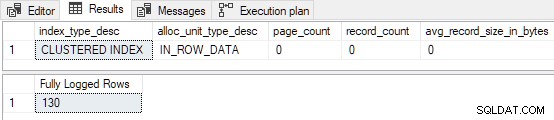
Pierwsze 130 wierszy jest w pełni zalogowanych . Dzieje się tak, ponieważ indeks był pusty, zanim zaczęliśmy, a 130 wierszy zmieściło się na pierwszej stronie. Pamiętaj, że pierwsza strona jest zawsze w pełni rejestrowana, gdy FastLoadContext jest używany, a indeks był wcześniej pusty. Pozostałe 139 wierszy jest wstawianych z minimalnym rejestrowaniem .
Jeśli TABLOCK wskazówka jest dodawana do wkładki, wszystkie strony są minimalnie rejestrowane (w tym pierwszy), ponieważ puste ładowanie indeksu klastrowego kwalifikuje się teraz do RowsetBulk mechanizm (kosztem pobrania Sch-M zamek).
2. FDemandRowsSortedForPerformance
Jeśli FOptimizeInsert testy nie powiodły się, DMLRequestSort może nadal mieć wartość prawda przez drugi zestaw testów w sqllang!CUpdUtil::FDemandRowsSortedForPerformance kod. Te warunki są nieco bardziej złożone, więc przydatne będzie zdefiniowanie niektórych parametrów:
P– liczba istniejących stron na poziomie liścia w indeksie docelowym .I– szacowany liczba wierszy do wstawienia.R=P/I(docelowe strony na wstawiony wiersz).T– liczba partycji docelowych (1 dla niepartycjonowanych).
Logika do określenia wartości DMLRequestSort jest wtedy:
- Jeśli
P <= 16zwróć fałsz , w przeciwnym razie :- Jeśli
R < 8:- Jeśli
P > 524zwróć prawda , w przeciwnym razie fałsz .
- Jeśli
- Jeśli
R >= 8:- Jeśli
T > 1iI > 250zwróć prawda , w przeciwnym razie fałsz .
- Jeśli
- Jeśli
Powyższe testy są oceniane przez procesor zapytań podczas kompilacji planu. Istnieje warunek końcowy oceniane przez kod silnika pamięci masowej (IndexDataSetSession::WakeUpInternal ) w czasie wykonania:
DMLRequestSortjest obecnie prawda; iI >= 100.
Następnie podzielimy całą tę logikę na łatwe do opanowania części.
Ponad 16 istniejących stron docelowych
Pierwszy test P <= 16 oznacza, że indeksy z mniej niż 17 istniejącymi stronami-liście nie będą kwalifikować się do FastLoadContext za pośrednictwem tej ścieżki kodu. Aby być całkowicie jasnym w tej kwestii, P to liczba stron na poziomie liścia w indeksie docelowym przed INSERT...SELECT jest wykonywany.
Aby zademonstrować tę część logiki, wstępnie załadujemy testową tabelę klastrową z 16 stronami danych. Ma to dwa ważne efekty (pamiętaj, że obie ścieżki kodu muszą zwracać false skończyć z fałszem wartość dla DMLRequestSort ):
- Zapewnia, że poprzedni
FOptimizeInserttest nie powiodło się , ponieważ trzeci warunek nie jest spełniony (P < 3). P <= 16warunek wFDemandRowsSortedForPerformancerównież nie być spełnione.
Dlatego oczekujemy FastLoadContext nie włączać. Zmodyfikowany skrypt demonstracyjny to:
IF OBJECT_ID(N'dbo.Test', N'U') IS NOT NULL
BEGIN
DROP TABLE dbo.Test;
END;
GO
CREATE TABLE dbo.Test
(
id integer NOT NULL IDENTITY
CONSTRAINT [PK dbo.Test (id)]
PRIMARY KEY,
c1 integer NOT NULL,
padding char(45) NOT NULL
DEFAULT ''
);
GO
-- 130 rows per page for this table
-- structure with row versioning off
INSERT dbo.Test
(c1)
SELECT TOP (16 * 130) -- 16 pages
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV;
GO
-- Show physical index statistics
-- to confirm the number of pages
SELECT
DDIPS.index_type_desc,
DDIPS.alloc_unit_type_desc,
DDIPS.page_count,
DDIPS.record_count,
DDIPS.avg_record_size_in_bytes
FROM sys.dm_db_index_physical_stats
(
DB_ID(),
OBJECT_ID(N'dbo.Test', N'U'),
1, -- Index ID
NULL, -- Partition ID
'DETAILED'
) AS DDIPS
WHERE
DDIPS.index_level = 0; -- leaf level only
GO
-- Clear the plan cache
DBCC FREEPROCCACHE;
GO
-- Clear the log
CHECKPOINT;
GO
-- Main test
INSERT dbo.Test
(c1)
SELECT TOP (269)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2;
GO
-- Show log entries
SELECT
FD.Operation,
FD.Context,
FD.[Log Record Length],
FD.[Log Reserve],
FD.AllocUnitName,
FD.[Transaction Name],
FD.[Lock Information],
FD.[Description]
FROM sys.fn_dblog(NULL, NULL) AS FD;
GO
-- Count the number of fully-logged rows
SELECT
[Fully Logged Rows] = COUNT_BIG(*)
FROM sys.fn_dblog(NULL, NULL) AS FD
WHERE
FD.Operation = N'LOP_INSERT_ROWS'
AND FD.Context = N'LCX_CLUSTERED'
AND FD.AllocUnitName = N'dbo.Test.PK dbo.Test (id)'; Wszystkie 269 wierszy jest w pełni rejestrowane zgodnie z przewidywaniami:
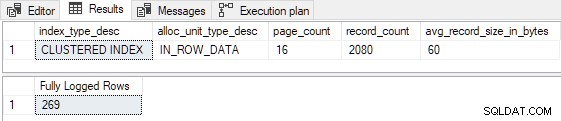
Pamiętaj, że bez względu na to, jak wysoko ustawimy liczbę nowych wierszy do wstawienia, powyższy skrypt nigdy produkować minimalne logowanie ze względu na P <= 16 test (i P < 3 test w FOptimizeInsert ).
Jeśli zdecydujesz się uruchomić demo samodzielnie z większą liczbą wierszy, skomentuj sekcję, która pokazuje poszczególne zapisy dziennika transakcji, w przeciwnym razie będziesz czekać bardzo długo, a SSMS może się zawiesić. (Szczerze mówiąc, i tak może to zrobić, ale po co zwiększać ryzyko).
Stosunek stron na wstawiony wiersz
Jeśli jest 17 lub więcej strony liści w istniejącym indeksie, poprzednie P <= 16 test nie zawiedzie. Następna sekcja logiki dotyczy proporcji istniejących stron do nowo wstawionych wierszy . To również musi przejść, aby osiągnąć minimalne logowanie . Przypominamy, że odpowiednie warunki to:
- Współczynnik
R=P/I. - Jeśli
R < 8:- Jeśli
P > 524zwróć prawda , w przeciwnym razie fałsz .
- Jeśli
Musimy również pamiętać o ostatecznym teście silnika pamięci masowej dla co najmniej 100 wierszy:
I >= 100.
Nieco reorganizując te warunki, wszystkie z następujących musi być prawdziwe:
P > 524(istniejące strony indeksu)I >= 100(szacunkowa liczba wstawionych wierszy)P / I < 8(stosunekR)
Istnieje wiele sposobów na jednoczesne spełnienie tych trzech warunków. Wybierzmy minimalne możliwe wartości dla P (525) i I (100) dając R wartość (525/100) =5,25. To spełnia (R < 8 test), więc spodziewamy się, że ta kombinacja spowoduje minimalne rejestrowanie :
IF OBJECT_ID(N'dbo.Test', N'U') IS NOT NULL
BEGIN
DROP TABLE dbo.Test;
END;
GO
CREATE TABLE dbo.Test
(
id integer NOT NULL IDENTITY
CONSTRAINT [PK dbo.Test (id)]
PRIMARY KEY,
c1 integer NOT NULL,
padding char(45) NOT NULL
DEFAULT ''
);
GO
-- 130 rows per page for this table
-- structure with row versioning off
INSERT dbo.Test
(c1)
SELECT TOP (525 * 130) -- 525 pages
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2;
GO
-- Show physical index statistics
-- to confirm the number of pages
SELECT
DDIPS.index_type_desc,
DDIPS.alloc_unit_type_desc,
DDIPS.page_count,
DDIPS.record_count,
DDIPS.avg_record_size_in_bytes
FROM sys.dm_db_index_physical_stats
(
DB_ID(),
OBJECT_ID(N'dbo.Test', N'U'),
1, -- Index ID
NULL, -- Partition ID
'DETAILED'
) AS DDIPS
WHERE
DDIPS.index_level = 0; -- leaf level only
GO
-- Clear the plan cache
DBCC FREEPROCCACHE;
GO
-- Clear the log
CHECKPOINT;
GO
-- Main test
INSERT dbo.Test
(c1)
SELECT TOP (100)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2;
GO
-- Show log entries
SELECT
FD.Operation,
FD.Context,
FD.[Log Record Length],
FD.[Log Reserve],
FD.AllocUnitName,
FD.[Transaction Name],
FD.[Lock Information],
FD.[Description]
FROM sys.fn_dblog(NULL, NULL) AS FD;
GO
-- Count the number of fully-logged rows
SELECT
[Fully Logged Rows] = COUNT_BIG(*)
FROM sys.fn_dblog(NULL, NULL) AS FD
WHERE
FD.Operation = N'LOP_INSERT_ROWS'
AND FD.Context = N'LCX_CLUSTERED'
AND FD.AllocUnitName = N'dbo.Test.PK dbo.Test (id)';
100-wierszowy INSERT...SELECT jest rzeczywiście minimalnie rejestrowany :
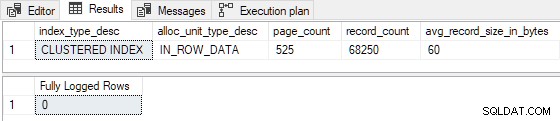
Zmniejszenie szacowanego wstawiono wiersze do 99 (przełamując I >= 100 ) i/lub zmniejszenie liczby istniejących stron indeksowych do 524 (przerywanie P > 524 ) powoduje pełne rejestrowanie . Moglibyśmy również wprowadzić zmiany takie, że R wynosi nie mniej niż 8, aby uzyskać pełne logowanie . Na przykład ustawienie P = 1000 i I = 125 daje R = 8 , z następującymi wynikami:
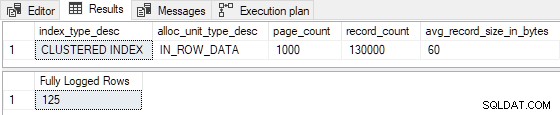
125 wstawionych wierszy zostało w pełni zalogowanych zgodnie z oczekiwaniami. (Nie jest to spowodowane pełnym logowaniem pierwszej strony, ponieważ indeks nie był wcześniej pusty).
Stosunek stron dla indeksów partycjonowanych
Jeśli wszystkie poprzednie testy zakończą się niepowodzeniem, jeden pozostały test wymaga R >= 8 i może tylko być spełnione, gdy liczba partycji (T ) jest większe niż 1 i jest ponad 250 szacowanych wstawione wiersze (I ). Przypomnij:
- Jeśli
R >= 8:- Jeśli
T > 1iI > 250zwróć prawda , w przeciwnym razie fałsz .
- Jeśli
Jedna subtelność:dla partycjonowanych indeksów, reguła, która mówi, że wszystkie wiersze na pierwszej stronie są w pełni rejestrowane (dla początkowo pustego indeksu) ma zastosowanie na partycję . W przypadku obiektu z 15 000 partycjami oznacza to 15 000 w pełni zalogowanych „pierwszych” stron.
Podsumowanie i końcowe przemyślenia
Formuły i kolejność oceny opisane w treści bazują na kontroli kodu za pomocą debuggera. Zostały one przedstawione w formie, która ściśle odzwierciedla czas i kolejność użyte w prawdziwym kodzie.
Można nieco zmienić kolejność i uprościć te warunki, aby uzyskać bardziej zwięzłe podsumowanie praktycznych wymagań dotyczących minimalnego rejestrowania podczas wstawiania do b-drzewa za pomocą INSERT...SELECT . Poniższe udoskonalone wyrażenia wykorzystują następujące trzy parametry:
P=liczba istniejących indeksuj strony na poziomie liścia.I=szacowany liczba wierszy do wstawienia.S=szacowany wstaw rozmiar danych na stronach 8KB.
Zbiorcze ładowanie zestawu wierszy
- Używa
sqlmin!RowsetBulk. - Wymaga pustego klastrowany cel indeksu z
TABLOCK(lub odpowiednik). - Wymaga
DMLRequestSort = truena wstawce z indeksem klastrowym operator. DMLRequestSortjest ustawiona natruejeśliI > 250iS > 2.- Wszystkie wstawione wiersze są minimalnie rejestrowane .
Sch-Mblokada uniemożliwia równoczesny dostęp do tabeli.
Kontekst szybkiego ładowania
- Używa
sqlmin!FastLoadContext. - Włącza minimalnie rejestrowane wstawia do indeksów b-drzewa:
- Sklastrowane lub nieklastrowe.
- Z blokadą stołu lub bez.
- Indeks docelowy jest pusty lub nie.
- Wymaga
DMLRequestSort = truena powiązanej wstawce indeksu operator planu. - Tylko wiersze zapisywane na nowych stronach są ładowane zbiorczo i minimalnie rejestrowane .
- Pierwsza strona poprzednio pustego indeksu partycja jest zawsze w pełni zalogowana .
- Absolutne minimum
I >= 100. - Wymaga flagi śledzenia 610 przed SQL Server 2016.
- Domyślnie dostępne od SQL Server 2016 (flaga śledzenia 692 wyłącza).
DMLRequestSort jest ustawiona na true dla:
- Dowolny indeks (partycjonowane lub nie), jeśli:
I > 250iP < 3iS > 2; lubI >= 100iP > 524iP < I * 8
Dla tylko indeksów partycjonowanych (z> 1 partycją), DMLRequestSort jest również ustawiona na true jeśli:
I > 250iP > 16iP >= I * 8
Istnieje kilka interesujących przypadków wynikających z tych FastLoadContext warunki:
- Wszystkie wstawia do niepartycjonowanego indeks z od 3 do 524 (włącznie) istniejące strony liści będą w pełni rejestrowane niezależnie od liczby i całkowitego rozmiaru dodanych wierszy. Najbardziej zauważalnie wpłynie to na duże wstawki do małych (ale nie pustych) tabel.
- Wszystkie wstawia do partycjonowanej indeks z od 3 do 16 istniejące strony będą w pełni rejestrowane .
- Duże wstawki za duże bez partycji indeksy nie mogą być minimalnie rejestrowane z powodu nierówności
P < I * 8. KiedyPjest duży, odpowiednio duży szacowany liczba wstawionych wierszy (I) jest wymagane. Na przykład indeks z 8 milionami stron nie obsługuje minimalnego rejestrowania podczas wstawiania 1 miliona wierszy lub mniej.
Indeksy nieklastrowane
Te same uwagi i obliczenia, które zastosowano do indeksów klastrowych w prezentacjach, dotyczą nieklastrowanych indeksy b-drzewa, o ile indeks jest utrzymywany przez dedykowanego operatora planu (szeroki lub na indeks plan). Indeksy nieklastrowane obsługiwane przez podstawowy operator tabeli (np. Wstawka indeksu klastrowego ) nie kwalifikują się do FastLoadContext .
Pamiętaj, że parametry formuły muszą być oceniane od nowa dla każdego nieklastrowanego operator indeksu — obliczony rozmiar wiersza, liczba istniejących stron indeksu i oszacowanie liczności.
Uwagi ogólne
Uważaj na szacunki o niskiej kardynalności przy wstawce indeksu operatora, ponieważ wpłyną one na I i S parametry. Jeśli próg nie zostanie osiągnięty z powodu błędu oszacowania liczności, wstawka zostanie w pełni zarejestrowana .
Pamiętaj, że DMLRequestSort jest buforowany z planem — nie jest oceniany przy każdym wykonaniu ponownie wykorzystanego planu. Może to wprowadzić formę dobrze znanego problemu z wrażliwością parametrów (znanego również jako „podsłuchiwanie parametrów”).
Wartość P (indeksowe strony liści) nie jest odświeżany na początku każdego oświadczenia. Obecna implementacja buforuje wartość dla całej partii . Może to mieć nieoczekiwane skutki uboczne. Na przykład TRUNCATE TABLE w tej samej partii jako INSERT...SELECT nie zresetuje P do zera dla obliczeń opisanych w tym artykule — będą nadal używać wartości sprzed przycięcia, a ponowna kompilacja nie pomoże. Rozwiązaniem jest przesyłanie dużych zmian w oddzielnych partiach.
Flagi śledzenia
Możliwe jest wymuszenie FDemandRowsSortedForPerformance aby zwrócić prawdę ustawiając nieudokumentowane i nieobsługiwane trace flag 2332, jak pisałem w Optymalizacji zapytań T-SQL, które zmieniają dane. Gdy TF 2332 jest aktywny, szacunkowa liczba wierszy do wstawienia nadal musi wynosić co najmniej 100 . TF 2332 wpływa na minimalne logowanie decyzja dla FastLoadContext tylko (działa to dla stosów partycjonowanych do DMLRequestSort dotyczy, ale nie ma wpływu na sam stos, ponieważ FastLoadContext dotyczy tylko indeksów).
szeroki/na indeks kształt planu dla konserwacji indeksu nieklastrowanego może być wymuszony dla tabel magazynu wierszy przy użyciu flagi śledzenia 8790 (nie jest to oficjalnie udokumentowane, ale wspomniane w artykule z bazy wiedzy Knowledge Base, a także w moim artykule jako link do TF2332 tuż powyżej).
Powiązane czytanie
Wszystko autorstwa Sunila Agarwala z zespołu SQL Server:
- Co to są optymalizacje importu zbiorczego?
- Optymalizacja importu zbiorczego (minimalne rejestrowanie)
- Minimalne zmiany rejestrowania w SQL Server 2008
- Minimalne zmiany rejestrowania w SQL Server 2008 (część 2)
- Minimalne zmiany rejestrowania w SQL Server 2008 (część 3)