[ Część 1 | Część 2 | Część 3 ]
Ostatnio ktoś w pracy poprosił o więcej miejsca na szybko rosnący stół. W tym czasie miał 3,75 miliarda wierszy, prezentowanych na 143 milionach stron i zajmujących ~1,14 TB. Oczywiście zawsze możemy rzucić więcej dysków na stół, ale chciałem zobaczyć, czy możemy skalować to wydajniej niż obecny trend liniowy. Brzmi jak świetna robota do kompresji, prawda? Ale chciałem też wypróbować kilka innych rozwiązań, w tym columnstore – którego ludzie zaskakująco niechętnie próbują. Nie jestem Niko, ale chciałem się postarać, aby zobaczyć, co może tu dla nas zrobić.
Pamiętaj, że w tej chwili nie skupiam się na raportowaniu obciążenia lub wydajności innych zapytań odczytu – chcę tylko zobaczyć, jaki wpływ mogę mieć na wykorzystanie pamięci (i pamięci) tych danych.
Oto oryginalny stół. Zmieniłem nazwy tabel i kolumn, aby chronić niewinnych, ale wszystko inne jest stosunkowo dokładne.
CREATE TABLE dbo.tblOriginal
(
OID bigint IDENTITY(1,1) NOT NULL PRIMARY KEY, -- there are gaps!
IN1 int NOT NULL,
IN2 int NOT NULL,
VC1 varchar(3) NULL,
BI1 bigint NULL,
IN3 int NULL,
VC2 varchar(128) NOT NULL,
VC3 varchar(128) NOT NULL,
VC4 varchar(128) NULL,
NM1 numeric(24,12) NULL,
NM2 numeric(24,12) NULL,
NM3 numeric(24,12) NULL,
BI2 bigint NULL,
IN4 int NULL,
BI3 bigint NULL,
NM4 numeric(24,12) NULL,
IN5 int NULL,
NM5 numeric(24,12) NULL,
DT1 date NULL,
VC5 varchar(128) NULL,
BI4 bigint NULL,
BI5 bigint NULL,
BI6 bigint NULL,
BT1 bit NOT NULL,
NV1 nvarchar(512) NULL,
VB1 AS (HASHBYTES('MD5',VC2+VC3)),
IN6 int NULL,
IN7 int NULL,
IN8 int NULL
);
Jest tam kilka innych drobiazgów, które są szersze niż powinny i/lub kompresja wierszy może zostać oczyszczona, na przykład te numeric(24,12) i bigint kolumny, które mogą być przedwcześnie przewymiarowane, ale nie zamierzam wracać do zespołu aplikacji i sprawdzać, czy jest tam niewielka wydajność, i pominę kompresję wierszy w tym ćwiczeniu i skoncentruję się na kompresji strony i magazynu kolumn.
Jest to kopia danych na bezczynnym serwerze (8 rdzeni, 64 GB RAM), z dużą ilością miejsca na dysku (znacznie ponad 6 TB). Więc najpierw dodajmy kilka grup plików, jedną dla standardowego klastrowanego magazynu kolumn i jedną dla partycjonowanej wersji tabeli (gdzie wszystkie partycje oprócz najnowszej zostaną skompresowane za pomocą COLUMNSTORE_ARCHIVE , ponieważ wszystkie te starsze dane są teraz „tylko do odczytu i rzadko”):
ALTER DATABASE OCopy ADD FILEGROUP FG_CCI; ALTER DATABASE OCopy ADD FILEGROUP FG_CCI_PARTITIONED;
A potem kilka plików dla tych grup plików (jeden plik na rdzeń, ładny i jednorodny rozmiar przy 256 GB):
ALTER DATABASE OCopy ADD FILE (name = N'CCI_1', size = 250000, filename = 'K:\Data\o_cci_1.mdf') TO FILEGROUP FG_CCI; -- ... 6 more ... ALTER DATABASE OCopy ADD FILE (name = N'CCI_8', size = 250000, filename = 'K:\Data\o_cci_8.mdf') TO FILEGROUP FG_CCI; ALTER DATABASE OCopy ADD FILE (name = N'CCI_P_1', size = 250000, filename = 'K:\Data\o_p_1.mdf') TO FILEGROUP FG_CCI_PARTITIONED; -- ... 6 more ... ALTER DATABASE OCopy ADD FILE (name = N'CCI_P_8', size = 250000, filename = 'K:\Data\o_p_8.mdf') TO FILEGROUP FG_CCI_PARTITIONED;
Na tym konkretnym sprzęcie (YMMV!) zajęło to około 10 sekund na plik i dało następujące wyniki:
Aby wygenerować partycje, naiwnie podzieliłem dane „równomiernie” – a przynajmniej tak mi się wydawało. Właśnie wziąłem 3,75 miliarda wierszy i podzieliłem na coś, co wydawało mi się możliwe do opanowania:38 partycji ze 100 milionami wierszy w pierwszych 37 partycjach, a reszta w ostatniej. (Pamiętaj, że to tylko część 1! Istnieje nieodłączne założenie o równomiernym rozkładzie wartości w tabeli źródłowej, a także wokół tego, co jest optymalne dla populacji wierszy w tabeli docelowej.) Tworzenie schematu partycji i funkcji dla tego jest tak następuje:
CREATE PARTITION FUNCTION PF_OID([bigint]) AS RANGE LEFT FOR VALUES (100000000, 200000000, /* ... 33 more ... */ , 3600000000, 3700000000); CREATE PARTITION SCHEME PS_OID AS PARTITION PF_OID ALL TO (FG_CCI_PARTITIONED);
Używam RANGE LEFT ponieważ, jak wciąż przypomina mi Cathrine Wilhelmsen, oznacza to, że wartość graniczna jest częścią przegrody po jej lewej stronie. Innymi słowy, wartości, które określam, są maksymalnymi wartościami w każdej partycji (w przypadku dat zwykle chcesz RANGE RIGHT ).
Następnie utworzyłem dwie kopie tabeli, po jednej na każdej grupie plików. Pierwszy z nich miał standardowy klastrowany indeks magazynu kolumn, jedyne różnice to OID kolumna nie jest IDENTITY a wyliczona kolumna to po prostu varbinary(8000) :
CREATE TABLE dbo.tblCCI ( OID bigint NOT NULL, -- ... other columns ... ) ON FG_CCI; GO CREATE CLUSTERED COLUMNSTORE INDEX CCI_IX ON dbo.tblCCI;
Drugi został zbudowany na schemacie partycji, więc najpierw potrzebował nazwanego PK, który następnie musiał zostać zastąpiony klastrowanym indeksem magazynu kolumn (chociaż Brent Ozar pokazuje w tym krótkim poście, że istnieje pewna nieintuicyjna składnia, która umożliwi to w mniejszej liczbie kroków ):
CREATE TABLE dbo.tblCCI_Partitioned ( OID bigint NOT NULL, -- ... other columns ..., CONSTRAINT PK_CCI_Part PRIMARY KEY CLUSTERED (OID) ON PS_OID (OID) ); GO ALTER TABLE dbo.tblCCI_Partitioned DROP CONSTRAINT PK_CCI_Part; GO CREATE CLUSTERED COLUMNSTORE INDEX CCI_Part ON dbo.tblCCI_Partitioned ON PS_OID (OID);
Następnie, aby umieścić kompresję archiwum na wszystkich partycjach oprócz ostatniej, uruchomiłem następujące polecenie:
ALTER TABLE dbo.tblCCI_Part
REBUILD PARTITION = ALL WITH
(
DATA_COMPRESSION = COLUMNSTORE ON PARTITIONS (38),
DATA_COMPRESSION = COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TO 37)
); Teraz byłem gotów wypełnić te tabele danymi, zmierzyć czas i wynikowy rozmiar oraz porównać. Zmodyfikowałem pomocny skrypt wsadowy Andy'ego Mallona i wstawiłem wiersze do obu tabel po kolei, z rozmiarem partii 10 milionów wierszy. W prawdziwym skrypcie jest o wiele więcej (w tym aktualizacja tabeli kolejki z postępem), ale w zasadzie:
DECLARE @BatchSize int = 10000000, @MaxID bigint, @LastID bigint = 0;
SELECT @MaxID = MAX(OID) FROM dbo.tblOriginal;
WHILE @LastID < @MaxID
BEGIN
INSERT dbo.tblCCI
(
-- all columns except the computed column
)
SELECT -- all columns except the computed column
FROM dbo.tblOriginal AS o
WHERE o.CostID >= @LastID
AND o.CostID < @LastID + @BatchSize;
SET @LastID += @BatchSize;
END Po zapełnieniu obu tabel magazynu kolumn z oryginalnego (nieskompresowanego) źródła, ponownie odbudowałem te partycje, aby wyczyścić bałagan w grupach wierszy i słownikach. Na koniec zastosowałem kompresję stron w tabeli źródłowej. Oto czasy i wyniki kompresji każdego typu:
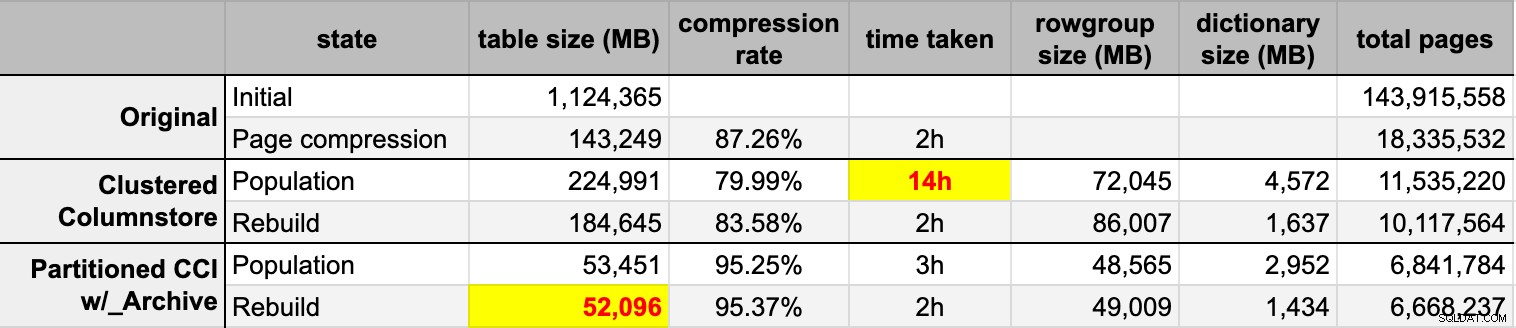
Jestem pod wrażeniem i rozczarowaniem. Pod wrażeniem, ponieważ te dane są bardzo dobrze skompresowane – zmniejszenie pojemności pamięci masowej do 5% pierwotnego 1 TB jest niesamowite. Rozczarowany, ponieważ:
- Zrobiłem te pliki danych sposób za duży.
- Nie rozumiem, co się stało z 14-godzinną wstępną kompresją magazynu kolumn:
- Nie zaobserwowałem żadnej pamięci ani nacisku na dzienniki.
- Nie wystąpiły zdarzenia wzrostu plików.
- Niestety nie przyszło mi do głowy, aby śledzić oczekiwania. Nie, nie zamierzam ponownie tego próbować. :-)
- Kompresja strony przewyższa zwykłą kompresję magazynu kolumn — być może z powodu danych.
- Odbudowa partycji archiwum magazynu kolumn zużywała dużo czasu procesora przy prawie zerowym zysku.
W nadchodzących postach i po przejrzeniu moich notatek z niesamowitej prezentacji w sklepie kolumnowym autorstwa Joe Obbisha na PASS Summit (do którego link bezpośrednio, gdyby tylko PASS wiedział, jak korzystać z interfejsu użytkownika), opowiem trochę o zmianach, które wprowadź konfigurację serwera i mój skrypt populacji, aby sprawdzić, czy mogę uzyskać lepszą wydajność z populacji magazynu kolumn.
[ Część 1 | Część 2 | Część 3 ]