W moim ostatnim poście pokazałem kilka skutecznych podejść do grupowej konkatenacji. Tym razem chciałem omówić kilka dodatkowych aspektów tego problemu, które możemy łatwo rozwiązać za pomocą FOR XML PATH podejście:uporządkowanie listy i usunięcie duplikatów.
Istnieje kilka sposobów, w jakie ludzie chcą, aby lista rozdzielana przecinkami była uporządkowana. Czasami chcą, aby pozycja na liście była uporządkowana alfabetycznie; Pokazałem to już w poprzednim poście. Ale czasami chcą go posortować według innego atrybutu, który w rzeczywistości nie jest wprowadzany w wyniku; na przykład, może chcę najpierw uporządkować listę według najnowszych pozycji. Weźmy prosty przykład, gdzie mamy tabele Employees i CoffeeOrders. Po prostu wypełnijmy zamówienia jednej osoby na kilka dni:
CREATE TABLE dbo.Employees
(
EmployeeID INT PRIMARY KEY,
Name NVARCHAR(128)
);
INSERT dbo.Employees(EmployeeID, Name) VALUES(1, N'Jack');
CREATE TABLE dbo.CoffeeOrders
(
EmployeeID INT NOT NULL REFERENCES dbo.Employees(EmployeeID),
OrderDate DATE NOT NULL,
OrderDetails NVARCHAR(64)
);
INSERT dbo.CoffeeOrders(EmployeeID, OrderDate, OrderDetails)
VALUES(1,'20140801',N'Large double double'),
(1,'20140802',N'Medium double double'),
(1,'20140803',N'Large Vanilla Latte'),
(1,'20140804',N'Medium double double');
Jeśli użyjemy istniejącego podejścia bez określenia ORDER BY , otrzymujemy dowolną kolejność (w tym przypadku najprawdopodobniej zobaczysz wiersze w kolejności, w jakiej zostały wstawione, ale nie polegaj na tym z większymi zestawami danych, większą liczbą indeksów itp.):
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Wyniki (pamiętaj, że możesz uzyskać *różne* wyniki, chyba że określisz ORDER BY ):
Jack | Duży podwójny podwójny, Średni podwójny podwójny, Duży Vanilla Latte, Średni podwójny podwójny
Jeśli chcemy uporządkować listę alfabetycznie, jest to proste; po prostu dodajemy ORDER BY c.OrderDetails :
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID ORDER BY c.OrderDetails -- only change FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Wyniki:
Nazwa | ZamówieniaJack | Duży podwójny podwójny, Duży Vanilla Latte, Średni podwójny podwójny, Średni podwójny podwójny
Możemy również uporządkować według kolumny, która nie pojawia się w zestawie wyników; na przykład możemy najpierw zamówić według najnowszego zamówienia kawy:
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID ORDER BY c.OrderDate DESC -- only change FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Wyniki:
Nazwa | ZamówieniaJack | Średni podwójny podwójny, Duży Vanilla Latte, Średni podwójny podwójny, Duży podwójny podwójny
Inną rzeczą, którą często chcemy robić, jest usuwanie duplikatów; w końcu nie ma powodu, aby dwukrotnie zobaczyć „Medium double double”. Możemy to wyeliminować, używając GROUP BY :
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID GROUP BY c.OrderDetails -- removed ORDER BY and added GROUP BY here FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Teraz *zdarza się* uporządkowanie wyników alfabetycznie, ale znowu nie możesz na tym polegać:
Nazwa | ZamówieniaJack | Duża podwójna podwójna, Duża waniliowa Latte, Średnia podwójna podwójna
Jeśli chcesz zagwarantować, że zamawiasz w ten sposób, możesz po prostu ponownie dodać ORDER BY:
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID GROUP BY c.OrderDetails ORDER BY c.OrderDetails -- added ORDER BY FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Wyniki są takie same (ale powtórzę, w tym przypadku to tylko zbieg okoliczności; jeśli chcesz taką kolejność, zawsze tak mów):
Nazwa | ZamówieniaJack | Duża podwójna podwójna, Duża waniliowa Latte, Średnia podwójna podwójna
Ale co, jeśli chcemy wyeliminować duplikaty *i* najpierw posortować listę według najnowszego zamówienia kawy? Twoim pierwszym odruchem może być zachowanie GROUP BY i po prostu zmień ORDER BY , tak:
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID GROUP BY c.OrderDetails ORDER BY c.OrderDate DESC -- changed ORDER BY FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
To nie zadziała, ponieważ OrderDate nie jest pogrupowane ani zagregowane jako część zapytania:
Kolumna „dbo.CoffeeOrders.OrderDate” jest nieprawidłowa w klauzuli ORDER BY, ponieważ nie jest zawarta ani w funkcji agregującej, ani w klauzuli GROUP BY.
Rozwiązaniem, które wprawdzie sprawia, że zapytanie jest trochę brzydsze, jest najpierw pogrupowanie zamówień oddzielnie, a następnie pobranie tylko wierszy z maksymalną datą zamówienia kawy na pracownika:
;WITH grouped AS ( SELECT EmployeeID, OrderDetails, OrderDate = MAX(OrderDate) FROM dbo.CoffeeOrders GROUP BY EmployeeID, OrderDetails ) SELECT e.Name, Orders = STUFF((SELECT N', ' + g.OrderDetails FROM grouped AS g WHERE g.EmployeeID = e.EmployeeID ORDER BY g.OrderDate DESC FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Wyniki:
Nazwa | ZamówieniaJack | Średni podwójny podwójny, Duży Vanilla Latte, Duży podwójny podwójny
Osiąga to oba nasze cele:wyeliminowaliśmy duplikaty i uporządkowaliśmy listę według czegoś, czego w rzeczywistości nie ma na liście.
Wydajność
Być może zastanawiasz się, jak źle te metody radzą sobie z bardziej niezawodnym zestawem danych. Zamierzam wypełnić naszą tabelę 100 000 wierszy, zobaczę, jak radzą sobie bez żadnych dodatkowych indeksów, a następnie ponownie uruchomię te same zapytania z odrobiną dostrojenia indeksu w celu obsługi naszych zapytań. Tak więc najpierw uzyskaj 100 000 wierszy rozłożonych na 1000 pracowników:
-- clear out our tiny sample data
DELETE dbo.CoffeeOrders;
DELETE dbo.Employees;
-- create 1000 fake employees
INSERT dbo.Employees(EmployeeID, Name)
SELECT TOP (1000)
EmployeeID = ROW_NUMBER() OVER (ORDER BY t.[object_id]),
Name = LEFT(t.name + c.name, 128)
FROM sys.all_objects AS t
INNER JOIN sys.all_columns AS c
ON t.[object_id] = c.[object_id];
-- create 100 fake coffee orders for each employee
-- we may get duplicates in here for name
INSERT dbo.CoffeeOrders(EmployeeID, OrderDate, OrderDetails)
SELECT e.EmployeeID,
OrderDate = DATEADD(DAY, ROW_NUMBER() OVER
(PARTITION BY e.EmployeeID ORDER BY c.[guid]), '20140630'),
LEFT(c.name, 64)
FROM dbo.Employees AS e
CROSS APPLY
(
SELECT TOP (100) name, [guid] = NEWID()
FROM sys.all_columns
WHERE [object_id] < e.EmployeeID
ORDER BY NEWID()
) AS c; Teraz po prostu uruchommy każde z naszych zapytań dwa razy i zobaczmy, jaki jest czas przy drugiej próbie (zrobimy skok wiary i założymy, że – w idealnym świecie – będziemy pracować z zagruntowaną pamięcią podręczną ). Uruchomiłem je w SQL Sentry Plan Explorer, ponieważ jest to najłatwiejszy znany mi sposób na porównanie kilku indywidualnych zapytań:
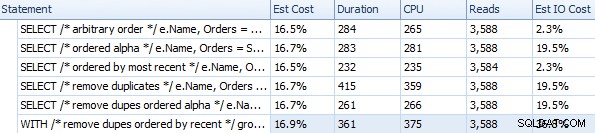 Czas trwania i inne metryki środowiska wykonawczego dla różnych metod FOR XML PATH
Czas trwania i inne metryki środowiska wykonawczego dla różnych metod FOR XML PATH
Te czasy (czas trwania w milisekundach) naprawdę nie są wcale takie złe IMHO, kiedy myślisz o tym, co się tutaj dzieje. Najbardziej skomplikowanym planem, przynajmniej wizualnie, wydawał się ten, w którym usunęliśmy duplikaty i posortowaliśmy według najnowszej kolejności:
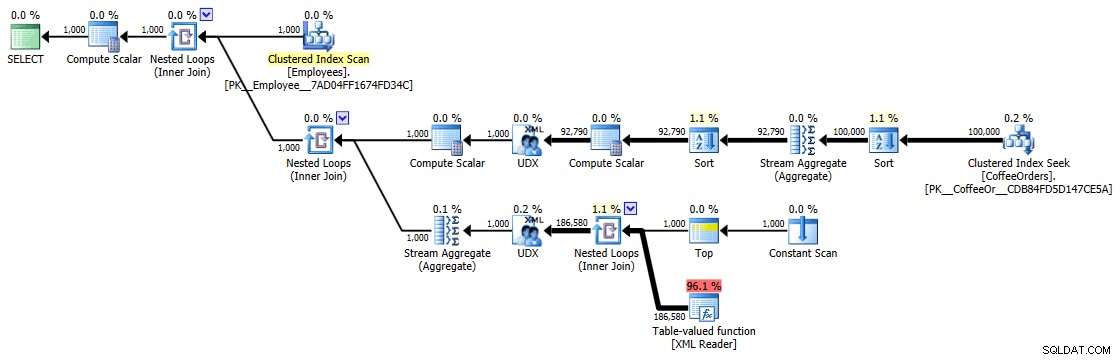 Plan wykonania zapytań pogrupowanych i posortowanych
Plan wykonania zapytań pogrupowanych i posortowanych
Ale nawet najdroższy operator tutaj – funkcja XML z wartościami tabelarycznymi – wydaje się być w całości CPU (chociaż dobrowolnie przyznam, że nie jestem pewien, jaka część rzeczywistej pracy jest ujawniona w szczegółach planu zapytania):
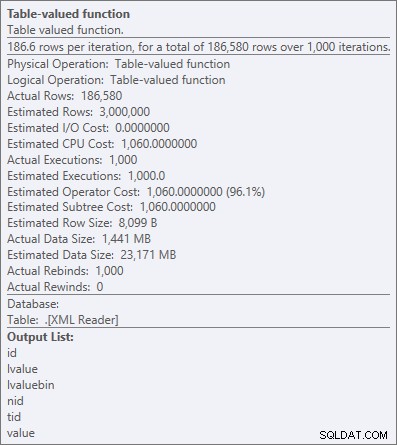 Właściwości operatora dla funkcji zwracającej tabelę XML
Właściwości operatora dla funkcji zwracającej tabelę XML
„Cały procesor” jest zazwyczaj w porządku, ponieważ większość systemów jest związana z we/wy i/lub pamięcią, a nie z procesorem. Jak często mówię, w większości systemów zamienię część mojego zapasu procesora na pamięć lub dysk każdego dnia tygodnia (jeden z powodów, dla których lubię OPTION (RECOMPILE) jako rozwiązanie wszechobecnych problemów związanych z podsłuchiwaniem parametrów).
To powiedziawszy, gorąco zachęcam do przetestowania tych podejść z podobnymi wynikami, które można uzyskać z podejścia GROUP_CONCAT CLR w CodePlex, a także do wykonywania agregacji i sortowania w warstwie prezentacji (szczególnie, jeśli zachowujesz w jakiś sposób znormalizowane dane buforowania warstwy).