Parametry wyceniane w tabeli istnieją od SQL Server 2008 i zapewniają przydatny mechanizm wysyłania wielu wierszy danych do SQL Server, połączonych w jedno sparametryzowane wywołanie. Wszelkie wiersze są następnie dostępne w zmiennej tabeli, która może być następnie wykorzystana w standardowym kodowaniu T-SQL, co eliminuje potrzebę pisania wyspecjalizowanej logiki przetwarzania w celu ponownego podziału danych. Z samej definicji parametry wyceniane w tabeli są silnie wpisane do typu tabeli zdefiniowanego przez użytkownika, który musi istnieć w bazie danych, w której wykonywane jest wywołanie. Jednak silnie wpisane nie jest tak naprawdę „mocno wpisane”, jak można by się spodziewać, jak to wykaże ten artykuł, a w rezultacie może to wpłynąć na wydajność.
Aby zademonstrować potencjalny wpływ na wydajność niepoprawnie wpisanych parametrów z wartościami przechowywanymi w tabeli w SQL Server, utworzymy przykładowy typ tabeli zdefiniowany przez użytkownika o następującej strukturze:
CREATE TYPE dbo.PharmacyData AS TABLE(Dawka int, Drug varchar(20), FirstName varchar(50), LastName varchar(50), AddressLine1 varchar(250), PhoneNumber varchar(50), CellNumber varchar(50), EmailAddress varchar(100), FillDate datetime);
Następnie będziemy potrzebować aplikacji .NET, która będzie używać tego typu tabeli zdefiniowanej przez użytkownika jako parametru wejściowego do przekazywania danych do SQL Server. Aby użyć parametru wycenianego w tabeli z naszej aplikacji, obiekt DataTable jest zwykle wypełniany, a następnie przekazywany jako wartość parametru z typem SqlDbType.Structured. DataTable można utworzyć na wiele sposobów w kodzie .NET, ale typowym sposobem tworzenia tabeli jest mniej więcej tak:
System.Data.DataTable DefaultTable =new System.Data.DataTable("@PharmacyData");DefaultTable.Columns.Add("Dawka", typeof(int));DefaultTable.Columns.Add("Drug", typeof (string));DefaultTable.Columns.Add("FirstName", typeof(string));DefaultTable.Columns.Add("LastName", typeof(string));DefaultTable.Columns.Add("AddressLine1", typeof(string ));DefaultTable.Columns.Add("PhoneNumber", typeof(string));DefaultTable.Columns.Add("CellNumber", typeof(string));DefaultTable.Columns.Add("EmailAddress", typeof(string));DefaultTable.Columns.Add("Data", typeof(DateTime)); Możesz również utworzyć DataTable, używając definicji wbudowanej w następujący sposób:
System.Data.DataTable DefaultTable =new System.Data.DataTable("@PharmacyData"){ Columns ={ {"Dawka", typeof(int)}, {"Lek", typeof(string)}, {" FirstName", typeof(string)}, {"LastName", typeof(string)}, {"AddressLine1", typeof(string)}, {"PhoneNumber", typeof(string)}, {"CellNumber", typeof(string )}, {"EmailAddress", typeof(string)}, {"Date", typeof(DateTime)}, }, Locale =CultureInfo.InvariantCulture}; Każda z tych definicji obiektu DataTable w programie .NET może być używana jako parametr wyceniany w tabeli dla typu danych zdefiniowanego przez użytkownika, który został utworzony, ale zwróć uwagę na definicję typeof(string) dla różnych kolumn ciągów; wszystkie mogą być „prawidłowo” wpisane, ale w rzeczywistości nie są silnie wpisane do typów danych zaimplementowanych w typie danych zdefiniowanym przez użytkownika. Możemy wypełnić tabelę losowymi danymi i przekazać je do SQL Server jako parametr do bardzo prostej instrukcji SELECT, która zwróci dokładnie te same wiersze, co tabela, którą przekazaliśmy, w następujący sposób:
Następnie możemy użyć przerwy debugowania, abyśmy mogli sprawdzić definicję tabeli domyślnej podczas wykonywania, jak pokazano poniżej:
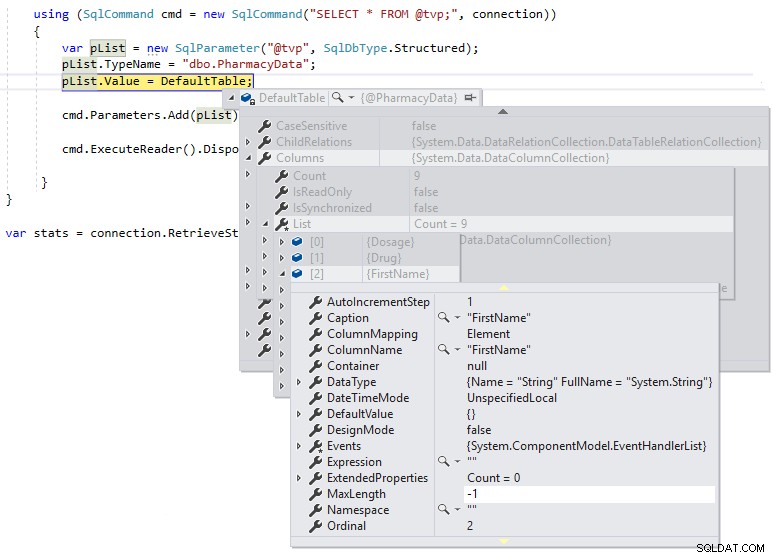
Widzimy, że maksymalna długość kolumn ciągów jest ustawiona na -1, co oznacza, że są one przekazywane przez TDS do SQL Server jako obiekty LOB (duże obiekty) lub zasadniczo jako kolumny z typami danych MAX, co może mieć negatywny wpływ na wydajność. Jeśli zmienimy definicję .NET DataTable na silnie wpisaną do definicji schematu typu tabeli zdefiniowanej przez użytkownika w następujący sposób i przyjrzymy się MaxLength tej samej kolumny przy użyciu przerwy debugowania:
System.Data.DataTable SchemaTable =new System.Data.DataTable("@PharmacyData"){ Columns ={ {new DataColumn() { ColumnName ="Dawka", DataType =typeof(int)} }, {new DataColumn () { ColumnName ="Drug", DataType =typeof(string), MaxLength =20} }, {new DataColumn() { ColumnName ="FirstName", DataType =typeof(string), MaxLength =50} }, {new DataColumn () { ColumnName ="LastName", DataType =typeof(string), MaxLength =50} }, {new DataColumn() { ColumnName ="AddressLine1", DataType =typeof(string), MaxLength =250} }, {new DataColumn () { ColumnName ="PhoneNumber", DataType =typeof(string), MaxLength =50} }, {new DataColumn() { ColumnName ="CellNumber", DataType =typeof(string), MaxLength =50} }, {new DataColumn () { ColumnName ="EmailAddress", DataType =typeof(string), MaxLength =100} }, {new DataColumn() { ColumnName ="Data", DataType =typeof(DateTime)} }, }, Locale =CultureInfo.InvariantCultur e};
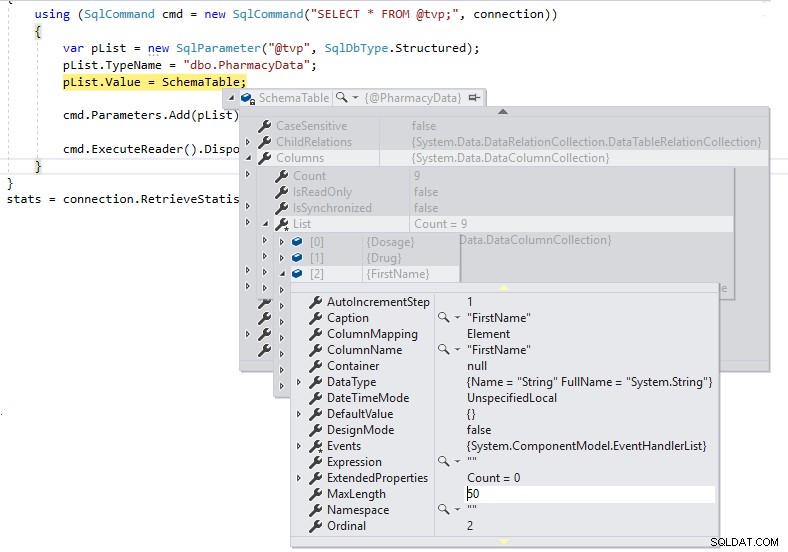
Mamy teraz poprawne długości definicji kolumn i nie będziemy przekazywać ich jako obiektów LOB przez TDS do SQL Server.
Możesz się zastanawiać, jak to wpływa na wydajność? Wpływa na liczbę buforów TDS wysyłanych przez sieć do programu SQL Server, a także wpływa na ogólny czas przetwarzania poleceń.
Użycie dokładnie tego samego zestawu danych dla dwóch tabel danych i wykorzystanie metody RetrieveStatistics na obiekcie SqlConnection pozwala nam uzyskać metryki statystyczne ExecutionTime i BuffersSent dla wywołań tego samego polecenia SELECT i po prostu użyć dwóch różnych definicji DataTable jako parametrów a wywołanie metody ResetStatistics obiektu SqlConnection umożliwia wyczyszczenie statystyk wykonania między testami.
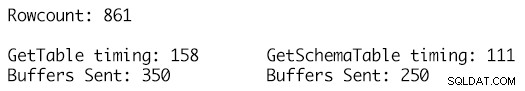
Definicja GetSchemaTable określa poprawnie MaxLength dla każdej kolumny ciągu, gdzie GetTable po prostu dodaje kolumny typu string, które mają wartość MaxLength ustawioną na -1, co skutkuje wysłaniem 100 dodatkowych buforów TDS dla 861 wierszy danych w tabeli i środowiska wykonawczego 158 milisekund w porównaniu do tylko 250 buforów wysyłanych dla definicji DataTable o jednoznacznie określonym typie i czasu wykonywania 111 milisekund. Chociaż może to nie wydawać się zbyt wiele w wielkim schemacie rzeczy, jest to pojedyncze wezwanie, pojedyncza egzekucja, a skumulowany wpływ w czasie dla wielu tysięcy lub milionów takich egzekucji to moment, w którym korzyści zaczynają się sumować i mają zauważalny wpływ na wydajność i przepustowość obciążenia.
To, co naprawdę może mieć znaczenie, to wdrożenia w chmurze, w których płacisz za coś więcej niż tylko zasoby obliczeniowe i magazynowe. Oprócz stałych kosztów zasobów sprzętowych dla maszyny wirtualnej platformy Azure, bazy danych SQL lub AWS EC2 lub RDS istnieje dodatkowy koszt ruchu sieciowego do iz chmury, który jest dodawany do rozliczeń za każdy miesiąc. Zmniejszenie buforów przechodzących przez przewód z czasem obniży całkowity koszt posiadania rozwiązania, a zmiany kodu wymagane do wprowadzenia tych oszczędności są stosunkowo proste.