Azure SQL Database to oferta bazy danych jako usługi firmy Microsoft, która zapewnia ogromną elastyczność. Jest zbudowany jako część środowiska platformy jako usługi, które zapewnia klientom dodatkowe monitorowanie i bezpieczeństwo produktu.
Azure SQL Database to oferta bazy danych jako usługi firmy Microsoft, która zapewnia ogromną elastyczność. Jest zbudowany jako część środowiska platformy jako usługi, które zapewnia klientom dodatkowe monitorowanie i bezpieczeństwo produktu.
Microsoft nieustannie pracuje nad ulepszaniem swoich produktów, a Azure SQL Database nie różni się od nich. Wiele nowszych funkcji dostępnych w programie SQL Server zostało początkowo uruchomionych w Azure SQL Database, w tym (ale nie tylko) zawsze szyfrowane, dynamiczne maskowanie danych, zabezpieczenia na poziomie wiersza i magazyn zapytań.
Poziom cen DTU
Po pierwszym uruchomieniu usługi Azure SQL Database istniała jedna opcja cenowa znana jako „jednostki DTU” lub jednostki transakcji bazy danych. (Andy Mallon, @AMtwo, wyjaśnia DTU w „Co do cholery to DTU?”) Model DTU zapewnia trzy poziomy usług:podstawowy, standardowy i premium. Warstwa podstawowa zapewnia do 5 jednostek DTU ze standardowym magazynem. Warstwa standardowa obsługuje od 10 do 3000 jednostek DTU w przypadku standardowej pamięci masowej, a warstwa premium obsługuje od 125 do 4000 jednostek DTU z pamięcią masową premium, co jest o rząd wielkości szybsze niż w przypadku standardowej pamięci masowej.
Poziom cenowy vCore
Kilka lat po wydaniu usługi Azure SQL Database do momentu udostępnienia usługi Azure SQL Managed Instance w publicznej wersji zapoznawczej ogłoszono „vcores” (wirtualne rdzenie) dla usługi Azure SQL Database. Wprowadzono warstwy ogólnego przeznaczenia i krytyczne dla firmy z procesorami Gen 4 i Gen 5. Gen 5 jest teraz podstawową opcją sprzętową w większości regionów, ponieważ Gen 4 się starzeje.
Gen 5 obsługuje zaledwie 2 rdzenie wirtualne i do 80 rdzeni wirtualnych, przy czym pamięć RAM jest przydzielana po 5,1 GB na rdzeń wirtualny. Warstwa ogólnego przeznaczenia zapewnia zdalny magazyn z maksymalną liczbą IOPS danych w zakresie od 640 dla bazy danych z 2 rdzeniami wirtualnymi do 25600 dla bazy danych z 80 rdzeniami wirtualnymi. Warstwa o znaczeniu krytycznym dla firmy ma lokalny dysk SSD, który zapewnia znacznie lepszą wydajność we/wy z maksymalną liczbą operacji we/wy danych w zakresie od 8000 dla bazy danych z 2 rdzeniami wirtualnymi do 204 800 dla bazy danych z 80 rdzeniami wirtualnymi. Zarówno poziomy ogólnego przeznaczenia, jak i warstwy krytyczne dla działalności biznesowej wynoszą maksymalnie 4096 GB na pamięć masową, co stało się ograniczeniem dla wielu klientów.
Baza danych HyperScale
Aby rozwiązać problem dotyczący limitu 4 TB usługi Azure SQL Database, firma Microsoft stworzyła warstwę hiperskalowania. Hiperskalowanie umożliwia klientom skalowanie do 100 TB rozmiaru bazy danych, a także zapewnia szybkie skalowanie w poziomie węzłów tylko do odczytu. Możesz także łatwo skalować w górę i w dół w modelu vCore. Bazy danych w hiperskalowaniu są udostępniane przy użyciu rdzeni wirtualnych. W przypadku 5. generacji baza danych hiperskalowania może wykorzystywać od 2 do 80 rdzeni wirtualnych i od 500 do 204 800 IOPS. Funkcja hiperskalowania zapewnia wysoką wydajność każdego węzła obliczeniowego wyposażonego w pamięci podręczne oparte na dyskach SSD, co pomaga zminimalizować ruch sieciowy w obie strony w celu pobrania danych. Istnieje wiele niesamowitych technologii związanych z hiperskalowaniem w sposobie, w jaki jest zaprojektowany do korzystania z pamięci podręcznych opartych na dyskach SSD i serwerów stron. Gorąco polecam rzucić okiem na diagram, który przedstawia architekturę i jak to wszystko działa w tym artykule.
Bezserwerowa baza danych
Innym bardzo powszechnym żądaniem ze strony klientów była możliwość automatycznego skalowania w górę i w dół ich bazy danych Azure SQL Database w miarę zwiększania i zmniejszania obciążeń. Klienci tradycyjnie mieli możliwość programowego skalowania w górę i w dół za pomocą PowerShell, Azure Automation i innych metod. Microsoft skorzystał z tego pomysłu i zbudował nową warstwę obliczeniową o nazwie Azure SQL Database bezserwerową, która stała się powszechnie dostępna w listopadzie 2019 r. Umożliwiają one klientowi ustawienie minimalnej i maksymalnej liczby rdzeni wirtualnych. W ten sposób mogą wiedzieć, że zawsze jest dostępny minimalny poziom obliczeń i zawsze mogą automatycznie skalować do wyznaczonego poziomu obliczeń. Istnieje również możliwość skonfigurowania opóźnienia autopauzy. To ustawienie umożliwia automatyczne wstrzymanie bazy danych po określonym czasie, gdy baza danych była nieaktywna. Gdy baza danych wchodzi w fazę autopauzy, koszty obliczeniowe spadają do zera i ponoszone są tylko koszty przechowywania. Całkowity koszt bezserwerowego to suma kosztu obliczeń i kosztu magazynowania. Gdy użycie obliczeń mieści się między minimalnym a maksymalnym limitem, koszt obliczeń jest oparty na rdzeniach wirtualnych i używanej pamięci. Jeśli rzeczywiste użycie jest poniżej wartości minimalnej, koszt obliczeniowy jest oparty na minimalnej liczbie rdzeni wirtualnych i minimalnej skonfigurowanej pamięci.
Warstwa bezserwerowa może potencjalnie zaoszczędzić klientom dużo pieniędzy, jednocześnie dając im możliwość zapewnienia spójnego doświadczenia użytkownika bazy danych, przy czym baza danych może być skalowana w miarę potrzeb.
Elastyczne baseny
Azure SQL Database ma udostępniony model zasobów, który umożliwia klientom większe wykorzystanie zasobów. Klient może utworzyć pulę elastyczną i przenieść bazy danych do tej puli. Każda baza danych może następnie rozpocząć udostępnianie wstępnie zdefiniowanych zasobów w tej puli. Pule elastyczne można skonfigurować przy użyciu modelu cen DTU lub modelu rdzeni wirtualnych. Klienci określają ilość zasobów potrzebnych w puli elastycznej do obsługi obciążenia pracą wszystkich swoich baz danych. Limity zasobów można skonfigurować na bazę danych, aby jedna baza danych nie mogła wykorzystywać całej puli. Pule elastyczne są idealne dla klientów, którzy muszą zarządzać dużą liczbą baz danych lub scenariuszami z wieloma dzierżawcami.
Nowa konfiguracja sprzętu dla aprowizowanej warstwy obliczeniowej
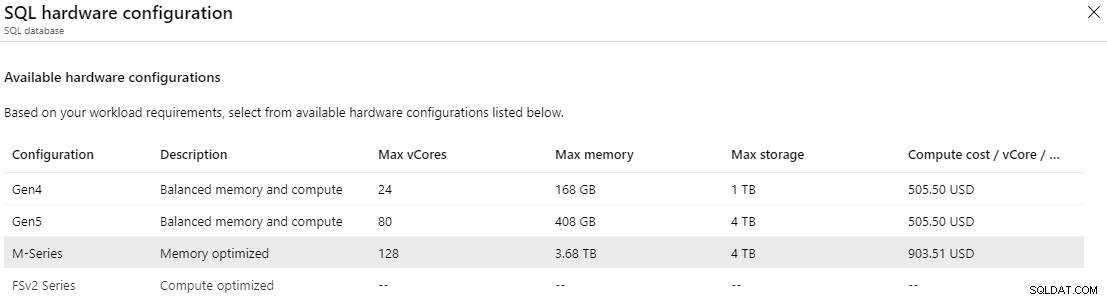
Konfiguracje sprzętowe Gen4/Gen5 są uważane za „zrównoważoną pamięć i moc obliczeniową”. Działa to dobrze w przypadku wielu obciążeń programu SQL Server, jednak zdarzały się przypadki użycia mniejszego opóźnienia procesora i wyższej częstotliwości taktowania w przypadku obciążeń intensywnie korzystających z procesora oraz potrzeby większej ilości pamięci na rdzeń wirtualny. Firma Microsoft po raz kolejny dostarczyła i stworzyła konfigurację sprzętową zoptymalizowaną pod kątem obliczeń i pamięci. Są one obecnie w wersji zapoznawczej i dostępne tylko w niektórych regionach.
W warstwie aprowizowanej ogólnego przeznaczenia można wybrać serię Fsv2, która może zapewnić większą wydajność procesora na rdzeń wirtualny niż sprzęt 5. generacji. Ogólnie rzecz biorąc, rozmiar 72 vCore może zapewnić większą wydajność procesora niż 80 vCore Gen 5, zapewniając niższe opóźnienia procesora i wyższe częstotliwości taktowania. Seria Fsv2 ma mniej pamięci i tempdb na rdzeń wirtualny niż Gen 5, więc trzeba to wziąć pod uwagę.
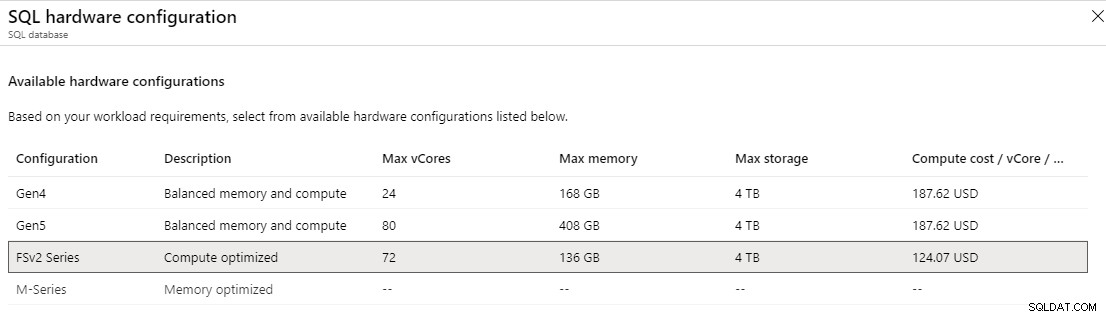
W krytycznej dla firmy warstwie aprowizowanej można uzyskać dostęp do serii M, która jest zoptymalizowana pod kątem pamięci. Seria M oferuje 29 GB na rdzeń wirtualny w porównaniu z 5,1 GB na rdzeń wirtualny w konfiguracji „zrównoważenie pamięci i obliczeń”. Dzięki serii M możesz skalować rdzeń wirtualny do 128, co zapewniłoby do 3,7 TB pamięci. Aby włączyć serię M, musisz być w umowie z płatnością zgodnie z rzeczywistym użyciem lub umową Enterprise i otworzyć zgłoszenie serwisowe. Nawet wtedy seria M jest obecnie dostępna tylko we wschodnich stanach USA, Europie Północnej, Europie Zachodniej i zachodnich stanach USA 2, a jej dostępność może być również ograniczona w innych regionach.
Wniosek
Azure SQL Database to bogata w funkcje platforma bazy danych, która oferuje szeroki zakres opcji obliczeń i skalowania. Klienci mogą konfigurować obliczenia dla pojedynczej bazy danych lub puli elastycznej przy użyciu jednostek DTU lub rdzeni wirtualnych. W przypadku baz danych o dużych wymaganiach dotyczących magazynu lub skalowaniu odczytu w poziomie można zastosować funkcję Hyperscale. W przypadku klientów o różnych wymaganiach dotyczących obciążenia można użyć opcji bezserwerowej do automatycznego skalowania w górę i w dół, gdy zmieniają się ich wymagania dotyczące obciążenia. Nowością w Azure SQL Database jest funkcja wersji zapoznawczej konfiguracji sprzętowej zoptymalizowanej pod kątem obliczeń i pamięci dla tych klientów, którzy potrzebują procesora o niższych opóźnieniach lub tych, którzy wymagają dużej ilości pamięci do procesora.
Aby dowiedzieć się więcej o zasobach platformy Azure, zapoznaj się z moimi poprzednimi artykułami:
- Opcje dostrajania wydajności bazy danych Azure SQL
- Zagadnienia dotyczące wydajności wystąpienia zarządzanego Azure SQL
- Nowe standardowe rozmiary warstw bazy danych SQL Azure
- Wypełnianie luki na platformie Azure:zarządzane instancje
- Migracja baz danych do Azure SQL Database