W części 5 mojej serii dotyczącej wyrażeń tabelowych przedstawiłem następujące rozwiązanie do generowania serii liczb za pomocą CTE, konstruktora wartości tabeli i sprzężeń krzyżowych:
DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
WITH
L0 AS ( SELECT 1 AS c FROM (VALUES(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
L4 AS ( SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B ),
L5 AS ( SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Istnieje wiele praktycznych przypadków użycia takiego narzędzia, w tym generowanie serii wartości daty i godziny, tworzenie przykładowych danych i nie tylko. Uwzględniając powszechną potrzebę, niektóre platformy udostępniają wbudowane narzędzie, takie jak funkcja generate_series PostgreSQLa. W chwili pisania tego tekstu T-SQL nie zapewnia takiego wbudowanego narzędzia, ale zawsze można mieć nadzieję i głosować na dodanie takiego narzędzia w przyszłości.
W komentarzu do mojego artykułu Marcos Kirchner wspomniał, że przetestował moje rozwiązanie z różnymi licznościami konstruktorów wartości tabeli i uzyskał różne czasy wykonania dla różnych liczności.
 Zawsze używałem mojego rozwiązania z kardynalnością konstruktora wartości tabeli bazowej równą 2, ale komentarz Marcos dał mi do myślenia. To narzędzie jest tak przydatne, że jako społeczność powinniśmy połączyć siły, aby spróbować stworzyć najszybszą wersję, jaką tylko możemy. Testowanie różnych kardynalności tabeli bazowej to tylko jeden wymiar do wypróbowania. Mogłoby być wiele innych. Przedstawię testy wydajności, które wykonałem z moim rozwiązaniem. Eksperymentowałem głównie z różnymi kardynalnościami konstruktorów wartości tabeli, z przetwarzaniem szeregowym w porównaniu z równoległym oraz z trybem wiersza w porównaniu z przetwarzaniem w trybie wsadowym. Może się jednak zdarzyć, że zupełnie inne rozwiązanie jest nawet szybsze niż moja najlepsza wersja. Wyzwanie trwa! Wzywam jednakowo wszystkich Jedi, padawanów, czarodziejów i uczniów. Jakie jest najskuteczniejsze rozwiązanie, które możesz wyczarować? Czy masz w sobie możliwość pokonania najszybszego rozwiązania opublikowanego do tej pory? Jeśli tak, udostępnij swój komentarz do tego artykułu i możesz ulepszyć dowolne rozwiązanie opublikowane przez innych.
Zawsze używałem mojego rozwiązania z kardynalnością konstruktora wartości tabeli bazowej równą 2, ale komentarz Marcos dał mi do myślenia. To narzędzie jest tak przydatne, że jako społeczność powinniśmy połączyć siły, aby spróbować stworzyć najszybszą wersję, jaką tylko możemy. Testowanie różnych kardynalności tabeli bazowej to tylko jeden wymiar do wypróbowania. Mogłoby być wiele innych. Przedstawię testy wydajności, które wykonałem z moim rozwiązaniem. Eksperymentowałem głównie z różnymi kardynalnościami konstruktorów wartości tabeli, z przetwarzaniem szeregowym w porównaniu z równoległym oraz z trybem wiersza w porównaniu z przetwarzaniem w trybie wsadowym. Może się jednak zdarzyć, że zupełnie inne rozwiązanie jest nawet szybsze niż moja najlepsza wersja. Wyzwanie trwa! Wzywam jednakowo wszystkich Jedi, padawanów, czarodziejów i uczniów. Jakie jest najskuteczniejsze rozwiązanie, które możesz wyczarować? Czy masz w sobie możliwość pokonania najszybszego rozwiązania opublikowanego do tej pory? Jeśli tak, udostępnij swój komentarz do tego artykułu i możesz ulepszyć dowolne rozwiązanie opublikowane przez innych.
Wymagania:
- Zaimplementuj swoje rozwiązanie jako wbudowaną funkcję zwracającą tabelę (iTVF) o nazwie dbo.GetNumsYourName z parametrami @low AS BIGINT i @high AS BIGINT. Jako przykład zobacz te, które przesyłam na końcu tego artykułu.
- W razie potrzeby można utworzyć pomocnicze tabele w bazie danych użytkownika.
- W razie potrzeby możesz dodać wskazówki.
- Jak wspomniano, rozwiązanie powinno obsługiwać ograniczniki typu BIGINT, ale można założyć maksymalną kardynalność serii wynoszącą 4 294 967 296.
- Aby ocenić wydajność Twojego rozwiązania i porównać je z innymi, przetestuję je z zakresem od 1 do 100 000 000, z włączoną opcją Odrzuć wyniki po wykonaniu w SSMS.
Powodzenia nam wszystkim! Niech wygra najlepsza społeczność.;)
Różne moce konstruktora wartości tabeli bazowej
Eksperymentowałem z różnymi mocami podstawowego CTE, zaczynając od 2 i przesuwając dalej w skali logarytmicznej, podnosząc do kwadratu poprzednią moc na każdym kroku:2, 4, 16 i 256.
Zanim zaczniesz eksperymentować z różnymi kardynałami podstawowymi, pomocne może być opracowanie formuły, która biorąc pod uwagę kardynalność podstawową i maksymalny zakres kardynalności, powie ci, ile poziomów CTE potrzebujesz. Na wstępie łatwiej jest najpierw wymyślić wzór, który biorąc pod uwagę bazową kardynalność i liczbę poziomów CTE, oblicza maksymalny wynikowy kardynalność zakresu. Oto taka formuła wyrażona w T-SQL:
DECLARE @basecardinality AS INT = 2, @levels AS INT = 5; SELECT POWER(1.*@basecardinality, POWER(2., @levels));
Z powyższymi przykładowymi wartościami wejściowymi to wyrażenie daje maksymalną kardynalność zakresu 4 294 967 296.
Następnie odwrotna formuła obliczania liczby potrzebnych poziomów CTE obejmuje zagnieżdżanie dwóch funkcji dziennika, takich jak:
DECLARE @basecardinality AS INT = 2, @seriescardinality AS BIGINT = 4294967296; SELECT CEILING(LOG(LOG(@seriescardinality, @basecardinality), 2));
Z powyższymi przykładowymi wartościami wejściowymi to wyrażenie daje 5. Zauważ, że ta liczba jest dodatkiem do podstawowego CTE, który ma konstruktor wartości tabeli, który nazwałem L0 (dla poziomu 0) w moim rozwiązaniu.
Nie pytaj mnie, jak dotarłem do tych formuł. Historia, której się trzymam, polega na tym, że Gandalf wypowiedział je do mnie po elfisku w moich snach.
Przejdźmy do testów wydajnościowych. Upewnij się, że włączono opcję Odrzuć wyniki po wykonaniu w oknie dialogowym Opcje zapytania programu SSMS w obszarze Siatka, Wyniki. Użyj poniższego kodu, aby uruchomić test z podstawową kardynalnością CTE równą 2 (wymaga 5 dodatkowych poziomów CTE):
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c FROM (VALUES(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
L4 AS ( SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B ),
L5 AS ( SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Mam plan pokazany na Rysunku 1 dla tego wykonania.
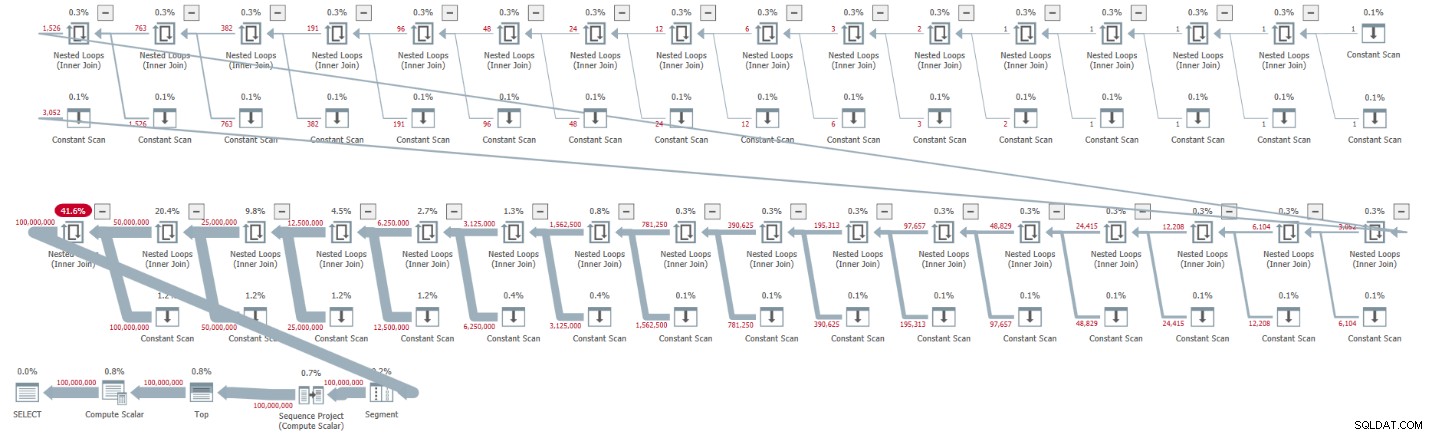 Rysunek 1:Plan dla podstawowej kardynalności CTE równej 2
Rysunek 1:Plan dla podstawowej kardynalności CTE równej 2
Plan jest szeregowy, a wszyscy operatorzy w planie domyślnie używają przetwarzania w trybie wierszowym. Jeśli domyślnie otrzymujesz plan równoległy, np. podczas enkapsulacji rozwiązania w iTVF i korzystania z dużego zakresu, na razie wymuś plan szeregowy ze wskazówką MAXDOP 1.
Zobacz, jak rozpakowanie CTE spowodowało 32 wystąpienia operatora Constant Scan, z których każdy reprezentuje tabelę z dwoma wierszami.
Otrzymałem następujące statystyki wydajności dla tego wykonania:
CPU time = 30188 ms, elapsed time = 32844 ms.
Użyj poniższego kodu, aby przetestować rozwiązanie z podstawową licznością CTE wynoszącą 4, co zgodnie z naszą formułą wymaga czterech poziomów CTE:
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c FROM (VALUES(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
L4 AS ( SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L4 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Mam plan pokazany na Rysunku 2 dla tego wykonania.
 Rysunek 2:Plan dla podstawowej liczby CTE wynoszącej 4
Rysunek 2:Plan dla podstawowej liczby CTE wynoszącej 4
Rozpakowanie CTE zaowocowało 16 operatorami Constant Scan, z których każdy reprezentuje tabelę z 4 wierszami.
Otrzymałem następujące statystyki wydajności dla tego wykonania:
CPU time = 23781 ms, elapsed time = 25435 ms.
To przyzwoita poprawa o 22,5 procent w stosunku do poprzedniego rozwiązania.
Analizując statystyki oczekiwania zgłoszone dla zapytania, dominującym typem oczekiwania jest SOS_SCHEDULER_YIELD. Rzeczywiście, liczba oczekiwania spadła o 22,8 procent w porównaniu z pierwszym rozwiązaniem (liczba oczekiwania 15 280 w porównaniu do 19 800).
Użyj poniższego kodu, aby przetestować rozwiązanie z podstawową licznością CTE wynoszącą 16, co zgodnie z naszą formułą wymaga trzech poziomów CTE:
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Mam plan pokazany na Rysunku 3 dla tego wykonania.
 Rysunek 3:Plan dla podstawowej liczności CTE wynoszącej 16
Rysunek 3:Plan dla podstawowej liczności CTE wynoszącej 16
Tym razem rozpakowanie CTE zaowocowało 8 operatorami Constant Scan, z których każdy reprezentuje tabelę z 16 wierszami.
Otrzymałem następujące statystyki wydajności dla tego wykonania:
CPU time = 22968 ms, elapsed time = 24409 ms.
To rozwiązanie dodatkowo skraca upływ czasu, choć tylko o kilka dodatkowych procent, co stanowi redukcję o 25,7 procent w porównaniu z pierwszym rozwiązaniem. Ponownie, liczba oczekiwania typu oczekiwania SOS_SCHEDULER_YIELD ciągle spada (12 938).
Posuwając się naprzód w naszej skali logarytmicznej, następny test obejmuje bazową kardynalność CTE wynoszącą 256. Jest długi i brzydki, ale spróbuj:
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L2 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Mam plan pokazany na Rysunku 4 dla tego wykonania.
 Rysunek 4:Plan dla podstawowej kardynalności CTE wynoszącej 256
Rysunek 4:Plan dla podstawowej kardynalności CTE wynoszącej 256
Tym razem rozpakowanie CTE zaowocowało tylko czterema operatorami Constant Scan, każdy z 256 wierszami.
Otrzymałem następujące wartości wydajności dla tego wykonania:
CPU time = 23516 ms, elapsed time = 25529 ms.
Tym razem wydaje się, że wydajność nieco się pogorszyła w porównaniu z poprzednim rozwiązaniem z podstawową kardynalnością CTE wynoszącą 16. Rzeczywiście, liczba oczekiwania typu oczekiwania SOS_SCHEDULER_YIELD wzrosła nieco do 13 176. Wygląda więc na to, że znaleźliśmy naszą złotą liczbę — 16!
Plany równoległe a plany szeregowe
Eksperymentowałem z wymuszeniem równoległego planu za pomocą podpowiedzi ENABLE_PARALLEL_PLAN_PREFERENCE, ale skończyło się na tym, że obniżyło to wydajność. W rzeczywistości, wdrażając rozwiązanie jako iTVF, domyślnie otrzymałem na swoim komputerze plan równoległy dla dużych zasięgów i musiałem wymusić plan szeregowy z podpowiedzią MAXDOP 1, aby uzyskać optymalną wydajność.
Przetwarzanie wsadowe
Głównym zasobem używanym w planach dla moich rozwiązań jest procesor. Biorąc pod uwagę, że przetwarzanie wsadowe polega na poprawie wydajności procesora, szczególnie w przypadku dużej liczby wierszy, warto wypróbować tę opcję. Główną czynnością, która może skorzystać z przetwarzania wsadowego, jest obliczanie numeru wiersza. Testowałem swoje rozwiązania w wersji SQL Server 2019 Enterprise. SQL Server domyślnie wybrał przetwarzanie w trybie wiersza dla wszystkich poprzednio pokazanych rozwiązań. Najwyraźniej to rozwiązanie nie przeszło heurystyki wymaganej do włączenia trybu wsadowego w sklepie rowstore. Istnieje kilka sposobów, aby SQL Server używał przetwarzania wsadowego.
Opcja 1 polega na włączeniu do rozwiązania tabeli z indeksem magazynu kolumn. Możesz to osiągnąć, tworząc fikcyjną tabelę z indeksem magazynu kolumn i wprowadzając fikcyjną lewe sprzężenie w najbardziej zewnętrznym zapytaniu między naszym Nums CTE a tą tabelą. Oto definicja fikcyjnej tabeli:
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Następnie sprawdź zewnętrzne zapytanie pod kątem Nums, aby użyć FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 =0. Oto przykład z podstawową licznością CTE wynoszącą 16:
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum; Mam plan pokazany na Rysunku 5 dla tego wykonania.
 Rysunek 5:Planowanie z przetwarzaniem wsadowym
Rysunek 5:Planowanie z przetwarzaniem wsadowym
Obserwuj użycie operatora Window Aggregate w trybie wsadowym, aby obliczyć numery wierszy. Zauważ też, że plan nie obejmuje atrapy stolika. Optymalizator zoptymalizował to.
Zaletą opcji 1 jest to, że działa ona we wszystkich edycjach SQL Server i jest odpowiednia w SQL Server 2016 lub nowszym, ponieważ w SQL Server 2016 wprowadzono operator Window Aggregate w trybie wsadowym. Minusem jest konieczność utworzenia fikcyjnej tabeli i uwzględnienia w rozwiązaniu.
Opcja 2, aby uzyskać przetwarzanie wsadowe dla naszego rozwiązania, pod warunkiem, że używasz wersji SQL Server 2019 Enterprise, polega na skorzystaniu z nieudokumentowanej, oczywistej wskazówki OVERRIDE_BATCH_MODE_HEURISTICS (szczegóły w artykule Dmitrija Pilugina), na przykład:
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum
OPTION(USE HINT('OVERRIDE_BATCH_MODE_HEURISTICS')); Zaletą opcji 2 jest to, że nie musisz tworzyć fikcyjnej tabeli i angażować jej w swoje rozwiązanie. Minusem jest to, że musisz używać wersji Enterprise, używać co najmniej SQL Server 2019, gdzie wprowadzono tryb wsadowy na rowstore, a rozwiązanie polega na użyciu nieudokumentowanej podpowiedzi. Z tych powodów preferuję opcję 1.
Oto liczby wydajności, które otrzymałem dla różnych podstawowych mocy CTE:
Cardinality 2: CPU time = 21594 ms, elapsed time = 22743 ms (down from 32844). Cardinality 4: CPU time = 18375 ms, elapsed time = 19394 ms (down from 25435). Cardinality 16: CPU time = 17640 ms, elapsed time = 18568 ms (down from 24409). Cardinality 256: CPU time = 17109 ms, elapsed time = 18507 ms (down from 25529).
Rysunek 6 przedstawia porównanie wydajności między różnymi rozwiązaniami:
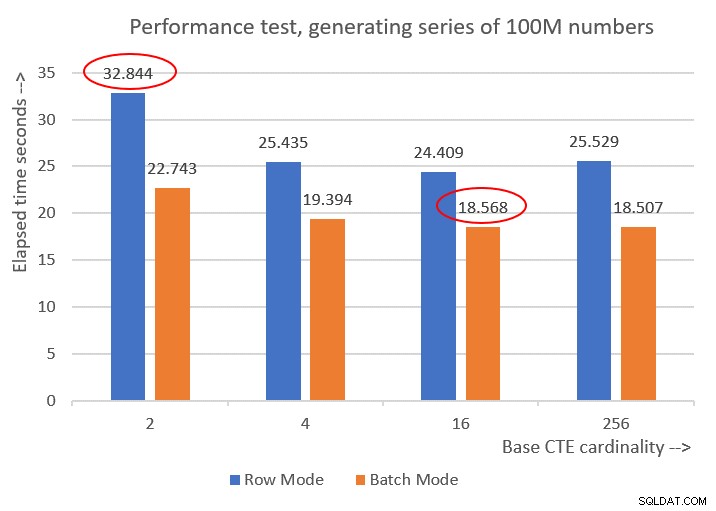 Rysunek 6:Porównanie wydajności
Rysunek 6:Porównanie wydajności
Możesz zaobserwować przyzwoitą poprawę wydajności o 20-30 procent w porównaniu z odpowiednikami w trybie wiersza.
Co ciekawe, w przypadku przetwarzania w trybie wsadowym rozwiązanie z podstawową kardynalnością CTE wynoszącą 256 spisało się najlepiej. Jest to jednak tylko odrobinę szybsze niż rozwiązanie z podstawową kardynalnością CTE wynoszącą 16. Różnica jest tak niewielka, a to drugie ma wyraźną przewagę pod względem zwięzłości kodu, że trzymałbym się 16.
Tak więc moje wysiłki związane z dostrajaniem przyniosły poprawę o 43,5% w porównaniu z oryginalnym rozwiązaniem z podstawową kardynalnością 2 przy użyciu przetwarzania w trybie wiersza.
Wyzwanie rozpoczęte!
Jako wkład społeczności w to wyzwanie zgłaszam dwa rozwiązania. Jeśli korzystasz z SQL Server 2016 lub nowszego i możesz utworzyć tabelę w bazie danych użytkownika, utwórz następującą fikcyjną tabelę:
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
I użyj następującej definicji iTVF:
CREATE OR ALTER FUNCTION dbo.GetNumsItzikBatch(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO Użyj następującego kodu, aby go przetestować (upewnij się, że zaznaczono opcję Odrzuć po wykonaniu):
SELECT n FROM dbo.GetNumsItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Ten kod kończy się na moim komputerze za 18 sekund.
Jeśli z jakiegoś powodu nie możesz spełnić wymagań rozwiązania przetwarzania wsadowego, przesyłam następującą definicję funkcji jako moje drugie rozwiązanie:
CREATE OR ALTER FUNCTION dbo.GetNumsItzik(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO Użyj następującego kodu, aby to przetestować:
SELECT n FROM dbo.GetNumsItzik(1, 100000000) OPTION(MAXDOP 1);
Ten kod kończy się w ciągu 24 sekund na moim komputerze.
Twoja kolej!