Obecnie istnieje wiele sposobów skontaktowania się z kimś, prawda?
Dysponujemy różnymi telefonami:komórkowymi i stacjonarnymi, osobistymi i służbowymi. Mamy różne adresy – mieszkalny, pocztowy, rozliczeniowy, służbowy itp. – i prawdopodobnie kilka adresów e-mail. Nie zapomnij o Skype i różnych aplikacjach do przesyłania wiadomości. Teraz dodaj LinkedIn i Facebooka – które, nawiasem mówiąc, mają swoje własne elementy wiadomości.
Nie tak dawno wiele z nich nie istniało. Możesz więc prawie zagwarantować, że za kilka lat będziemy mieli nowy sposób kontaktowania się z ludźmi i organizacjami.
Czy możemy zamodelować wszystkie te dane kontaktowe w taki sposób, abyśmy nie musieli zmieniać projektu naszej bazy danych, gdy pojawi się „najnowsza rzecz”? Czytaj dalej, aby dowiedzieć się…
Model punktu kontaktowego partii
Jednym słowem tak. Bazy danych można zaprojektować tak, aby pomieścić informacje, których nawet jeszcze nie mamy.
Wskoczę od razu i pokażę rozwiązanie, a następnie opiszę, jak te elementy współpracują ze sobą. Zadzwonię do różnych sposobów kontaktowania się ze stronami punktami kontaktowymi , chociaż widziałem metody kontaktu a nawet lokalizacje kontaktów używany.
Fizycznie wszystkie te punkty kontaktowe będą przechowywane w jednej kolumnie tabeli, contact_point.contact_value . Pomyśl o numerze telefonu, adresie e-mail lub adresie internetowym (URL), a zrozumiesz, dlaczego możemy je wszystkie tutaj przechowywać; na tym poziomie są tylko stringami (varcharami). Rozróżnienie tkwi w metadanych. Jedynym wyjątkiem jest adres pocztowy, który zostanie opisany bardziej szczegółowo później.
Żółte tabele po lewej stronie zawierają metadane, a niebieskie tabele po prawej zawierają dane biznesowe.
Główne kategorie
Chociaż mamy wiele sposobów skontaktowania się z kimś, te sposoby faktycznie dzielą się na niewielką liczbę kategorii lub typów. Zobaczysz, co mam na myśli, gdy spojrzysz na poniższą listę:
| Typ punktu kontaktowego |
|---|
| Numer telefonu (stacjonarny) |
| Numer komórkowy |
| Numer faksu |
| Adres e-mail |
| Adres pocztowy |
| Adres internetowy |
| Pager |
W pewnym sensie są one fizycznie odrębne. Oczywiście możesz użyć telefonu komórkowego, aby zadzwonić na numer stacjonarny lub inny telefon komórkowy. Jeśli chodzi o połączenia głosowe między telefonami stacjonarnymi i komórkowymi, rozróżnienie nie jest tak ważne. Mimo to bardziej prawdopodobne jest, że wyślemy SMS-a na telefon komórkowy niż na stacjonarny.
Ale prawdopodobnie nie będziesz celowo dzwonić pod numer faksu. W końcu, co mu powiesz, gdy go usłyszysz, oprócz „Ups, zły numer”? Oczywiście dużo bardziej prawdopodobne jest, że zadzwonisz za pomocą innego faksu, niezależnie od tego, czy jest to urządzenie fizyczne, czy emulowane. Nie wyślesz też listu na telefon stacjonarny ani nie spróbujesz nawiązać połączenia głosowego na adres pocztowy.
Ważne jest, abyśmy rozróżniali te typy, ponieważ inaczej się z nimi obcujemy. Będzie to szczególnie ważne, jeśli Twoja aplikacja jest w jakikolwiek sposób zintegrowana z usługami komunikacyjnymi. Musi wiedzieć, z jakim typem wchodzić w interakcje.
Jak strony wykorzystują punkty kontaktowe
Jest to prawdopodobnie nieco bardziej intuicyjne, bardziej zgodne z tym, jak myślimy o typach kontaktów. Oto dłuższa lista (ale nie wyczerpująca!), która pomoże Ci wyczuć te typy:
| Typ osoby kontaktowej (typ punktu kontaktowego) |
|---|
| Linia konferencyjna (numer telefonu) |
| Adres rozliczeniowy (adres pocztowy) |
| Adres dostawy (adres pocztowy) |
| Linia bezpośrednia (numer telefonu) |
| Adres wakacyjny/urlop (adres pocztowy) |
| Telefon wakacyjny/urlopowy (numer telefonu) |
| Adres domowy (adres pocztowy) |
| Telefon domowy (numer telefonu) |
| Telefon domowy/faks (numer telefonu) |
| Profil LinkedIn (adres internetowy) |
| Adres główny (adres pocztowy) |
| Główny adres e-mail (adres e-mail) |
| Główny faks (numer faksu) |
| Telefon główny (numer telefonu) |
| Główna strona internetowa (adres internetowy) |
| Osobisty adres e-mail (adres e-mail) |
| Osobisty faks (numer faksu) |
| Osobisty telefon komórkowy (numer telefonu komórkowego) |
| Osobisty pager (Pager) |
| Osobista witryna (adres internetowy) |
| Adres dodatkowy (adres pocztowy) |
| Telefon dodatkowy (numer telefonu) |
| Profil mediów społecznościowych (adres internetowy) |
| Adres pracy (adres pocztowy) |
| Służbowy adres e-mail (adres e-mail) |
| Faks służbowy (numer faksu) |
| Komórka służbowa (numer telefonu komórkowego) |
| Telefon służbowy (numer telefonu) |
Adres pocztowy – szczególny przypadek
Wszystkie te typy punktów kontaktowych są przechowywane w jednym polu, z wyjątkiem adresu pocztowego. Zwykle wymaga to kilku linii (lub pól).
Jest tutaj artykuł na blogu, który proponuje prosty, niezależny od języka sposób przechowywania adresów pocztowych. Jeśli Twoje wymagania są raczej podstawowe – np. do drukowania etykiet adresowych w miarę ich wprowadzania do systemu – to podejście prawdopodobnie wystarczy. Jeśli Twoje potrzeby są bardziej wyrafinowane, prawdopodobnie będziesz musiał opracować inne rozwiązanie.
Aby zorientować się, jak złożone może być adresowanie, rzuć okiem na ten schemat dla typów adresów British Standard BS7666. Norma składa się z szeregu części obejmujących Gazeterów Ulic, Gazeterów Gruntów i Nieruchomości oraz punkty dostaw. Nie rozróżnia nieruchomości komercyjnych i mieszkaniowych; pomiędzy gruntami zajętymi, zabudowanymi lub niezabudowanymi; między obszarami miejskimi lub wiejskimi; lub między podmiotami, które można adresować pocztowo, a podmiotami, które nie mają adresu pocztowego takich jak maszty komunikacyjne (wieże). Aby to osiągnąć, wprowadza terminy, których większość z nas prawdopodobnie nie zna, takie jak podstawowy obiekt adresowalny (PAO), czyli nazwa nadana obiektowi adresowalnemu, który można zaadresować bez odniesienia do innego obiektu adresowalnego. Znane przykłady PAO obejmują nazwę budynku lub numer ulicy. Wtórny obiekt adresowalny (SAO) jest nadawany dowolnemu obiektowi adresowalnemu, który jest adresowany przez odniesienie do PAO. Może to być pierwsze piętro nazwanego budynku.
Aby dać nam wizualizację tego, szybko przekształciłem to w narzędzie do modelowania UML. Oto, co otrzymujemy:
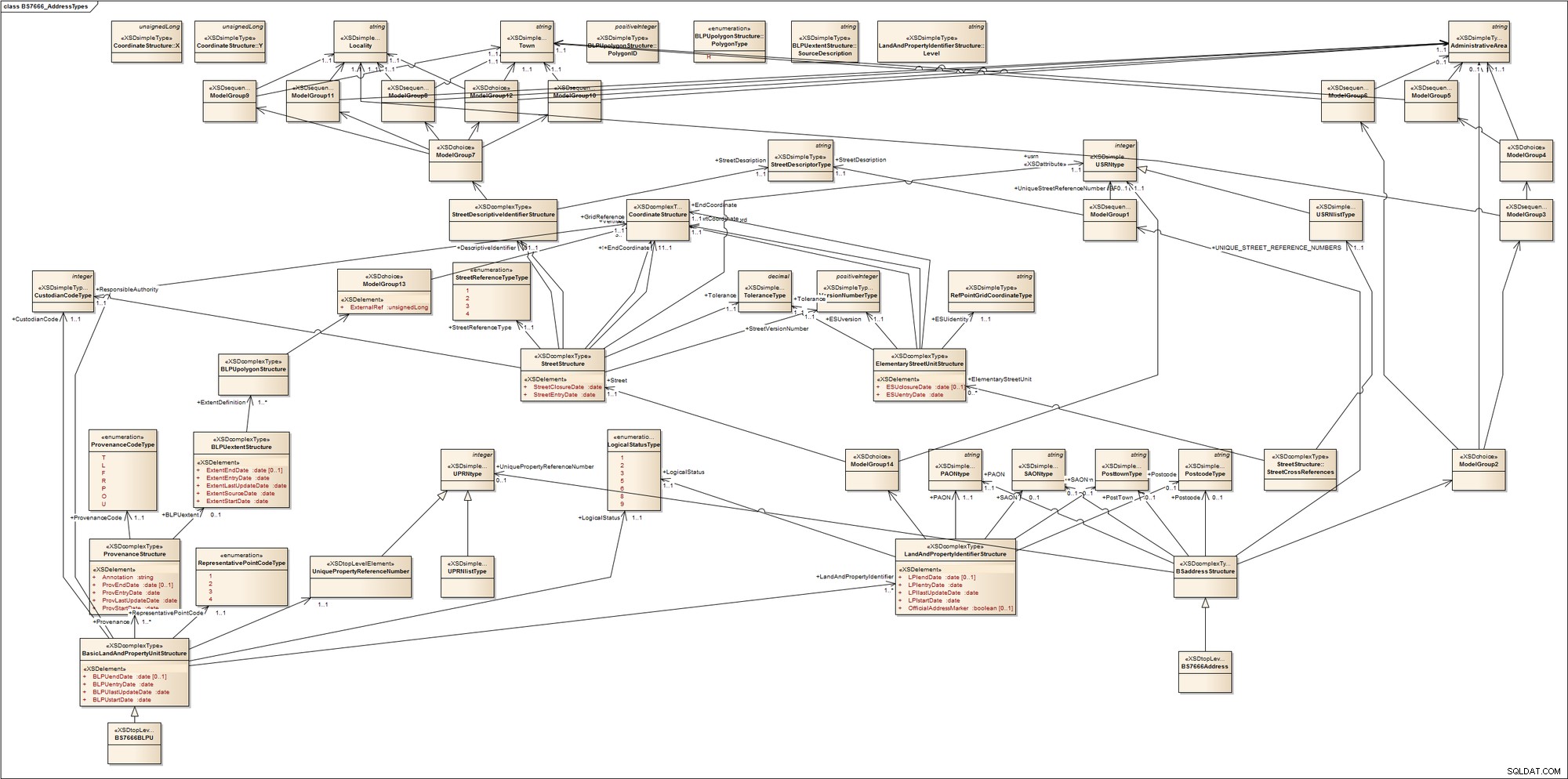
Chodzi mi o to, że może się to stać dość skomplikowane i niechlujne; adresowanie w niektórych domenach może być rzeczywiście bardzo złożone.
Gdybyś miał spłaszczyć to do pojedynczej tabeli relacyjnej, otrzymasz coś takiego:
Chociaż przechwytuje to składniki adresu BS7666, nie mówi, jak działa model. Cała logika relacyjna schematu XML zostaje ukryta w logice aplikacji.
Te dwa diagramy przedstawiają dwie ekstrema modelowania danych . Ale czy istnieje pośredni sposób modelowania adresów?
Rzeczywiście możliwe jest posiadanie stosunkowo prostego modelu adresu, który jest elastyczny i konfigurowalny.
Składniki adresu
Składnik adresu to zazwyczaj wiersz na etykiecie adresowej, a raczej rodzaj wiersza na etykiecie adresowej. Rodzaje komponentów, których zwykle używamy dla adresów w Wielkiej Brytanii, wymieniono w poniższej tabeli:
| Typ składnika adresu |
|---|
| Adresat |
| Obszar |
| Nazwa budynku |
| Numer budynku |
| Kraj |
| Powiat |
| Nazwa działu |
| Lokalizacja zależna |
| Nazwa zależnej drogi przelotowej |
| Podwójnie zależna lokalizacja |
| Międzynarodowy kod pocztowy |
| Poziom |
| Miejscowość |
| SSC sortowania poczty |
| Nazwa organizacji |
| Numer końcowy PAO |
| Końcowy przyrostek PAO |
| Numer początkowy PAO |
| Sufiks początkowy PAO |
| Tekst PAO |
| Skrytka pocztowa |
| Kod pocztowy |
| Poczta |
| Kod pocztowy |
| Typ kodu pocztowego |
| Numer końcowy SAO |
| Sufiks końcowy SAO |
| Numer początkowy SAO |
| Sufiks początkowy SAO |
| Tekst SAO |
| Ulica |
| Opis ulicy |
| Nazwa podbudynku |
| Nazwa przelotu |
| Miasto |
Możesz mieć trzy lub cztery wiersze adresu, a także miasto pocztowe i kod pocztowy. Jednak trudność, jaką napotkasz, polega na określeniu, co faktycznie zawierają te wiersze kiedy ma to znaczenie – np. podczas mapowania danych między systemami. Kiedy przeprowadzasz profilowanie danych, zauważysz, że wiersz adresu 3 czasami zawiera zależną miejscowość, ale innym razem zawiera hrabstwo lub miejscowość. Teraz zajmujesz się przetwarzaniem języka naturalnego (NLP); musisz rozpoznać różnicę między miejscowością a powiatem. A permutacje mnożą się w miarę dodawania kolejnych krajów.
Dlatego musimy zdefiniować wszystkie składniki adresu dla wszystkich krajów, w których działamy.
Formaty adresu
Formaty adresów składają się z dwóch części:nagłówka i jego szczegółów. Nagłówek to w zasadzie nazwa lub tytuł formatu adresu jest znany przez. Przykłady mogą obejmować:
| Typ formatu adresu |
|---|
| Ogólny 3-wierszowy |
| Ogólny 5-wierszowy |
| Poczta Sił Brytyjskich (BFPO) |
| Międzynarodowe |
| Adres poczty (PAF) |
| Stany Zjednoczone Adres |
| Adres francuski |
Biorąc jako przykład brytyjski pełny format adresu pocztowego (PAF), definiujemy następujące elementy formatu adresu:
| Format | Komponent | Sekwencja | Czy jest obowiązkowe? |
|---|---|---|---|
| PAF | Adresat | 1 | N |
| PAF | Nazwa organizacji | 2 | N |
| PAF | Nazwa działu | 3 | N |
| PAF | Skrytka pocztowa | 4 | N |
| PAF | Nazwa budynku | 5 | N |
| PAF | Nazwa podbudynku | 6 | N |
| PAF | Numer budynku | 7 | N |
| PAF | Dojazd | 8 | N |
| PAF | Ulica | 9 | N |
| PAF | Podwójnie zależna lokalizacja | 10 | N |
| PAF | Lokalizacja zależna | 11 | N |
| PAF | Poczta | 12 | T |
| PAF | Kod pocztowy | 13 | T |
Nasza aplikacja odczytuje te metadane i wyświetla składniki adresu we właściwej kolejności. Gdy wymagane jest przechwytywanie adresu, metadane informują nas, czy składnik adresu jest obowiązkowy, czy nie.
Coraz częściej nasza aplikacja żąda kodu pocztowego od użytkownika końcowego i wyszukuje odpowiednie wartości oraz automatycznie wypełnia składniki adresu. Niektóre aplikacje pozwalają użytkownikowi na edycję adresu; inne [irytujące] nie!
Nie jest to pokazane w PDM, ale jeśli Twoja organizacja działa na arenie międzynarodowej, możesz zdefiniować relację wiele-do-wielu między address_format_type i country aby właściwy format adresu (na podstawie kraju użytkownika) był prezentowany użytkownikowi końcowemu (party ).
Kiedy i tylko wtedy, gdy contact_point to adres pocztowy contact_point_type , musi mieć związek z typem_formatu_adresu. Z drugiej strony wynika z tego, że inne typy adresów nigdy mieć związek z address_format_type . Ponadto format musi pozostać stały na całe życie contact_point , w przeciwnym razie wprowadzisz możliwość problemów z integralnością danych. (Aby tak nie było , docelowy address_format_components musi być podzbiorem źródła address_format_components ).
Kolumna contact_value nie ma znaczenia dla adresu pocztowego, ponieważ wartości są przechowywane w ddress_line.line_content . I odwrotnie, contact_value jest obowiązkowe dla wszystkich innych contact_point_types . Zasadniczo contact_point.contact_value i address_line.line_content wzajemnie się wykluczają.
Relacja wiele-do-wielu między partią a punktem kontaktowym
Możesz pomyśleć o contact_point (plus address_line ) jako zawierające wartości i party_contact jako określenie użycia. Umożliwia to pojedynczy contact_point mieć wiele zastosowań . Nasz domowy adres [pocztowy] może być również naszym adresem rozliczeniowym i adresem dostawy, w zależności od kontekstu.
Jak dotąd narracja zakładała, że strona posiada określony contact_point . Ale model danych nie narzuca tej zasady własności! Nie wprowadza żadnych takich ograniczeń. W przypadku tego projektu istnieje inna możliwość:wiele stron dla tych samych punktów kontaktowych.
Musisz dokładnie rozważyć implikacje, zanim wyruszysz tą drogą.
Oto przykład. W Wielkiej Brytanii organizacje przyznające (AOs) zazwyczaj zatrudniają nauczycieli jako egzaminatorów. Nauczyciel ma dwie relacje:jedną ze szkołą, w której pracuje, a drugą z AO jako egzaminatorem. Szkoła będzie miała bank contact_points z różnymi numerami telefonów i ewentualnie jednym lub kilkoma adresami pocztowymi. Będą to takie rzeczy jak główny adres szkoły (adres pocztowy), główny e-mail (adres e-mail), główny faks (numer faksu) i główny telefon (numer telefonu).
Jest całkiem możliwe, że nasz egzaminator może używać tych samych contact_points jako swoją szkołę, ale użyje party_contact zdefiniować je jako związane z pracą. Jeśli zmieni się główny numer telefonu szkoły, numer służbowy nauczyciela zostanie automatycznie zaktualizowany, co jest całkiem miłe.
Jeśli pójdziesz tą drogą, musisz zdefiniować na poziomie aplikacji która strona lub strony mogą aktualizować contact_points .
Szybkie słowo o wydajności
Żółte tabele metadanych będą stale używane przez zapytania. W konsekwencji prawdopodobnie pozostaną w pamięci. W większości systemów RDBMS można przypiąć tabele do pamięci, aby to zapewnić. W Oracle utworzyłbym je jako tabele zorganizowane według indeksu, które są małe i dobrze działają. Zrób to, co jest odpowiednikiem dla twojego RDBMS.
Chcesz również upewnić się, że party_contact wiersze są umieszczone w tym samym bloku (lub stronie) przy użyciu indeksu klastrowego na party_id . Zrób to samo z address_line.contact_point_id . Zmniejsza to ilość IO.
Istnieje inna opcja, jeśli chcesz party wyłączne posiadanie contact_point . Następnie możesz scalić contact_point w party_contact aby utworzyć party_contact_point (nadal zgrupowane na party_id ). Upraszcza to model i może poprawić wydajność.
Zmiana kontaktów nie oznacza zmiany baz danych
Żyjemy w czasach, kiedy można powiedzieć, że zmiana jest jedyną stałą.
Nie oznacza to, że za każdym razem, gdy coś się zmieni, musi to wpłynąć na Twoją bazę danych. Przy odrobinie namysłu możemy zabezpieczyć nasze projekty na przyszłość – być może więcej niż dotychczas. Takie postępowanie pomaga nam szybko reagować na nieuniknioną zmianę.
Jeśli rozpoczynasz projekt od podstaw, sugerowałbym wykorzystanie Modelu Partii (którego częścią jest Contact Point) dla organizacji i osób. Dlaczego nie otworzyć modelu i dostosować go do swoich potrzeb? Zachęcamy do pobrania kopii i zrobienia jej własnej.
Ale jeśli twoja baza danych lub bazy danych są już określone, schemat, który tutaj przedstawiłem, nadal może być używany, w formie XML, do definiowania ładunku podczas integracji danych między systemami.



