W moim poprzednim artykule rozpocząłem nową serię na temat zatrzasków, wyjaśniając, czym one są, dlaczego są potrzebne i jak działają, i zdecydowanie zalecam przeczytanie tego artykułu przed tym. W tym artykule omówię zatrzask FGCB_ADD_REMOVE i pokażę, jak może być wąskim gardłem.
Co to jest zatrzask FGCB_ADD_REMOVE?
Większość nazw klas zatrzasków jest bezpośrednio powiązana ze strukturą danych, którą chronią. Zatrzask FGCB_ADD_REMOVE chroni strukturę danych o nazwie FGCB lub blok kontrolny grupy plików, a dla każdej grupy plików online każdej bazy danych online w wystąpieniu programu SQL Server będzie jeden z tych zatrzasków. Za każdym razem, gdy plik w grupie plików jest dodawany, odrzucany, powiększany lub zmniejszany, zatrzask musi zostać uzyskany w trybie EX, a podczas określania następnego pliku do przydzielenia, zatrzask musi zostać nabyty w trybie SH, aby zapobiec zmianom grupy plików. (Pamiętaj, że alokacje zakresu dla grupy plików są wykonywane na zasadzie round-robin za pośrednictwem plików w grupie plików, a także uwzględniają wypełnienie proporcjonalne , co wyjaśniam tutaj.)
W jaki sposób zatrzask staje się wąskim gardłem?
Najczęstszy scenariusz, kiedy ten zatrzask staje się wąskim gardłem, jest następujący:
- Istnieje jednoplikowa baza danych, więc wszystkie alokacje muszą pochodzić z tego jednego pliku danych
- Ustawienie automatycznego powiększania dla pliku jest ustawione na bardzo małe (pamiętaj, że przed SQL Server 2016 domyślne ustawienie automatycznego powiększania dla plików danych wynosiło 1 MB!)
- Istnieje wiele jednoczesnych operacji wymagających przydzielenia miejsca (np. stałe obciążenie wstawiania z wielu połączeń klientów)
W takim przypadku, mimo że istnieje tylko jeden plik, wątek wymagający alokacji nadal musi uzyskać zatrzask FGCB_ADD_REMOVE w trybie SH. Następnie spróbuje dokonać alokacji z pojedynczego pliku danych, zorientuje się, że nie ma miejsca, a następnie uzyska zatrzask w trybie EX, aby następnie mógł powiększyć plik.
Wyobraźmy sobie, że osiem wątków działających na ośmiu oddzielnych programach planujących próbuje przydzielić w tym samym czasie i wszyscy zdają sobie sprawę, że w pliku nie ma miejsca, więc muszą go powiększyć. Każda próba zdobycia zatrzasku w trybie EX. Tylko jeden z nich będzie w stanie go uzyskać i zacznie powiększać plik, a pozostali będą musieli czekać, z typem oczekiwania LATCH_EX i opisem zasobu FGCB_ADD_REMOVE plus adres pamięci zatrzasku.
Siedem oczekujących wątków znajduje się w kolejce oczekiwania pierwszego wejścia, pierwszego wyjścia (FIFO) zatrzasku. Gdy wątek wykonujący wzrost pliku zostanie zakończony, zwalnia zatrzask i przyznaje go pierwszemu oczekującemu wątkowi. Ten nowy właściciel zatrzasku zaczyna rozwijać plik i odkrywa, że już został wyhodowany i nie ma nic do zrobienia. Więc zwalnia zatrzask i przyznaje go następnemu oczekującemu wątkowi. I tak dalej.
Siedem oczekujących wątków czekało na zatrzask w trybie EX, ale ostatecznie nic nie zrobiło, gdy otrzymali zatrzask, więc wszystkie siedem wątków zasadniczo zmarnowało upływ czasu, a ilość marnowanego czasu wzrastała trochę dla każdego wątku, im dalej w dół to była kolejka oczekujących FIFO.
Pokazuje wąskie gardło
Teraz pokażę dokładnie powyższy scenariusz, wykorzystując rozszerzone zdarzenia. Stworzyłem jednoplikową bazę danych z niewielkim ustawieniem automatycznego powiększania i setkami równoczesnych połączeń, po prostu wstawiając dane do tabeli.
Mogę użyć następującej rozszerzonej sesji wydarzenia, aby zobaczyć, co się dzieje:
-- Drop the session if it exists.
IF EXISTS
(
SELECT * FROM sys.server_event_sessions
WHERE [name] = N'FGCB_ADDREMOVE'
)
BEGIN
DROP EVENT SESSION [FGCB_ADDREMOVE] ON SERVER;
END
GO
CREATE EVENT SESSION [FGCB_ADDREMOVE] ON SERVER
ADD EVENT [sqlserver].[database_file_size_change]
(WHERE [file_type] = 0), -- data files only
ADD EVENT [sqlserver].[latch_suspend_begin]
(WHERE [class] = 48 AND [mode] = 4), -- EX mode
ADD EVENT [sqlserver].[latch_suspend_end]
(WHERE [class] = 48 AND [mode] = 4) -- EX mode
ADD TARGET [package0].[ring_buffer]
WITH (TRACK_CAUSALITY = ON);
GO
-- Start the event session
ALTER EVENT SESSION [FGCB_ADDREMOVE]
ON SERVER STATE = START;
GO Sesja jest śledzona, kiedy wątek wchodzi do kolejki oczekiwania zatrzasku, kiedy opuszcza kolejkę (tj. Kiedy otrzymuje zatrzask) i kiedy następuje wzrost pliku danych. Korzystając ze śledzenia przyczynowości, możemy zobaczyć oś czasu działań w każdym wątku.
Korzystając z SQL Server Management Studio, mogę wybrać opcję Watch Live Data dla rozszerzonej sesji zdarzenia i zobaczyć całą rozszerzoną aktywność zdarzenia. Jeśli chcesz zrobić to samo, w oknie Dane na żywo kliknij prawym przyciskiem myszy jedną z nazw kolumn u góry i zmień wybrane kolumny na takie, jak poniżej:
Pozwoliłem obciążeniu działać przez kilka minut, aby osiągnąć stan stabilny, a następnie zobaczyłem doskonały przykład opisanego powyżej scenariusza:
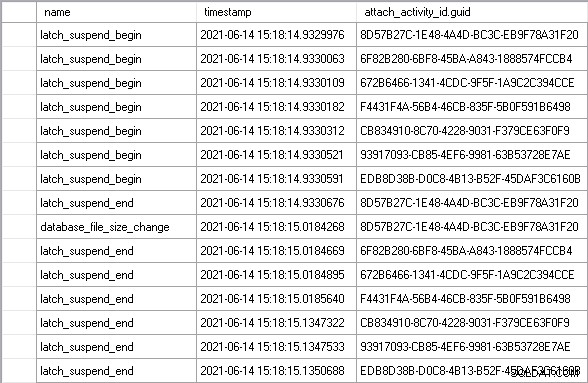
Korzystanie z attach_activity_id.guid wartości identyfikujących różne wątki, widzimy, że siedem wątków zaczyna czekać na zatrzask w ciągu 61,5 mikrosekund. Wątek z wartością GUID rozpoczynającą się od 8D57 uzyskuje zatrzask w trybie EX (latch_suspend_end zdarzenie), a następnie natychmiast powiększa plik (database_file_size_change wydarzenie). Wątek 8D57 następnie zwalnia zatrzask i przyznaje go w trybie EX wątkowi 6F82, który czekał 85 milisekund. Nie ma nic do zrobienia, więc przyznaje zatrzask wątku 672B. I tak dalej, dopóki wątek EDB8 nie otrzyma blokady, po odczekaniu 202 milisekund.
W sumie sześć wątków, które czekały bez powodu, czekało prawie 1 sekundę. Część tego czasu to czas oczekiwania na sygnał, gdzie nawet jeśli wątek uzyskał blokadę, nadal musi przejść na górę kolejki uruchomialnej harmonogramu, zanim będzie mógł dostać się do procesora i wykonać kod. Można powiedzieć, że nie jest to odpowiednia miara czasu spędzonego na oczekiwaniu na zatrzask, ale absolutnie tak jest, ponieważ czas oczekiwania na sygnał nie zostałby poniesiony, gdyby wątek nie musiał czekać w pierwszej kolejności.
Co więcej, możesz pomyśleć, że 200 milisekund opóźnienia to niewiele, ale wszystko zależy od umów dotyczących poziomu usług dotyczących wydajności dla danego obciążenia. Mamy wielu klientów na dużą skalę, w przypadku których wykonanie partii trwa dłużej niż 200 milisekund, nie jest to dozwolone w systemie produkcyjnym!
Podsumowanie
Jeśli monitorujesz oczekiwania na serwerze i zauważysz, że LATCH_EX jest jednym z najczęstszych, możesz użyć kodu w tym poście, więc sprawdź, czy FGCB_ADD_REMOVE jest jednym z winowajców.
Najprostszym sposobem na upewnienie się, że obciążenie nie napotyka wąskiego gardła FGCB_ADD_REMOVE, jest upewnienie się, że nie ma żadnych ustawień automatycznego powiększania plików danych, które są skonfigurowane przy użyciu ustawień domyślnych w wersji wcześniejszej niż SQL Server 2016. W sys.master_files widok, domyślnie 1 MB będzie wyświetlany jako plik danych (type_desc kolumna ustawiona na ROWS) z is_percent_growth kolumna ustawiona na 0, a kolumna wzrostu ustawiona na 128.
Zalecenie dotyczące tego, jaki powinien być automatyczny wzrost, to zupełnie inna dyskusja, ale teraz wiesz o potencjalnym wpływie na wydajność wynikającym z niezmieniania ustawień domyślnych we wcześniejszych wersjach.



