Po raz pierwszy wprowadzone w SQL Server 2017 Enterprise Edition, dołączanie adaptacyjne umożliwia przejście w czasie wykonywania z łączenia mieszającego w trybie wsadowym na skorelowane zagnieżdżone pętle w trybie wiersza, indeksowane (zastosowanie) łączenia w czasie wykonywania. Dla zwięzłości będę odnosić się do „skorelowanego indeksowanego łączenia zagnieżdżonych pętli” jako zastosuj przez resztę tego artykułu. Jeśli potrzebujesz odświeżenia na temat różnicy między zagnieżdżonymi pętlami a zastosowaniem, zapoznaj się z moim poprzednim artykułem.
To, czy łączenie adaptacyjne przechodzi z łączenia mieszającego do zastosowania w czasie wykonywania, zależy od wartości oznaczonej etykietą Adaptive Threshold Rows w Dołączeniu adaptacyjnym operator planu wykonania. Ten artykuł pokazuje, jak działa łączenie adaptacyjne, zawiera szczegóły obliczania progu i obejmuje konsekwencje niektórych dokonanych wyborów projektowych.
Wprowadzenie
Jedną rzeczą, o której chcę, abyś pamiętał w tym artykule, jest sprzężenie adaptacyjne zawsze rozpoczyna wykonywanie jako sprzężenie haszujące w trybie wsadowym. Dzieje się tak, nawet jeśli plan wykonania wskazuje, że złączenie adaptacyjne ma działać w trybie wiersza.
Podobnie jak w przypadku każdego sprzężenia mieszającego, sprzężenie adaptacyjne odczytuje wszystkie wiersze dostępne w jego danych wejściowych kompilacji i kopiuje wymagane dane do tabeli mieszającej. Funkcja łączenia mieszającego w trybie wsadowym przechowuje te wiersze w zoptymalizowanym formacie i dzieli je za pomocą co najmniej jednej funkcji mieszającej. Gdy dane wejściowe kompilacji zostaną wykorzystane, tabela mieszania jest w pełni zapełniona i podzielona na partycje, gotowa, aby sprzężenie mieszające zaczęło sprawdzać wiersze po stronie sondy pod kątem dopasowań.
Jest to punkt, w którym sprzężenie adaptacyjne podejmuje decyzję o kontynuowaniu łączenia mieszającego w trybie wsadowym lub o przejściu do trybu wierszowego. Jeśli liczba wierszy w tabeli skrótów jest mniejsza niż próg wartość, sprzężenie przełącza się na zastosowanie; w przeciwnym razie złączenie jest kontynuowane jako sprzężenie haszujące, zaczynając odczytywać wiersze z danych wejściowych sondy.
Jeśli nastąpi przejście do łączenia stosującego, plan wykonania nie odczytuje ponownie wierszy użytych do zapełnienia tabeli mieszającej, aby sterować operacją zastosowania. Zamiast tego wewnętrzny komponent znany jako adaptacyjny czytnik buforów rozszerza wiersze już zapisane w tablicy mieszającej i udostępnia je na żądanie zewnętrznym wejściu operatora Apply. Z czytnikiem bufora adaptacyjnego wiąże się koszt, ale jest on znacznie niższy niż koszt całkowitego przewinięcia danych wejściowych kompilacji.
Wybór przyłączenia adaptacyjnego
Optymalizacja zapytań obejmuje co najmniej jeden etap logicznej eksploracji i fizycznej implementacji alternatyw. Na każdym etapie, gdy optymalizator bada opcje fizyczne dla logicznego join, może rozważyć zarówno łączenie haszujące w trybie wsadowym, jak i tryb wierszowy, które stosują alternatywy.
Jeśli jedna z tych fizycznych opcji łączenia stanowi część najtańszego rozwiązania znalezionego na obecnym etapie — i drugi typ łączenia może dostarczyć te same wymagane właściwości logiczne — optymalizator oznacza grupę łączenia logicznego jako potencjalnie nadaje się do sprzężenia adaptacyjnego. Jeśli nie, rozważanie przyłączenia adaptacyjnego kończy się tutaj (i żadne zdarzenie rozszerzonego przyłączenia adaptacyjnego nie jest uruchamiane).
Normalne działanie optymalizatora oznacza, że najtańsze znalezione rozwiązanie będzie zawierało tylko jedną z fizycznych opcji łączenia — albo hash, albo Apply, w zależności od tego, która ma najniższy szacowany koszt. Następną rzeczą, jaką robi optymalizator, jest tworzenie i kosztowanie nowej implementacji typu sprzężenia, nie było wybrany jako najtańszy.
Ponieważ bieżąca faza optymalizacji zakończyła się już znalezieniem najtańszego rozwiązania, przeprowadzana jest specjalna pojedyncza runda eksploracji i wdrożenia dla połączenia adaptacyjnego. Na koniec optymalizator oblicza próg adaptacyjny .
Jeśli którakolwiek z poprzednich prac nie powiedzie się, rozszerzone zdarzenie adaptive_join_skiipped jest uruchamiane z powodu.
Jeśli przetwarzanie adaptacyjnego łączenia się powiedzie, Concat operator jest dodawany do planu wewnętrznego nad haszem i stosuje alternatywy za pomocą czytnika bufora adaptacyjnego i wszelkich wymaganych adapterów trybu wsadowego/wierszowego. Pamiętaj, że tylko jedna z alternatyw łączenia zostanie wykonana w czasie wykonywania, w zależności od liczby faktycznie napotkanych wierszy w porównaniu z progiem adaptacyjnym.
Konkat operator i poszczególne alternatywy skrótu/zastosowania nie są zwykle pokazywane w ostatecznym planie wykonania. Zamiast tego otrzymujemy jedno Dołączanie adaptacyjne operator. To tylko decyzja dotycząca prezentacji – Concat i sprzężenia są nadal obecne w kodzie uruchamianym przez aparat wykonawczy programu SQL Server. Więcej informacji na ten temat można znaleźć w sekcjach Dodatek i Czytanie pokrewne tego artykułu.
Adaptacyjny próg
Aplikacja jest zazwyczaj tańsza niż sprzężenie haszujące dla mniejszej liczby wierszy sterujących. Połączenie haszujące wiąże się z dodatkowym kosztem początkowym w celu zbudowania tabeli haszującej, ale niższym kosztem na wiersz, gdy zaczyna szukać dopasowań.
Zwykle jest punkt, w którym szacowany koszt zastosowania i łączenia mieszającego będzie równy. Pomysł ten został dobrze zilustrowany przez Joe Sack w jego artykule, Wprowadzenie adaptacyjnych złączeń w trybie wsadowym:
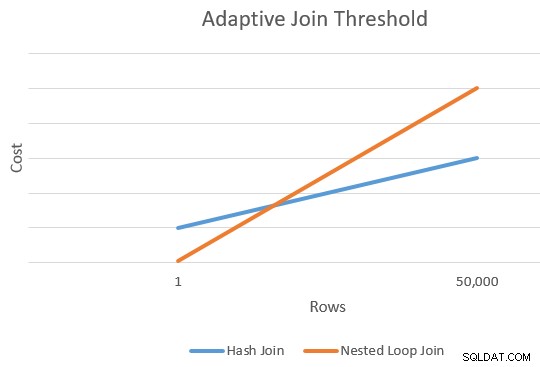
Obliczanie progu
W tym momencie optymalizator ma jedno oszacowanie liczby wierszy wprowadzających dane wejściowe kompilacji sprzężenia mieszającego i stosuje alternatywy. Zawiera również szacunkowy koszt skrótu i stosuje operatorów jako całość.
To daje nam pojedynczy punkt na skrajnej prawej krawędzi pomarańczowej i niebieskiej linii na powyższym schemacie. Optymalizator potrzebuje innego punktu odniesienia dla każdego typu złączenia, aby mógł „narysować linie” i znaleźć przecięcie (nie rysuje dosłownie linii, ale masz pomysł).
Aby znaleźć drugi punkt dla linii, optymalizator prosi dwa sprzężenia o wygenerowanie nowego oszacowania kosztów w oparciu o inną (i hipotetyczną) kardynalność wejściową. Jeśli pierwsze oszacowanie liczności było większe niż 100 wierszy, prosi sprzężenia o oszacowanie nowych kosztów dla jednego wiersza. Jeśli pierwotna liczność była mniejsza lub równa 100 rzędom, drugi punkt jest oparty na liczności wejściowej 10 000 rzędów (a więc jest wystarczająco przyzwoity zakres do ekstrapolacji).
W każdym razie wynikiem są dwa różne koszty i liczba wierszy dla każdego typu złączenia, co pozwala na „rysowanie linii”.
Wzór przecięcia
Znalezienie przecięcia dwóch linii na podstawie dwóch punktów dla każdej linii to problem z kilkoma dobrze znanymi rozwiązaniami. SQL Server używa jednego na podstawie wyznaczników zgodnie z opisem w Wikipedii:
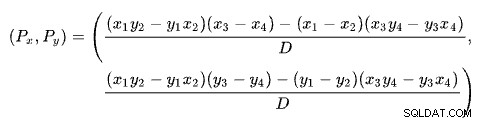
gdzie:
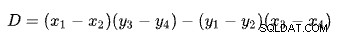
Pierwsza linia jest zdefiniowana przez punkty (x1 , y1 ) i (x2 , y2 ). Druga linia jest określona przez punkty (x3 , y3 ) i (x4 , y4 ). Skrzyżowanie znajduje się w (Px , Py ).
Nasz schemat zawiera liczbę wierszy na osi x i szacowany koszt na osi y. Interesuje nas liczba rzędów, w których przecinają się linie. Daje to wzór na Px . Gdybyśmy chcieli poznać szacunkowy koszt na skrzyżowaniu, byłby to Py .
Dla Px wierszy, szacunkowe koszty rozwiązań Apply i Hash Join byłyby równe. To jest próg adaptacyjny, którego potrzebujemy.
Sprawny przykład
Oto przykład wykorzystujący przykładową bazę danych AdventureWorks2017 i następującą sztuczkę indeksowania autorstwa Itzika Ben-Gana, aby uzyskać bezwarunkowe rozważenie wykonania w trybie wsadowym:
-- Sztuczka Itzika TWORZENIE INDEKSU KOLUMNOWEGO NIESKLASTRAROWONEGO Tryb BatchModeON Sales.SalesOrderHeader (SalesOrderID)WHERE SalesOrderID =-1AND SalesOrderID =-2; -- Testowe zapytanieSELECT SOH.SubTotalFROM Sales.SalesOrderHeader AS SOHJOIN Sales.SalesOrderDetail AS SOD ON SOD.SalesOrderID =SOH.SalesOrderIDWHERE SOH.SalesOrderID <=75123;
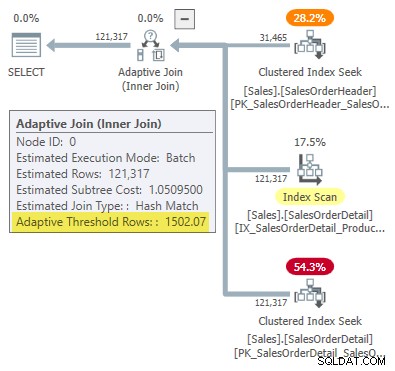
Plan wykonania pokazuje przyłączanie adaptacyjne z progiem 1502,07 wiersze:
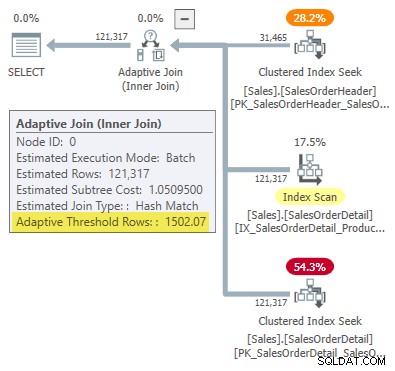
Szacunkowa liczba wierszy napędzających sprzężenie adaptacyjne to 31 465 .
Koszty przyłączenia
W tym uproszczonym przypadku możemy znaleźć szacunkowe koszty poddrzewa dla hasha i zastosować alternatywy łączenia za pomocą podpowiedzi:
-- HashSELECT SOH.SubTotalFROM Sales.SalesOrderHeader AS SOHJOIN Sales.SalesOrderDetail AS SOD ON SOD.SalesOrderID =SOH.SalesOrderIDWHERE SOH.SalesOrderID <=75123OPTION (HASH JOIN, MAXDOP 1);

-- ApplySELECT SOH.SubTotalFROM Sales.SalesOrderHeader AS SOHJOIN Sales.SalesOrderDetail AS SOD ON SOD.SalesOrderID =SOH.SalesOrderIDWHERE SOH.SalesOrderID <=75123OPTION (LOOP JOIN, MAXDOP 1);
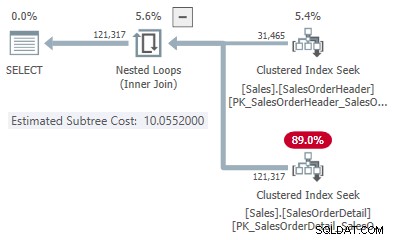
To daje nam jeden punkt na linii dla każdego typu połączenia:
- 31 465 wierszy
- Koszt skrótu 1.05083
- Zastosuj koszt 10.0552
Drugi punkt na linii
Ponieważ szacowana liczba wierszy jest większa niż 100, drugie punkty odniesienia pochodzą ze specjalnych wewnętrznych szacunków opartych na jednym wierszu wejściowym złączenia. Niestety, nie ma łatwego sposobu na uzyskanie dokładnych liczb kosztów dla tych wewnętrznych obliczeń (więcej na ten temat opowiem wkrótce).
Na razie pokażę ci tylko liczby kosztów (przy użyciu pełnej wewnętrznej precyzji, a nie sześciu znaczących liczb przedstawionych w planach wykonania):
- Jeden wiersz (obliczenia wewnętrzne)
- Koszt skrótu 0,999027422729
- Zastosuj koszt 0.547927305023
- 31 465 wierszy
- Koszt skrótu 1.05082787359
- Zastosuj koszt 10.0552890166
Zgodnie z oczekiwaniami, zastosowanie join jest tańsze niż hash dla małej liczności danych wejściowych, ale znacznie droższe dla oczekiwanej liczności 31 465 wierszy.
Obliczanie skrzyżowania
Wstawienie tych liczb kardynalności i kosztu do formuły przecięcia linii daje następujące wyniki:
-- Punkty skrótu (x =liczność; y =koszt) DECLARE @x1 float =1, @y1 float =0.999027422729, @x2 float =31465, @y2 float =1.05082787359; -- Zastosuj punkty (x =liczność; y =koszt) DECLARE @x3 float =1, @y3 float =0.547927305023, @x4 float =31465, @y4 float =10.0552890166; -- Formuła:WYBIERZ Próg =( (@x1 * @y2 - @y1 * @x2) * (@x3 - @x4) - (@x1 - @x2) * (@x3 * @y4 - @y3 * @x4 ) ) / ( (@x1 - @x2) * (@y3 - @y4) - (@y1 - @y2) * (@x3 - @x4) ); -- Zwraca 1502.06521571273
Zaokrąglony do sześciu cyfr znaczących, ten wynik odpowiada 1502.07 wiersze pokazane w planie wykonania połączeń adaptacyjnych:
Wada czy projekt?
Pamiętaj, że SQL Server potrzebuje czterech punktów, aby „narysować” liczbę wierszy w porównaniu z liniami kosztów, aby znaleźć próg adaptacyjnego łączenia. W obecnym przypadku oznacza to znalezienie szacunkowych kosztów dla kardynalności jednorzędowej i 31 465-wierszowej zarówno dla implementacji typu Apply, jak i łączenia mieszającego.
Optymalizator wywołuje procedurę o nazwie sqllang!CuNewJoinEstimate aby obliczyć te cztery koszty połączenia adaptacyjnego. Niestety, nie ma żadnych flag śledzenia ani rozszerzonych zdarzeń, które zapewniają przydatny przegląd tego działania. Zwykłe flagi śledzenia używane do badania zachowania optymalizatora i kosztów wyświetlania nie działają tutaj (więcej szczegółów znajdziesz w Załączniku).
Jedynym sposobem na uzyskanie jednowierszowych szacunków kosztów jest dołączenie debugera i ustawienie punktu przerwania po czwartym wywołaniu CuNewJoinEstimate w kodzie sqllang!CardSolveForSwitch . Użyłem WinDbg, aby uzyskać ten stos wywołań na SQL Server 2019 CU12:

W tym momencie kodu koszty zmiennoprzecinkowe o podwójnej precyzji są przechowywane w czterech lokalizacjach pamięci wskazywanych przez adresy w rsp+b0 , rsp+d0 , rsp+30 i rsp+28 (gdzie rsp jest rejestrem procesora, a przesunięcia są szesnastkowe):

Przedstawione liczby kosztów w poddrzewie operatora odpowiadają tym użytym we wzorze obliczania progu adaptacyjnego łączenia.
Informacje o jednowierszowych szacunkowych kosztach
Być może zauważyłeś, że szacunkowe koszty poddrzewa dla złączeń jednorzędowych wydają się dość wysokie, biorąc pod uwagę nakład pracy związany z łączeniem jednego wiersza:
- Jeden rząd
- Koszt skrótu 0,999027422729
- Zastosuj koszt 0.547927305023
Jeśli spróbujesz stworzyć jednowierszowe plany wykonania danych wejściowych dla łączenia mieszającego i zastosujesz przykłady, zobaczysz dużo niższe szacowane koszty poddrzewa przy łączeniu niż te pokazane powyżej. Podobnie uruchomienie oryginalnego zapytania z celem wiersza równym jeden (lub liczbą wierszy wyjściowych sprzężenia oczekiwaną dla danych wejściowych jednego wiersza) również da szacunkowy koszt sposób niższa niż pokazano.
Powodem jest CuNewJoinEstimate rutyna szacuje jeden wiersz w taki sposób, jak sądzę, że większość ludzi nie uznałaby to za intuicyjne.
Ostateczny koszt składa się z trzech głównych elementów:
- Koszt poddrzewa wejściowego kompilacji
- Lokalny koszt przyłączenia
- Koszt poddrzewa wejściowego sondy
Pozycje 2 i 3 zależą od typu sprzężenia. W przypadku sprzężenia mieszającego uwzględniają one koszt odczytania wszystkich wierszy z danych wejściowych sondy, dopasowując je (lub nie) do jednego wiersza w tabeli mieszającej i przekazując wyniki do następnego operatora. W przypadku zastosowania koszty pokrywają jedno poszukiwanie na niższych danych wejściowych do złączenia, wewnętrzny koszt samego złączenia i zwracanie dopasowanych wierszy do operatora nadrzędnego.
Nic z tego nie jest niezwykłe ani zaskakujące.
Niespodzianka kosztowa
Niespodzianka pojawia się po stronie kompilacji złączenia (pozycja 1 na liście). Można by oczekiwać, że optymalizator wykona jakieś wymyślne obliczenia, aby przeskalować już obliczony koszt poddrzewa dla 31 465 wierszy do jednego wiersza średniego lub coś w tym stylu.
W rzeczywistości zarówno hash, jak i szacunkowe łączenie jednowierszowe po prostu wykorzystują cały koszt poddrzewa dla oryginalnego oszacowanie kardynalności 31 465 wierszy. W naszym przykładzie to „poddrzewo” to 0,54456 koszt wyszukiwania indeksu klastrowego w trybie wsadowym w tabeli nagłówków:
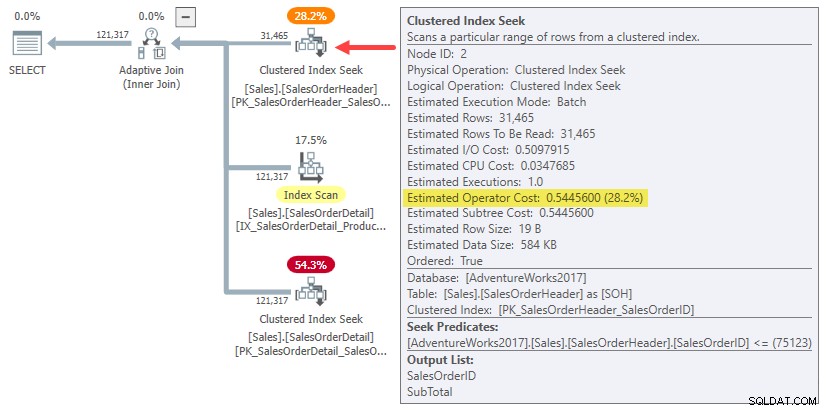
Aby było jasne:szacunkowe koszty po stronie kompilacji dla alternatywnych połączeń jednorzędowych wykorzystują koszt wejściowy obliczony dla 31 465 wierszy. To powinno wydać ci się trochę dziwne.
Przypominamy, że koszty jednowierszowe obliczone przez CuNewJoinEstimate były następujące:
- Jeden rząd
- Koszt skrótu 0,999027422729
- Zastosuj koszt 0.547927305023
Jak widać, całkowity koszt zastosowania (~0,54793) jest zdominowany przez 0,54456 koszt poddrzewa strony budowania, z niewielką dodatkową kwotą za pojedyncze wyszukiwanie strony wewnętrznej, przetwarzanie małej liczby wynikowych wierszy w ramach złączenia i przekazywanie ich do operatora nadrzędnego.
Szacowany koszt jednowierszowego łączenia mieszającego jest wyższy, ponieważ strona sondująca planu składa się z pełnego skanowania indeksu, w którym wszystkie wynikowe wiersze muszą przejść przez łączenie. Całkowity koszt jednowierszowego łączenia mieszającego jest nieco niższy niż pierwotny koszt 1.05095 dla przykładu z 31 465 wierszami, ponieważ w tabeli mieszającej jest teraz tylko jeden wiersz.
Implikacje
Można by oczekiwać, że oszacowanie jednowierszowego złączenia będzie oparte częściowo na koszcie dostarczenia jednego wiersza do wejścia sterującego złączeniem. Jak widzieliśmy, nie dotyczy to złączenia adaptacyjnego:zarówno alternatywy typu Apply, jak i hash są obarczone pełnym szacowanym kosztem dla 31 465 wierszy. Pozostała część połączenia kosztuje mniej więcej tyle, ile można by się spodziewać po jednowierszowej kompilacji.
Ten intuicyjnie dziwny układ sprawia, że trudno (a może nawet niemożliwe) pokazać plan wykonania odzwierciedlający wyliczone koszty. Musielibyśmy skonstruować plan dostarczający 31 465 wierszy do górnego wejścia sprzężenia, ale kosztować samo sprzężenie i jego wewnętrzne dane wejściowe tak, jakby był obecny tylko jeden wiersz. Trudne pytanie.
Efektem tego wszystkiego jest podniesienie skrajnego lewego punktu na naszym diagramie przecinających się linii w górę osi y. Ma to wpływ na nachylenie linii, a tym samym na punkt przecięcia.
Innym praktycznym efektem jest to, że obliczony próg adaptacyjnego łączenia zależy teraz od oryginalnego oszacowania kardynalności na wejściu kompilacji skrótu, jak zauważył Joe Obbish w swoim poście na blogu z 2017 roku. Na przykład, jeśli zmienimy WHERE klauzula w zapytaniu testowym do SOH.SalesOrderID <= 55000 , próg adaptacji zmniejsza się od 1502.07 do 1259.8 bez zmiany hasha planu zapytania. Ten sam plan, inny próg.
Dzieje się tak, ponieważ, jak widzieliśmy, wewnętrzne jednowierszowe oszacowanie kosztów zależy od kosztu wejściowego kompilacji dla pierwotnego oszacowania kardynalności. Oznacza to, że różne początkowe oszacowania po stronie kompilacji dadzą inny „wzmocnienie” osi y w stosunku do oszacowania jednego wiersza. Z kolei linia będzie miała inne nachylenie i inny punkt przecięcia.
Intuicja sugerowałaby, że jednowierszowe oszacowanie dla tego samego sprzężenia powinno zawsze dawać tę samą wartość niezależnie od innych szacunków kardynalności na linii (biorąc pod uwagę dokładnie to samo sprzężenie o tych samych właściwościach i rozmiarach wierszy ma związek zbliżony do liniowego pomiędzy kierowaniem wiersze i koszt). Nie dotyczy to złączenia adaptacyjnego.
Według projektu?
Mogę z pewną dozą pewności powiedzieć, co robi SQL Server podczas obliczania progu adaptacyjnego łączenia. Nie mam żadnego szczególnego wglądu w dlaczego robi to w ten sposób.
Mimo to istnieją powody, by sądzić, że to rozwiązanie jest celowe i zostało wprowadzone po należytym rozważeniu i informacjach zwrotnych z testów. Pozostała część tej sekcji obejmuje niektóre z moich przemyśleń na ten temat.
Adaptacyjne sprzężenie nie jest prostym wyborem między normalnym stosowaniem a mieszaniem w trybie wsadowym. Łączenie adaptacyjne zawsze zaczyna się od pełnego zapełnienia tablicy mieszającej. Dopiero po zakończeniu tej pracy podjęta zostanie decyzja o przejściu na wdrożenie aplikacji lub nie.
Do tego czasu ponieśliśmy już potencjalnie znaczne koszty wypełniania i partycjonowania sprzężenia mieszającego w pamięci. Może to nie mieć większego znaczenia w przypadku jednego rzędu, ale staje się coraz ważniejsze w miarę wzrostu kardynalności. Nieoczekiwane „wzmocnienie” może być sposobem na włączenie tych realiów do obliczeń przy jednoczesnym zachowaniu rozsądnego kosztu obliczeń.
Model kosztów SQL Server od dawna jest nieco stronniczy w stosunku do sprzężenia zagnieżdżonych pętli, prawdopodobnie z pewnym uzasadnieniem. Nawet idealny przypadek zastosowania indeksowanego może być w praktyce powolny, jeśli potrzebne dane nie znajdują się już w pamięci, a podsystem we/wy nie jest flashowany, zwłaszcza przy nieco losowym wzorcu dostępu. Ograniczone ilości pamięci i powolne operacje we/wy nie będą na przykład całkowicie obce użytkownikom słabszych silników baz danych opartych na chmurze.
Możliwe, że praktyczne testy w takich środowiskach wykazały, że intuicyjnie kosztowane adaptacyjne łączenie było zbyt szybkie, aby przejść do zastosowania. Teoria jest czasami świetna tylko w teorii.
Mimo to obecna sytuacja nie jest idealna; buforowanie planu opartego na niezwykle niskiej szacunkowej kardynalności spowoduje, że złącze adaptacyjne będzie o wiele bardziej niechętne do przejścia na zastosowanie, niż miałoby to miejsce w przypadku większego wstępnego oszacowania. Jest to różnorodny problem z wrażliwością na parametry, ale dla wielu z nas będzie to nowe rozwiązanie tego typu.
Teraz jest to również możliwe użycie pełnego kosztu poddrzewa danych wejściowych kompilacji dla skrajnego lewego punktu przecinających się linii kosztów jest po prostu niepoprawnym błędem lub przeoczeniem. Mam wrażenie, że obecna implementacja jest prawdopodobnie świadomym praktycznym kompromisem, ale potrzebujesz kogoś, kto ma dostęp do dokumentów projektowych i kodu źródłowego, aby wiedzieć na pewno.
Podsumowanie
Łączenie adaptacyjne umożliwia programowi SQL Server przejście z łączenia mieszającego w trybie wsadowym do zastosowania po pełnym wypełnieniu tabeli mieszania. Podejmuje tę decyzję, porównując liczbę wierszy w tabeli mieszającej z wstępnie obliczonym progiem adaptacyjnym.
Próg jest obliczany przez przewidywanie, gdzie zastosowanie i koszty łączenia mieszającego są równe. Aby znaleźć ten punkt, SQL Server tworzy drugi szacunkowy koszt złączenia wewnętrznego dla innej kardynalności wejściowej kompilacji — zwykle jeden wiersz.
Co zaskakujące, szacowany koszt oszacowania jednowierszowego obejmuje pełny koszt poddrzewa po stronie kompilacji dla oryginalnego oszacowania kardynalności (nieskalowany do jednego wiersza). Oznacza to, że wartość progowa zależy od oryginalnego oszacowania kardynalności na wejściu kompilacji.
W związku z tym złącze adaptacyjne może mieć nieoczekiwanie niską wartość progową, co oznacza, że jest znacznie mniej prawdopodobne, że złącze adaptacyjne odejdzie od złączenia mieszającego. Nie jest jasne, czy to zachowanie jest zgodne z projektem.
Powiązane czytanie
- Joe Sack przedstawia dołączanie adaptacyjne w trybie wsadowym
- Zrozumienie złączeń adaptacyjnych w dokumentacji produktu
- Adaptive Join Internals przez Dima Pilugin
- Jak działają adaptacyjne łączenia w trybie wsadowym? na temat wymiany stosów administratorów baz danych autorstwa Erika Darlinga
- Regresja adaptacyjnego łączenia Joe Obbisha
- Jeśli chcesz adaptacyjnych łączeń, potrzebujesz szerszych indeksów i czy jest większy, lepszy? autorstwa Erika Darlinga
- Wąchanie parametrów:Adaptacyjne złączenia Brenta Ozara
- Inteligentne przetwarzanie zapytań – pytania i odpowiedzi Joe Sack
Załącznik
Ta sekcja obejmuje kilka adaptacyjnych aspektów łączenia, które trudno było uwzględnić w tekście głównym w naturalny sposób.
Rozszerzony plan adaptacyjny
Możesz spróbować spojrzeć na wizualną reprezentację planu wewnętrznego przy użyciu nieudokumentowanej flagi śledzenia 9415, dostarczonej przez Dimę Pilugina w jego doskonałym artykule dotyczącym adaptacyjnych łączeń wewnętrznych, do którego link znajduje się powyżej. Gdy ta flaga jest aktywna, adaptacyjny plan łączenia dla naszego przykładu biegania wygląda następująco:
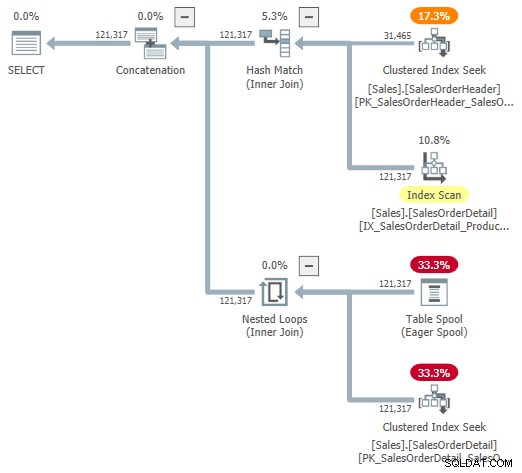
Jest to przydatne przedstawienie ułatwiające zrozumienie, ale nie jest całkowicie dokładne, kompletne ani spójne. Na przykład bufor tabeli nie istnieje — jest to domyślna reprezentacja czytnika bufora adaptacyjnego odczytywanie wierszy bezpośrednio z tabeli mieszającej trybu wsadowego.
Właściwości operatora i szacunki kardynalności są również nieco wszechobecne. Dane wyjściowe z czytnika bufora adaptacyjnego („bufora”) powinny zawierać 31 465 wierszy, a nie 121 317. Koszt poddrzewa aplikacji jest nieprawidłowo ograniczony przez koszt operatora nadrzędnego. Jest to normalne w przypadku showplanu, ale nie ma sensu w kontekście adaptacyjnego łączenia.
Istnieją również inne niespójności — zbyt wiele, by można je było użytecznie wymienić — ale może się to zdarzyć w przypadku nieudokumentowanych flag śledzenia. Przedstawiony powyżej rozszerzony plan nie jest przeznaczony dla użytkowników końcowych, więc być może nie jest to całkowicie zaskakujące. Przesłanie tutaj nie polega na zbyt dużym poleganiu na liczbach i właściwościach pokazanych w tej nieudokumentowanej formie.
Powinienem również wspomnieć, że ukończony standardowy operator planu adaptacyjnego łączenia nie jest całkowicie pozbawiony własnych problemów ze spójnością. Wynikają one w dużej mierze wyłącznie z ukrytych szczegółów.
Na przykład wyświetlane właściwości złączenia adaptacyjnego pochodzą z połączenia podstawowych funkcji Concat , Dołączanie haszujące i Zastosuj operatorów. Możesz zobaczyć, jak łączenie adaptacyjne raportuje wykonanie w trybie wsadowym dla łączenia w pętle zagnieżdżone (co jest niemożliwe), a pokazany czas, który upłynął, jest faktycznie kopiowany z ukrytego elementu Concat , a nie konkretne złączenie, które zostało wykonane w czasie wykonywania.
Zwykli podejrzani
możemy uzyskać przydatne informacje z rodzajów nieudokumentowanych flag śledzenia zwykle używanych do przeglądania danych wyjściowych optymalizatora. Na przykład:
SELECT SOH.SubTotalFROM Sales.SalesOrderHeader AS SOHJOIN Sales.SalesOrderDetail AS SOD ON SOD.SalesOrderID =SOH.SalesOrderIDWHERE SOH.SalesOrderID <=75123OPTION ( QUERYTRACEON 3604, QUERYTRACEON 8607, QUERYTRACEON 8612); Dane wyjściowe (mocno edytowane dla czytelności): *** Drzewo wyjściowe:***
PhyOp_ExecutionModeAdapter(BatchToRow) Card=121317 Koszt=1.05095
- PhyOp_Concat (partia) Karta=121317 Koszt=1,05325
- PhyOp_HashJoinx_jtInner (partia) Karta=121317 Koszt=1.05083
- PhyOp_Range Sales.SalesOrderHeader Card=31465 Koszt=0,54456
- PhyOp_Filter(batch) Card=121317 Koszt=0.397185
- PhyOp_Range Sales.SalesOrderDetail Card=121317 Koszt=0.338953
- PhyOp_ExecutionModeAdapter(RowToBatch) Card=121317 Koszt=10.0798
- PhyOp_Apply Card=121317 Koszt=10,0553
- PhyOp_ExecutionModeAdapter(BatchToRow) Card=31465 Koszt=0.544623
- PhyOp_Range Sales.SalesOrderHeader Card=31465 Koszt=0,54456 [** 3 **]
- PhyOp_Filter Card=3.85562 Koszt=9.00356
- PhyOp_Range Sales.SalesOrderDetail Card=3.85562 Koszt=8.94533
- PhyOp_ExecutionModeAdapter(BatchToRow) Card=31465 Koszt=0.544623
- PhyOp_Apply Card=121317 Koszt=10,0553
Daje to pewien wgląd w szacowane koszty przypadku pełnej kardynalności z hashem i stosowania alternatyw bez pisania oddzielnych zapytań i używania podpowiedzi. Jak wspomniano w głównym tekście, te flagi śledzenia nie działają w CuNewJoinEstimate , więc nie możemy bezpośrednio zobaczyć powtórnych obliczeń dla przypadku 31 465 wierszy ani żadnych szczegółów oszacowań jednowierszowych w ten sposób.
Łączenie łączenia i łączenie skrótu w trybie wiersza
Łączenia adaptacyjne umożliwiają tylko przejście z trybu wsadowego łączenia mieszającego do trybu wierszowego. Aby dowiedzieć się, dlaczego łączenie mieszające w trybie wiersza nie jest obsługiwane, zobacz sekcję Pytania i odpowiedzi dotyczące inteligentnego przetwarzania zapytań w sekcji Pokrewne odczyty. Krótko mówiąc, uważa się, że łączenia haszujące w trybie wiersza byłyby zbyt podatne na regresję wydajności.
Przejście na łączenie scalające w trybie wiersza byłoby inną opcją, ale optymalizator obecnie tego nie bierze pod uwagę. Jak rozumiem, jest mało prawdopodobne, że będzie rozwijany w tym kierunku w przyszłości.
Niektóre z rozważań są takie same, jak w przypadku łączenia mieszającego w trybie wiersza. Ponadto plany łączenia przez scalanie wydają się być trudniejsze do zastąpienia z łączeniem mieszającym, nawet jeśli ograniczymy się do indeksowanego łączenia przez scalanie (brak jawnego sortowania).
Istnieje również znacznie większe rozróżnienie między haszowaniem a zastosowaniem niż między haszowaniem a łączeniem. Zarówno skrót, jak i scalanie są odpowiednie dla większych danych wejściowych, a aplikacja Apply jest lepiej dostosowana do mniejszych danych wejściowych. Łączenie scalające nie jest tak łatwe do zrównoleglenia jak łączenie haszujące i nie skaluje się tak dobrze wraz ze wzrostem liczby wątków.
Biorąc pod uwagę, że motywacją do przyłączeń adaptacyjnych jest lepsze radzenie sobie z znacząco różne rozmiary danych wejściowych — a tylko łączenie mieszania obsługuje przetwarzanie w trybie wsadowym — wybór mieszania wsadowego w porównaniu z zastosowaniem wiersza jest bardziej naturalny. Wreszcie, posiadanie trzech opcji złączenia adaptacyjnego znacznie skomplikowałoby obliczenie progu dla potencjalnie niewielkiego zysku.