Jest to trzynasta i ostatnia część serii dotyczącej wyrażeń tabelowych. W tym miesiącu kontynuuję dyskusję, którą rozpocząłem w zeszłym miesiącu, na temat wbudowanych funkcji z wartościami tabelarycznymi (iTVF).
W zeszłym miesiącu wyjaśniłem, że kiedy SQL Server wstawia iTVF, które są odpytywane za pomocą stałych jako danych wejściowych, domyślnie stosuje optymalizację osadzania parametrów. Osadzanie parametrów oznacza, że SQL Server zastępuje odwołania do parametrów w zapytaniu literałowymi wartościami stałymi z bieżącego wykonania, a następnie kod ze stałymi zostaje zoptymalizowany. Proces ten umożliwia uproszczenia, które mogą skutkować bardziej optymalnymi planami zapytań. W tym miesiącu rozwijam temat, obejmując konkretne przypadki takich uproszczeń, jak ciągłe składanie oraz dynamiczne filtrowanie i porządkowanie. Jeśli potrzebujesz odświeżenia na temat optymalizacji osadzania parametrów, zapoznaj się z artykułem z zeszłego miesiąca, a także z doskonałym artykułem Paula White'a Wykrywanie parametrów, osadzanie i opcje RECOMPILE.
W moich przykładach użyję przykładowej bazy danych o nazwie TSQLV5. Skrypt, który tworzy i wypełnia go tutaj, oraz jego diagram ER można znaleźć tutaj.
Stałe składanie
Na wczesnych etapach przetwarzania zapytań SQL Server ocenia pewne wyrażenia zawierające stałe, składając je do stałych wynikowych. Na przykład wyrażenie 40 + 2 można złożyć do stałej 42. Zasady dla wyrażeń składanych i niemożliwych można znaleźć tutaj w sekcji „Stałe składanie i ocena wyrażeń”.
Interesujące w odniesieniu do iTVF jest to, że dzięki optymalizacji osadzania parametrów zapytania dotyczące iTVF, w których podaje się stałe jako dane wejściowe, mogą, w odpowiednich okolicznościach, skorzystać ze stałego składania. Znajomość reguł dla wyrażeń składanych i nieskładalnych może wpłynąć na sposób implementacji iTVF. W niektórych przypadkach, wprowadzając bardzo subtelne zmiany do wyrażeń, możesz włączyć bardziej optymalne plany z lepszym wykorzystaniem indeksowania.
Jako przykład rozważ następującą implementację iTVF o nazwie Sales.MyOrders:
USE TSQLV5;
GO
CREATE OR ALTER FUNCTION Sales.MyOrders
( @add AS INT, @subtract AS INT )
RETURNS TABLE
AS
RETURN
SELECT orderid + @add - @subtract AS myorderid,
orderdate, custid, empid
FROM Sales.Orders;
GO Wydaj następujące zapytanie dotyczące iTVF (nazywam to zapytaniem 1):
SELECT myorderid, orderdate, custid, empid FROM Sales.MyOrders(1, 10248) ORDER BY myorderid;
Plan dla zapytania 1 pokazano na rysunku 1.
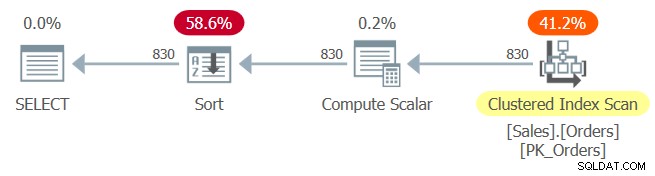 Rysunek 1:Plan dla zapytania 1
Rysunek 1:Plan dla zapytania 1
Indeks klastrowy PK_Orders jest zdefiniowany z identyfikatorem zamówienia jako kluczem. Gdyby tutaj po osadzeniu parametrów miało miejsce stałe składanie, wyrażenie porządkujące orderid + 1 – 10248 zostałoby złożone do orderid – 10247. To wyrażenie byłoby uważane za wyrażenie zachowujące porządek w odniesieniu do orderid i jako takie umożliwiłoby optymalizator, aby polegać na kolejności indeksów. Niestety, tak nie jest, co widać po wyraźnym operatorze Sort w planie. Więc co się stało?
Stałe zasady składania są wybredne. Wyrażenie kolumna1 + stała1 – stała2 jest oceniane od lewej do prawej w celu stałego składania. Pierwsza część, kolumna1 + stała1 nie jest złożona. Nazwijmy to wyrażenie1. Następna część, która jest oceniana, jest traktowana jako wyrażenie1 – stała2, która również nie jest zwijana. Bez fałdowania wyrażenie w postaci kolumna1 + stała1 – stała2 nie jest uważane za zachowywanie kolejności względem kolumny1 i dlatego nie może polegać na kolejności indeksów, nawet jeśli masz pomocniczy indeks na kolumnie1. Podobnie wyrażenie stała1 + kolumna1 – stała2 nie jest stałą składaną. Jednak wyrażenie stała1 – stała2 + kolumna1 jest zwijane. Dokładniej, pierwsza część stała1 – stała2 jest składana w jedną stałą (nazwijmy ją stałą3), co daje wyrażenie stała3 + kolumna1. To wyrażenie jest uważane za wyrażenie zachowujące kolejność w odniesieniu do kolumny 1. Tak więc, o ile upewnisz się, że piszesz swoje wyrażenie w ostatniej formie, możesz umożliwić optymalizatorowi poleganie na kolejności indeksów.
Rozważ następujące zapytania (nazywam je Zapytanie 2, Zapytanie 3 i Zapytanie 4), a zanim przyjrzysz się planom zapytań, sprawdź, czy potrafisz określić, które z nich będą wymagały jawnego sortowania w planie, a które nie:
-- Query 2 SELECT orderid + 1 - 10248 AS myorderid, orderdate, custid, empid FROM Sales.Orders ORDER BY myorderid; -- Query 3 SELECT 1 + orderid - 10248 AS myorderid, orderdate, custid, empid FROM Sales.Orders ORDER BY myorderid; -- Query 4 SELECT 1 - 10248 + orderid AS myorderid, orderdate, custid, empid FROM Sales.Orders ORDER BY myorderid;
Teraz sprawdź plany dla tych zapytań, jak pokazano na rysunku 2.
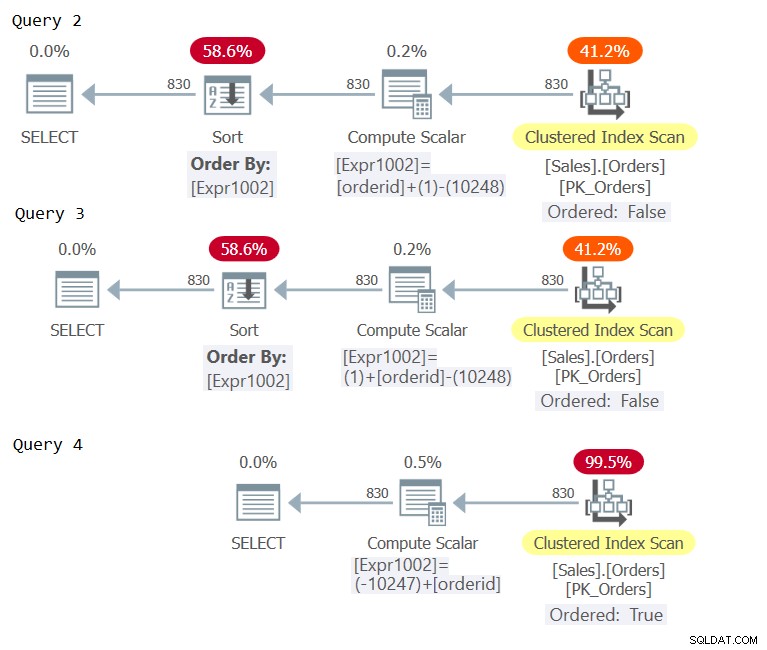 Rysunek 2:Plany dla zapytania 2, zapytania 3 i zapytania 4
Rysunek 2:Plany dla zapytania 2, zapytania 3 i zapytania 4
Sprawdź operatory obliczeniowe skalarne w trzech planach. Tylko plan dla Zapytania 4 wymagał stałego składania, co skutkuje wyrażeniem porządkującym, które jest uważane za zachowujące porządek w odniesieniu do orderid, co pozwala uniknąć jawnego sortowania.
Rozumiejąc ten aspekt ciągłego składania, możesz łatwo naprawić iTVF, zmieniając wyrażenie id.zamówienia + @add – @subtract na @add – @subtract + id.zamówienia, na przykład:
CREATE OR ALTER FUNCTION Sales.MyOrders
( @add AS INT, @subtract AS INT )
RETURNS TABLE
AS
RETURN
SELECT @add - @subtract + orderid AS myorderid,
orderdate, custid, empid
FROM Sales.Orders;
GO Zapytaj funkcję ponownie (nazwę to zapytaniem 5):
SELECT myorderid, orderdate, custid, empid FROM Sales.MyOrders(1, 10248) ORDER BY myorderid;
Plan dla tego zapytania pokazano na rysunku 3.
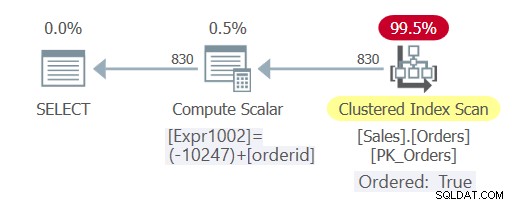 Rysunek 3:Plan dla zapytania 5
Rysunek 3:Plan dla zapytania 5
Jak widać, tym razem zapytanie podlegało ciągłemu składaniu, a optymalizator mógł polegać na kolejności indeksów, unikając jawnego sortowania.
Użyłem prostego przykładu, aby zademonstrować tę technikę optymalizacji i jako taki może wydawać się nieco wymyślny. Praktyczne zastosowanie tej techniki można znaleźć w artykule Rozwiązania wyzwań generatora serii liczb – część 1.
Dynamiczne filtrowanie/kolejność
W zeszłym miesiącu omówiłem różnicę między sposobem, w jaki SQL Server optymalizuje zapytanie w iTVF, a tym samym zapytaniem w procedurze składowanej. SQL Server zazwyczaj domyślnie stosuje optymalizację osadzania parametrów dla zapytania obejmującego iTVF ze stałymi jako danymi wejściowymi, ale optymalizuje sparametryzowaną formę zapytania w procedurze składowanej. Jeśli jednak dodasz opcję OPTION(RECOMPILE) do zapytania w procedurze składowanej, SQL Server zwykle również w tym przypadku zastosuje optymalizację osadzania parametrów. Korzyści w przypadku iTVF obejmują fakt, że możesz zaangażować go w zapytanie, a dopóki przekazujesz powtarzające się stałe dane wejściowe, istnieje możliwość ponownego wykorzystania wcześniej buforowanego planu. W przypadku procedury składowanej nie można włączyć jej do zapytania, a jeśli dodasz OPTION(RECOMPILE), aby uzyskać optymalizację osadzania parametrów, nie ma możliwości ponownego wykorzystania planu. Procedura składowana pozwala na znacznie większą elastyczność pod względem elementów kodu, których możesz użyć.
Zobaczmy, jak to wszystko wygląda w klasycznym zadaniu osadzania i porządkowania parametrów. Poniżej znajduje się uproszczona procedura składowana, która stosuje dynamiczne filtrowanie i sortowanie podobne do tego, którego użył Paul w swoim artykule:
CREATE OR ALTER PROCEDURE HR.GetEmpsP @lastnamepattern AS NVARCHAR(50), @sort AS TINYINT AS SET NOCOUNT ON; SELECT empid, firstname, lastname FROM HR.Employees WHERE lastname LIKE @lastnamepattern OR @lastnamepattern IS NULL ORDER BY CASE WHEN @sort = 1 THEN empid END, CASE WHEN @sort = 2 THEN firstname END, CASE WHEN @sort = 3 THEN lastname END; GO
Zwróć uwagę, że bieżąca implementacja procedury składowanej nie zawiera opcji OPTION(RECOMPILE) w zapytaniu.
Rozważ następujące wykonanie procedury składowanej:
EXEC HR.GetEmpsP @lastnamepattern = N'D%', @sort = 3;
Plan tego wykonania pokazano na rysunku 4.
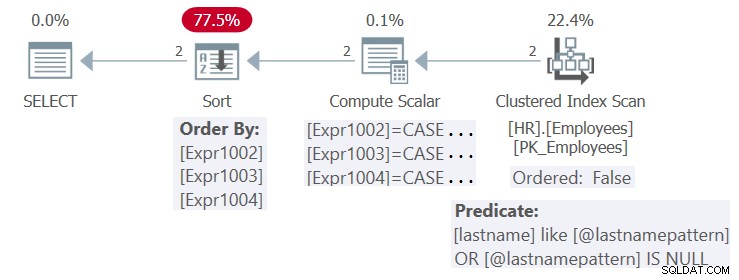 Rysunek 4:Plan procedury HR.GetEmpsP
Rysunek 4:Plan procedury HR.GetEmpsP
W kolumnie nazwiska znajduje się indeks. Teoretycznie, przy bieżących danych wejściowych, indeks mógłby być korzystny zarówno dla potrzeb filtrowania (z wyszukiwaniem), jak i porządkowania (z uporządkowanym:skanowaniem zakresu prawdziwego) zapytania. Ponieważ jednak SQL Server domyślnie optymalizuje sparametryzowaną formę zapytania i nie stosuje osadzania parametrów, nie stosuje uproszczeń wymaganych, aby móc korzystać z indeksu zarówno do celów filtrowania, jak i porządkowania. Tak więc plan jest wielokrotnego użytku, ale nie jest optymalny.
Aby zobaczyć, jak zmienia się sytuacja dzięki optymalizacji osadzania parametrów, zmień zapytanie procedury składowanej, dodając OPTION(RECOMPILE), na przykład:
CREATE OR ALTER PROCEDURE HR.GetEmpsP @lastnamepattern AS NVARCHAR(50), @sort AS TINYINT AS SET NOCOUNT ON; SELECT empid, firstname, lastname FROM HR.Employees WHERE lastname LIKE @lastnamepattern OR @lastnamepattern IS NULL ORDER BY CASE WHEN @sort = 1 THEN empid END, CASE WHEN @sort = 2 THEN firstname END, CASE WHEN @sort = 3 THEN lastname END OPTION(RECOMPILE); GO
Wykonaj procedurę składowaną ponownie z tymi samymi danymi wejściowymi, których użyłeś wcześniej:
EXEC HR.GetEmpsP @lastnamepattern = N'D%', @sort = 3;
Plan tego wykonania pokazano na rysunku 5.
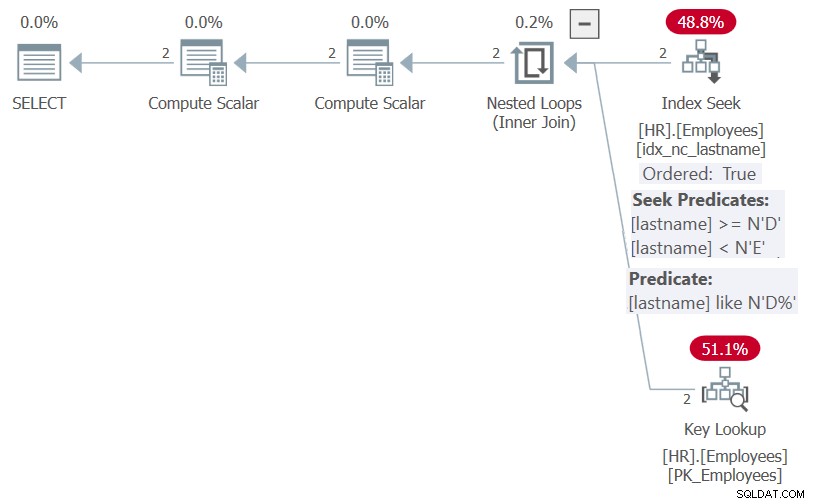 Rysunek 5:Plan procedury HR.GetEmpsP z opcją OPTION(RECOMPILE)
Rysunek 5:Plan procedury HR.GetEmpsP z opcją OPTION(RECOMPILE)
Jak widać, dzięki optymalizacji osadzania parametrów, SQL Server był w stanie uprościć predykat filtra do predykatu sargable lastname LIKE N'D%' i listy porządkowej do NULL, NULL, lastname. Oba elementy mogą skorzystać na indeksie na nazwisko, dlatego plan pokazuje wyszukiwanie w indeksie i nie ma wyraźnego sortowania.
Teoretycznie spodziewasz się uzyskania podobnego uproszczenia, jeśli zaimplementujesz zapytanie w iTVF, a co za tym idzie, podobnych korzyści optymalizacyjnych, ale z możliwością ponownego wykorzystania planów z pamięci podręcznej, gdy te same wartości wejściowe są ponownie używane. Spróbujmy więc…
Oto próba zaimplementowania tego samego zapytania w iTVF (nie uruchamiaj jeszcze tego kodu):
CREATE OR ALTER FUNCTION HR.GetEmpsF
(
@lastnamepattern AS NVARCHAR(50),
@sort AS TINYINT
)
RETURNS TABLE
AS
RETURN
SELECT empid, firstname, lastname
FROM HR.Employees
WHERE lastname LIKE @lastnamepattern OR @lastnamepattern IS NULL
ORDER BY
CASE WHEN @sort = 1 THEN empid END,
CASE WHEN @sort = 2 THEN firstname END,
CASE WHEN @sort = 3 THEN lastname END;
GO Czy widzisz problem z tą implementacją, zanim spróbujesz wykonać ten kod? Pamiętaj, że na początku tej serii wyjaśniłem, że wyrażenie tabeli to tabela. Treść tabeli jest zbiorem (lub zbiorem) wierszy i jako taka nie ma kolejności. Dlatego zwykle zapytanie używane jako wyrażenie tabelowe nie może zawierać klauzuli ORDER BY. Rzeczywiście, jeśli spróbujesz uruchomić ten kod, otrzymasz następujący błąd:
Msg 1033, Level 15, State 1, Procedure GetEmps, Line 16 [Batch Start Line 128]Klauzula ORDER BY jest nieprawidłowa w widokach, funkcjach wbudowanych, tabelach pochodnych, podzapytaniach i typowych wyrażeniach tabel, chyba że TOP, OFFSET lub FOR XML jest również określony.
Oczywiście, jak mówi błąd, SQL Server zrobi wyjątek, jeśli użyjesz elementu filtrującego, takiego jak TOP lub OFFSET-FETCH, który opiera się na klauzuli ORDER BY w celu zdefiniowania aspektu porządkowania filtra. Ale nawet jeśli włączysz klauzulę ORDER BY w zapytaniu wewnętrznym dzięki temu wyjątkowi, nadal nie otrzymasz gwarancji kolejności wyników w zapytaniu zewnętrznym względem wyrażenia tabeli, chyba że ma ono własną klauzulę ORDER BY .
Jeśli nadal chcesz zaimplementować zapytanie w iTVF, możesz poprosić wewnętrzne zapytanie o obsługę dynamicznej części filtrowania, ale nie dynamicznego porządkowania, na przykład:
CREATE OR ALTER FUNCTION HR.GetEmpsF ( @lastnamepattern AS NVARCHAR(50) ) RETURNS TABLE AS RETURN SELECT empid, firstname, lastname FROM HR.Employees WHERE lastname LIKE @lastnamepattern OR @lastnamepattern IS NULL; GO
Oczywiście możesz sprawić, by zewnętrzne zapytanie obsłużyło każdą konkretną potrzebę porządkowania, jak w poniższym kodzie (nazwę to zapytaniem 6):
SELECT empid, firstname, lastname FROM HR.GetEmpsF(N'D%') ORDER BY lastname;
Plan dla tego zapytania pokazano na rysunku 6.
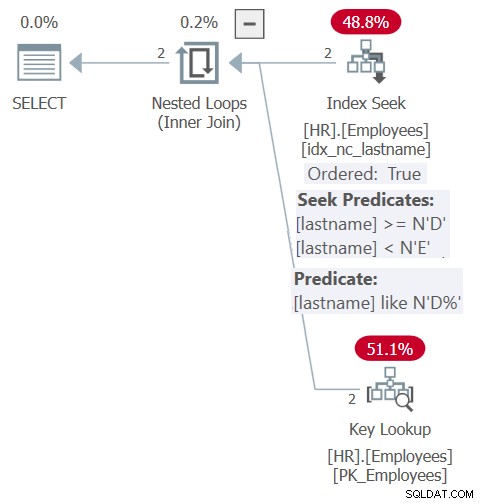 Rysunek 6:Plan dla zapytania 6
Rysunek 6:Plan dla zapytania 6
Dzięki inliningowi i osadzeniu parametrów plan jest podobny do pokazanego wcześniej dla zapytania procedury składowanej na rysunku 5. Plan efektywnie opiera się na indeksie zarówno do celów filtrowania, jak i porządkowania. Jednak nie uzyskujesz elastyczności danych wejściowych porządkowania dynamicznego, jak w przypadku procedury składowanej. Musisz wyraźnie określić kolejność w klauzuli ORDER BY w zapytaniu względem funkcji.
Poniższy przykład zawiera zapytanie dotyczące funkcji bez filtrowania i bez wymagań dotyczących kolejności (nazywam to zapytaniem 7):
SELECT empid, firstname, lastname FROM HR.GetEmpsF(NULL);
Plan dla tego zapytania pokazano na rysunku 7.
 Rysunek 7:Plan dla zapytania 7
Rysunek 7:Plan dla zapytania 7
Po wstawieniu i osadzeniu parametrów zapytanie jest uproszczone, tak aby nie zawierało predykatu filtra ani porządkowania, a także jest optymalizowane za pomocą pełnego nieuporządkowanego skanowania indeksu klastrowego.
Na koniec zapytaj funkcję z N'D%' jako wejściowym wzorcem filtrowania według nazwiska i uporządkuj wynik według kolumny imienia (nazwę to Zapytanie 8):
SELECT empid, firstname, lastname FROM HR.GetEmpsF(N'D%') ORDER BY firstname;
Plan dla tego zapytania pokazano na rysunku 8.
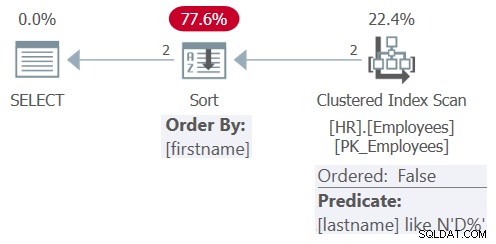 Rysunek 8:Plan dla zapytania 8
Rysunek 8:Plan dla zapytania 8
Po uproszczeniu zapytanie obejmuje tylko nazwisko predykatu filtrującego LIKE N'D%' oraz imię elementu porządkującego. Tym razem optymalizator zdecydował się na zastosowanie nieuporządkowanego skanowania indeksu klastrowego, z resztkowym nazwiskiem predykatu LIKE N'D%', po którym następuje jawne sortowanie. Postanowił nie stosować wyszukiwania w indeksie na nazwisko, ponieważ indeks nie jest indeksem zakrywającym, tabela jest tak mała, a kolejność indeksów nie jest korzystna dla bieżących potrzeb porządkowania zapytań. Ponadto nie ma indeksu zdefiniowanego w kolumnie imienia, więc i tak należy zastosować sortowanie jawne.
Wniosek
Domyślna optymalizacja osadzania parametrów iTVF może również skutkować ciągłym składaniem, umożliwiając bardziej optymalne plany. Musisz jednak pamiętać o stałych regułach składania, aby określić, jak najlepiej formułować swoje wyrażenia.
Implementacja logiki w iTVF ma zalety i wady w porównaniu z implementacją logiki w procedurze składowanej. Jeśli nie interesuje Cię optymalizacja osadzania parametrów, domyślna optymalizacja sparametryzowanych zapytań procedur składowanych może skutkować bardziej optymalnym buforowaniem planu i zachowaniem ponownego użycia. W przypadkach, w których interesuje Cię optymalizacja osadzania parametrów, zazwyczaj otrzymujesz ją domyślnie za pomocą iTVF. Aby uzyskać tę optymalizację za pomocą procedur składowanych, musisz dodać opcję zapytania RECOMPILE, ale wtedy nie będziesz mieć możliwości ponownego wykorzystania planu. Przynajmniej w przypadku iTVF można ponownie wykorzystać plan, pod warunkiem, że powtarzają się te same wartości parametrów. Z drugiej strony masz mniejszą elastyczność w zakresie elementów zapytania, których możesz użyć w iTVF; na przykład nie możesz mieć klauzuli ORDER BY prezentacji.
Wracając do całej serii o wyrażeniach tabelowych, uważam, że temat jest bardzo ważny dla praktyków baz danych. Bardziej kompletna seria obejmuje podserię generatora serii liczb, który jest zaimplementowany jako iTVF. W sumie seria składa się z następujących 19 części:
- Podstawy wyrażeń tabelowych, część 1
- Podstawy wyrażeń tablicowych, Część 2 – Tablice pochodne, rozważania logiczne
- Podstawy wyrażeń tabelarycznych, Część 3 – Tablice pochodne, rozważania dotyczące optymalizacji
- Podstawy wyrażeń tabelarycznych, Część 4 – Tabele pochodne, rozważania dotyczące optymalizacji, ciąg dalszy
- Podstawy wyrażeń tablicowych, Część 5 – CTE, rozważania logiczne
- Podstawy wyrażeń tabelowych, Część 6 – Rekurencyjne CTE
- Podstawy wyrażeń tabelarycznych, Część 7 – CTE, rozważania dotyczące optymalizacji
- Podstawy wyrażeń tabelarycznych, Część 8 – CTE, kontynuacja rozważań dotyczących optymalizacji
- Podstawy wyrażeń tabelowych, Część 9 – Widoki, w porównaniu z tabelami pochodnymi i CTE
- Podstawy wyrażeń tabelowych, Część 10 – Widoki, SELECT * i zmiany DDL
- Podstawy wyrażeń tabelarycznych, część 11 – Widoki, uwagi dotyczące modyfikacji
- Podstawy wyrażeń tabelarycznych, część 12 — wbudowane funkcje o wartościach tabelarycznych
- Podstawy wyrażeń tabelarycznych, część 13 – Wbudowane funkcje o wartościach tabelarycznych, ciąg dalszy
- Wyzwanie rozpoczęte! Wezwanie społeczności do stworzenia najszybszego generatora serii liczb
- Rozwiązania wyzwań generatora szeregów liczb – część 1
- Rozwiązania wyzwań generatora szeregów liczb – część 2
- Rozwiązania wyzwań generatora szeregów liczb – część 3
- Rozwiązania wyzwań generatora szeregów liczb – część 4
- Rozwiązania wyzwań generatora serii liczb – część 5