Wprowadzenie do zbiorczego zbierania PL/SQL
Dobrze skonstruowane zapytanie, napisane dzisiaj, może uchronić Cię przed katastrofalnymi wydarzeniami w przyszłości. Wydajność zapytań to coś, czego wszyscy szukamy, ale bardzo niewielu naprawdę ją znajduje. Nauka małych pojęć może pomóc w zdobyciu doświadczenia, które może prowadzić do lepszych umiejętności pisania zapytań. Dzisiaj na tym blogu poznasz jedną z tych małych koncepcji, jaką jest „Zbieranie zbiorcze ”.
Zbieranie zbiorcze polega na ograniczeniu przełączeń kontekstowych i poprawę wydajności zapytania. Dlatego, aby zrozumieć, czym jest zbieranie zbiorcze, musimy najpierw dowiedzieć się, czym jest Przełączanie kontekstu ?
Co to jest przełączanie kontekstu?
Za każdym razem, gdy piszesz blok PL/SQL lub wypowiadasz program PL/SQL i go wykonujesz, silnik wykonawczy PL/SQL zaczyna przetwarzać go wiersz po wierszu. Silnik ten sam przetwarza wszystkie instrukcje PL/SQL, ale przekazuje wszystkie instrukcje SQL, które zostały zakodowane w tym bloku PL/SQL, do silnika wykonawczego SQL. Te instrukcje SQL będą następnie przetwarzane oddzielnie przez aparat SQL. Po zakończeniu przetwarzania silnik SQL zwraca wynik z powrotem do silnika PL/SQL. Aby ten ostatni mógł uzyskać łączny wynik. To przeskakiwanie w tę i z powrotem nazywa się przełączaniem kontekstu.
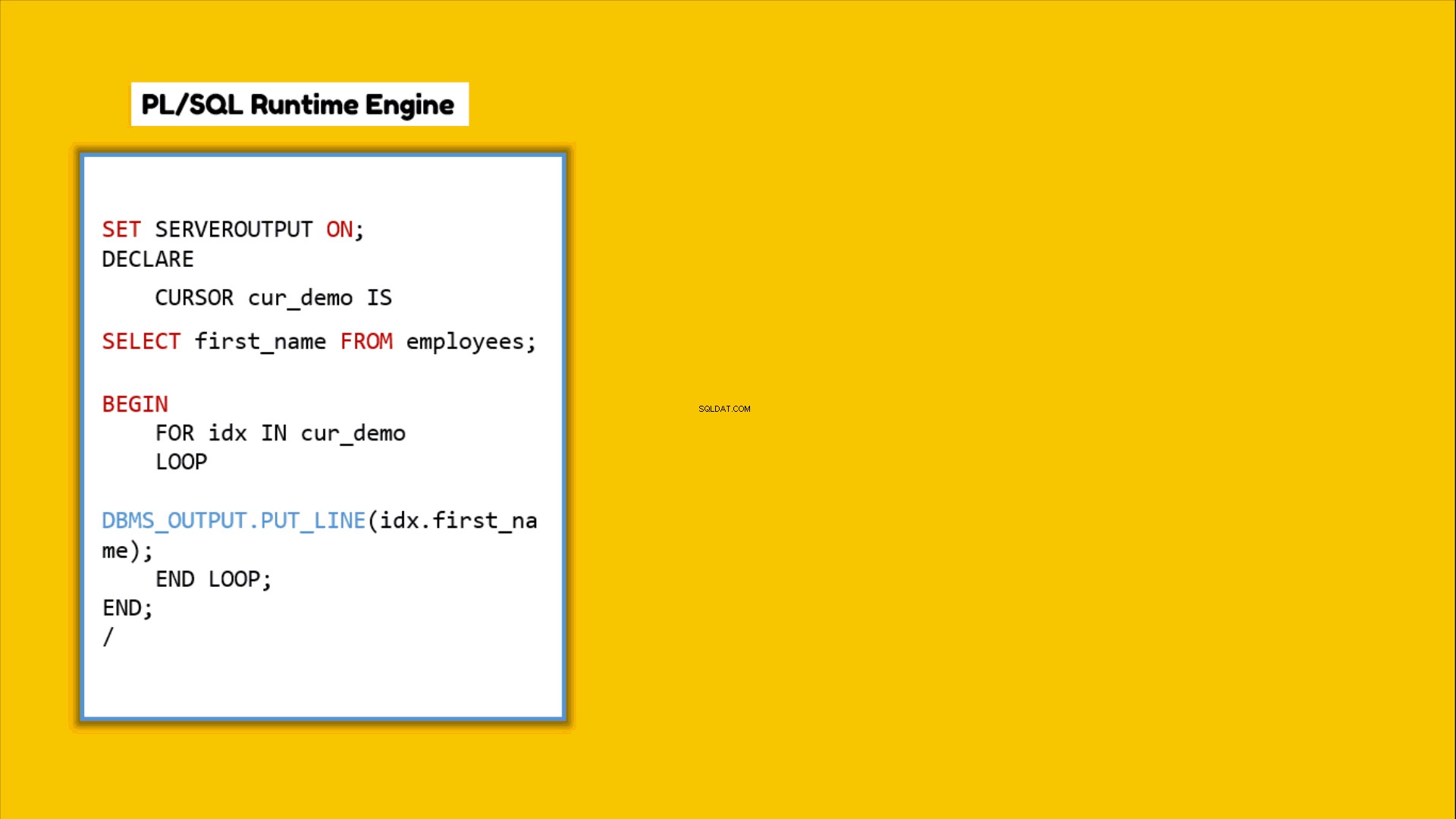
Jak przełączanie kontekstu wpływa na wydajność zapytania?
Przełączanie kontekstu ma bezpośredni wpływ na wydajność zapytania. Im wyższe przeskakiwanie elementów sterujących, tym większe będą koszty ogólne, co z kolei obniży wydajność. Oznacza to, że im mniejsze przełączanie kontekstów, tym lepsze będzie wydajność zapytania.
Teraz musisz pomyśleć:„Czy nie możemy czegoś z tym zrobić?” Czy możemy ograniczyć te przejścia kontrolne? Czy mimo to za pomocą którego możemy zredukować przełączniki kontekstu? Odpowiedź na wszystkie te pytania brzmi tak, mamy opcję, która może nam pomóc. Ta opcja to klauzula zbiorczego zbierania .
Co to jest klauzula zbiorczego zbierania?
Klauzula zbiorczego zbierania kompresuje wiele przełączników w jeden przełącznik kontekstowy i zwiększa wydajność i wydajność programu PL/SQL.
Klauzula zbiorczego zbierania ogranicza wielokrotne przeskakiwanie kontroli poprzez zbieranie wszystkich wywołań instrukcji SQL z programu PL/SQL i wysyłanie ich do silnika SQL za jednym razem i na odwrót.
Gdzie możemy użyć klauzuli Bulk Collect?
Klauzula zbiorczego zbierania może być używana z klauzulami SELECT-INTO, FETCH-INTO i RETURN-INTO.
Za pomocą instrukcji Bulk Collect możemy WYBRAĆ, WSTAWIĆ, UAKTUALNIĆ lub USUNĄĆ duże zbiory danych z obiektów bazy danych, takich jak tabele lub widoki.
Co to jest zbiorcze przetwarzanie danych?
Proces pobierania partii danych z silnika wykonawczego PL/SQL do silnika SQL i odwrotnie nazywa się zbiorczym przetwarzaniem danych.
Ile mamy wyciągów dotyczących zbiorczego przetwarzania danych?
Mamy jedną klauzulę do zbiorczego przetwarzania danych czyli Bulk Collect i jedno oświadczenie o zbiorczym przetwarzaniu danych który jest FORALL w Oracle Database.
Słyszałem, że klauzula zbiorczego zbierania używa zarówno niejawnych, jak i jawnych kursorów?
Tak, dobrze słyszałeś. Klauzuli zbiorczego zbierania danych możemy użyć wewnątrz instrukcji SQL lub z instrukcją FETCH. Kiedy używamy klauzuli zbiorczego zbierania z instrukcją SQL, tj. SELECT INTO, używa ona niejawnego kursora. Podczas gdy używamy klauzuli zbiorczego zbierania z instrukcją FETCH, używa ona jawnego kursora.
Było to szybkie wprowadzenie do pierwszej klauzuli PL/SQL do masowego przetwarzania danych, którą jest BULK COLLECT. O drugim oświadczeniu o zbiorczym przetwarzaniu danych dowiemy się, gdy skończymy z pierwszym. W międzyczasie koniecznie zasubskrybuj nasz kanał na YouTube, ponieważ w następnym samouczku dowiemy się, jak możemy poprawić wydajność instrukcji SQL przy użyciu klauzuli Bulk Collect.
Dzięki i życzę miłego dnia!