Jednym z podstawowych wymagań każdej bazy danych jest osiągnięcie skalowalności. Można to osiągnąć tylko wtedy, gdy rywalizacja (blokada) jest zminimalizowana do minimum, jeśli nie zostanie całkowicie usunięta. Ponieważ odczyt / zapis / aktualizacja / usuwanie to jedne z głównych częstych operacji wykonywanych w bazie danych, dlatego bardzo ważne jest, aby te operacje odbywały się jednocześnie bez blokowania. Aby to osiągnąć, większość głównych baz danych wykorzystuje model współbieżności o nazwie Kontrola współbieżności wielu wersji co zmniejsza rywalizację do absolutnego minimum.
Co to jest MVCC
Multi Version Concurrency Control (odtąd MVCC) to algorytm zapewniający precyzyjną kontrolę współbieżności poprzez utrzymywanie wielu wersji tego samego obiektu, tak aby operacje ODCZYTU i ZAPISU nie powodowały konfliktu. Tutaj ZAPISZ oznacza AKTUALIZUJ i USUŃ, ponieważ nowo wstawiony rekord i tak będzie chroniony zgodnie z poziomem izolacji. Każda operacja WRITE tworzy nową wersję obiektu, a każda równoczesna operacja odczytu odczytuje inną wersję obiektu w zależności od poziomu izolacji. Ponieważ zarówno odczyt, jak i zapis działają na różnych wersjach tego samego obiektu, żadna z tych operacji nie wymagała całkowitego zablokowania, a zatem obie mogą działać jednocześnie. Jedynym przypadkiem, w którym spór może nadal istnieć, jest sytuacja, w której dwie równoczesne transakcje próbują ZAPISAĆ ten sam rekord.
Większość obecnych głównych baz danych obsługuje MVCC. Intencją tego algorytmu jest utrzymywanie wielu wersji tego samego obiektu, więc implementacja MVCC różni się w zależności od bazy danych tylko pod względem sposobu tworzenia i utrzymywania wielu wersji. W związku z tym odpowiednie działanie bazy danych i przechowywanie zmian danych.
Najbardziej znanym podejściem do implementacji MVCC jest to, które stosują PostgreSQL i Firebird/Interbase, a drugie jest stosowane przez InnoDB i Oracle. W kolejnych sekcjach omówimy szczegółowo, w jaki sposób został zaimplementowany w PostgreSQL i InnoDB.
MVCC w PostgreSQL
Aby obsługiwać wiele wersji, PostgreSQL utrzymuje dodatkowe pola dla każdego obiektu (Tuple w terminologii PostgreSQL), jak wspomniano poniżej:
- xmin – Identyfikator transakcji, która wstawiła lub zaktualizowała krotkę. W przypadku UPDATE nowsza wersja krotki zostanie przypisana z tym identyfikatorem transakcji.
- xmax – Identyfikator transakcji, która usunęła lub zaktualizowała krotkę. W przypadku UPDATE aktualnie istniejącej wersji krotki zostanie przypisany ten identyfikator transakcji. W nowo utworzonej krotce domyślna wartość tego pola to null.
PostgreSQL przechowuje wszystkie dane w podstawowej pamięci o nazwie HEAP (strona o domyślnym rozmiarze 8KB). Cała nowa krotka otrzymuje xmin jako transakcję, która ją utworzyła, a starsza krotka wersji (która została zaktualizowana lub usunięta) zostaje przypisana z xmax. Zawsze istnieje link ze starszej wersji krotki do nowej wersji. Starsza wersja krotki może być użyta do odtworzenia krotki w przypadku wycofania i do odczytania starszej wersji krotki przez instrukcję READ, w zależności od poziomu izolacji.
Załóżmy, że istnieją dwie krotki, T1 (o wartości 1) i T2 (o wartości 2) dla tabeli, tworzenie nowych wierszy można zademonstrować w poniższych 3 krokach:
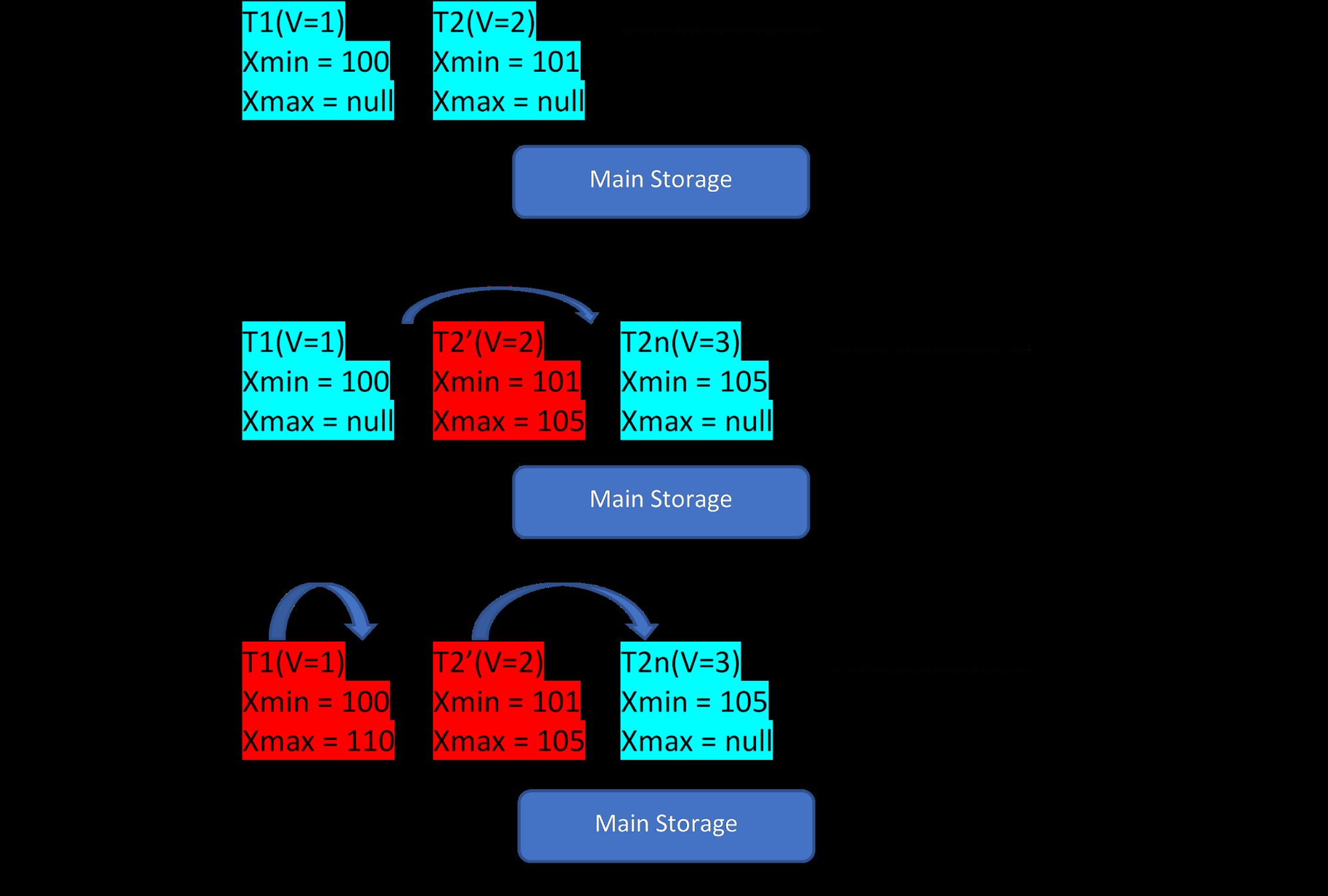 MVCC:przechowywanie wielu wersji w PostgreSQL
MVCC:przechowywanie wielu wersji w PostgreSQL Jak widać na rysunku, początkowo w bazie danych znajdują się dwie krotki o wartościach 1 i 2.
Następnie, zgodnie z drugim krokiem, wiersz T2 o wartości 2 zostanie zaktualizowany o wartość 3. W tym momencie tworzona jest nowa wersja z nową wartością i po prostu jest zapisywana jako obok istniejącej krotki w tym samym obszarze przechowywania . Wcześniej starsza wersja jest przypisywana za pomocą xmax i wskazuje na najnowszą krotkę wersji.
Podobnie w trzecim kroku, gdy wiersz T1 o wartości 1 zostanie usunięty, to istniejący wiersz zostanie wirtualnie usunięty (tzn. właśnie przypisał xmax z bieżącą transakcją) w tym samym miejscu. W tym celu nie zostanie utworzona żadna nowa wersja.
Następnie zobaczmy, jak każda operacja tworzy wiele wersji i jak utrzymywany jest poziom izolacji transakcji bez blokowania, z kilkoma prawdziwymi przykładami. We wszystkich poniższych przykładach domyślnie używana jest izolacja „CZYTAJ ZATWIERDZONE”.
WSTAW
Za każdym razem, gdy rekord zostanie wstawiony, utworzy nową krotkę, która zostanie dodana do jednej ze stron należących do odpowiedniej tabeli.
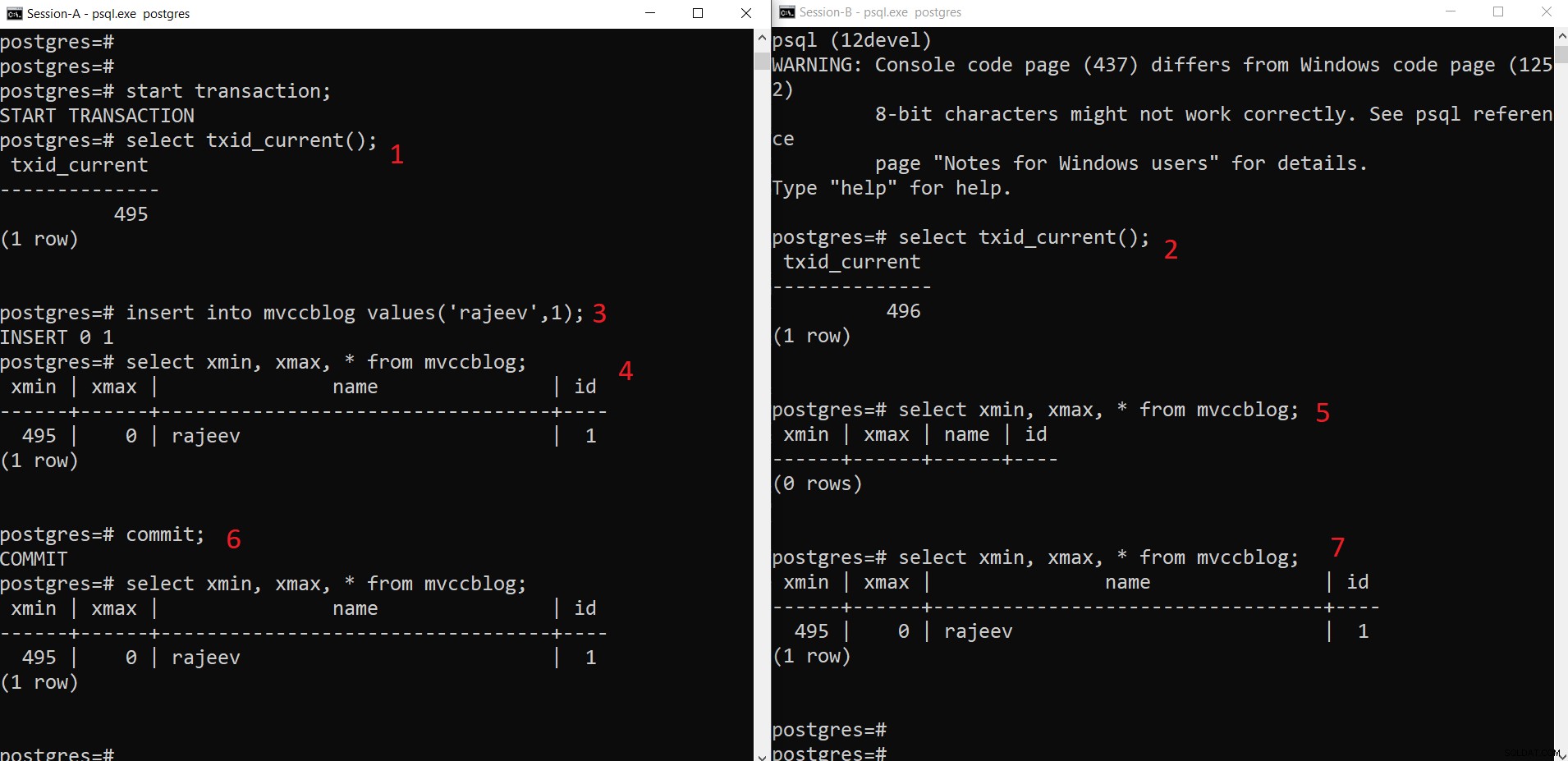 Jednoczesna operacja INSERT PostgreSQL
Jednoczesna operacja INSERT PostgreSQL Jak widzimy tutaj krok po kroku:
- Sesja-A rozpoczyna transakcję i otrzymuje identyfikator transakcji 495.
- Sesja B rozpoczyna transakcję i otrzymuje identyfikator transakcji 496.
- Sesja-A wstawia nową krotkę (jest zapisywana w HEAP)
- Teraz nowa krotka z xmin ustawionym na bieżący identyfikator transakcji 495 zostaje dodana.
- Ale to samo nie jest widoczne z sesji B, ponieważ xmin (tj. 495) nadal nie jest zatwierdzony.
- Po zatwierdzeniu.
- Dane są widoczne w obu sesjach.
AKTUALIZACJA
PostgreSQL UPDATE nie jest aktualizacją „IN-PLACE”, tzn. nie modyfikuje istniejącego obiektu o wymaganą nową wartość. Zamiast tego tworzy nową wersję obiektu. A zatem UPDATE zasadniczo obejmuje poniższe kroki:
- Oznacza bieżący obiekt jako usunięty.
- Następnie dodaje nową wersję obiektu.
- Przekieruj starszą wersję obiektu do nowej wersji.
Więc nawet jeśli liczba rekordów pozostaje taka sama, HEAP zajmuje miejsce, tak jakby wstawiono jeszcze jeden rekord.
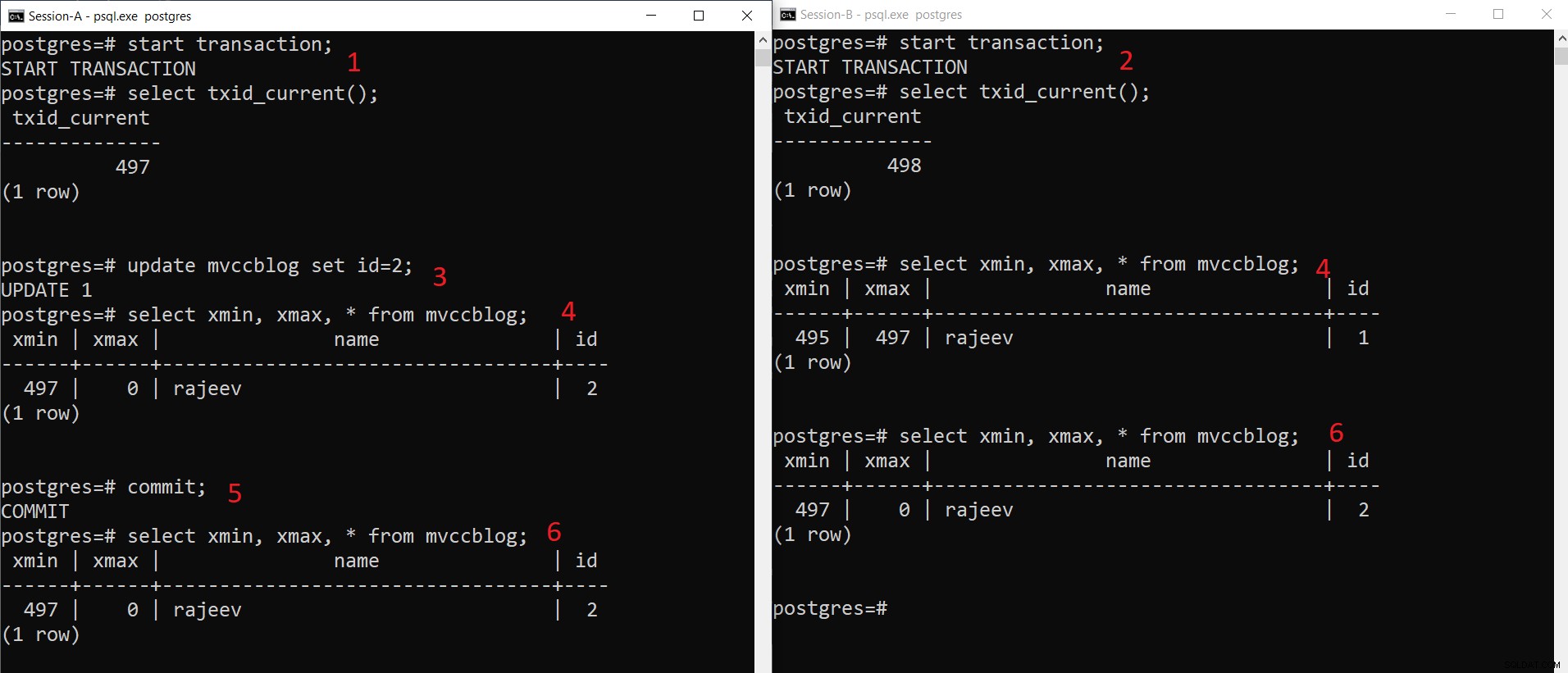 Jednoczesna operacja INSERT PostgreSQL
Jednoczesna operacja INSERT PostgreSQL Jak widzimy tutaj krok po kroku:
- Sesja-A rozpoczyna transakcję i otrzymuje identyfikator transakcji 497.
- Sesja B rozpoczyna transakcję i otrzymuje identyfikator transakcji 498.
- Sesja-A aktualizuje istniejący rekord.
- Tutaj Sesja-A widzi jedną wersję krotki (zaktualizowaną krotkę), podczas gdy Sesja-B widzi inną wersję (starsza krotka, ale xmax ustawiony na 497). Obie wersje krotek są przechowywane w pamięci HEAP (nawet ta sama strona w zależności od dostępności miejsca)
- Gdy sesja-A zatwierdzi transakcję, starsza krotka wygaśnie, ponieważ xmax starszej krotki zostanie zatwierdzony.
- Teraz obie sesje widzą tę samą wersję rekordu.
USUŃ
Usuwanie jest prawie jak operacja UPDATE, z tym wyjątkiem, że nie wymaga dodawania nowej wersji. Po prostu oznacza bieżący obiekt jako USUNIĘTY, jak wyjaśniono w przypadku UPDATE.
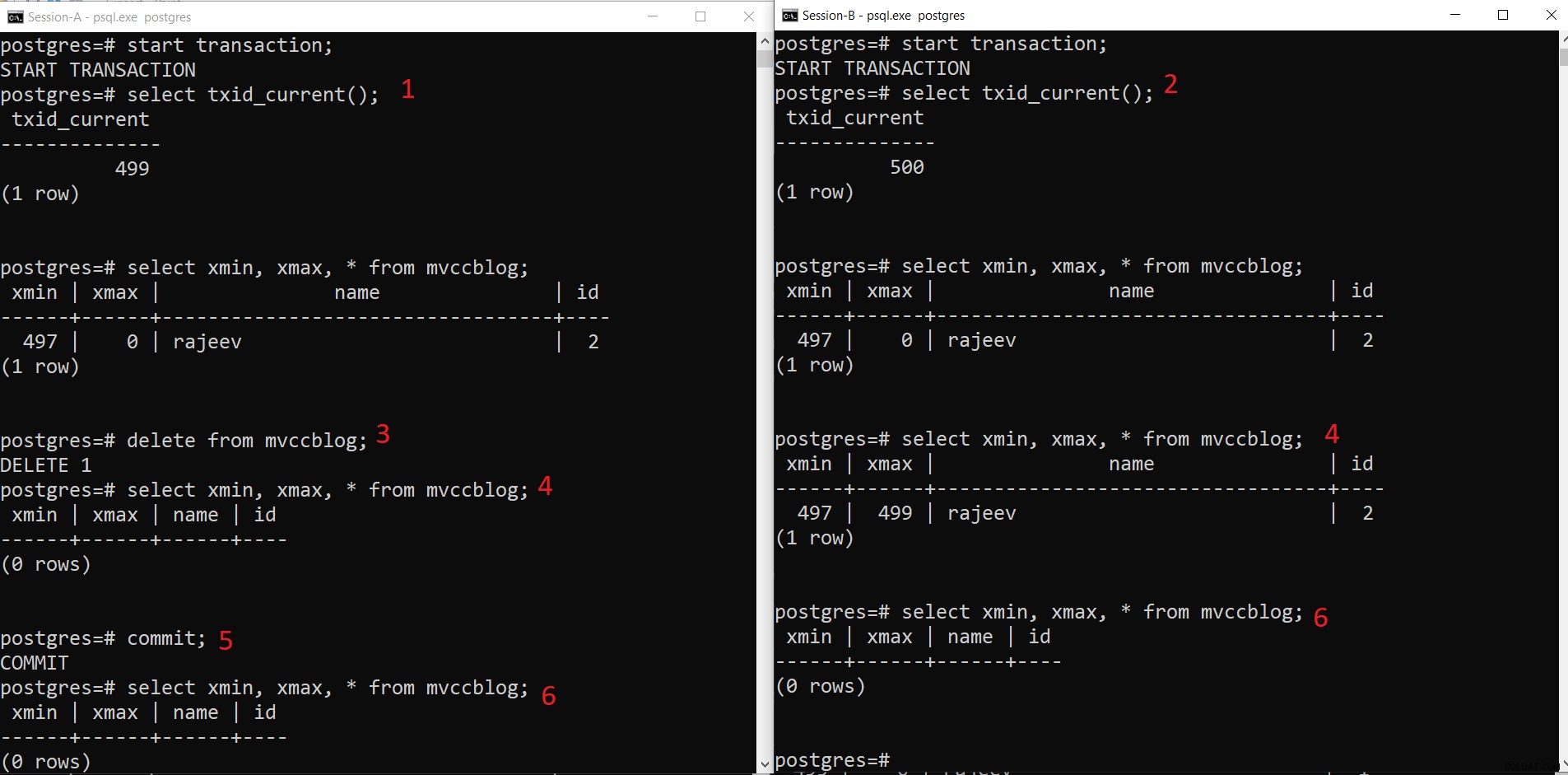 Jednoczesna operacja DELETE PostgreSQL
Jednoczesna operacja DELETE PostgreSQL - Sesja-A rozpoczyna transakcję i otrzymuje identyfikator transakcji 499.
- Sesja B rozpoczyna transakcję i otrzymuje identyfikator transakcji 500.
- Sesja A usuwa istniejący rekord.
- Tutaj Sesja-A nie widzi żadnej krotki jako usuniętej z bieżącej transakcji. Podczas gdy sesja B widzi starszą wersję krotki (z xmax jako 499; transakcja, która usunęła ten rekord).
- Gdy sesja-A zatwierdzi transakcję, starsza krotka wygaśnie, ponieważ xmax starszej krotki zostanie zatwierdzony.
- Teraz obie sesje nie widzą usuniętej krotki.
Jak widzimy, żadna z operacji nie usuwa bezpośrednio istniejącej wersji obiektu, aw razie potrzeby dodaje dodatkową wersję obiektu.
Zobaczmy teraz, jak zapytanie SELECT jest wykonywane na krotce mającej wiele wersji:SELECT musi odczytać wszystkie wersje krotki, aż znajdzie odpowiednią krotkę zgodnie z poziomem izolacji. Załóżmy, że istnieje krotka T1, która została zaktualizowana i utworzyła nową wersję T1’, a która z kolei utworzyła T1’’ podczas aktualizacji:
- Operacja SELECT przejdzie przez magazyn sterty dla tej tabeli i najpierw sprawdzi T1. Jeśli transakcja T1 xmax została zatwierdzona, przechodzi do następnej wersji tej krotki.
- Załóżmy, że teraz krotka T1’ xmax jest również zadeklarowana, a następnie ponownie przechodzi do następnej wersji tej krotki.
- Na koniec odnajduje T1'' i widzi, że xmax nie jest zatwierdzony (lub ma wartość NULL), a T1'' xmin jest widoczny dla bieżącej transakcji zgodnie z poziomem izolacji. W końcu odczyta krotkę T1”.
Jak widzimy, musi przejść przez wszystkie 3 wersje krotki, aby znaleźć odpowiednią widoczną krotkę, dopóki wygasła krotka nie zostanie usunięta przez garbage collector (VACUUM).
MVCC w InnoDB
Aby obsługiwać wiele wersji, InnoDB utrzymuje dodatkowe pola dla każdego wiersza, jak wspomniano poniżej:
- DB_TRX_ID:Identyfikator transakcji, która wstawiła lub zaktualizowała wiersz.
- DB_ROLL_PTR:Jest również nazywany wskaźnikiem wycofywania i wskazuje cofnięcie rekordu dziennika zapisanego w segmencie wycofywania (więcej o tym dalej).
Podobnie jak PostgreSQL, InnoDB tworzy również wiele wersji wiersza w ramach wszystkich operacji, ale przechowywanie starszej wersji jest inne.
W przypadku InnoDB stara wersja zmienionego wiersza jest przechowywana w oddzielnym obszarze tabel/pamięci (tzw. segment cofania). Więc w przeciwieństwie do PostgreSQL, InnoDB przechowuje tylko najnowszą wersję wierszy w głównym obszarze pamięci, a starsza wersja jest przechowywana w segmencie cofania. Wersje wierszy z segmentu cofania służą do cofania operacji w przypadku wycofania i do odczytu starszej wersji wierszy przez instrukcję READ w zależności od poziomu izolacji.
Załóżmy, że istnieją dwa wiersze, T1 (o wartości 1) i T2 (o wartości 2) dla tabeli, tworzenie nowych wierszy można zademonstrować w 3 poniższych krokach:
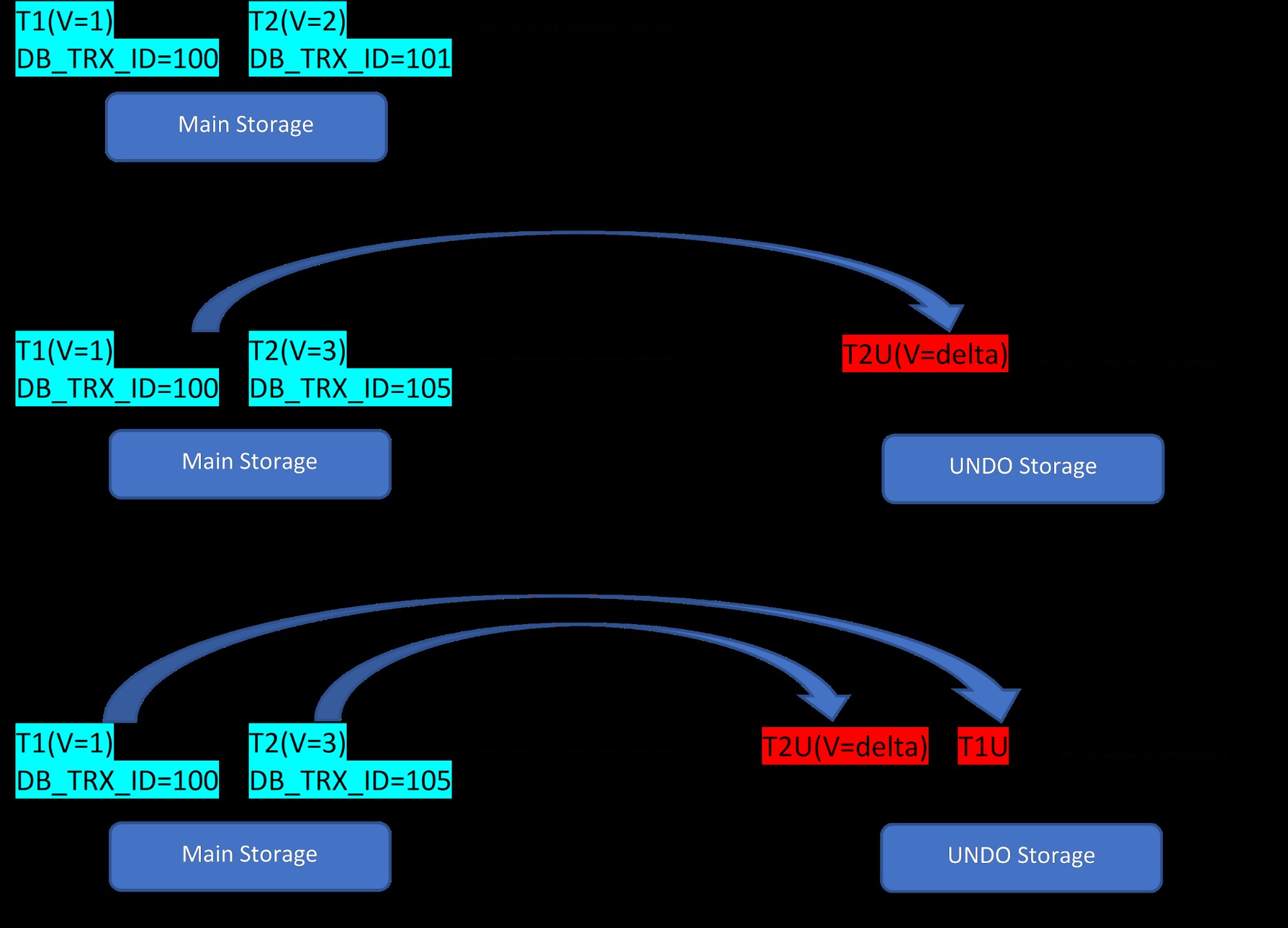 MVCC:przechowywanie wielu wersji w InnoDB
MVCC:przechowywanie wielu wersji w InnoDB Jak widać na rysunku, początkowo w bazie danych są dwa wiersze z wartościami 1 i 2.
Następnie, zgodnie z drugim etapem, wiersz T2 o wartości 2 zostanie zaktualizowany o wartość 3. W tym momencie tworzona jest nowa wersja z nową wartością i zastępuje starszą wersję. Wcześniej starsza wersja jest przechowywana w segmencie cofania (zauważ, że wersja segmentu UNDO ma tylko wartość delta). Należy również zauważyć, że w segmencie wycofywania istnieje jeden wskaźnik od nowej wersji do starszej wersji. Więc w przeciwieństwie do PostgreSQL, aktualizacja InnoDB jest „NA MIEJSCU”.
Podobnie w trzecim kroku, gdy wiersz T1 z wartością 1 zostanie usunięty, to istniejący wiersz zostanie wirtualnie usunięty (tzn. po prostu zaznacza specjalny bit w wierszu) w obszarze pamięci głównej, a odpowiadająca temu nowa wersja zostanie dodana w segment Cofnij. Znowu jest jeden wskaźnik rolki z pamięci głównej do segmentu cofania.
Wszystkie operacje z zewnątrz zachowują się tak samo jak w przypadku PostgreSQL. Tylko pamięć wewnętrzna wielu wersji różni się.
Pobierz oficjalny dokument już dziś Zarządzanie i automatyzacja PostgreSQL za pomocą ClusterControlDowiedz się, co musisz wiedzieć, aby wdrażać, monitorować, zarządzać i skalować PostgreSQLPobierz oficjalny dokumentMVCC:PostgreSQL kontra InnoDB
Przeanalizujmy teraz, jakie są główne różnice między PostgreSQL i InnoDB pod względem implementacji MVCC:
-
Rozmiar starszej wersji
PostgreSQL po prostu aktualizuje xmax w starszej wersji krotki, więc rozmiar starszej wersji pozostaje taki sam jak w odpowiednim wstawionym rekordzie. Oznacza to, że jeśli masz 3 wersje starszej krotki, wszystkie będą miały ten sam rozmiar (z wyjątkiem różnicy w rzeczywistym rozmiarze danych, jeśli występuje przy każdej aktualizacji).
Natomiast w przypadku InnoDB wersja obiektu przechowywana w segmencie Cofnij jest zwykle mniejsza niż odpowiedni wstawiony rekord. Dzieje się tak, ponieważ tylko zmienione wartości (tj. Różnice) są zapisywane w dzienniku UNDO.
-
Operacja WSTAW
InnoDB musi napisać jeden dodatkowy rekord w segmencie UNDO nawet dla INSERT, podczas gdy PostgreSQL tworzy nową wersję tylko w przypadku UPDATE.
-
Przywracanie starszej wersji w przypadku wycofania
PostgreSQL nie potrzebuje niczego konkretnego, aby przywrócić starszą wersję w przypadku wycofania. Pamiętaj, że starsza wersja ma xmax równe transakcji, która zaktualizowała tę krotkę. Tak więc, dopóki ten identyfikator transakcji nie zostanie zatwierdzony, uważa się, że jest to żywa krotka dla współbieżnej migawki. Po wycofaniu transakcji odpowiednia transakcja zostanie automatycznie uznana za aktywną dla wszystkich transakcji, ponieważ będzie to transakcja przerwana.
Podczas gdy w przypadku InnoDB, jest wyraźnie wymagane odbudowanie starszej wersji obiektu po wycofaniu.
-
Odzyskiwanie miejsca zajmowanego przez starszą wersję
W przypadku PostgreSQL miejsce zajmowane przez starszą wersję można uznać za martwe tylko wtedy, gdy nie ma równoległej migawki do odczytu tej wersji. Gdy starsza wersja jest martwa, operacja VACUUM może odzyskać zajmowaną przez nie przestrzeń. VACUUM może być uruchamiany ręcznie lub jako zadanie w tle, w zależności od konfiguracji.
Dzienniki InnoDB UNDO są podzielone głównie na INSERT UNDO i UPDATE UNDO. Pierwsza z nich zostaje odrzucona, gdy tylko odpowiednia transakcja zostanie zatwierdzona. Drugą trzeba zachować, aż będzie równoległa do każdej innej migawki. InnoDB nie ma wyraźnej operacji VACUUM, ale w podobnej linii ma asynchroniczne PURGE, aby odrzucić logi UNDO, które działa jako zadanie w tle.
-
Wpływ opóźnionej próżni
Jak wspomniano w poprzednim punkcie, w przypadku PostgreSQL istnieje ogromny wpływ opóźnionej próżni. Powoduje to, że tabela zaczyna się powiększać i zwiększa się ilość miejsca do przechowywania, mimo że rekordy są stale usuwane. Może również dojść do punktu, w którym należy wykonać PEŁNĄ PRÓŻNIĘ, co jest bardzo kosztowną operacją.
-
Skanowanie sekwencyjne w przypadku rozdętego stołu
Skanowanie sekwencyjne PostgreSQL musi przechodzić przez wszystkie starsze wersje obiektu, nawet jeśli wszystkie są martwe (do momentu usunięcia próżniowego). Jest to typowy i najczęściej omawiany problem w PostgreSQL. Pamiętaj, że PostgreSQL przechowuje wszystkie wersje krotki w tej samej pamięci.
Natomiast w przypadku InnoDB, nie musi odczytywać rekordu Cofnij, chyba że jest to wymagane. W przypadku, gdy wszystkie rekordy cofania są martwe, wystarczy tylko przeczytać wszystkie najnowsze wersje obiektów.
-
Indeks
PostgreSQL przechowuje indeks w oddzielnym magazynie, który przechowuje jedno łącze do rzeczywistych danych w HEAP. Więc PostgreSQL musi zaktualizować część INDEX, nawet jeśli nie było żadnych zmian w INDEX. Chociaż później ten problem został naprawiony przez implementację aktualizacji HOT (Heap Only Tuple), ale nadal ma ograniczenie polegające na tym, że jeśli nowa krotka sterty nie może zostać umieszczona na tej samej stronie, zostanie przywrócona do normalnej aktualizacji.
InnoDB nie ma tego problemu, ponieważ używa indeksu klastrowego.
Wniosek
PostgreSQL MVCC ma kilka wad, zwłaszcza jeśli chodzi o nadmierną pamięć masową, jeśli twoje obciążenie ma częste UPDATE/DELETE. Więc jeśli zdecydujesz się użyć PostgreSQL, powinieneś być bardzo ostrożny, aby mądrze skonfigurować VACUUM.
Społeczność PostgreSQL również uznała to za poważny problem i już rozpoczęło pracę nad podejściem MVCC opartym na UNDO (nazwa wstępna to ZHEAP) i możemy zobaczyć to samo w przyszłej wersji.