Obciążenie bazy danych MySQL zależy od liczby przetwarzanych przez nią zapytań. Istnieje kilka sytuacji, w których może powstać spowolnienie MySQL. Pierwsza możliwość dotyczy zapytań, które nie używają prawidłowego indeksowania. Gdy zapytanie nie może skorzystać z indeksu, serwer MySQL musi użyć więcej zasobów i czasu, aby przetworzyć to zapytanie. Monitorując zapytania, masz możliwość wskazania kodu SQL, który jest główną przyczyną spowolnienia i naprawienia go, zanim ogólna wydajność spadnie.
W tym poście na blogu zamierzamy wyróżnić funkcję Query Outlier dostępną w ClusterControl i zobaczyć, jak może ona pomóc nam poprawić wydajność bazy danych. Ogólnie ClusterControl wykonuje próbkowanie zapytań MySQL na dwa sposoby:
- Pobierz zapytania ze schematu wydajności (zalecane ).
- Przeanalizuj zawartość MySQL Slow Query.
Jeśli schemat wydajności jest wyłączony, ClusterControl domyślnie przejdzie do dziennika powolnych zapytań. Aby dowiedzieć się więcej o tym, jak ClusterControl to robi, zapoznaj się z tym wpisem na blogu Jak używać ClusterControl Query Monitor dla MySQL, MariaDB i Percona Server.
Co to są wartości odstające zapytań?
Obserwacja odstająca to zapytanie, które zajmuje więcej czasu niż normalny czas zapytania tego typu. Nie traktuj tego dosłownie jako „źle napisane” zapytania. Należy je traktować jako potencjalne nieoptymalne wspólne zapytania, które można poprawić. Po wielu próbkach i gdy ClusterControl ma wystarczającą ilość statystyk, może określić, czy opóźnienie jest wyższe niż normalnie (2 sigma + średnia_czas_zapytania), to jest wartością odstającą i zostanie dodana do wartości odstającej zapytania.
Ta funkcja jest zależna od funkcji Najpopularniejsze zapytania. Jeśli monitorowanie zapytań jest włączone, a najpopularniejsze zapytania są przechwytywane i wypełniane, wartości odstające zapytań podsumują je i zapewnią filtr oparty na sygnaturze czasowej. Aby zobaczyć listę zapytań wymagających uwagi, przejdź do ClusterControl -> Query Monitor -> Query Outliers i powinieneś zobaczyć listę zapytań (jeśli są):
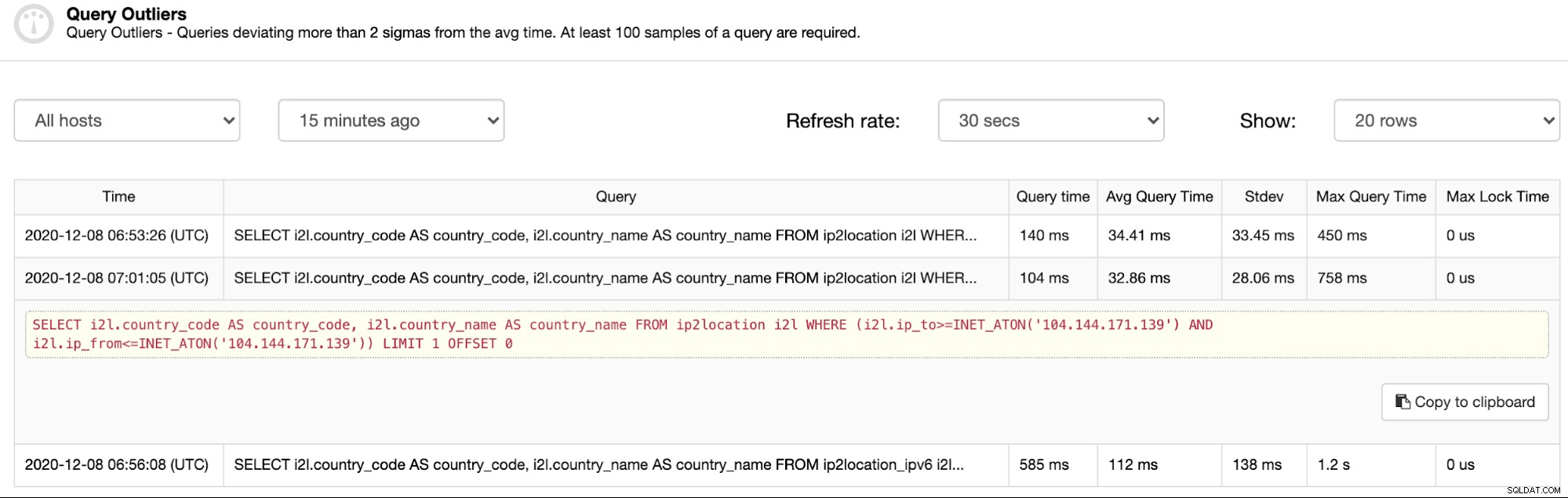
Jak widać na powyższym zrzucie ekranu, wartości odstające to w zasadzie zapytania, które trwało co najmniej 2 razy dłużej niż średni czas zapytania. Pierwszy wpis, średni czas to 34,41 ms, podczas gdy czas zapytania odstającego wynosi 140 ms (ponad 2 razy więcej niż średni czas). Podobnie w przypadku następnych wpisów kolumny Query Time i Avg Query Time to dwie ważne rzeczy, które uzasadniają zaległe wyniki konkretnego zapytania odstającego.
Stosunkowo łatwo jest znaleźć wzorzec konkretnego elementu odstającego zapytania, patrząc na dłuższy okres, na przykład tydzień temu, jak pokazano na poniższym zrzucie ekranu:
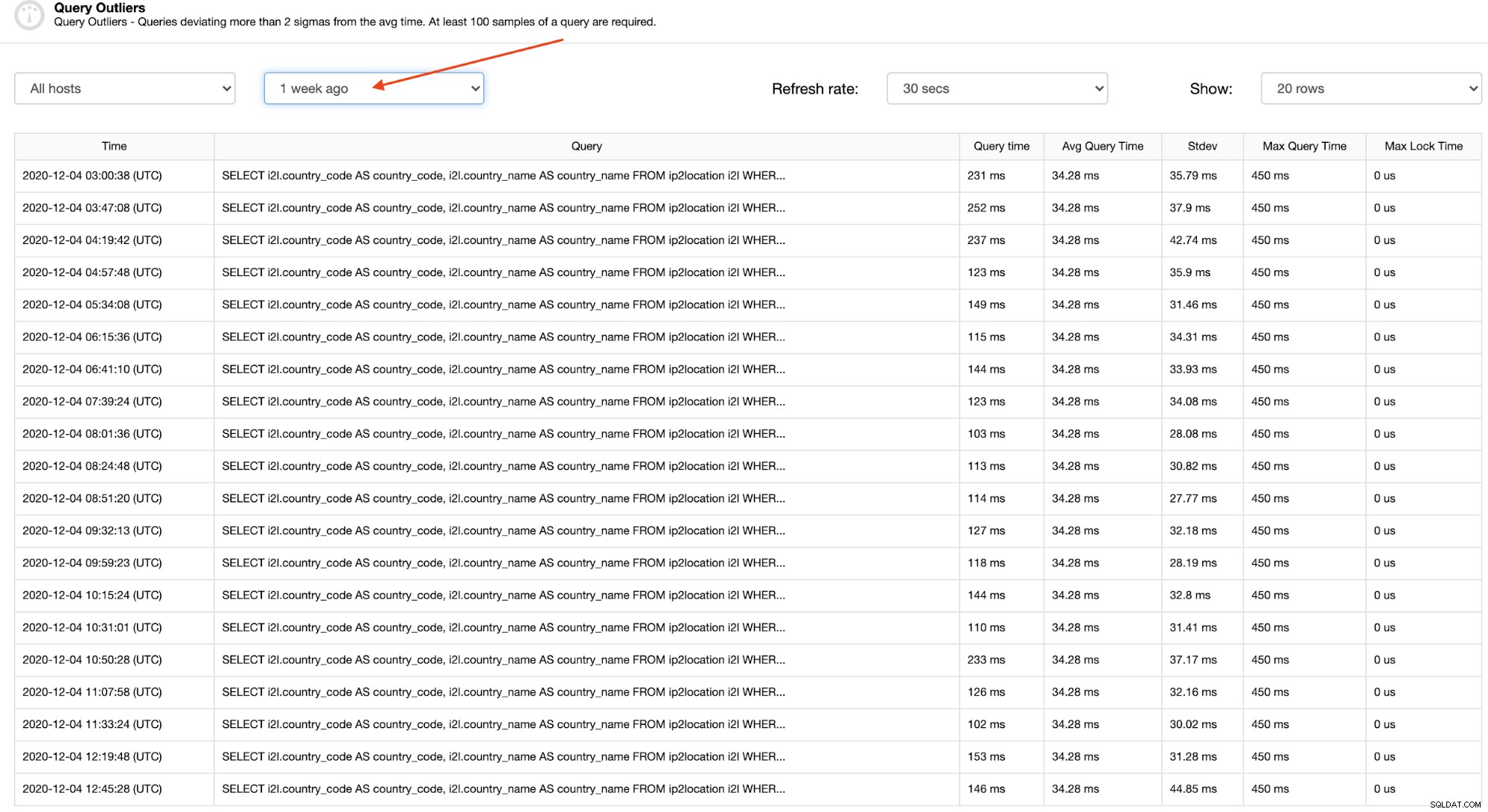
Klikając każdy wiersz, możesz zobaczyć pełne zapytanie, które jest naprawdę pomocne w zlokalizowaniu i zrozumieniu problemu, jak pokazano w następnej sekcji.
Naprawianie wyników odstających zapytań
Aby naprawić wartości odstające, musimy zrozumieć naturę zapytania, mechanizm przechowywania tabel, wersję bazy danych, typ klastrowania i wpływ zapytania. W niektórych przypadkach zapytanie o wartości odstające w rzeczywistości nie pogarsza ogólnej wydajności bazy danych. Tak jak w tym przykładzie, widzieliśmy, że zapytanie wyróżniało się przez cały tydzień i było to jedyne przechwycone zapytanie, więc prawdopodobnie dobrym pomysłem jest naprawienie lub ulepszenie tego zapytania, jeśli to możliwe.
Podobnie jak w naszym przypadku, zapytanie odstające to:
SELECT i2l.country_code AS country_code, i2l.country_name AS country_name
FROM ip2location i2l
WHERE (i2l.ip_to >= INET_ATON('104.144.171.139')
AND i2l.ip_from <= INET_ATON('104.144.171.139'))
LIMIT 1
OFFSET 0;A wynik zapytania to:
+--------------+---------------+
| country_code | country_name |
+--------------+---------------+
| US | United States |
+--------------+---------------+Korzystanie z WYJAŚNIJ
Zapytanie jest zapytaniem wyboru zakresu tylko do odczytu w celu określenia informacji o położeniu geograficznym użytkownika (kod kraju i nazwa kraju) dla adresu IP w tabeli ip2location. Użycie instrukcji EXPLAIN może pomóc nam zrozumieć plan wykonania zapytania:
mysql> EXPLAIN SELECT i2l.country_code AS country_code, i2l.country_name AS country_name
FROM ip2location i2l
WHERE (i2l.ip_to>=INET_ATON('104.144.171.139')
AND i2l.ip_from<=INET_ATON('104.144.171.139'))
LIMIT 1 OFFSET 0;
+----+-------------+-------+------------+-------+--------------------------------------+-------------+---------+------+-------+----------+------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+--------------------------------------+-------------+---------+------+-------+----------+------------------------------------+
| 1 | SIMPLE | i2l | NULL | range | idx_ip_from,idx_ip_to,idx_ip_from_to | idx_ip_from | 5 | NULL | 66043 | 50.00 | Using index condition; Using where |
+----+-------------+-------+------------+-------+--------------------------------------+-------------+---------+------+-------+----------+------------------------------------+Zapytanie jest wykonywane ze skanowaniem zakresu w tabeli przy użyciu indeksu idx_ip_from z 50% potencjalnymi wierszami (filtrowanymi).
Właściwy silnik pamięci masowej
Patrząc na strukturę tabeli ip2location:
mysql> SHOW CREATE TABLE ip2location\G
*************************** 1. row ***************************
Table: ip2location
Create Table: CREATE TABLE `ip2location` (
`ip_from` int(10) unsigned DEFAULT NULL,
`ip_to` int(10) unsigned DEFAULT NULL,
`country_code` char(2) COLLATE utf8_bin DEFAULT NULL,
`country_name` varchar(64) COLLATE utf8_bin DEFAULT NULL,
KEY `idx_ip_from` (`ip_from`),
KEY `idx_ip_to` (`ip_to`),
KEY `idx_ip_from_to` (`ip_from`,`ip_to`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_binTa tabela jest oparta na bazie danych lokalizacji IP2 i rzadko jest aktualizowana/zapisywana, zwykle tylko pierwszego dnia miesiąca kalendarzowego (zalecane przez dostawcę). Jedną z opcji jest konwersja tabeli do silnika pamięci masowej MyISAM (MySQL) lub Aria (MariaDB) ze stałym formatem wierszy, aby uzyskać lepszą wydajność tylko do odczytu. Pamiętaj, że ma to zastosowanie tylko wtedy, gdy korzystasz z autonomicznego MySQL lub MariaDB lub z replikacją. W Galera Cluster and Group Replication, trzymaj się silnika pamięci masowej InnoDB (chyba że wiesz, co robisz).
W każdym razie, aby przekonwertować tabelę z InnoDB na MyISAM ze stałym formatem wiersza, po prostu uruchom następujące polecenie:
ALTER TABLE ip2location ENGINE=MyISAM ROW_FORMAT=FIXED;W naszych pomiarach, przy 1000 losowych testach wyszukiwania adresów IP, wydajność zapytań poprawiła się o około 20% dzięki MyISAM i stałemu formatowi wierszy:
- Średni czas (InnoDB):21,467823 ms
- Średni czas (MyISAM naprawiony):17,175942 ms
- Poprawa:19.992157565301 %
Możesz oczekiwać, że ten wynik będzie natychmiastowy po zmianie tabeli. Żadna modyfikacja na wyższym poziomie (aplikacja/system równoważenia obciążenia) nie jest konieczna.
Dostrajanie zapytania
Innym sposobem jest sprawdzenie planu zapytań i zastosowanie wydajniejszego podejścia do lepszego planu wykonywania zapytań. To samo zapytanie można również napisać za pomocą podzapytania, jak poniżej:
SELECT `country_code`, `country_name` FROM
(SELECT `country_code`, `country_name`, `ip_from`
FROM `ip2location`
WHERE ip_to >= INET_ATON('104.144.171.139')
LIMIT 1)
AS temptable
WHERE ip_from <= INET_ATON('104.144.171.139');Dostrojone zapytanie ma następujący plan wykonania zapytania:
mysql> EXPLAIN SELECT `country_code`,`country_name` FROM
(SELECT `country_code`, `country_name`, `ip_from`
FROM `ip2location`
WHERE ip_to >= INET_ATON('104.144.171.139')
LIMIT 1)
AS temptable
WHERE ip_from <= INET_ATON('104.144.171.139');
+----+-------------+--------------+------------+--------+---------------+-----------+---------+------+-------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------------+------------+--------+---------------+-----------+---------+------+-------+----------+-----------------------+
| 1 | PRIMARY | <derived2> | NULL | system | NULL | NULL | NULL | NULL | 1 | 100.00 | NULL |
| 2 | DERIVED | ip2location | NULL | range | idx_ip_to | idx_ip_to | 5 | NULL | 66380 | 100.00 | Using index condition |
+----+-------------+--------------+------------+--------+---------------+-----------+---------+------+-------+----------+-----------------------+Korzystając z podzapytania, możemy zoptymalizować zapytanie, korzystając z tabeli pochodnej, która skupia się na jednym indeksie. Zapytanie powinno zwrócić tylko 1 rekord, w którym wartość ip_to jest większa lub równa wartości adresu IP. Dzięki temu potencjalne rzędy (filtrowane) osiągną 100%, co jest najbardziej wydajne. Następnie sprawdź, czy wartość ip_from jest mniejsza lub równa wartości adresu IP. Jeśli tak, to powinniśmy znaleźć zapis. W przeciwnym razie adres IP nie istnieje w tabeli ip2location.
W naszym pomiarze wydajność zapytania poprawiła się o około 99% przy użyciu podzapytania:
- Średni czas (InnoDB + skanowanie zakresu):22.87112 ms
- Średni czas (InnoDB + podzapytanie):0,14744 ms
- Poprawa:99.355344207017 %
Dzięki powyższej optymalizacji możemy zauważyć submilisekundowy czas wykonania zapytań tego typu, co jest ogromną poprawą biorąc pod uwagę poprzedni średni czas wynoszący 22 ms. Jednak musimy wprowadzić pewne modyfikacje na wyższym poziomie (równoważnik aplikacji/obciążenia), aby skorzystać z tego dostrojonego zapytania.
Łatanie lub przepisywanie zapytań
Popraw swoje aplikacje, aby używały dostrojonego zapytania lub przepisz zapytanie odstające, zanim dotrze ono do serwera bazy danych. Możemy to osiągnąć, używając modułu równoważenia obciążenia MySQL, takiego jak ProxySQL (reguły zapytań) lub MariaDB MaxScale (filtr przepisywania instrukcji) lub korzystając z wtyczki MySQL Query Rewriter. W poniższym przykładzie używamy ProxySQL przed naszym klastrem baz danych i możemy po prostu utworzyć regułę przepisywania wolniejszego zapytania na szybsze, na przykład:
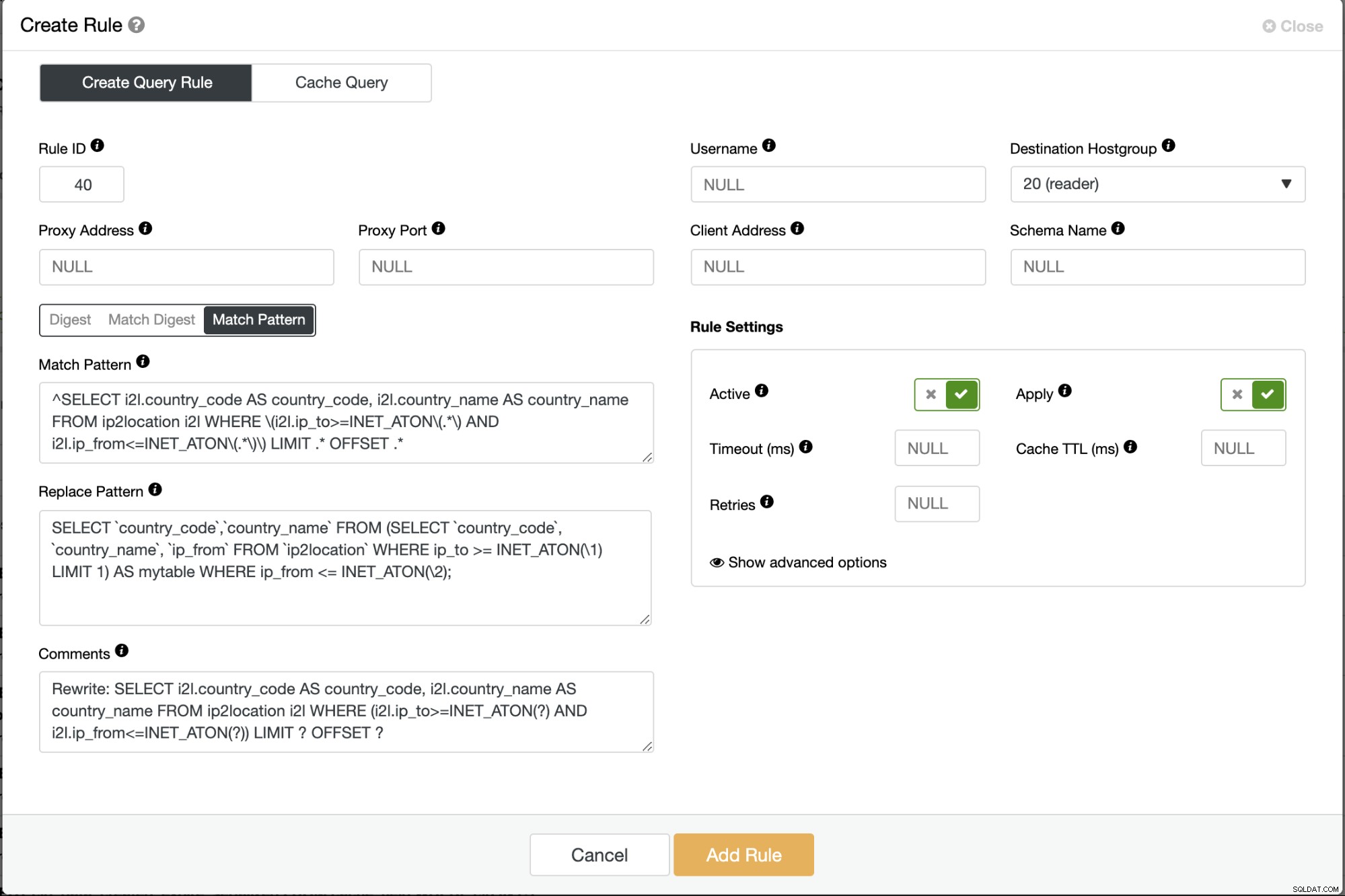
Zapisz regułę zapytania i monitoruj stronę Query Outliers w ClusterControl. Ta poprawka oczywiście usunie zapytania odstające z listy po aktywowaniu reguły zapytania.
Wnioski
Obserwacje odstające zapytań to proaktywne narzędzie do monitorowania zapytań, które może pomóc nam zrozumieć i naprawić problem z wydajnością, zanim wymknie się on spod kontroli. W miarę jak aplikacja rośnie i staje się coraz bardziej wymagająca, to narzędzie może pomóc w utrzymaniu przyzwoitej wydajności bazy danych.