Problemy z opóźnieniami replikacji w PostgreSQL nie są powszechnym problemem w większości konfiguracji. Chociaż może się to zdarzyć, a kiedy to nastąpi, może wpłynąć na twoje ustawienia produkcyjne. PostgreSQL jest przeznaczony do obsługi wielu wątków, takich jak równoległość zapytań lub wdrażanie wątków roboczych do obsługi określonych zadań w oparciu o przypisane wartości w konfiguracji. PostgreSQL jest zaprojektowany do obsługi dużych i stresujących obciążeń, ale czasami (z powodu złej konfiguracji) Twój serwer może nadal działać na południe.
Identyfikacja opóźnienia replikacji w PostgreSQL nie jest skomplikowanym zadaniem, ale istnieje kilka różnych podejść do zbadania problemu. W tym blogu przyjrzymy się, na co należy zwrócić uwagę, gdy replikacja PostgreSQL jest opóźniona.
Typy replikacji w PostgreSQL
Zanim zagłębimy się w ten temat, zobaczmy najpierw, jak ewoluuje replikacja w PostgreSQL, ponieważ istnieje zróżnicowany zestaw podejść i rozwiązań dotyczących replikacji.
Warm standby dla PostgreSQL został zaimplementowany w wersji 8.2 (w 2006 roku) i opierał się na metodzie przesyłania dziennika. Oznacza to, że rekordy WAL są bezpośrednio przenoszone z jednego serwera bazy danych na drugi w celu zastosowania lub po prostu analogiczne podejście do PITR lub bardzo podobne do tego, co robisz z rsync.
To podejście, nawet stare, jest nadal stosowane i niektóre instytucje wolą to starsze podejście. To podejście implementuje przesyłanie dzienników oparte na plikach, przesyłając jednocześnie rekordy WAL jeden plik (segment WAL). Chociaż ma to wadę; Poważna awaria serwerów głównych, transakcje, które nie zostały jeszcze wysłane, zostaną utracone. Istnieje okno utraty danych (możesz to dostroić za pomocą parametru archive_timeout, który można ustawić na zaledwie kilka sekund, ale tak niskie ustawienie znacznie zwiększy przepustowość wymaganą do przesyłania plików).
W PostgreSQL w wersji 9.0 wprowadzono replikację strumieniową. Ta funkcja pozwoliła nam być bardziej na czasie w porównaniu z wysyłką logów na podstawie plików. Jego podejście polega na przesyłaniu rekordów WAL (plik WAL składa się z rekordów WAL) w locie (tylko przesyłanie dziennika opartego na rekordach), między serwerem głównym a jednym lub kilkoma serwerami rezerwowymi. Ten protokół nie musi czekać na wypełnienie pliku WAL, w przeciwieństwie do przesyłania dziennika opartego na plikach. W praktyce proces zwany odbiornikiem WAL, działający na serwerze rezerwowym, połączy się z serwerem głównym za pomocą połączenia TCP/IP. Na serwerze podstawowym istnieje inny proces o nazwie WAL sender. Jego rola jest odpowiedzialna za wysyłanie rejestrów WAL do serwerów rezerwowych w miarę ich występowania.
Konfiguracje replikacji asynchronicznej w replikacji strumieniowej mogą powodować problemy, takie jak utrata danych lub opóźnienie podrzędne, dlatego w wersji 9.1 wprowadzono replikację synchroniczną. W replikacji synchronicznej każde zatwierdzenie transakcji zapisu będzie czekać do momentu otrzymania potwierdzenia, że zatwierdzenie zostało zapisane w dzienniku zapisu z wyprzedzeniem na dysku zarówno serwera podstawowego, jak i rezerwowego. Ta metoda minimalizuje możliwość utraty danych, ponieważ do tego celu będziemy potrzebować jednoczesnej awarii mastera i standby.
Oczywistą wadą tej konfiguracji jest to, że wydłuża się czas odpowiedzi dla każdej transakcji zapisu, ponieważ musimy czekać, aż wszystkie strony odpowiedzą. W przeciwieństwie do MySQL, nie ma wsparcia, na przykład w półsynchronicznym środowisku MySQL, po awarii nastąpi powrót do asynchronicznego, jeśli nastąpi przekroczenie limitu czasu. Tak więc w przypadku PostgreSQL czas na zatwierdzenie to (co najmniej) podróż w obie strony między serwerem podstawowym a rezerwowym. Nie będzie to miało wpływu na transakcje tylko do odczytu.
W miarę rozwoju PostgreSQL jest stale ulepszany, a mimo to jego replikacja jest różnorodna. Na przykład można użyć fizycznej asynchronicznej replikacji strumieniowej lub logicznej replikacji strumieniowej. Oba są monitorowane w różny sposób, ale używają tego samego podejścia podczas wysyłania danych przez replikację, która nadal jest replikacją strumieniową. Aby uzyskać więcej informacji, zapoznaj się z instrukcją obsługi różnych typów rozwiązań w PostgreSQL w przypadku replikacji.
Przyczyny opóźnienia replikacji PostgreSQL
Zgodnie z definicją w naszym poprzednim blogu opóźnienie replikacji to koszt opóźnienia transakcji lub operacji obliczony na podstawie różnicy czasu wykonania między głównym/głównym a rezerwowym/podrzędnym węzeł.
Ponieważ PostgreSQL używa replikacji strumieniowej, został zaprojektowany tak, aby był szybki, ponieważ zmiany są rejestrowane jako zestaw sekwencji rekordów dziennika (bajt po bajcie) przechwyconych przez odbiornik WAL, a następnie zapisuje te rekordy dziennika do pliku WAL. Następnie proces uruchamiania przez PostgreSQL odtwarza dane z tego segmentu WAL i rozpoczyna się replikacja strumieniowa. W PostgreSQL opóźnienie replikacji może wynikać z następujących czynników:
- Problemy z siecią
- Nie można znaleźć segmentu WAL z podstawowego. Zwykle jest to spowodowane zachowaniem punktów kontrolnych, w których segmenty WAL są obracane lub poddawane recyklingowi
- Zajęte węzły (główne i rezerwowe). Może być spowodowane przez procesy zewnętrzne lub nieprawidłowe zapytania, które wymagają dużej ilości zasobów
- Zły sprzęt lub problemy ze sprzętem powodujące pewne opóźnienia
- Słaba konfiguracja w PostgreSQL, taka jak mała liczba max_wal_senders ustawiona podczas przetwarzania ton żądań transakcji (lub dużej ilości zmian).
Na co zwrócić uwagę z opóźnieniem replikacji PostgreSQL
Replikacja PostgreSQL jest jeszcze zróżnicowana, ale monitorowanie stanu replikacji jest subtelne, ale nie skomplikowane. W tym podejściu pokażemy, że są one oparte na konfiguracji podstawowego trybu gotowości z asynchroniczną replikacją strumieniową. Replikacja logiczna nie może przynieść korzyści w większości przypadków, które tutaj omawiamy, ale widok pg_stat_subscription może pomóc w zbieraniu informacji. Jednak nie będziemy się na tym skupiać w tym blogu.
Korzystanie z widoku pg_stat_replication
Najczęstszym podejściem jest uruchomienie zapytania odwołującego się do tego widoku w węźle podstawowym. Pamiętaj, że za pomocą tego widoku możesz zbierać informacje tylko z węzła podstawowego. Ten widok zawiera następującą definicję tabeli opartą na PostgreSQL 11, jak pokazano poniżej:
postgres=# \d pg_stat_replication
View "pg_catalog.pg_stat_replication"
Column | Type | Collation | Nullable | Default
------------------+--------------------------+-----------+----------+---------
pid | integer | | |
usesysid | oid | | |
usename | name | | |
application_name | text | | |
client_addr | inet | | |
client_hostname | text | | |
client_port | integer | | |
backend_start | timestamp with time zone | | |
backend_xmin | xid | | |
state | text | | |
sent_lsn | pg_lsn | | |
write_lsn | pg_lsn | | |
flush_lsn | pg_lsn | | |
replay_lsn | pg_lsn | | |
write_lag | interval | | |
flush_lag | interval | | |
replay_lag | interval | | |
sync_priority | integer | | |
sync_state | text | | | Gdzie pola są zdefiniowane jako (w tym wersja PG <10),
- pid :Identyfikator procesu procesu Walsendera
- identyfikator użycia :OID użytkownika, który jest używany do replikacji strumieniowej.
- nazwa użytkownika :Nazwa użytkownika, który jest używany do replikacji strumieniowej
- nazwa_aplikacji :Nazwa aplikacji połączona z masterem
- client_addr :Adres replikacji w trybie gotowości/strumieniowania
- nazwa_hosta_klienta :Nazwa hosta w trybie gotowości.
- port_klienta :Numer portu TCP, na którym standby komunikuje się z nadawcą WAL
- backend_start :Czas rozpoczęcia, gdy SR połączył się z Master.
- backend_xmin :horyzont xmin czuwania zgłaszany przez hot_standby_feedback.
- stan :Aktualny stan nadawcy WAL, tj. streaming
- sent_lsn /wysłana_lokalizacja :Ostatnia lokalizacja transakcji wysłana do trybu gotowości.
- write_lsn /write_location :Ostatnia transakcja zapisana na dysku w trybie gotowości
- flush_lsn /flush_location :Ostatnia transakcja opróżniona na dysku w trybie gotowości.
- replay_lsn /lokalizacja_odtwarzania :Ostatnia transakcja opróżniona na dysku w trybie gotowości.
- write_lag :Czas, który upłynął podczas zatwierdzonych warstw WAL od podstawowego do rezerwowego (ale jeszcze nie zatwierdzony w trybie gotowości)
- flush_lag :Czas, który upłynął podczas zatwierdzonych WAL-ów od podstawowego do gotowości (WAL został już usunięty, ale jeszcze nie zastosowany)
- replay_lag :Czas, jaki upłynął podczas zatwierdzonych WAL-ów od podstawowego do rezerwowego (w pełni zatwierdzone w węźle rezerwowym)
- sync_priority :Priorytet wyboru serwera rezerwowego jako synchronicznego czuwania
- sync_state :Synchronizacja stanu gotowości (czy jest asynchroniczna czy synchroniczna).
Przykładowe zapytanie wyglądałoby następująco w PostgreSQL 9.6,
paultest=# select * from pg_stat_replication;
-[ RECORD 1 ]----+------------------------------
pid | 7174
usesysid | 16385
usename | cmon_replication
application_name | pgsql_1_node_1
client_addr | 192.168.30.30
client_hostname |
client_port | 10580
backend_start | 2020-02-20 18:45:52.892062+00
backend_xmin |
state | streaming
sent_location | 1/9FD5D78
write_location | 1/9FD5D78
flush_location | 1/9FD5D78
replay_location | 1/9FD5D78
sync_priority | 0
sync_state | async
-[ RECORD 2 ]----+------------------------------
pid | 7175
usesysid | 16385
usename | cmon_replication
application_name | pgsql_80_node_2
client_addr | 192.168.30.20
client_hostname |
client_port | 60686
backend_start | 2020-02-20 18:45:52.899446+00
backend_xmin |
state | streaming
sent_location | 1/9FD5D78
write_location | 1/9FD5D78
flush_location | 1/9FD5D78
replay_location | 1/9FD5D78
sync_priority | 0
sync_state | asyncTo zasadniczo informuje, które bloki lokalizacji w segmentach WAL zostały zapisane, opróżnione lub zastosowane. Zapewnia szczegółowy podgląd stanu replikacji.
Zapytania do użycia w węźle gotowości
W węźle gotowości są obsługiwane funkcje, w przypadku których można ograniczyć to do postaci zapytania i zapewnić przegląd stanu replikacji w stanie gotowości. Aby to zrobić, możesz uruchomić następujące zapytanie poniżej (zapytanie jest oparte na wersji PG> 10),
postgres=# select pg_is_in_recovery(),pg_is_wal_replay_paused(), pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn(), pg_last_xact_replay_timestamp();
-[ RECORD 1 ]-----------------+------------------------------
pg_is_in_recovery | t
pg_is_wal_replay_paused | f
pg_last_wal_receive_lsn | 0/2705BDA0
pg_last_wal_replay_lsn | 0/2705BDA0
pg_last_xact_replay_timestamp | 2020-02-21 02:18:54.603677+00W starszych wersjach możesz użyć następującego zapytania:
postgres=# select pg_is_in_recovery(),pg_last_xlog_receive_location(), pg_last_xlog_replay_location(), pg_last_xact_replay_timestamp();
-[ RECORD 1 ]-----------------+------------------------------
pg_is_in_recovery | t
pg_last_xlog_receive_location | 1/9FD6490
pg_last_xlog_replay_location | 1/9FD6490
pg_last_xact_replay_timestamp | 2020-02-21 08:32:40.485958-06Co mówi zapytanie? Funkcje są tutaj odpowiednio zdefiniowane,
- pg_is_in_recovery ():(boolean) Prawda, jeśli odzyskiwanie nadal trwa.
- pg_last_wal_receive_lsn ()/pg_last_xlog_receive_location(): (pg_lsn) Lokalizacja dziennika zapisu z wyprzedzeniem odebrana i zsynchronizowana z dyskiem przez replikację strumieniową.
- pg_last_wal_replay_lsn ()/pg_last_xlog_replay_location(): (pg_lsn) Ostatnia lokalizacja dziennika zapisu z wyprzedzeniem odtwarzana podczas odzyskiwania. Jeśli proces przywracania jest nadal w toku, będzie wzrastał monotonicznie.
- pg_last_xact_replay_timestamp (): (sygnatura czasowa ze strefą czasową) Pobierz sygnaturę czasową ostatniej transakcji odtworzonej podczas odzyskiwania.
Korzystając z podstawowej matematyki, możesz połączyć te funkcje. Najczęściej używane funkcje używane przez administratorów baz danych to:
SELECT CASE WHEN pg_last_wal_receive_lsn() = pg_last_wal_replay_lsn()
THEN 0
ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
END AS log_delay;
lub w wersjach PG <10,
SELECT CASE WHEN pg_last_xlog_receive_location() = pg_last_xlog_replay_location()
THEN 0
ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
END AS log_delay;Chociaż to zapytanie było w praktyce i jest używane przez administratorów baz danych. Mimo to nie zapewnia dokładnego obrazu opóźnienia. Czemu? Omówmy to w następnej sekcji.
Identyfikowanie opóźnienia spowodowanego brakiem segmentu WAL
Węzły rezerwowe PostgreSQL, które są w trybie odzyskiwania, nie zgłaszają dokładnego stanu replikacji. Nie, dopóki nie przejrzysz dziennika PG, możesz zebrać informacje o tym, co się dzieje. Nie ma zapytania, które można uruchomić, aby to ustalić. W większości przypadków organizacje, a nawet małe instytucje opracowują oprogramowanie innych firm, które pozwala im ostrzegać, gdy zostanie podniesiony alarm.
Jednym z nich jest ClusterControl, który zapewnia obserwowalność, wysyła alerty, gdy alarmy są zgłoszone lub przywraca węzeł w przypadku katastrofy lub katastrofy. Weźmy ten scenariusz, mój klaster asynchronicznej replikacji strumieniowej w podstawowym trybie gotowości nie powiódł się. Skąd wiesz, że coś jest nie tak? Połączmy następujące:
Krok 1:Określ, czy występuje opóźnienie
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn() = pg_last_wal_replay_lsn()
postgres-# THEN 0
postgres-# ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
postgres-# END AS log_delay;
-[ RECORD 1 ]
log_delay | 0Krok 2:Określ segmenty WAL otrzymane z głównego i porównaj z węzłem gotowości
## Get the master's current LSN. Run the query below in the master
postgres=# SELECT pg_current_wal_lsn();
-[ RECORD 1 ]------+-----------
pg_current_wal_lsn | 0/925D7E70W przypadku starszych wersji PG <10 użyj pg_current_xlog_location.
## Get the current WAL segments received (flushed or applied/replayed)
postgres=# select pg_is_in_recovery(),pg_is_wal_replay_paused(), pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn(), pg_last_xact_replay_timestamp();
-[ RECORD 1 ]-----------------+------------------------------
pg_is_in_recovery | t
pg_is_wal_replay_paused | f
pg_last_wal_receive_lsn | 0/2705BDA0
pg_last_wal_replay_lsn | 0/2705BDA0
pg_last_xact_replay_timestamp | 2020-02-21 02:18:54.603677+00Wygląda to źle.
Krok 3:Określ, jak bardzo może być źle
Teraz wymieszajmy formułę z kroku 1 i kroku 2, aby uzyskać różnicę. Jak to zrobić, PostgreSQL ma funkcję o nazwie pg_wal_lsn_diff, która jest zdefiniowana jako,
pg_wal_lsn_diff(lsn pg_lsn, lsn pg_lsn) / pg_xlog_location_diff (lokalizacja pg_lsn, lokalizacja pg_lsn): (liczba) Oblicz różnicę między dwoma lokalizacjami dziennika zapisu z wyprzedzeniem
Teraz użyjmy go do określenia opóźnienia. Możesz go uruchomić w dowolnym węźle PG, ponieważ dostarczamy tylko wartości statyczne:
postgres=# select pg_wal_lsn_diff('0/925D7E70','0/2705BDA0'); -[ RECORD 1 ]---+-----------
pg_wal_lsn_diff | 1800913104Oszacujmy, ile wynosi 1800913104, czyli około 1,6GiB mogło być nieobecne w węźle gotowości,
postgres=# select round(1800913104/pow(1024,3.0),2) missing_lsn_GiB;
-[ RECORD 1 ]---+-----
missing_lsn_gib | 1.68Na koniec możesz kontynuować lub nawet przed zapytaniem spojrzeć na logi, np. używając tail -5f do śledzenia i sprawdzania, co się dzieje. Zrób to dla obu węzłów podstawowych i rezerwowych. W tym przykładzie zobaczymy, że ma problem,
## Primary
example@sqldat.com:/var/lib/postgresql/11/main# tail -5f log/postgresql-2020-02-21_033512.log
2020-02-21 16:44:33.574 UTC [25023] ERROR: requested WAL segment 000000030000000000000027 has already been removed
...
## Standby
example@sqldat.com:/var/lib/postgresql/11/main# tail -5f log/postgresql-2020-02-21_014137.log
2020-02-21 16:45:23.599 UTC [26976] LOG: started streaming WAL from primary at 0/27000000 on timeline 3
2020-02-21 16:45:23.599 UTC [26976] FATAL: could not receive data from WAL stream: ERROR: requested WAL segment 000000030000000000000027 has already been removed
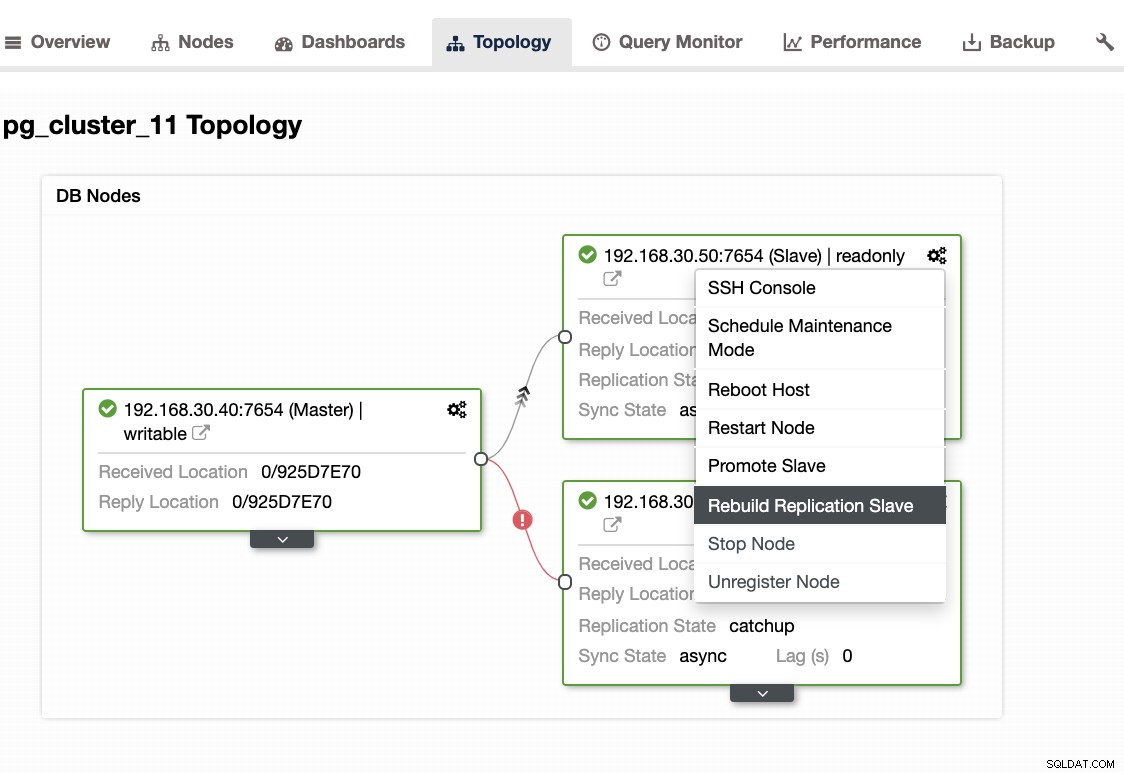
...W przypadku napotkania tego problemu lepiej jest odbudować węzły rezerwowe. W ClusterControl wystarczy jedno kliknięcie. Po prostu przejdź do sekcji Węzły/Topologia i odbuduj węzeł tak jak poniżej:
Inne rzeczy do sprawdzenia
Możesz zastosować to samo podejście w naszym poprzednim blogu (w MySQL), używając narzędzi systemowych, takich jak kombinacja ps, top, iostat, netstat. Na przykład możesz również pobrać bieżący odzyskany segment WAL z węzła gotowości,
example@sqldat.com:/var/lib/postgresql/11/main# ps axufwww|egrep "postgre[s].*startup"
postgres 8065 0.0 8.3 715820 170872 ? Ss 01:41 0:03 \_ postgres: 11/main: startup recovering 000000030000000000000027Jak ClusterControl może pomóc?
ClusterControl oferuje efektywny sposób monitorowania węzłów bazy danych od węzłów głównych do węzłów podrzędnych. Po przejściu na kartę Przegląd masz już widok stanu replikacji:
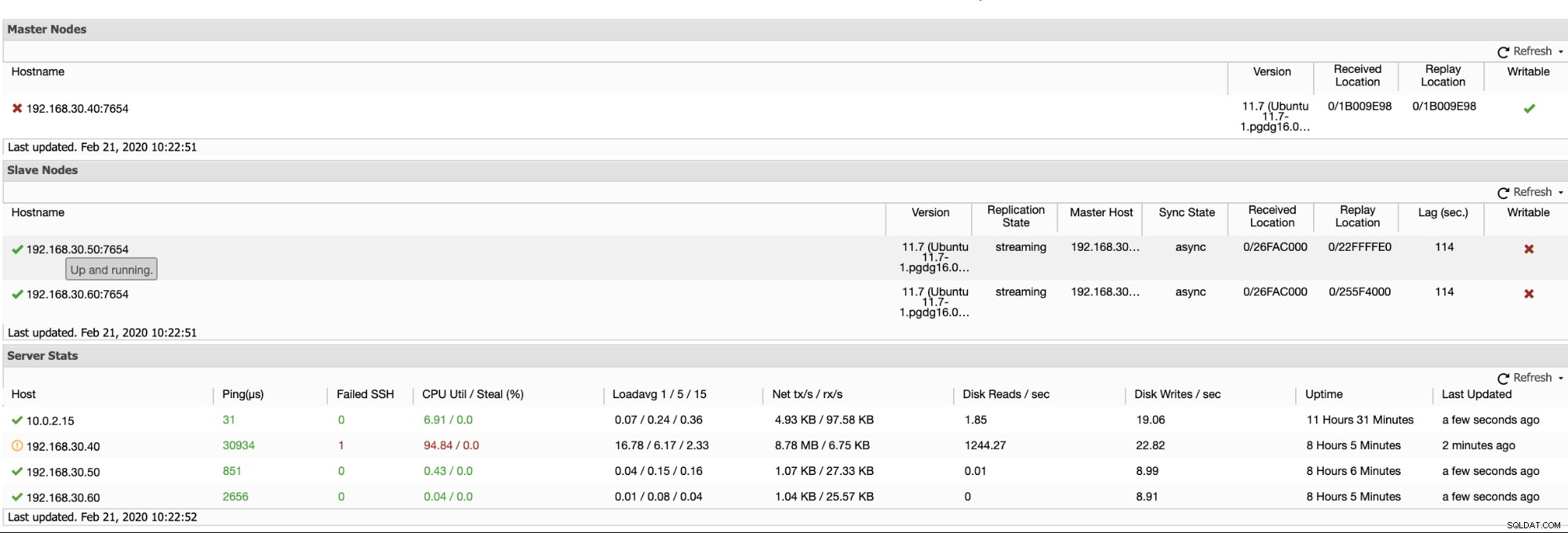
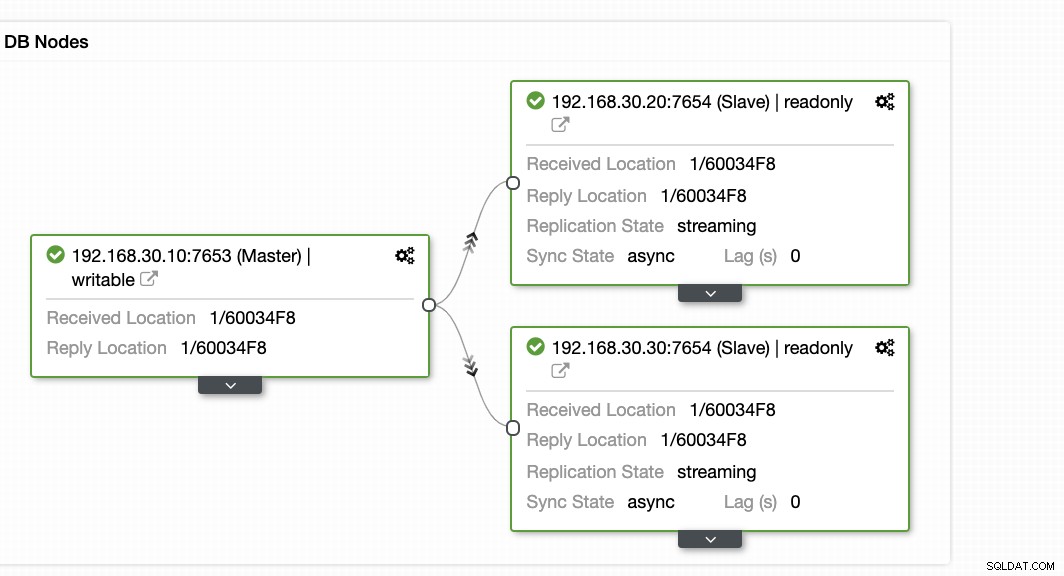
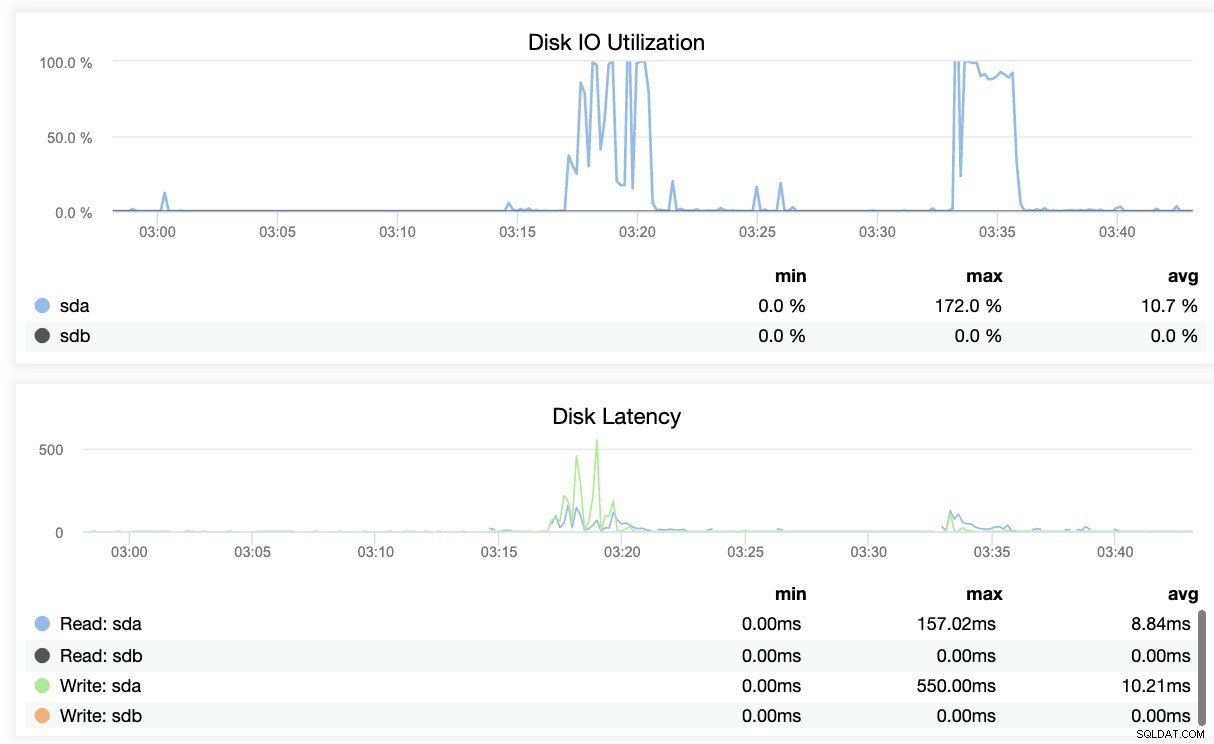
Zasadniczo dwa powyższe zrzuty ekranu przedstawiają stan replikacji i aktualną Segmenty WAL. To wcale nie jest. ClusterControl pokazuje również bieżącą aktywność tego, co dzieje się z Twoim klastrem.
Wnioski
Monitorowanie stanu replikacji w PostgreSQL może skończyć się innym podejściem, o ile jesteś w stanie zaspokoić swoje potrzeby. Korzystanie z narzędzi innych firm z możliwością obserwacji, które mogą powiadamiać Cię w przypadku katastrofy, to idealna droga, niezależnie od tego, czy jest to open source, czy przedsiębiorstwo. Najważniejszą rzeczą jest to, że masz plan odzyskiwania po awarii i ciągłość biznesową zaplanowaną na wypadek takich problemów.