Hybrydowa chmura to nowa koncepcja, która była rozwijana przez kilka lat, a teraz jest powszechną topologią w każdej firmie dla planu odzyskiwania po awarii (DRP), a nawet w celu zapewnienia nadmiarowości w systemach.
Gdy już uruchomisz swoje środowisko Hybrid Cloud, będziesz musiał przez cały czas wiedzieć, co się dzieje. Monitorowanie jest koniecznością, jeśli chcesz mieć pewność, że wszystko jest w porządku lub jeśli musisz coś zmienić. W przypadku każdej technologii baz danych należy monitorować kilka rzeczy. Niektóre z nich są specyficzne dla silnika bazy danych, dostawcy, a nawet konkretnej wersji, której używasz.
W tym blogu zobaczymy, co należy monitorować w bazie danych PostgreSQL działającej w środowisku Hybrid Cloud i jak ClusterControl może pomóc w tym zadaniu.
Co monitorować w PostgreSQL
Podczas monitorowania klastra lub węzła bazy danych należy wziąć pod uwagę dwie główne rzeczy:system operacyjny i samą bazę danych. Musisz określić, które metryki będziesz monitorować z obu stron i jak to zrobisz.
Pamiętaj, że gdy ma to wpływ na jeden z Twoich wskaźników, może to mieć również wpływ na inne, przez co rozwiązywanie problemu staje się bardziej złożone. Posiadanie dobrego systemu monitorowania i ostrzegania jest ważne, aby maksymalnie uprościć to zadanie.
Monitorowanie systemu operacyjnego
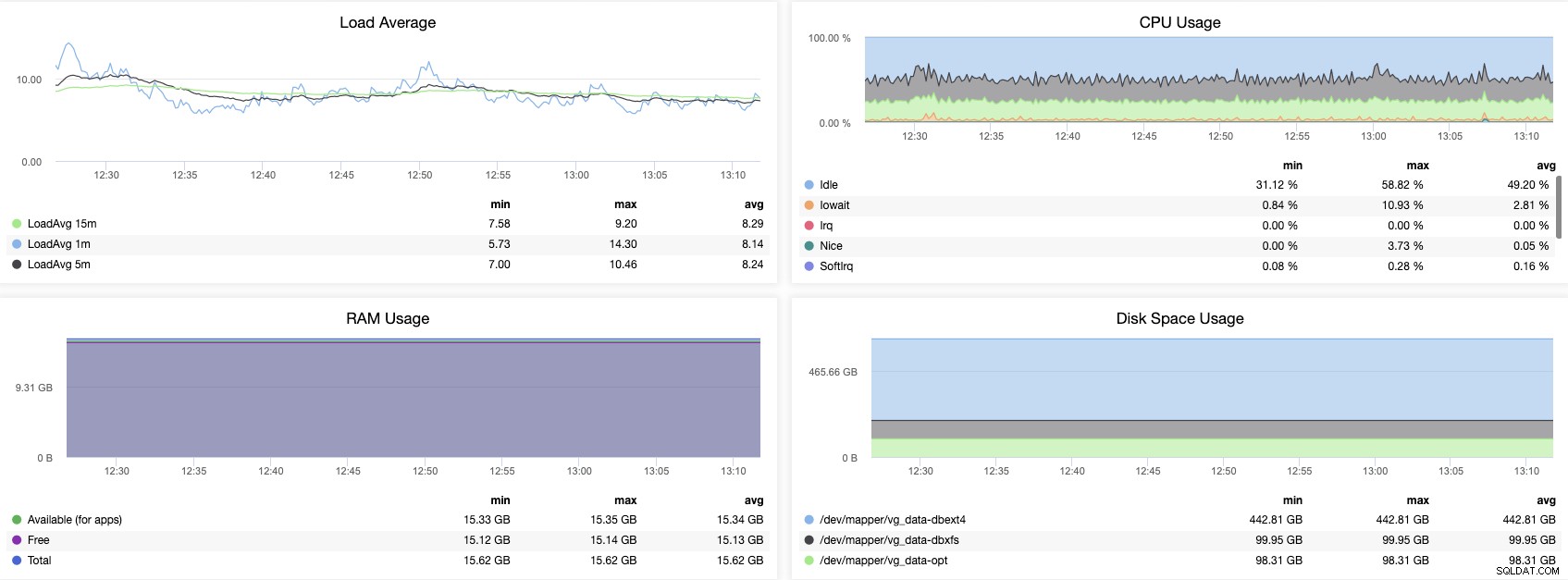
Jedną ważną rzeczą (która jest wspólna dla wszystkich silników baz danych, a nawet dla wszystkich systemów) jest monitorowanie zachowania systemu operacyjnego. Zobaczmy kilka punktów do sprawdzenia tutaj.
Wykorzystanie procesora
Nadmierny procent wykorzystania procesora może stanowić problem, jeśli nie jest to zwykłe zachowanie. W takim przypadku ważne jest, aby zidentyfikować proces/procesy, które generują ten problem. Jeśli problemem jest proces bazy danych, musisz sprawdzić, co dzieje się w bazie danych.
Pamięć RAM lub użycie SWAP
Jeśli widzisz wysoką wartość tej metryki i nic się nie zmieniło w twoim systemie, prawdopodobnie musisz sprawdzić konfigurację bazy danych. Parametry takie jak shared_buffers i work_mem mogą mieć na to bezpośredni wpływ, ponieważ definiują ilość pamięci, którą można wykorzystać dla bazy danych PostgreSQL.
Wykorzystanie dysku
Nienormalny wzrost wykorzystania miejsca na dysku lub nadmierne zużycie dostępu do dysku to ważne rzeczy do monitorowania, ponieważ w pliku dziennika PostgreSQL może być zarejestrowanych wiele błędów lub zła konfiguracja pamięci podręcznej, która może generować ważne zużycie dostępu do dysku zamiast używać pamięci do przetwarzania zapytań.
Średnia obciążenia
Wiąże się to z trzema wymienionymi powyżej punktami. Wysokie średnie obciążenie może być generowane przez nadmierne użycie procesora, pamięci RAM lub dysku.
Sieć
Problem z siecią może mieć wpływ na wszystkie systemy, ponieważ aplikacja nie może połączyć się (lub połączyć utraconych pakietów) z bazą danych, więc jest to istotna metryka do monitorowania. Możesz monitorować opóźnienia lub utratę pakietów, a głównym problemem może być nasycenie sieci, problem ze sprzętem lub po prostu zła konfiguracja sieci.
Monitorowanie bazy danych
Monitorowanie bazy danych PostgreSQL jest ważne nie tylko po to, aby sprawdzić, czy masz problem, ale także, aby wiedzieć, czy musisz coś zmienić, aby poprawić wydajność bazy danych, to prawdopodobnie jedna z najważniejszych rzeczy do monitorowania w bazie danych. Zobaczmy kilka wskaźników, które są w tym ważne.
Monitorowanie zapytań
Ogólnie rzecz biorąc, bazy danych są domyślnie konfigurowane z myślą o kompatybilności i stabilności, więc musisz znać swoje zapytania i ich wzorce oraz konfigurować bazy danych w zależności od ruchu, który masz. Tutaj możesz użyć polecenia EXPLAIN, aby sprawdzić plan zapytania dla określonego zapytania, a także możesz monitorować ilość operacji SELECT, INSERT, UPDATE lub DELETE na każdym węźle. Jeśli masz długie zapytanie lub dużą liczbę zapytań uruchomionych w tym samym czasie, może to stanowić problem dla wszystkich systemów.
Aktywne sesje
Powinieneś także monitorować liczbę aktywnych sesji. Jeśli jesteś blisko limitu, musisz sprawdzić, czy coś jest nie tak, czy po prostu musisz zwiększyć maksymalną wartość połączenia w konfiguracji bazy danych. Różnica w liczbie może oznaczać wzrost lub spadek połączeń. Złe korzystanie z puli połączeń, blokowania lub problemy z siecią to najczęstsze problemy związane z liczbą połączeń.
Blokady bazy danych
Jeśli masz zapytanie oczekujące na inne zapytanie, musisz sprawdzić, czy to inne zapytanie jest normalnym procesem, czy czymś nowym. W niektórych przypadkach, na przykład, jeśli ktoś dokonuje aktualizacji na dużym stole, ta akcja może wpływać na normalne zachowanie bazy danych, generując dużą liczbę blokad.
Stan replikacji
Kluczowe metryki do monitorowania replikacji to opóźnienie i stan replikacji. Najczęstsze problemy to problemy z siecią, problemy z zasobami sprzętowymi lub problemy z niewymiarowaniem. Jeśli napotkasz problem z replikacją, musisz wiedzieć o tym jak najszybciej, ponieważ będziesz musiał to naprawić, aby zapewnić środowisko wysokiej dostępności.
Kopie zapasowe
Unikanie utraty danych jest jednym z podstawowych zadań DBA, więc nie musisz tylko wykonać kopii zapasowej, powinieneś wiedzieć, czy kopia zapasowa została ukończona i czy nadaje się do użytku. Zwykle ten ostatni punkt nie jest brany pod uwagę, ale jest to prawdopodobnie najważniejsza kontrola w procesie tworzenia kopii zapasowej.
Dzienniki bazy danych
Należy monitorować dziennik bazy danych pod kątem błędów, problemów z uwierzytelnianiem, a nawet długotrwałych zapytań. Większość błędów jest zapisywana w pliku dziennika ze szczegółowymi przydatnymi informacjami, aby je naprawić.
Powiadomienia i alerty
Samo monitorowanie systemu nie wystarczy, jeśli nie otrzymasz powiadomienia o każdym problemie. Bez systemu ostrzegania powinieneś przejść do narzędzia monitorującego, aby sprawdzić, czy wszystko jest w porządku, i możliwe, że masz poważny problem od wielu godzin. Ta praca z alertami może być wykonana za pomocą alertów e-mail, alertów tekstowych lub innych narzędzi, takich jak Slack.
Naprawdę trudno jest znaleźć narzędzie do monitorowania wszystkich niezbędnych metryk PostgreSQL, ogólnie rzecz biorąc, będziesz musiał użyć więcej niż jednego, a nawet trzeba będzie wykonać kilka skryptów. Jednym ze sposobów scentralizowania zadania monitorowania i alarmowania jest użycie ClusterControl, który zapewnia takie funkcje, jak zarządzanie kopiami zapasowymi, monitorowanie i ostrzeganie, wdrażanie i skalowanie, automatyczne odzyskiwanie i ważniejsze funkcje ułatwiające zarządzanie bazami danych. Wszystkie te funkcje w tym samym systemie.
Jedną z ważnych kwestii jest to, że ClusterControl działa w chmurze, On-prem, a nawet kombinacji obu. Wymagane jest tutaj posiadanie dostępu SSH do węzłów, a następnie zajmie się nimi ClusterControl.
Monitorowanie bazy danych PostgreSQL za pomocą ClusterControl
ClusterControl to system zarządzania i monitorowania, który pomaga wdrażać, zarządzać, monitorować i skalować bazy danych z przyjaznego interfejsu. Obsługuje najlepsze technologie baz danych typu open source i możesz zautomatyzować wiele zadań związanych z bazą danych, które musisz regularnie wykonywać, takich jak dodawanie i skalowanie nowych węzłów, wykonywanie kopii zapasowych i przywracanie oraz wiele innych.
ClusterControl umożliwia monitorowanie serwerów w czasie rzeczywistym za pomocą wstępnie zdefiniowanego zestawu pulpitów nawigacyjnych w celu analizowania niektórych z najczęstszych wskaźników.
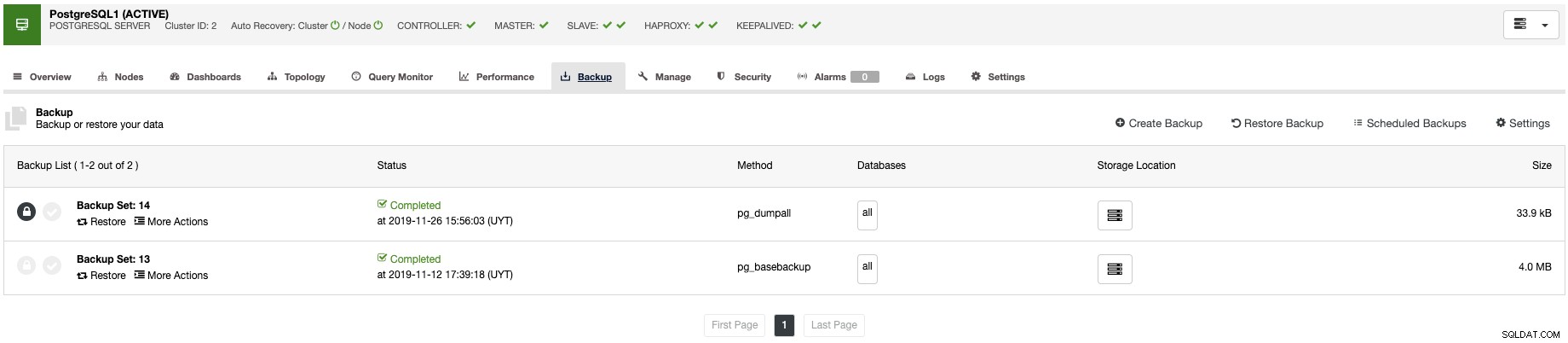
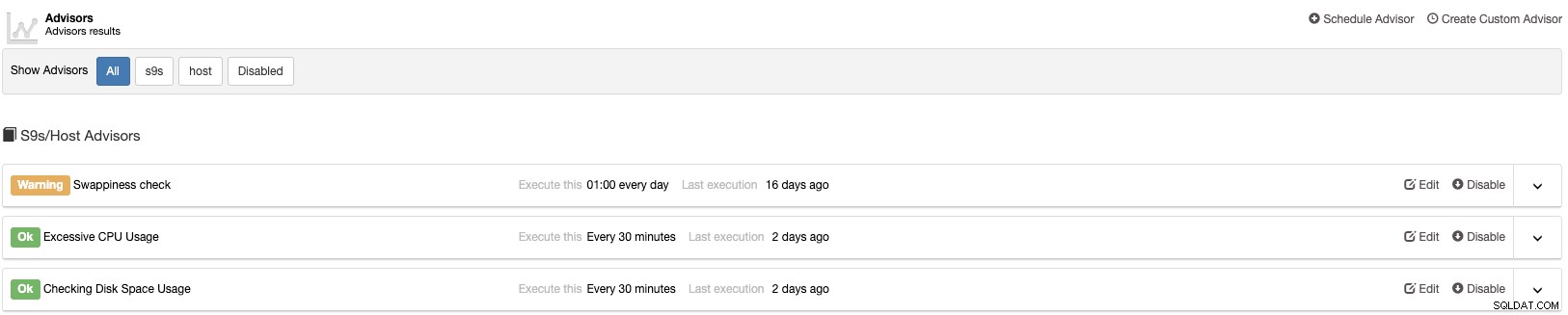
Pozwala dostosować wykresy dostępne w klastrze i włączyć monitorowanie oparte na agentach w celu generowania bardziej szczegółowych pulpitów nawigacyjnych.
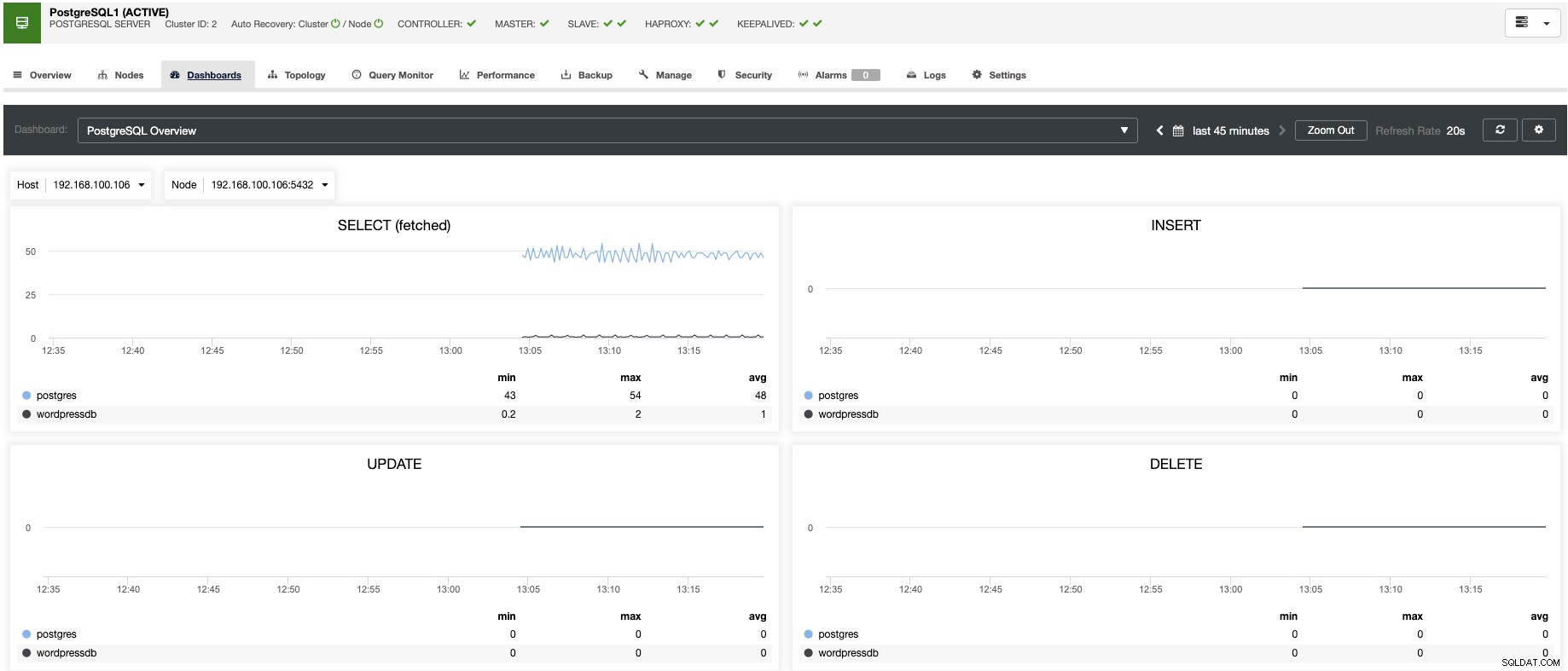
Możesz także tworzyć alerty informujące o zdarzeniach w klastrze lub integrować się z różnymi usługami, takimi jak PagerDuty lub Slack.
W sekcji monitora zapytań możesz znaleźć najpopularniejsze zapytania, uruchomione zapytania, wartości odstające zapytań oraz statystyki zapytań w celu monitorowania ruchu w bazie danych.
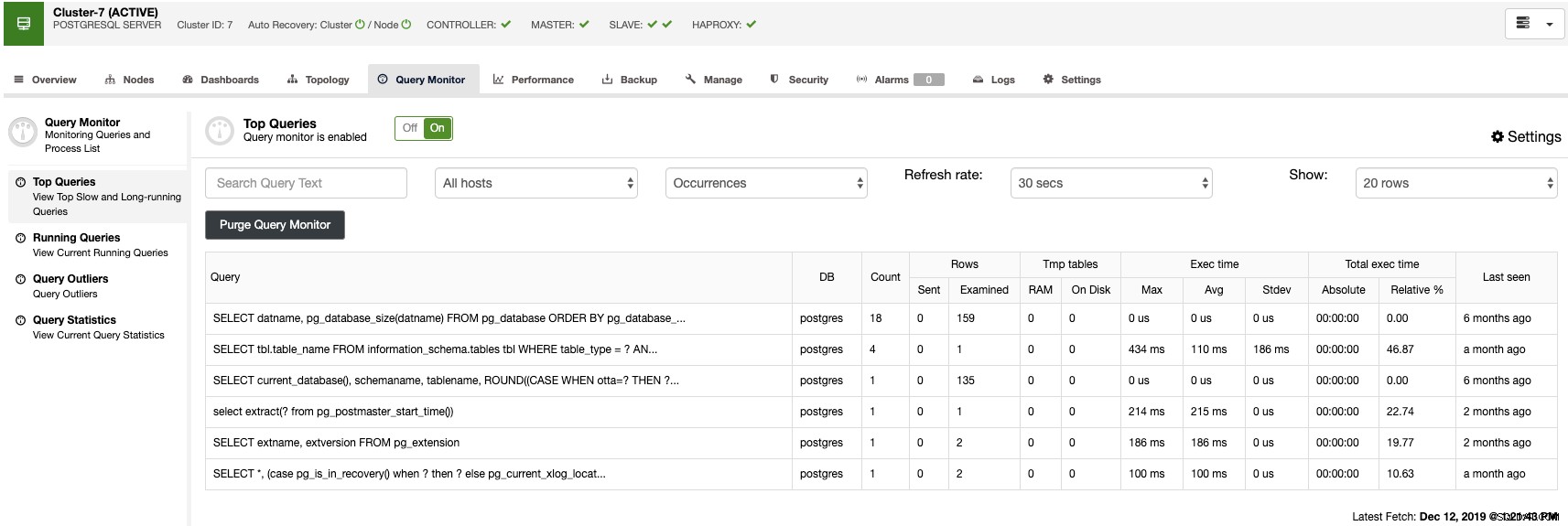
Dzięki tym funkcjom możesz zobaczyć, jak działa Twoja baza danych PostgreSQL.
W celu zarządzania kopiami zapasowymi ClusterControl centralizuje je w celu ochrony, zabezpieczenia i odzyskiwania danych, a dzięki funkcji weryfikacji kopii zapasowej możesz potwierdzić, czy kopia zapasowa jest gotowa.
To weryfikacyjne zadanie kopii zapasowej przywróci kopię zapasową na oddzielnym samodzielnym hoście, dzięki czemu możesz upewnić się, że kopia zapasowa działa.
Na koniec nie musisz uzyskiwać dostępu do węzła bazy danych, aby sprawdzić logi, możesz znaleźć wszystkie logi bazy danych scentralizowane w sekcji ClusterControl Log.
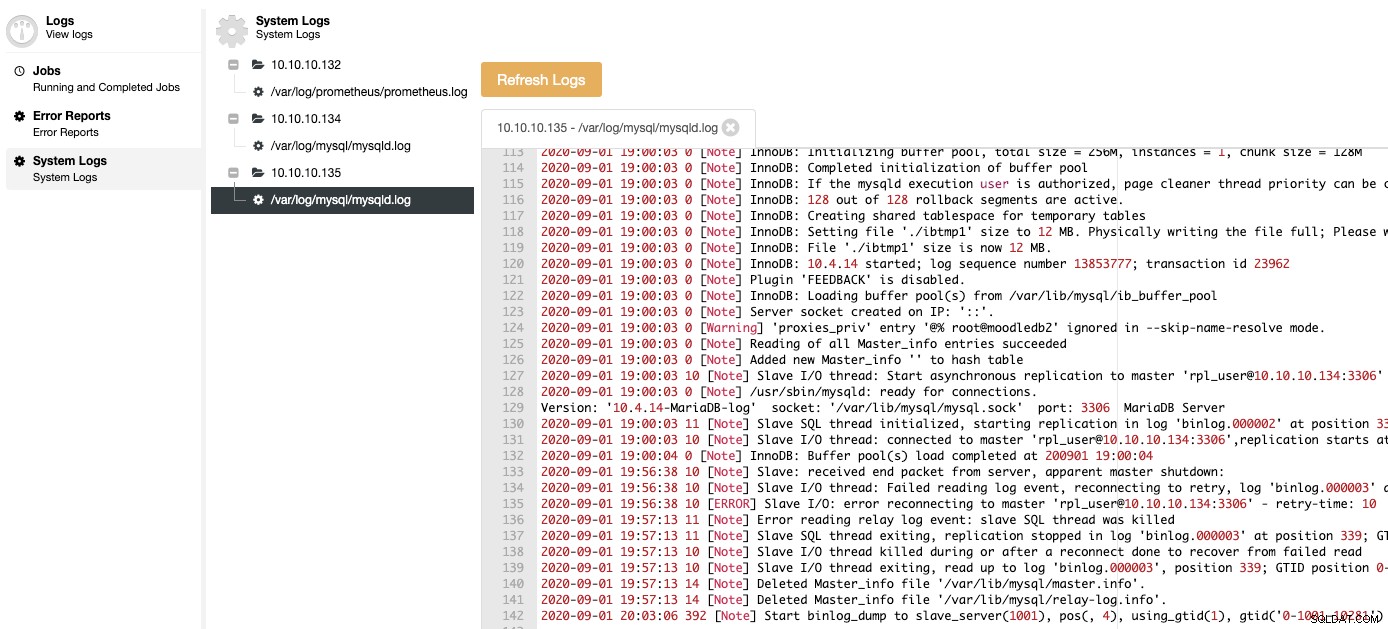
Jak widać, możesz obsługiwać wszystkie wymienione rzeczy z tego samego scentralizowanego systemu:ClusterControl.
Monitorowanie za pomocą wiersza poleceń ClusterControl
Do pisania skryptów i automatyzacji zadań, a nawet jeśli wolisz tylko wiersz poleceń, ClusterControl ma narzędzie s9s. Jest to narzędzie wiersza poleceń do zarządzania lub monitorowania klastra bazy danych.
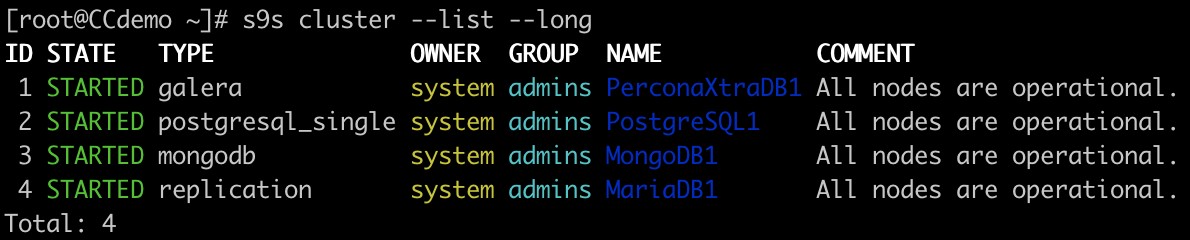
Lista klastrów
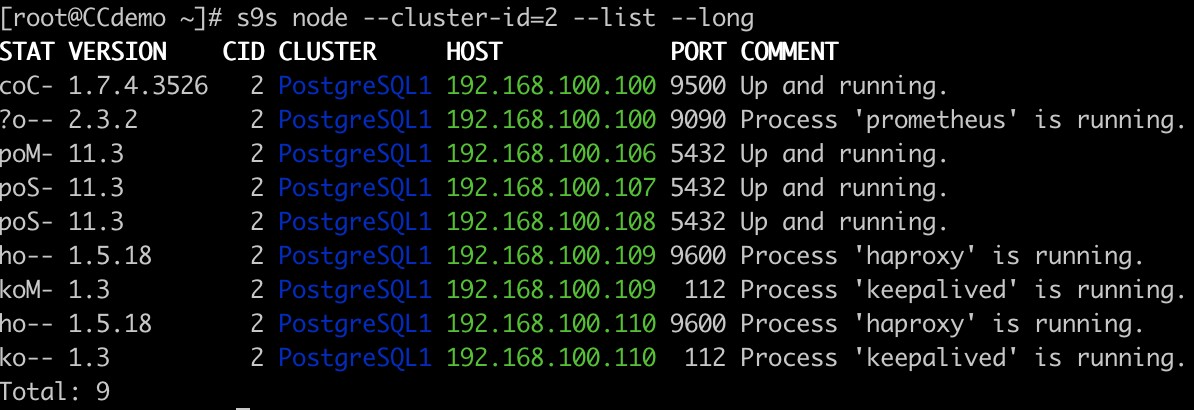
Lista węzłów
Możesz wykonywać wszystkie zadania (a nawet więcej) dostępne w interfejsie użytkownika ClusterControl i możesz zintegrować tę funkcję z niektórymi narzędziami zewnętrznymi, takimi jak slack, aby zarządzać nią z tego miejsca.
Wnioski
Jak widać, monitorowanie jest absolutnie konieczne, bez względu na to, czy działa on lokalnie, w chmurze, czy nawet na ich mieszance, a najlepszy sposób, jak to zrobić, zależy od infrastruktury i samego systemu. W tym blogu wspomnieliśmy o kilku ważnych metrykach do monitorowania w środowisku PostgreSQL, jak używać ClusterControl do wykonywania pracy.