Mysqldump to najpopularniejsze logiczne narzędzie do tworzenia kopii zapasowych dla MySQL. Jest zawarty w dystrybucji MySQL, więc jest gotowy do użycia we wszystkich instancjach MySQL.
Logiczne kopie zapasowe nie są jednak najszybszym ani najbardziej oszczędnym sposobem tworzenia kopii zapasowych baz danych MySQL, ale mają ogromną przewagę nad fizycznymi kopiami zapasowymi.
Fizyczne kopie zapasowe są zwykle kopiami zapasowymi typu wszystko albo nic. Chociaż możliwe jest utworzenie częściowej kopii zapasowej za pomocą Xtrabackup (opisaliśmy to w jednym z naszych poprzednich wpisów na blogu), przywracanie takiej kopii zapasowej jest trudne i czasochłonne.
Zasadniczo, jeśli chcemy przywrócić pojedynczą tabelę, musimy zatrzymać cały łańcuch replikacji i wykonać odzyskiwanie na wszystkich węzłach jednocześnie. To poważny problem - w dzisiejszych czasach rzadko można pozwolić sobie na zatrzymanie wszystkich baz danych.
Innym problemem jest to, że poziom tabeli jest najniższym poziomem szczegółowości, jaki można osiągnąć dzięki Xtrabackup:można przywrócić pojedynczą tabelę, ale nie można przywrócić jej części. Logiczną kopię zapasową można jednak przywrócić w taki sposób, jak uruchamiane są instrukcje SQL, dzięki czemu można ją łatwo wykonać na działającym klastrze i można (nie nazwalibyśmy tego łatwo, ale nadal) wybrać, które instrukcje SQL mają zostać uruchomione, aby móc wykonać częściowe przywrócenie tabeli.
Rzućmy okiem, jak można to zrobić w prawdziwym świecie.
Przywracanie pojedynczej tabeli MySQL za pomocą mysqldump
Na początku należy pamiętać, że częściowe kopie zapasowe nie zapewniają spójnego widoku danych. W przypadku tworzenia kopii zapasowych osobnych tabel nie można przywrócić takiej kopii zapasowej do znanej pozycji w czasie (na przykład w celu udostępnienia urządzenia podrzędnego replikacji), nawet jeśli przywrócono wszystkie dane z kopii zapasowej. Mając to za sobą, kontynuujmy.
Mamy mistrza i niewolnika:
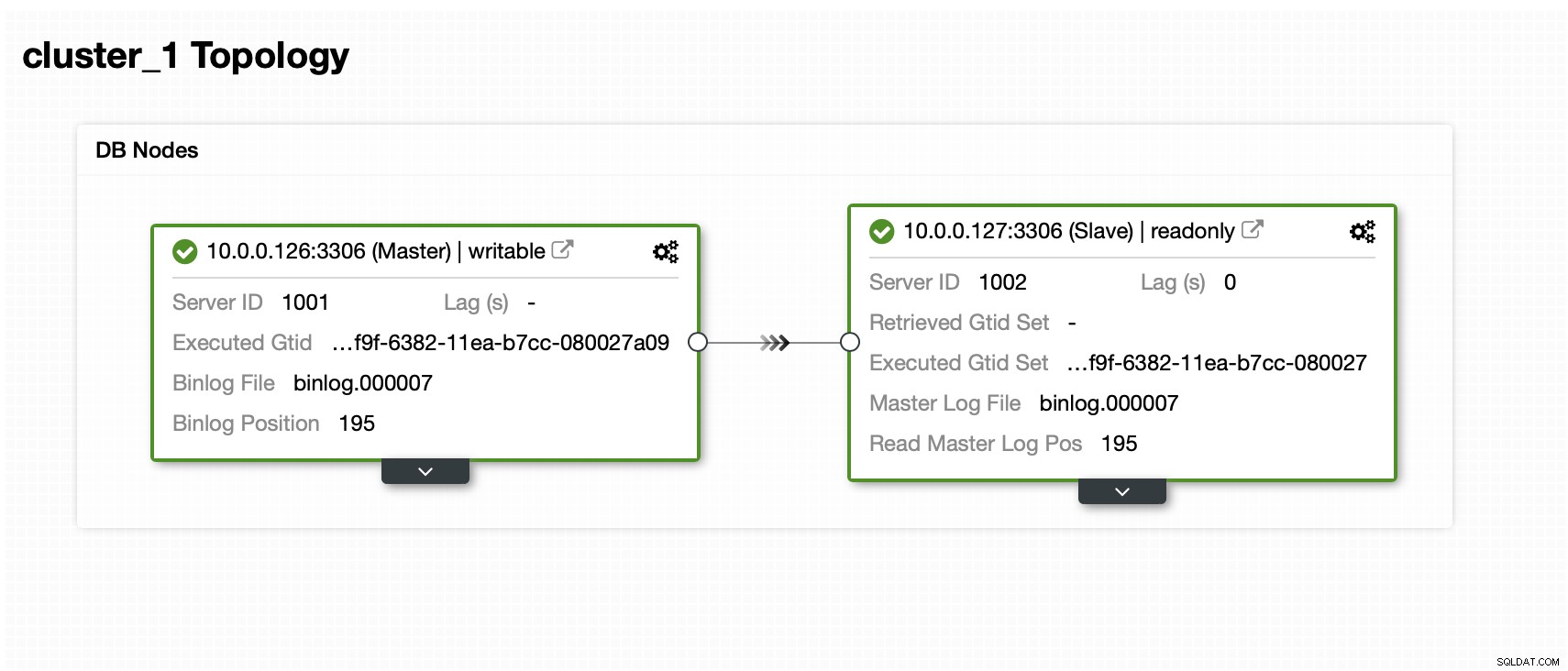
Zbiór danych zawiera jeden schemat i kilka tabel:
mysql> SHOW SCHEMAS;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sbtest |
| sys |
+--------------------+
5 rows in set (0.01 sec)
mysql> SHOW TABLES FROM sbtest;
+------------------+
| Tables_in_sbtest |
+------------------+
| sbtest1 |
| sbtest10 |
| sbtest11 |
| sbtest12 |
| sbtest13 |
| sbtest14 |
| sbtest15 |
| sbtest16 |
| sbtest17 |
| sbtest18 |
| sbtest19 |
| sbtest2 |
| sbtest20 |
| sbtest21 |
| sbtest22 |
| sbtest23 |
| sbtest24 |
| sbtest25 |
| sbtest26 |
| sbtest27 |
| sbtest28 |
| sbtest29 |
| sbtest3 |
| sbtest30 |
| sbtest31 |
| sbtest32 |
| sbtest4 |
| sbtest5 |
| sbtest6 |
| sbtest7 |
| sbtest8 |
| sbtest9 |
+------------------+
32 rows in set (0.00 sec)Teraz musimy zrobić kopię zapasową. Jest kilka sposobów, w jakie możemy podejść do tego problemu. Możemy po prostu wykonać spójną kopię zapasową całego zestawu danych, ale wygeneruje to duży, pojedynczy plik ze wszystkimi danymi. Aby przywrócić pojedynczą tabelę, musielibyśmy wyodrębnić dane dla tabeli z tego pliku. Jest to oczywiście możliwe, ale jest to dość czasochłonne i jest to w zasadzie operacja ręczna, którą można oskryptować, ale jeśli nie masz odpowiednich skryptów, pisanie kodu ad hoc, gdy twoja baza danych jest niedostępna i jesteś pod dużą presją, jest niekoniecznie najbezpieczniejszy pomysł.
Zamiast tego możemy przygotować kopię zapasową w taki sposób, że każda tabela będzie przechowywana w osobnym pliku:
example@sqldat.com:~/backup# d=$(date +%Y%m%d) ; db='sbtest'; for tab in $(mysql -uroot -ppass -h127.0.0.1 -e "SHOW TABLES FROM ${db}" | grep -v Tables_in_${db}) ; do mysqldump --set-gtid-purged=OFF --routines --events --triggers ${db} ${tab} > ${d}_${db}.${tab}.sql ; donePamiętaj, że ustawiamy --set-gtid-purged=OFF. Potrzebujemy tego, jeśli będziemy ładować te dane później do bazy danych. W przeciwnym razie MySQL spróbuje ustawić @@GLOBAL.GTID_PURGED, co najprawdopodobniej się nie powiedzie. MySQL również ustawiłby SET @@SESSION.SQL_LOG_BIN=0; co zdecydowanie nie jest tym, czego chcemy. Te ustawienia są wymagane, jeśli tworzymy spójną kopię zapasową całego zestawu danych i chcemy ją wykorzystać do udostępnienia nowego węzła. W naszym przypadku wiemy, że nie jest to spójna kopia zapasowa i nie ma możliwości, aby cokolwiek z niej odbudować. Chcemy tylko wygenerować zrzut, który możemy załadować do urządzenia głównego i pozwolić mu na replikację do urządzeń podrzędnych.
To polecenie wygenerowało ładną listę plików sql, które można przesłać do klastra produkcyjnego:
example@sqldat.com:~/backup# ls -alh
total 605M
drwxr-xr-x 2 root root 4.0K Mar 18 14:10 .
drwx------ 9 root root 4.0K Mar 18 14:08 ..
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest10.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest11.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest12.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest13.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest14.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest15.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest16.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest17.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest18.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest19.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest1.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest20.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest21.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest22.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest23.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest24.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest25.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest26.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest27.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest28.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest29.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest2.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest30.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest31.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest32.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest3.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest4.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest5.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest6.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest7.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest8.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest9.sqlGdy chcesz przywrócić dane, wystarczy załadować plik SQL do węzła głównego:
example@sqldat.com:~/backup# mysql -uroot -ppass sbtest < 20200318_sbtest.sbtest11.sqlDane zostaną załadowane do bazy danych i zreplikowane do wszystkich urządzeń podrzędnych.
Jak przywrócić pojedynczą tabelę MySQL za pomocą ClusterControl?
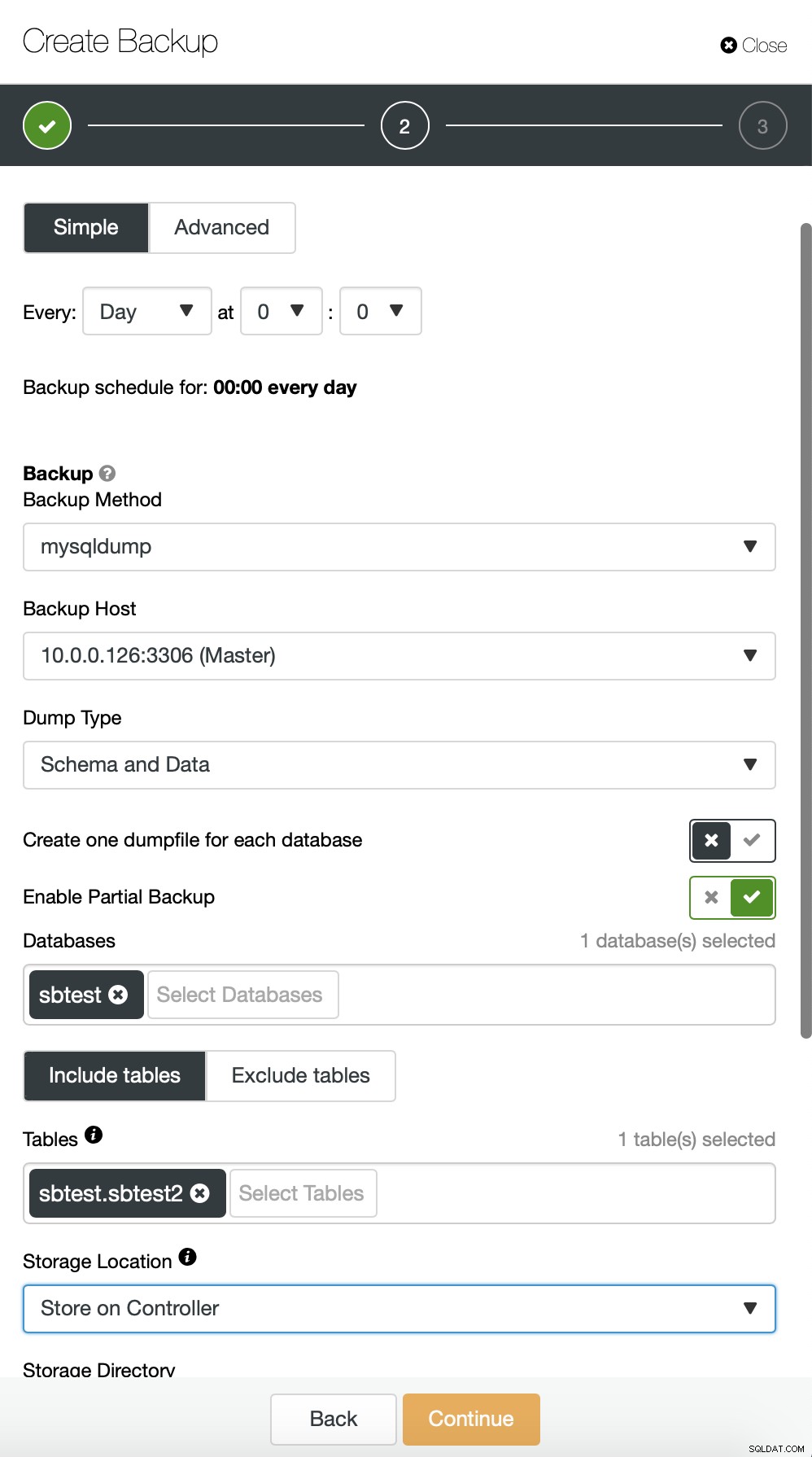
Obecnie ClusterControl nie zapewnia łatwego sposobu przywrócenia tylko jednej tabeli, ale nadal można to zrobić za pomocą kilku ręcznych działań. Istnieją dwie opcje, z których możesz skorzystać. Po pierwsze, odpowiednie dla małej liczby tabel, możesz w zasadzie stworzyć harmonogram, w którym wykonujesz częściowe kopie zapasowe oddzielnych tabel jedna po drugiej:
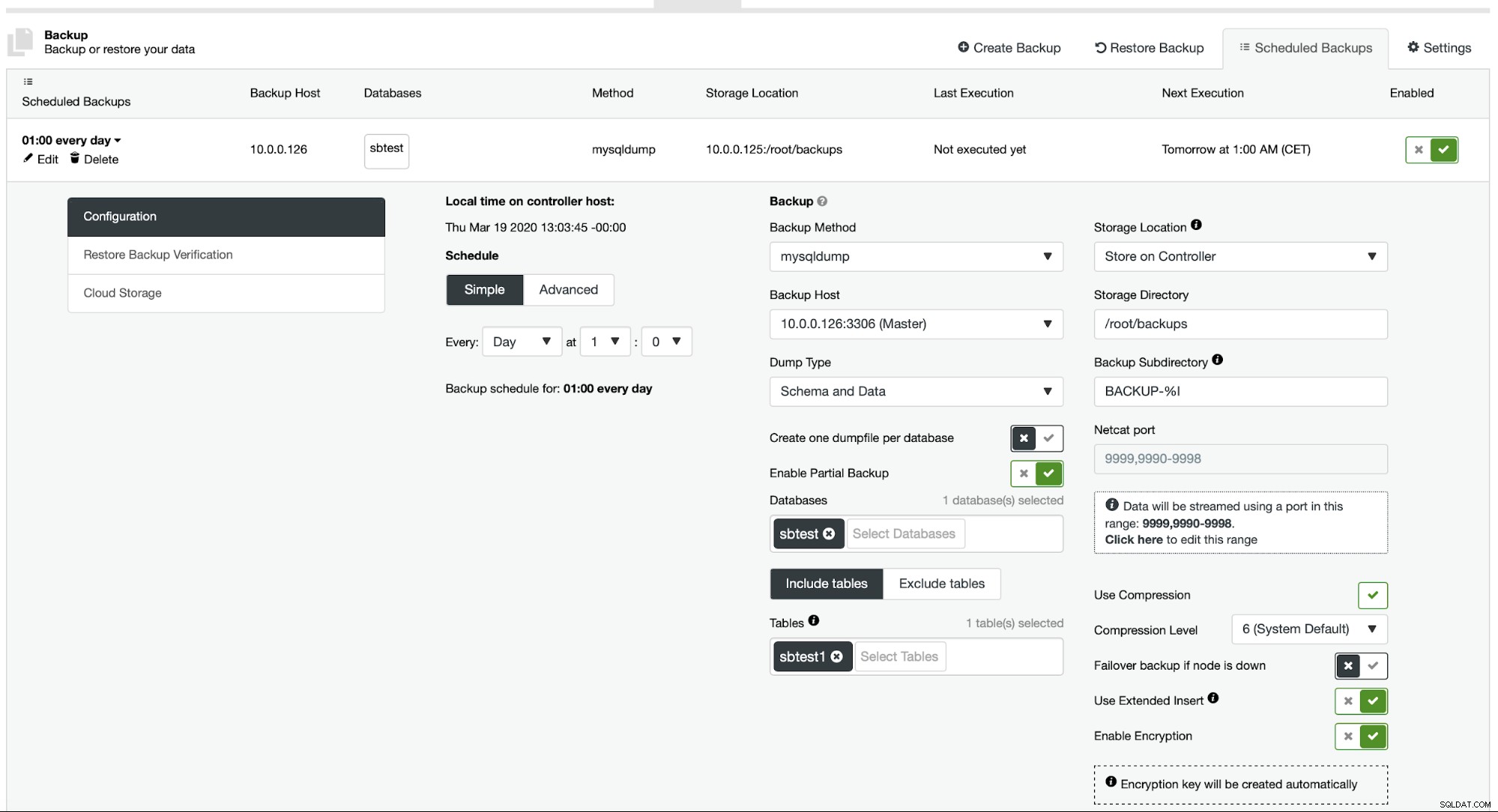
Tutaj wykonujemy kopię zapasową tabeli sbtest.sbtest1. Możemy łatwo zaplanować kolejną kopię zapasową dla tabeli sbtest2:
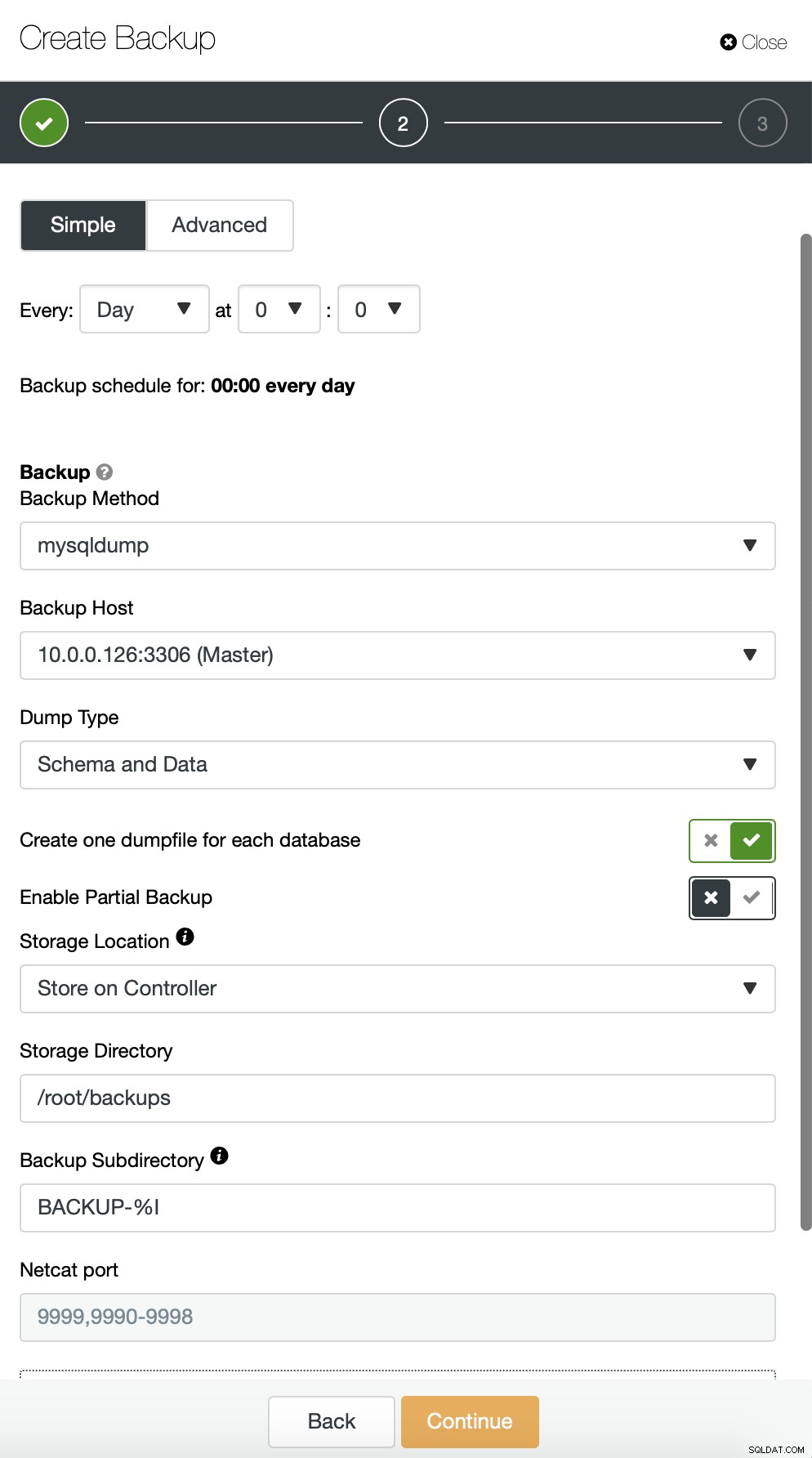
Alternatywnie możemy wykonać kopię zapasową i umieścić dane z jednego schematu w oddzielny plik:
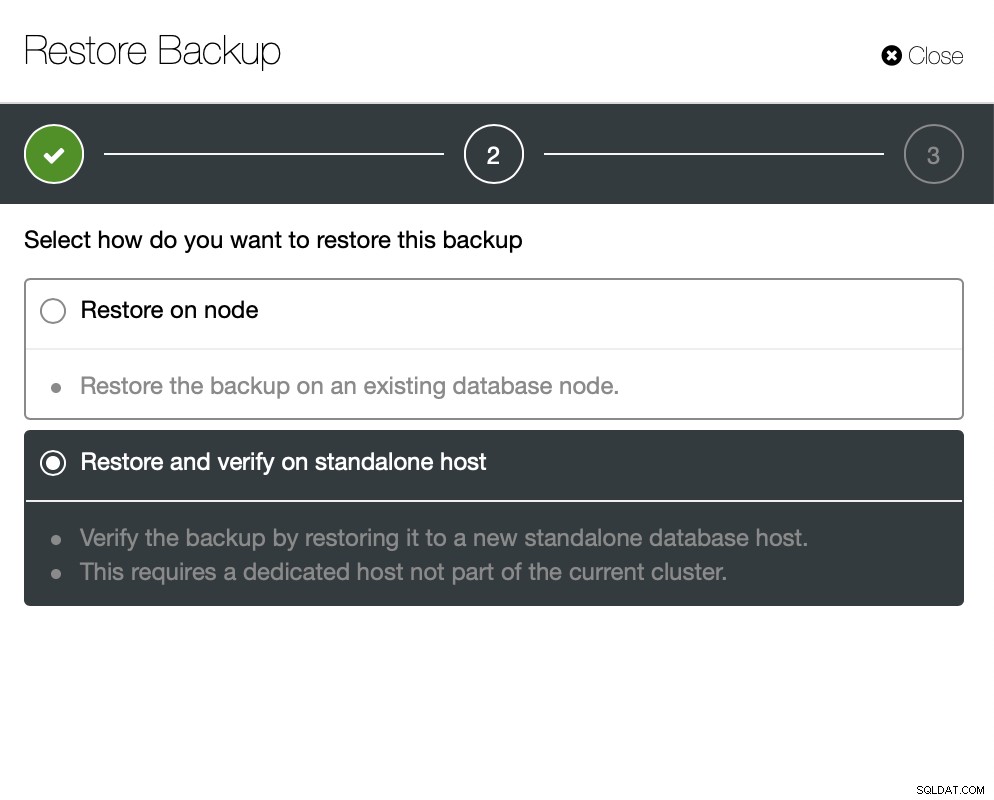
Teraz możesz znaleźć brakujące dane ręcznie w pliku, przywrócić tę kopię zapasową na oddzielny serwer lub pozwól, aby zrobił to ClusterControl:
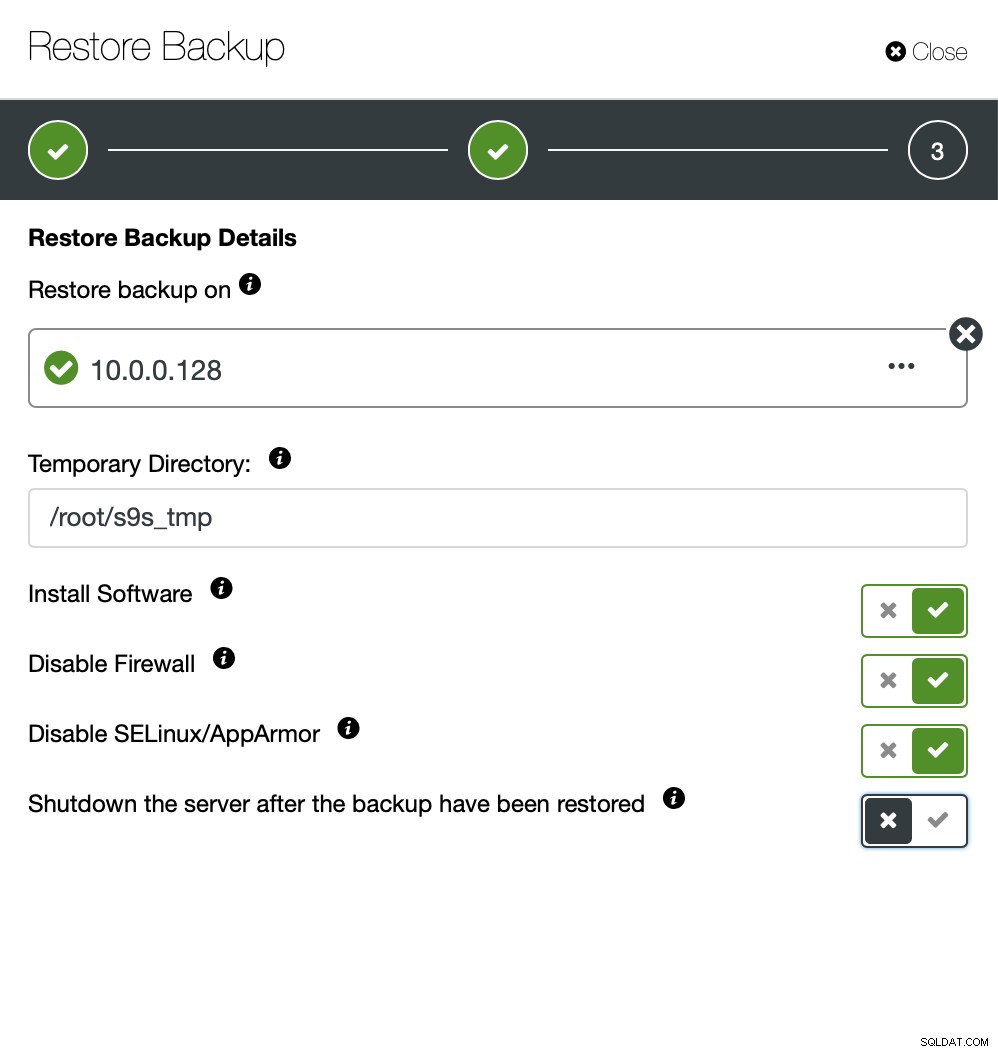
Utrzymujesz serwer w stanie gotowości i możesz wyodrębnić dane, które chciał przywrócić za pomocą mysqldump lub SELECT … INTO OUTFILE. Tak wyodrębnione dane będą gotowe do zastosowania w klastrze produkcyjnym.