Musi być dostępnych wiele potężnych narzędzi jako opcji tworzenia kopii zapasowych i przywracania dla PostgreSQL ogólnie; Barman, PgBackRest, BART to tylko kilka w tym kontekście. Naszą uwagę zwróciło to, że Barman to narzędzie, które szybko nadąża za wdrażaniem produkcji i trendami rynkowymi.
Czy to wdrożenie oparte na dokerze, potrzeba przechowywania kopii zapasowej w innej pamięci masowej w chmurze, czy wysoce konfigurowalnych potrzeb architektury odzyskiwania po awarii - Barman jest bardzo silnym rywalem we wszystkich takich przypadkach.
Ten blog bada Barmana z kilkoma założeniami dotyczącymi wdrażania, jednak w żadnym wypadku nie powinno to być uważane za tylko możliwy zestaw funkcji. Barman wykracza daleko poza to, co możemy uchwycić na tym blogu i należy go dokładniej zbadać, jeśli weźmie się pod uwagę „tworzenie kopii zapasowej i przywracanie instancji PostgreSQL”.
Założenie wdrożenia gotowego do DR
RPO=0 generalnie wiąże się z kosztami — wdrożenie synchronicznego serwera rezerwowego często by to spełniało, ale wtedy dość często wpływa to na TPS serwera podstawowego.
Podobnie jak PostgreSQL, Barman oferuje liczne opcje wdrażania, aby spełnić Twoje potrzeby, jeśli chodzi o RPO vs wydajność. Pomyśl o prostocie wdrożenia, RPO=0 lub prawie zerowym wpływie na wydajność; Barman pasuje do wszystkich.
Rozważaliśmy następujące wdrożenie, aby ustanowić rozwiązanie do odzyskiwania po awarii dla naszej architektury tworzenia kopii zapasowych i przywracania.
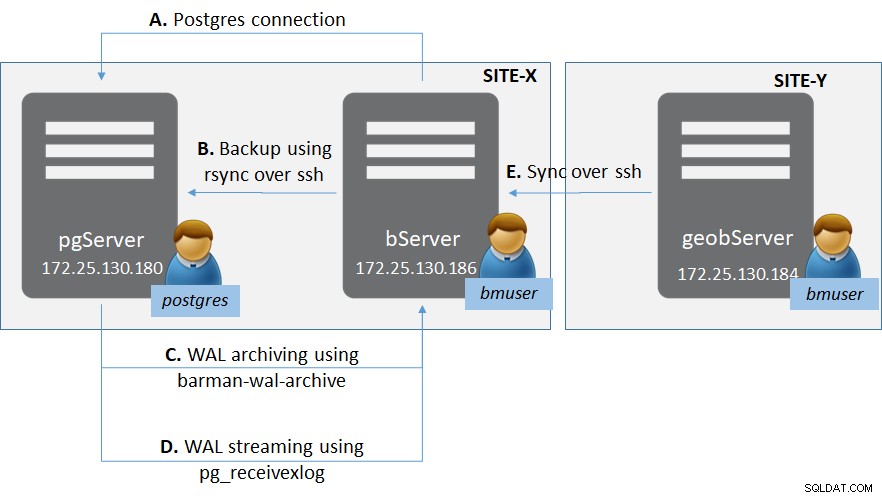 Rysunek 1:Wdrożenie PostgreSQL z Barmanem
Rysunek 1:Wdrożenie PostgreSQL z BarmanemIstnieją dwie witryny (jak ogólnie dla witryn odzyskiwania po awarii) — Site-X i Site-Y.
W Site-X jest:
- Jeden serwer „pgServer” obsługujący instancję serwera PostgreSQL pgServer i jeden użytkownik systemu operacyjnego „postgres”
- Instancja PostgreSQL również do hostowania roli superużytkownika „bmuser”
- Jeden serwer „bServer” obsługujący pliki binarne Barmana i użytkownika systemu operacyjnego „bmuser”
W Ośrodku Y znajduje się:
- Jeden serwer „geobServer” obsługujący pliki binarne Barmana i użytkownika systemu operacyjnego „bmuser”
W tej konfiguracji jest zaangażowanych wiele typów połączeń.
- Między ‘bServer’ i ‘pgServer’:
- Łączność płaszczyzny zarządzania od Barmana do instancji PostgreSQL
- połączenie rsync w celu wykonania rzeczywistej podstawowej kopii zapasowej z Barmana do instancji PostgreSQL
- Archiwizacja WAL przy użyciu barman-wal-archive z instancji PostgreSQL do Barmana
- Transmisja strumieniowa WAL przy użyciu pg_receivexlog w Barman
- Między ‘bServer’ i ‘geobserver’:
- Synchronizacja między serwerami Barman w celu zapewnienia replikacji geograficznej
Najpierw łączność
Podstawowe potrzeby łączności między serwerami to ssh. Aby to zrobić, używane są bezhasłowe klucze ssh. Ustalmy klucze ssh i wymieńmy je.
Na pgServer:
example@sqldat.com$ ssh-keygen -q -t rsa -N '' -f ~/.ssh/id_rsa <<<y 2>&1 >/dev/null
example@sqldat.com$ ssh-copy-id -i ~/.ssh/id_rsa.pub example@sqldat.com
example@sqldat.com$ ssh example@sqldat.com "chmod 600 ~/.ssh/authorized_keys"Na bServer:
example@sqldat.com$ ssh-keygen -q -t rsa -N '' -f ~/.ssh/id_rsa <<<y 2>&1 >/dev/null
example@sqldat.com$ ssh-copy-id -i ~/.ssh/id_rsa.pub example@sqldat.com
example@sqldat.com$ ssh example@sqldat.com "chmod 600 ~/.ssh/authorized_keys"Na geobServer:
example@sqldat.com$ ssh-keygen -q -t rsa -N '' -f ~/.ssh/id_rsa <<<y 2>&1 >/dev/null
example@sqldat.com$ ssh-copy-id -i ~/.ssh/id_rsa.pub example@sqldat.com
example@sqldat.com$ ssh example@sqldat.com "chmod 600 ~/.ssh/authorized_keys"Konfiguracja instancji PostgreSQL
Istnieją dwie główne rzeczy, których potrzebujemy, aby odtworzyć instancję postgres - katalog podstawowy i wygenerowane później logi WAL / Transactions. Serwer Barman inteligentnie je śledzi. To, czego potrzebujemy, to zapewnienie generowania odpowiednich pasz, aby Barman mógł zebrać te artefakty.
Dodaj następujące wiersze do postgresql.conf:
listen_addresses = '172.25.130.180' #as per above deployment assumption
wal_level = replica #or higher
archive_mode = on
archive_command = 'barman-wal-archive -U bmuser bserver pgserver %p'Polecenie Archive zapewnia, że gdy WAL ma być zarchiwizowany przez instancję postgres, narzędzie barman-wal-archive prześle go do serwera Barman. Należy zauważyć, że pakiet barman-cli powinien zostać udostępniony na „pgServer”. Istnieje inna opcja korzystania z rsync, jeśli nie chcemy korzystać z narzędzia barman-wal-archive.
Dodaj następujące do pg_hba.conf:
host all all 172.25.130.186/32 md5
host replication all 172.25.130.186/32 md5W zasadzie pozwala na replikację i normalne połączenie z „bmserver” do tej instancji postgres.
Teraz po prostu uruchom ponownie instancję i utwórz rolę superużytkownika o nazwie bmuser:
example@sqldat.com$ pg_ctl restart
example@sqldat.com$ createuser -s -P bmuser W razie potrzeby możemy uniknąć używania bmuser jako superużytkownika; wymagałoby to uprawnień przypisanych do tego użytkownika. W powyższym przykładzie użyliśmy również bmuser jako hasła. Ale to prawie wszystko, o ile wymagana jest konfiguracja instancji PostgreSQL.
Konfiguracja barmana
Barman ma w swojej konfiguracji trzy podstawowe komponenty:
- Konfiguracja globalna
- Konfiguracja na poziomie serwera
- Użytkownik, który będzie prowadził barmana
W naszym przypadku, ponieważ Barman jest instalowany przy użyciu rpm, nasze globalne pliki konfiguracyjne są przechowywane pod adresem:
/etc/barman.confChcieliśmy przechowywać konfigurację na poziomie serwera w katalogu domowym bmuser, stąd nasz globalny plik konfiguracyjny miał następującą zawartość:
[barman]
barman_user = bmuser
configuration_files_directory = /home/bmuser/barman.d
barman_home = /home/bmuser
barman_lock_directory = /home/bmuser/run
log_file = /home/bmuser/barman.log
log_level = INFOKonfiguracja podstawowego serwera Barmana
W powyższym wdrożeniu zdecydowaliśmy się utrzymać główny serwer Barmana w tym samym centrum danych/lokalu, w którym przechowywana jest instancja PostgreSQL. Zaletą tego samego jest to, że w razie potrzeby występuje mniejsze opóźnienie i szybsze odzyskiwanie. Nie trzeba dodawać, że serwer PostgreSQL wymaga mniej mocy obliczeniowej i/lub przepustowości sieci.
W celu umożliwienia Barmanowi zarządzania instancją PostgreSQL na pgServer, musimy dodać plik konfiguracyjny (nazwaliśmy pgserver.conf) o następującej treści:
[pgserver]
description = "Example pgserver configuration"
ssh_command = ssh example@sqldat.com
conninfo = host=pgserver user=bmuser dbname=postgres
backup_method = rsync
reuse_backup = link
backup_options = concurrent_backup
parallel_jobs = 2
archiver = on
archiver_batch_size = 50
path_prefix = "/usr/pgsql-12/bin"
streaming_conninfo = host=pgserver user=bmuser dbname=postgres
streaming_archiver=on
create_slot = autoI plik .pgpass zawierający dane uwierzytelniające dla bmuser w instancji PostgreSQL:
echo 'pgserver:5432:*:bmuser:bmuser' > ~/.pgpass Aby lepiej zrozumieć ważne elementy konfiguracji:
- ssh_command :Używany do ustanowienia połączenia, przez które będzie wykonywany rsync
- conninfo :Ciąg połączenia umożliwiający Barmanowi nawiązanie połączenia z serwerem postgres
- reuse_backup :aby umożliwić tworzenie przyrostowych kopii zapasowych przy mniejszej ilości miejsca
- metoda_backup_ :metoda wykonania kopii zapasowej katalogu podstawowego
- prefiks_ścieżki :lokalizacja, w której przechowywane są pliki binarne pg_receivexlog
- streaming_conninfo :Parametry połączenia używane do przesyłania strumieniowego WAL
- create_slot :aby upewnić się, że sloty zostały utworzone przez instancję postgres
Pasywna konfiguracja serwera Barmana
Konfiguracja witryny replikacji geograficznej jest dość prosta. Wszystko, czego potrzebuje, to informacje o połączeniu ssh, przez które ta strona z pasywnym węzłem będzie przeprowadzać replikację.
Ciekawe jest to, że taki pasywny węzeł może pracować w trybie mieszanym; innymi słowy - mogą działać jako aktywne serwery Barmana do tworzenia kopii zapasowych dla witryn PostgreSQL i równolegle działać jako witryna replikacji/kaskadowa dla innych serwerów Barmana.
Ponieważ w naszym przypadku ta instancja Barmana (w Site-Y) musi być tylko węzłem pasywnym, wystarczy utworzyć plik /home/bmuser/barman.d/pgserver.conf z następującą konfiguracją:
[pgserver]
description = "Geo-replication or sync for pgserver"
primary_ssh_command = ssh example@sqldat.comPrzy założeniu, że klucze zostały wymienione, a globalna konfiguracja w tym węźle została wykonana tak, jak wspomniano wcześniej - jesteśmy prawie skończeni z konfiguracją.
Oto nasza pierwsza kopia zapasowa i przywracanie
Na bserverze upewnij się, że proces w tle odbierania WAL został uruchomiony; a następnie sprawdź konfigurację serwera:
example@sqldat.com$ barman cron
example@sqldat.com$ barman check pgserverWeryfikacja powinna być OK dla wszystkich podetapów. Jeśli nie, przejdź do /home/bmuser/barman.log.
Wydaj polecenie tworzenia kopii zapasowej na Barmanie, aby upewnić się, że istnieją podstawowe DANE, na których można zastosować WAL:
example@sqldat.com$ barman backup pgserverNa „geobmserver” upewnij się, że replikacja jest wykonywana, wykonując następujące polecenia:
example@sqldat.com$ barman cron
example@sqldat.com$ barman list-backup pgserverCron powinien zostać wstawiony do pliku crontab (jeśli go nie ma). Dla uproszczenia nie pokazałem tego tutaj. Ostatnie polecenie pokaże, że folder kopii zapasowej został również utworzony na serwerze geobmserver.
Teraz w instancji Postgres utwórzmy kilka fikcyjnych danych:
example@sqldat.com$ psql -U postgres -c "CREATE TABLE dummy_data( i INTEGER);"
example@sqldat.com$ psql -U postgres -c "insert into dummy_data values ( generate_series (1, 1000000 ));"Replikację WAL z instancji PostgreSQL można zobaczyć za pomocą poniższego polecenia:
example@sqldat.com$ psql -U postgres -c "SELECT * from pg_stat_replication ;”W celu odtworzenia instancji w Site-Y, najpierw upewnij się, że rekordy WAL są przełączane. lub w tym przykładzie, aby utworzyć czyste odzyskiwanie:
example@sqldat.com$ barman switch-xlog --force --archive pgserverW Site-X uruchommy samodzielną instancję PostgreSQL, aby sprawdzić, czy kopia zapasowa jest rozsądna:
example@sqldat.com$ barman cron
barman recover --get-wal pgserver latest /tmp/dataTeraz edytuj pliki postgresql.conf i postgresql.auto.conf zgodnie z potrzebami. Poniżej wyjaśnij zmiany wprowadzone w tym przykładzie:
- postgresql.conf :listen_addresses skomentowane tak, aby domyślnie było to localhost
- postgresql.auto.conf :usunięto sudo bmuser z polecenia restore_command
Wybierz te DANE w /tmp/data i sprawdź istnienie swoich rekordów.
Wnioski
To był tylko wierzchołek góry lodowej. Barman jest znacznie głębszy ze względu na funkcjonalność, jaką zapewnia - m.in. działając jako zsynchronizowany tryb gotowości, skrypty przechwytujące i tak dalej. Nie trzeba dodawać, że należy zbadać całą dokumentację, aby skonfigurować ją zgodnie z potrzebami środowiska produkcyjnego.



