Przez ostatnie kilka miesięcy w 2ndQuadrant pracowaliśmy nad połączeniem PostgreSQL 9.6 z Postgres-XL, co z różnych powodów okazało się dość trudne i zajęło więcej czasu niż początkowo planowaliśmy ze względu na kilka inwazyjnych zmian. Jeśli jesteś zainteresowany, spójrz na oficjalne repozytorium tutaj (na razie spójrz na gałąź „master”).
Jest jeszcze sporo pracy do wykonania – scalanie kilku pozostałych bitów z upstreamu, naprawianie znanych błędów i niepowodzeń regresji, testowanie itp. Jeśli rozważasz przyczynienie się do Postgres-XL, jest to idealna okazja (wyślij mi e-mail, a pomogę Ci w pierwszych krokach).
Ale ogólnie rzecz biorąc, Postgres-XL 9.6 jest wyraźnie dużym krokiem naprzód w wielu ważnych obszarach.
Nowe funkcje w Postgres-XL 9.6
Jakie nowe funkcje zyskuje Postgres-XL dzięki połączeniu PostgreSQL 9.6? Mógłbym po prostu wskazać Ci informacje o wydaniu autorów — większość ulepszeń dotyczy bezpośrednio XL 9.6, z wyjątkiem tych związanych z funkcjami nieobsługiwanymi w XL.
Głównym ulepszeniem widocznym dla użytkownika w PostgreSQL 9.6 było wyraźnie równoległe zapytania, i dotyczy to również Postgres-XL 9.6.
Równoległość między węzłami
Przed PostgreSQL 9.6, Postgres-XL był jednym ze sposobów na uzyskanie równoległych zapytań (poprzez umieszczenie wielu węzłów Postgres-XL na tej samej maszynie). Od PostgreSQL 9.6 nie jest to już potrzebne, ale oznacza to również, że Postgres-XL zyskuje możliwość paralelizmu wewnątrzwęzłowego.
Dla porównania, Postgres-XL 9.5 pozwolił na to – dystrybucję zapytania do wielu węzłów danych, ale każdy węzeł danych nadal podlegał ograniczeniu „jeden backend na zapytanie”, tak jak zwykły PostgreSQL.
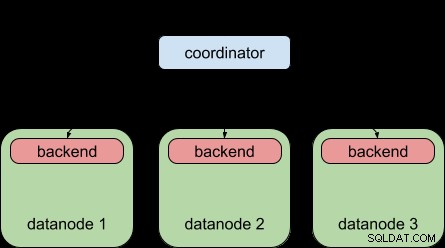
Dzięki funkcji zapytań równoległych PostgreSQL 9.6, Postgres-XL 9.6 może teraz to zrobić:
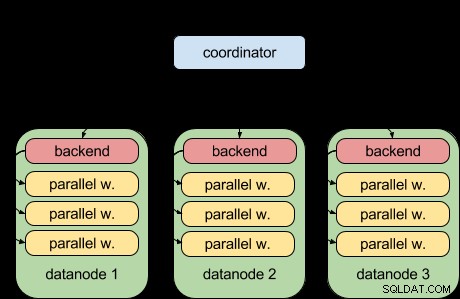
Oznacza to, że każdy węzeł danych może teraz równolegle uruchamiać swoją część zapytania, korzystając z nadrzędnej infrastruktury zapytań równoległych. To świetnie i sprawia, że Postgres-XL jest znacznie bardziej wydajny, jeśli chodzi o obciążenia analityczne.
Konserwacja widelca
Wspomniałem, że to połączenie okazało się trudniejsze, niż początkowo zakładaliśmy, z wielu powodów.
Po pierwsze, ogólne utrzymanie forków jest trudne, szczególnie gdy projekt nadrzędny porusza się tak szybko, jak PostgreSQL. Musisz opracować funkcje specyficzne dla twojego widelca, dlatego właśnie widelce istnieją. Ale chcesz też nadążyć za prądem, w przeciwnym razie zostaniesz beznadziejnie w tyle. Dlatego niektóre z istniejących forków nadal tkwią w PostgreSQL 8.x, brakuje im wszystkich gadżetów wprowadzonych od tego czasu.
Po drugie, scalenie zostało zrobione w jednej dużej bryle, tak jak wszystkie poprzednie (9,5, 9,2, …). Oznacza to, że wszystkie wcześniejsze zatwierdzenia zostały scalone w jednym poleceniu scalania git. To jest całkiem gwarantowane, że spowoduje wiele konfliktów podczas łączenia, do tego stopnia, że kod nawet się nie skompiluje, nie wspominając o uruchamianiu testów regresji lub czegoś w tym rodzaju.
Tak więc pierwsza partia poprawek polega na doprowadzeniu go do stanu możliwego do kompilacji, następna polega na doprowadzeniu go do rzeczywistego działania bez natychmiastowych błędów segfault, a na końcu rozpoczyna się „zwykłe” naprawianie (przeprowadzanie testów regresji, rozwiązywanie problemów, płukanie i powtarzanie) .
Te złożoności są nieodłącznie związane z konserwacją forka (i jest to powód, dla którego prawdopodobnie powinieneś ponownie rozważyć uruchomienie kolejnego forka i zamiast tego przyczynić się bezpośrednio do Postgresa i/lub Postgresa-XL).
Są jednak sposoby na znaczne zmniejszenie tego wpływu – na przykład planujemy przeprowadzić kolejne scalanie (z PostgreSQL 10) w mniejszych porcjach. Powinno to zminimalizować zakres konfliktów scalania i pozwolić nam znacznie szybciej rozwiązywać awarie.
Bliżej PostgreSQL
Co ciekawe, przyjęcie paralelizmu z wcześniejszych źródeł pozwoliło nam również pozbyć się dużej ilości kodu z bazy kodu XL – najlepszym tego przykładem jest równoległy kod agregujący, który z łatwością zastąpił kod specyficzny dla XL.
Innym przykładem zmiany w fazie początkowej, która znacząco wpłynęła na kod XL, jest „patyfikacja” wyższego planisty, wprowadzona pod koniec cyklu rozwojowego wersji 9.6. Okazało się to bardzo inwazyjną zmianą (w rzeczywistości prawdopodobnie jest z nią związanych wiele otwartych błędów), ale ostatecznie pozwoliło nam uprościć kod planowania (zasadniczo konstruować właściwe ścieżki zamiast poprawiać wynikowy plan).
Kiedy mówię, że połączenie pozwoliło nam uprościć kod XL i zbliżyć go do PostgreSQL, co mam przez to na myśli? Najprostszym sposobem ilościowego określenia zmiany jest wykonanie „git diff –stat” względem pasującej gałęzi upstream i porównanie liczb. Dla gałęzi 9.5 i 9.6 wyniki wyglądają tak:
| wersja | pliki zmienione | dodatki | usunięcie |
|---|---|---|---|
| XL 9,5 | 1099 | 234509 | 18336 |
| XL 9,6 | 1051 | 201158 | 17627 |
| delta | -48 (-4,3%) | -33351 (-14,2%) | -709 (-3,8%) |
Najwyraźniej scalenie 9.6 znacznie zmniejsza deltę w stosunku do upstream (łącznie o ~14%). Skąd bierze się ta różnica?
Po pierwsze, część tej redukcji wynika z rzeczywistego uproszczenia kodu. Najlepszym tego przykładem jest agregacja równoległa, która jest w zasadzie zamiennikiem 1:1 oryginalnej implementacji Postgres-XL. Więc po prostu to usunęliśmy i zamiast tego używamy implementacji nadrzędnej. Mamy nadzieję znaleźć więcej takich miejsc w przyszłości i wykorzystać implementację upstream zamiast utrzymywać własne.
Po drugie, znaczna redukcja wynika z usunięcia martwego kodu. Nie tylko zredukowaliśmy niektóre martwe/nieosiągalne fragmenty kodu, ale także odkryliśmy sporo plików źródłowych, które nie zostały nawet skompilowane i tak dalej.
Co dalej?
W tym momencie połączyliśmy zmiany aż do b5bce6c1, czyli miejsca, w którym PostgreSQL 9.6 oddzielił się od mastera. Aby więc dogonić PostgreSQL 9.6.2, musimy scalić pozostałe zmiany w gałęzi 9.6. Biorąc pod uwagę, że powinny to być w większości tylko poprawki błędów, co powinno być (mam nadzieję) dość prostą pracą w porównaniu z pełnym scaleniem.
Oczywiście będą błędy. W rzeczywistości w tym momencie wciąż jest kilka nieudanych testów regresji. Należy to naprawić przed oficjalnym wydaniem XL 9.6. Musimy przeprowadzić więcej testów, więc jeśli jesteś zainteresowany pomocą Postgres-XL, będzie to niezwykle korzystne.
Jeden problem, o którym ciągle słyszymy, to paczki lub ich brak. Być może zauważyłeś, że ostatnie dostępne pakiety są dość stare i jest tylko .rpm, nic więcej. Planujemy rozwiązać ten problem i zacząć oferować aktualne pakiety w wielu smakach (np. .rpm i .deb).
Planujemy również wprowadzić pewne zmiany w organizacji procesu rozwoju, aby ułatwić wnoszenie wkładu i uczestniczenie w procesie rozwoju. To naprawdę osobny temat niezwiązany z gałęzią 9.6, więc więcej szczegółów na ten temat opublikuję za kilka dni.