Myślę, że to błąd Pg.
Moim zdaniem PostgreSQL powinien normalizować utf-8 do postaci wstępnie skomponowanej przed wykonaniem konwersji kodowania. Przedstawione wyniki konwersji są nieprawidłowe.
Podniosę to na pgsql-bugs ... gotowe.
https://www.postgresql.org/identyfikator-wiadomości/przykład @sqldat.com
Powinieneś być w stanie śledzić tam wątek.
Edytuj :pgsql-hackers najwyraźniej się nie zgadzają, więc jest mało prawdopodobne, by zmieniło się to w pośpiechu. Zdecydowanie radzę znormalizować kod UTF-8 na granicach wejściowych aplikacji.
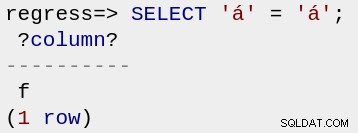
BTW, można to uprościć do:
regress=> SELECT 'á' = 'á';
?column?
----------
f
(1 row)
co jest zwykłym szaleństwem, ale jest dozwolone. Pierwsza jest z góry skomponowana, druga nie. (Aby zobaczyć ten wynik, musisz skopiować i wkleić, a to zadziała tylko wtedy, gdy Twoja przeglądarka lub terminal nie znormalizują utf-8).
Jeśli używasz Firefoksa, możesz nie widzieć poprawnie powyższego; Chrome renderuje to poprawnie. Oto, co powinieneś zobaczyć, jeśli Twoja przeglądarka poprawnie obsługuje rozłożony kod Unicode: