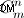Policz wszystkie wiersze
SELECT date, '1_D' AS time_series, count(DISTINCT user_id) AS cnt
FROM uniques
GROUP BY 1
UNION ALL
SELECT DISTINCT ON (1)
date, '2_W', count(*) OVER (PARTITION BY week_beg ORDER BY date)
FROM uniques
UNION ALL
SELECT DISTINCT ON (1)
date, '3_M', count(*) OVER (PARTITION BY month_beg ORDER BY date)
FROM uniques
ORDER BY 1, time_series
-
Twoje kolumny
week_begimonth_begsą w 100% nadmiarowe i można je łatwo zastąpićdate_trunc('week', date + 1) - 1idate_trunc('month', date)odpowiednio. -
Wydaje się, że Twój tydzień zaczyna się w niedzielę (przerwa o jeden), dlatego
+ 1 .. - 1. -
domyślna ramka funkcji okna z
ORDER BYwOVERklauzula używa toRANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW. Właśnie tego potrzebujesz. -
Użyj
UNION ALL, a nieUNION. -
Twój niefortunny wybór dla
time_series(D, W, M) nie sortuje dobrze, zmieniłem nazwę, aby wykonać ostateczneORDER BYłatwiej. -
To zapytanie może dotyczyć wielu wierszy dziennie. Liczby obejmują wszystkich rówieśników na dzień.
-
Więcej o
DISTINCT ON:
DISTINCT użytkowników dziennie
Aby policzyć każdego użytkownika tylko raz dziennie, użyj CTE z DISTINCT ON :
WITH x AS (SELECT DISTINCT ON (1,2) date, user_id FROM uniques)
SELECT date, '1_D' AS time_series, count(user_id) AS cnt
FROM x
GROUP BY 1
UNION ALL
SELECT DISTINCT ON (1)
date, '2_W'
,count(*) OVER (PARTITION BY (date_trunc('week', date + 1)::date - 1)
ORDER BY date)
FROM x
UNION ALL
SELECT DISTINCT ON (1)
date, '3_M'
,count(*) OVER (PARTITION BY date_trunc('month', date) ORDER BY date)
FROM x
ORDER BY 1, 2
DISTINCT użytkownicy w dynamicznym okresie
Zawsze możesz skorzystać z skorelowanych podzapytań . Z dużymi tabelami zwykle działa wolno!
Budowanie na poprzednich zapytaniach:
WITH du AS (SELECT date, user_id FROM uniques GROUP BY 1,2)
,d AS (
SELECT date
,(date_trunc('week', date + 1)::date - 1) AS week_beg
,date_trunc('month', date)::date AS month_beg
FROM uniques
GROUP BY 1
)
SELECT date, '1_D' AS time_series, count(user_id) AS cnt
FROM du
GROUP BY 1
UNION ALL
SELECT date, '2_W', (SELECT count(DISTINCT user_id) FROM du
WHERE du.date BETWEEN d.week_beg AND d.date )
FROM d
GROUP BY date, week_beg
UNION ALL
SELECT date, '3_M', (SELECT count(DISTINCT user_id) FROM du
WHERE du.date BETWEEN d.month_beg AND d.date)
FROM d
GROUP BY date, month_beg
ORDER BY 1,2;
Skrzypce SQL dla wszystkich trzech rozwiązań.
Szybciej dzięki dense_rank()
@Clodoaldo
wymyśliłem znaczną poprawę:użyj funkcji okna dense_rank()
. Oto kolejny pomysł na zoptymalizowaną wersję. Od razu wykluczenie codziennych duplikatów powinno być jeszcze szybsze. Wzrost wydajności rośnie wraz z liczbą wierszy dziennie.
Opierając się na uproszczonym i oczyszczonym modelu danych - bez zbędnych kolumn - day jako nazwę kolumny zamiast date
date to zastrzeżone słowo w standardowym SQL
i podstawowa nazwa typu w PostgreSQL i nie powinna być używana jako identyfikator.
CREATE TABLE uniques(
day date -- instead of "date"
,user_id int
);
Ulepszone zapytanie:
WITH du AS (
SELECT DISTINCT ON (1, 2)
day, user_id
,date_trunc('week', day + 1)::date - 1 AS week_beg
,date_trunc('month', day)::date AS month_beg
FROM uniques
)
SELECT day, count(user_id) AS d, max(w) AS w, max(m) AS m
FROM (
SELECT user_id, day
,dense_rank() OVER(PARTITION BY week_beg ORDER BY user_id) AS w
,dense_rank() OVER(PARTITION BY month_beg ORDER BY user_id) AS m
FROM du
) s
GROUP BY day
ORDER BY day;
Skrzypce SQL
demonstrowanie wydajności 4 szybszych wariantów. Zależy to od Twojej dystrybucji danych, która jest dla Ciebie najszybsza.
Wszystkie są około 10 razy szybsze niż wersja skorelowanych podzapytań (co nie jest złe w przypadku skorelowanych podzapytań).