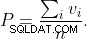To wydaje się być nieporozumieniem.
Twój cytat z mojej odpowiedzi jest nieco mylący, ponieważ ma zastosowanie tylko wtedy, gdy utworzysz również dodatkowy indeks częściowy, jak opisano tam:
Jak dodać warunkowy unikalny indeks w PostgreSQL
Jeśli nie dodasz tego drugiego indeksu (tak jak nie), masz już swoje rozwiązanie , wydawałoby się. Z samym unikalnym indeksem wielokolumnowym możesz wpisać (1, NULL) wiele razy, ale (1,2) lub (1,3) tylko raz.
Puste ciągi
Jeśli przez pomyłkę rozważałeś puste ciągi ('' ) (dla typu znaków
) zamiast NULL wartości:są one obsługiwane jak każda inna wartość. możesz radzić sobie z tą sytuacją za pomocą wielokolumnowego, częściowo funkcjonalnego unikalnego indeksu (indeks wyrażenia
):
CREATE UNIQUE INDEX predictions _dim_tat_uni_idx
ON predictions (tat, NULLIF(dim, ''));
W ten sposób możesz wpisać (1, 'a') , (1, 'b') tylko raz.
Ale (1, NULL) i (1, '') wiele razy.
Skutki uboczne
Indeks nadal będzie w pełni obsługiwał zwykłe zapytania w pierwszej kolumnie (tat ).
Ale zapytania w obu kolumnach musiałyby pasować do wyrażenia, aby wykorzystać pełny potencjał. Byłoby to szybsze, nawet jeśli wydaje się to nie mieć sensu:
SELECT * FROM predictions
WHERE tat = 1
AND NULLIF(dim, '') = 'foo';
.. niż to:
SELECT * FROM predictions
WHERE tat = 1
AND dim = 'foo';
.. ponieważ pierwsze zapytanie może używać obu kolumn indeksu. Wynik byłby taki sam (z wyjątkiem wyszukiwania '' lub NULL ). Szczegóły w tej powiązanej odpowiedzi na dba.SE
.