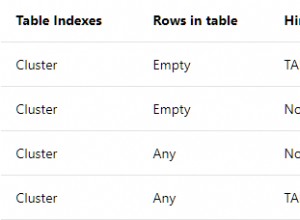
Co najważniejsze, potrzebujesz indeksu playersinclubs(club_id, player_id) . Reszta to szczegóły (które nadal mogą mieć duże znaczenie).
Musisz precyzyjnie określić swoje rzeczywiste cele. Piszesz:
Nie musisz dołączać do club za to w ogóle:
SELECT p.*
FROM playersinclubs pc
JOIN player p ON p.id = pc.player_id
WHERE pc.club_id = 3;
I nie potrzebujesz kolumn playersinclubs w danych wyjściowych, co stanowi niewielki wzrost wydajności — chyba że pozwala na tylko indeks skanuj w playersinclubs , to może być znaczne.
Prawdopodobnie nie potrzebujesz wszystkich kolumny player w rezultacie. Tylko SELECT kolumny, których faktycznie potrzebujesz.
PK na player zapewnia indeks, którego potrzebujesz w tej tabeli.
Potrzebujesz indeksu na playersinclubs(club_id, player_id) , ale nie uczynić go wyjątkowym, chyba że gracze nie mogą dołączyć do tego samego klubu po raz drugi.
Jeśli gracze mogą dołączać wiele razy, a potrzebujesz tylko listy „wszystkich graczy”, musisz również dodać DISTINCT krok, aby złożyć zduplikowane wpisy. Możesz po prostu:
SELECT DISTINCT p.* ...
Ale ponieważ próbujesz zoptymalizować wydajność:taniej jest wcześnie wyeliminować duplikaty:
SELECT p.*
FROM (
SELECT DISTINCT player_id
FROM playersinclubs
WHERE club_id = 3;
) pc
JOIN player p ON p.id = pc.player_id;
Może naprawdę chcesz wszystko wpisy w playersinclubs a także wszystkie kolumny tabeli. Ale twój opis mówi inaczej. Zapytanie i indeksy byłyby inne.
Ściśle powiązana odpowiedź: