Wprowadzenie
Osiągnięcie minimalnego rejestrowania używając INSERT...SELECT w puste cel indeksu klastrowego nie jest tak prosty, jak opisano w Przewodniku ładowania wydajności danych .
Ten post zawiera nowe szczegóły o wymaganiach minimalnego logowania gdy cel wstawiania jest pustym tradycyjnym indeksem klastrowym. (Słowo „tradycyjny” nie obejmuje sklepu kolumnowego i zoptymalizowane pod kątem pamięci („Hekaton”) tabele w grupach). Aby zapoznać się z warunkami, które mają zastosowanie, gdy tabela docelowa jest stertą, zobacz poprzedni artykuł z tej serii.
Podsumowanie tabel klastrowych
Przewodnik po wydajności ładowania danych zawiera ogólne podsumowanie warunków wymaganych do minimalnego logowania w zgrupowane tabele:
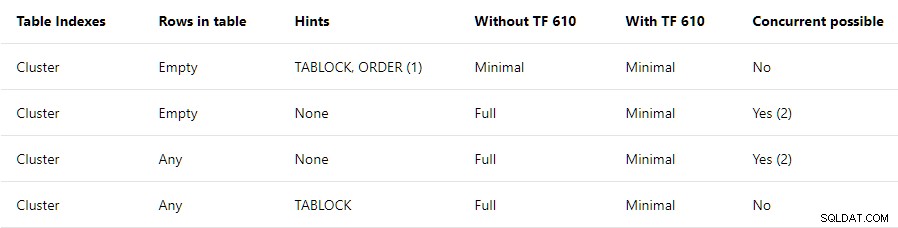
Ten post dotyczy tylko górnego wiersza . Stwierdza, że TABLOCK i ORDER wymagane są wskazówki, z dopiskiem:
Jeśli używasz BULK INSERT, należy użyć wskazówki dotyczącej zamówienia.
Pusty cel z blokadą tabeli
Górny wiersz podsumowania sugeruje, że wszystkie wstawienia do pustego indeksu klastrowego będą minimalnie rejestrowane tak długo, jak TABLOCK i ORDER podpowiedzi są określone. TABLOCK wskazówka jest wymagana, aby włączyć RowSetBulk obiekt stosowany do ładunków masowych na stercie. ORDER wskazówka jest wymagana, aby wiersze dotarły do wstawki indeksu klastrowanego operator planu w indeksie docelowym kolejność kluczy . Bez tej gwarancji SQL Server może dodawać niepoprawnie posortowane wiersze indeksu, co nie byłoby dobre.
W przeciwieństwie do innych metod ładowania zbiorczego, nie jest to możliwe aby określić wymagane ORDER wskazówka dotycząca INSERT...SELECT oświadczenie. Ta wskazówka to nie to samo jak przy użyciu ORDER BY klauzula INSERT...SELECT oświadczenie. ORDER BY klauzula na INSERT gwarantuje tylko sposób, w jaki każda tożsamość przypisane są wartości, a nie kolejność wstawiania wierszy.
Dla INSERT...SELECT , SQL Server dokonuje własnej decyzji czy upewnić się, że wiersze są prezentowane w wstawce indeksu klastrowego operator w kolejności klucza, czy nie. Wynik tej oceny jest widoczny w planach wykonania poprzez DMLRequestSort właściwość Wstaw operator. DMLRequestSort właściwość musi być ustawione na prawdę dla INSERT...SELECT do indeksu, aby był minimalnie rejestrowany . Gdy jest ustawiony na false , minimalne logowanie nie może wystąpić.
Posiadanie DMLRequestSort ustaw prawdę jest jedyną akceptowaną gwarancją zamawiania wstawiania danych wejściowych dla programu SQL Server. Można sprawdzić plan wykonania i przewidywać że wiersze powinny/będzie/muszą dotrzeć w kolejności indeksów klastrowych, ale bez określonych gwarancji wewnętrznych dostarczone przez DMLRequestSort , ta ocena się nie liczy.
Kiedy DMLRequestSort jest prawda , SQL Server może wprowadź wyraźne sortowanie operatora w planie wykonania. Jeśli może wewnętrznie zagwarantować zamawianie w inny sposób, Sortuj można pominąć. Jeśli dostępne są zarówno alternatywy sortowania, jak i braku sortowania, optymalizator utworzy opartą na kosztach wybór. Analiza kosztów nie uwzględnia minimalnego logowania bezpośrednio; jest napędzany oczekiwanymi korzyściami sekwencyjnego we/wy i unikaniem dzielenia stron.
Warunki DMLRequestSort
Oba poniższe testy muszą przejść, aby SQL Server wybrał ustawienie DMLRequestSort do prawdy podczas wstawiania do pustego indeksu klastrowego z określonym blokowaniem tabeli:
- Szacunkowe ponad 250 wierszy po stronie wejściowej wstawki z indeksem klastrowym operator; i
- Szacunkowa rozmiar danych więcej niż 2 strony . Szacowany rozmiar danych nie jest liczbą całkowitą, więc wynik 2.001 stron spełnia ten warunek.
(Może to przypominać o warunkach minimalnego rejestrowania sterty , ale wymagane szacunkowe rozmiar danych to dwie strony zamiast ośmiu).
Obliczanie rozmiaru danych
szacowany rozmiar danych obliczenie tutaj podlega tym samym dziwactwom opisanym w poprzednim artykule dla stosów, z wyjątkiem tego, że 8-bajtowy RID nie jest obecny.
W przypadku SQL Server 2012 i wcześniejszych oznacza to 5 dodatkowych bajtów na wiersz są uwzględniane przy obliczaniu rozmiaru danych:jeden bajt na wewnętrzny bit flaga i cztery bajty dla unikacza (używane w obliczeniach nawet dla unikalnych indeksów, które nie przechowują unikatnika ).
W przypadku SQL Server 2014 i nowszych, uniquifier jest poprawnie pominięty dla unikalny indeksy, ale jeden dodatkowy bajt dla wewnętrznego bitu flaga jest zachowana.
Demo
Poniższy skrypt należy uruchomić na rozwojowej instancji SQL Server w nowej testowej bazie danych ustaw na używanie SIMPLE lub BULK_LOGGED model odzyskiwania.
Demo ładuje 268 wierszy do zupełnie nowej tabeli klastrowej za pomocą INSERT...SELECT z TABLOCK oraz raporty dotyczące wygenerowanych rekordów dziennika transakcji.
IF OBJECT_ID(N'dbo.Test', N'U') IS NOT NULL
BEGIN
DROP TABLE dbo.Test;
END;
GO
CREATE TABLE dbo.Test
(
id integer NOT NULL IDENTITY
CONSTRAINT [PK dbo.Test (id)]
PRIMARY KEY,
c1 integer NOT NULL,
padding char(45) NOT NULL
DEFAULT ''
);
GO
-- Clear the log
CHECKPOINT;
GO
-- Insert rows
INSERT dbo.Test WITH (TABLOCK)
(c1)
SELECT TOP (268)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV;
GO
-- Show log entries
SELECT
FD.Operation,
FD.Context,
FD.[Log Record Length],
FD.[Log Reserve],
FD.AllocUnitName,
FD.[Transaction Name],
FD.[Lock Information],
FD.[Description]
FROM sys.fn_dblog(NULL, NULL) AS FD;
GO
-- Count the number of fully-logged rows
SELECT
[Fully Logged Rows] = COUNT_BIG(*)
FROM sys.fn_dblog(NULL, NULL) AS FD
WHERE
FD.Operation = N'LOP_INSERT_ROWS'
AND FD.Context = N'LCX_CLUSTERED'
AND FD.AllocUnitName = N'dbo.Test.PK dbo.Test (id)';
(Jeśli uruchamiasz skrypt na SQL Server 2012 lub starszym, zmień TOP klauzula w skrypcie od 268 do 252 z powodów, które zostaną wyjaśnione za chwilę.)
Dane wyjściowe pokazują, że wszystkie wstawione wiersze zostały w pełni zarejestrowane pomimo pustego docelowa tabela klastrowa i TABLOCK wskazówka:
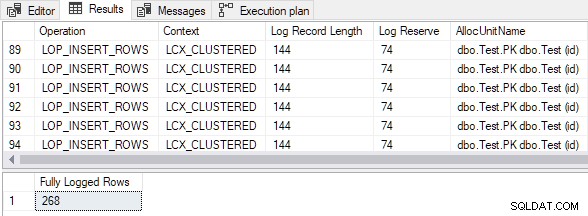
Obliczony rozmiar danych wstawiania
Właściwości planu wykonania wstawki z indeksem klastrowym operator pokazuje, że DMLRequestSort jest ustawione na fałsz . Dzieje się tak, ponieważ chociaż szacowana liczba wierszy do wstawienia przekracza 250 (spełnia pierwszy wymóg), obliczona rozmiar danych nie przekraczają dwie strony po 8 KB.
Szczegóły obliczeń (dla SQL Server 2014 i nowsze) są następujące:
- Łączna stała długość rozmiar kolumny =54 bajty :
- Identyfikator typu 104
bit=1 bajt (wewnętrzny). - Wpisz identyfikator 56
integer=4 bajty (idkolumna). - Wpisz identyfikator 56
integer=4 bajty (c1kolumna). - Wpisz id 175
char(45)=45 bajtów (paddingkolumna).
- Identyfikator typu 104
- Bitmapa zerowa =3 bajty .
- Nagłówek wiersza narzut =4 bajty .
- Obliczony rozmiar wiersza =54 + 3 + 4 =61 bajtów .
- Obliczony rozmiar danych =61 bajtów * 268 wierszy =16 348 bajtów .
- Obliczone strony danych =16 384 / 8192 =1.99560546875 .
Obliczony rozmiar wiersza (61 bajtów) różni się od rzeczywistego rozmiaru pamięci wiersza (60 bajtów) dodatkowym jednym bajtem wewnętrznych metadanych obecnych w strumieniu wstawiania. Obliczenie nie uwzględnia również 96 bajtów używanych na każdej stronie przez nagłówek strony ani innych rzeczy, takich jak narzut wersjonowania wierszy. Te same obliczenia na SQL Server 2012 dodaje kolejne 4 bajty w wierszu dla ujednolicacza (który nie występuje w unikalnych indeksach, jak wspomniano wcześniej). Dodatkowe bajty oznaczają, że oczekuje się, że na każdej stronie zmieści się mniej wierszy:
- Obliczony rozmiar wiersza =61 + 4 =65 bajtów .
- Obliczony rozmiar danych =65 bajtów * 252 wiersze =16 380 bajtów
- Obliczone strony danych =16 380 / 8192 =1.99951171875 .
Zmiana TOP klauzula od 268 wierszy do 269 (lub od 252 do 253 dla 2012 r.) powoduje, że oczekiwany rozmiar danych jest obliczany tylko przekroczyć minimalny próg 2 stron:
- Serwer SQL 2014
- 61 bajtów * 269 wierszy =16 409 bajtów.
- 16 409 / 8192 =2.0030517578125 stron.
- SQL Server 2012
- 65 bajtów * 253 wiersze =16 445 bajtów.
- 16 445/8192 =2.0074462890625 stron.
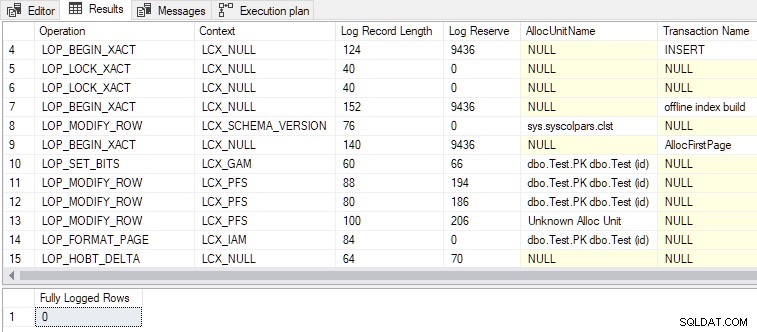
Gdy drugi warunek również jest spełniony, DMLRequestSort ma wartość prawda i minimalne rejestrowanie został osiągnięty, jak pokazano na poniższym wyjściu:
Inne ciekawe miejsca:
- Łącznie generowanych jest 79 rekordów dziennika, w porównaniu z 328 dla wersji z pełnym logowaniem. Mniejsza liczba rekordów logów to oczekiwany wynik minimalnego rejestrowania.
LOP_BEGIN_XACTrekordy w minimalnie rejestrowanych rekordy rezerwują stosunkowo dużą ilość miejsca w dzienniku (każdy po 9436 bajtów).- Jedną z nazw transakcji wymienionych w zapisach dziennika jest „budowanie indeksu offline” . Chociaż nie prosiliśmy o utworzenie indeksu jako takiego, zbiorcze ładowanie wierszy do pustego indeksu jest zasadniczo tą samą operacją.
- W pełni zalogowany insert przyjmuje blokadę na poziomie tabeli (
Tab-X), a minimalnie rejestrowane insert przyjmuje modyfikację schematu (Sch-M) tak jak robi to „prawdziwa” kompilacja indeksu offline. - Zbiorcze ładowanie pustej tabeli klastrowej za pomocą
INSERT...SELECTzTABLOCKiDMRequestSortustaw prawdę używaRowsetBulkpodobnie jak mechanizm minimalnie rejestrowany stosy w poprzednim artykule.
Szacunki kardynalności
Uważaj na szacunki o niskiej kardynalności na wstawce z indeksem klastrowym operator. Jeśli którykolwiek z progów jest wymagany do ustawienia DMLRequestSort do prawdy nie zostanie osiągnięty z powodu niedokładnego oszacowania liczności, wstawka zostanie w pełni zalogowana , niezależnie od rzeczywistej liczby wierszy i całkowitego rozmiaru danych napotkanych w czasie wykonywania.
Na przykład zmiana TOP klauzula w skrypcie demonstracyjnym, aby użyć zmiennej powoduje stałą kardynalność zgadnij 100 wierszy, czyli poniżej minimum 251 wierszy:
-- Insert rows
DECLARE @NumRows bigint = 269;
INSERT dbo.Test WITH (TABLOCK)
(c1)
SELECT TOP (@NumRows)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV; Buforowanie planu
DMLRequestSort właściwość jest zapisywana jako część buforowanego planu. Gdy plan w pamięci podręcznej jest ponownie używany , wartość DMLRequestSort nie jest ponownie obliczany w czasie wykonywania, chyba że nastąpi ponowna kompilacja. Zauważ, że ponowna kompilacja nie występuje dla TRIVIAL plany oparte na zmianach w statystykach lub kardynalności tabeli.
Jednym ze sposobów uniknięcia nieoczekiwanych zachowań spowodowanych buforowaniem jest użycie OPTION (RECOMPILE) wskazówka. Zapewni to odpowiednie ustawienie dla DMLRequestSort jest obliczana ponownie, kosztem kompilacji przy każdym wykonaniu.
Flaga śledzenia
Możliwe jest wymuszenie DMLRequestSort być ustawionym na prawdę ustawiając nieudokumentowane i nieobsługiwane trace flag 2332, jak pisałem w Optymalizacji zapytań T-SQL, które zmieniają dane. Niestety, to nie wpływa na minimalne logowanie kwalifikowalność do pustych tabel klastrowych — wkładka nadal musi być szacowana na ponad 250 wierszy i 2 strony. Ta flaga śledzenia ma wpływ na inne minimalne rejestrowanie scenariusze, które zostały omówione w ostatniej części tej serii.
Podsumowanie
Zbiorcze ładowanie pustego indeks klastrowy przy użyciu INSERT...SELECT ponownie wykorzystuje RowsetBulk mechanizm używany do zbiorczego ładowania tabel sterty. Wymaga to zablokowania tabeli (zwykle osiągane za pomocą TABLOCK podpowiedź) i ORDER wskazówka. Nie ma możliwości dodania ORDER wskazówka do INSERT...SELECT oświadczenie. W konsekwencji osiągnięcie minimalnego rejestrowania do pustej tabeli klastrowej wymaga, aby DMLRequestSort właściwość wstawki indeksu klastrowego operator jest ustawiony na prawda . To gwarancje do SQL Server, który wiersze są prezentowane w Wstaw operator przybędzie w kolejności klucza indeksu docelowego. Efekt jest taki sam jak przy użyciu ORDER wskazówka dostępna dla innych metod wstawiania zbiorczego, takich jak BULK INSERT i bcp .
Aby wykonać DMLRequestSort być ustawionym na prawdę , musi być:
- Ponad 250 wierszy szacowany do wstawienia; i
- Szacunkowa wstaw dane o rozmiarze większym niż dwie strony .
szacowana wstaw obliczenia rozmiaru danych nie dopasuj wynik pomnożenia planu wykonania szacowana liczba wierszy i szacowany rozmiar wiersza właściwości na wejściu do Wstaw operator. Obliczenia wewnętrzne (niepoprawnie) obejmują jedną lub więcej kolumn wewnętrznych w strumieniu wstawiania, które nie są utrwalane w końcowym indeksie. Wewnętrzne obliczenia nie uwzględniają również nagłówków stron ani innych kosztów ogólnych, takich jak wersjonowanie wierszy.
Podczas testowania lub debugowania minimalne logowanie problemów, uważaj na szacunkowe wartości niskiej kardynalności i pamiętaj, że ustawienie DMLRequestSort jest buforowany jako część planu wykonania.
W ostatniej części tej serii szczegółowo opisano warunki wymagane do osiągnięcia minimalnego rejestrowania bez użycia RowsetBulk mechanizm. Odpowiadają one bezpośrednio nowym funkcjom dodanym pod flagą śledzenia 610 do SQL Server 2008, a następnie domyślnie włączonym od SQL Server 2016 i nowszych.