W poprzednim artykule wyjaśniłem krok po kroku proces instalowania klastrowego wystąpienia trybu failover programu SQL Server. W tym artykule wyjaśnię, jak dodać dodatkowy węzeł do istniejącej instancji klastra pracy awaryjnej.
Zainstaluj instancję SQL Server Failover Cluster
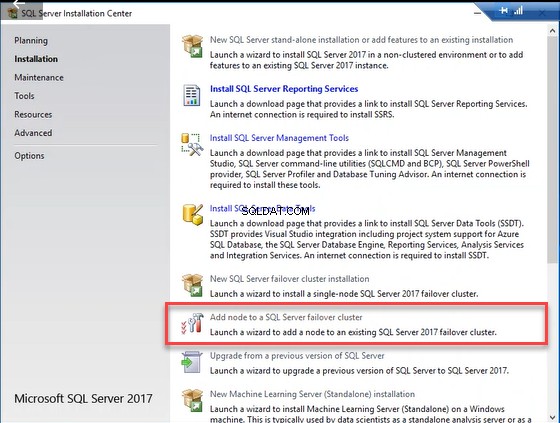
Po zainstalowaniu programu SQL Server na SQL01.dc.Local węzeł, połącz się z SQL02.dc.Local i uruchom setup.exe – otworzy się kreator instalacji SQL Server. W kreatorze wybierz „Instalacja ” z panelu po lewej stronie i kliknij „Dodaj węzeł do klastra pracy awaryjnej SQL Server ”. Zobacz następujący obraz:
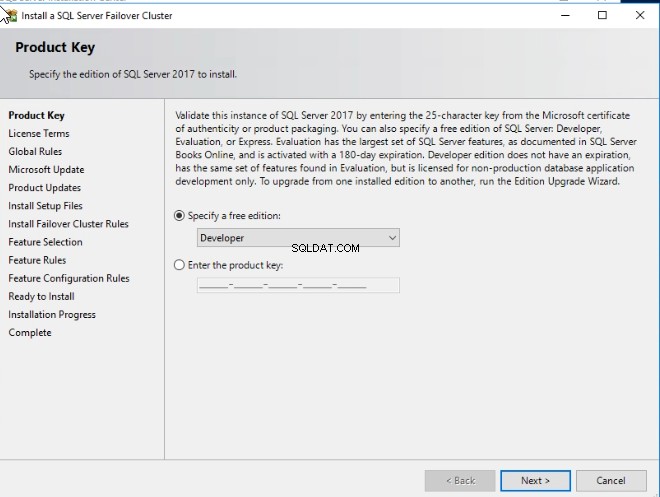
W „Kluczu produktu ”, wybierz wersję SQL Server, którą chcesz zainstalować. Jeśli masz klucz licencyjny dla wersji standardowej lub Enterprise programu SQL Server, możesz wprowadzić go w polu tekstowym „Wprowadź klucz produktu”. Jeśli korzystasz z wersji dla programistów lub bezpłatnej wersji próbnej, wybierz dowolną opcję z „określ bezpłatną wersję " upuścić pudło.
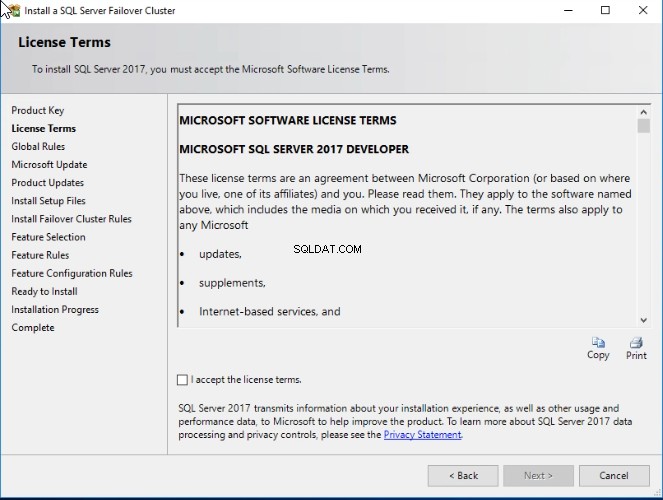
W „Warunkach licencji ”, zaakceptuj warunki firmy Microsoft. Zobacz następujący obraz:
W „Aktualizacji Microsoft ”, możesz wybrać instalację aktualizacji firmy Microsoft. Jeśli chcesz pobrać aktualizacje ręcznie, możesz pominąć ten krok. Kliknij Dalej.
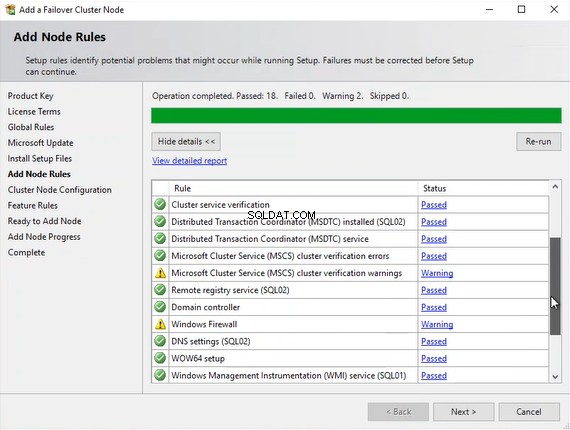
W sekcji „Dodaj reguły węzłów ”, upewnij się, że wszystkie reguły zostały pomyślnie zweryfikowane. Jeśli jakakolwiek reguła nie powiedzie się lub wyświetli ostrzeżenie, należy ją naprawić i kontynuować konfigurację. W wersji demonstracyjnej pominąłem ostrzeżenie, więc otrzymujemy następujący obraz:
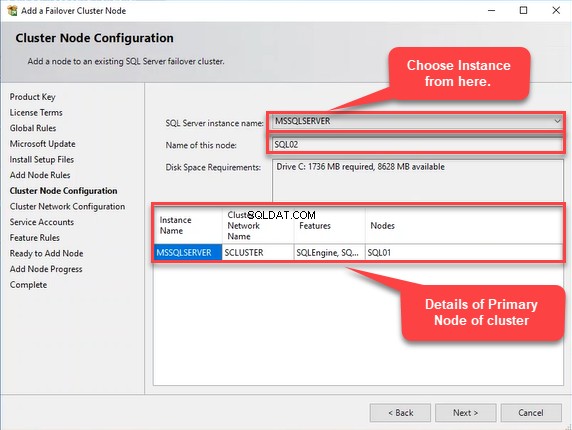
W sekcji „Konfiguracja węzła klastra ”, sprawdź nazwę instancji SQL Server, nazwę sieci klastra, funkcje i wybrany węzeł. Jeśli tworzysz wiele instancji przełączania awaryjnego, możesz wybrać odpowiednią instancję z „Nazwa instancji SQL Server " upuścić pudło. Sprawdź wszystkie konfiguracje, kliknij Dalej i zobacz następujący obraz:
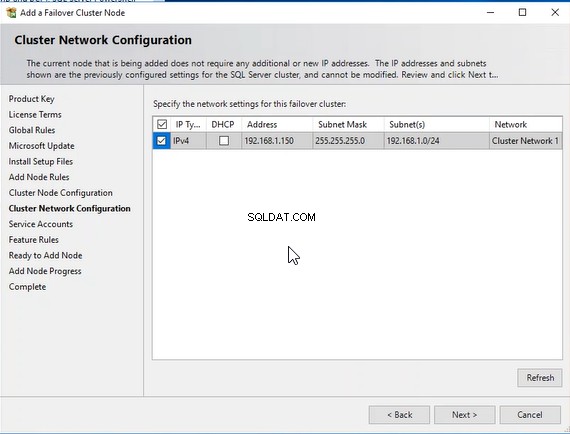
W sekcji „Konfiguracja sieci klastra ”, sprawdź konfigurację sieci klastra pracy awaryjnej i kliknij Dalej. Zobacz następujący obraz:
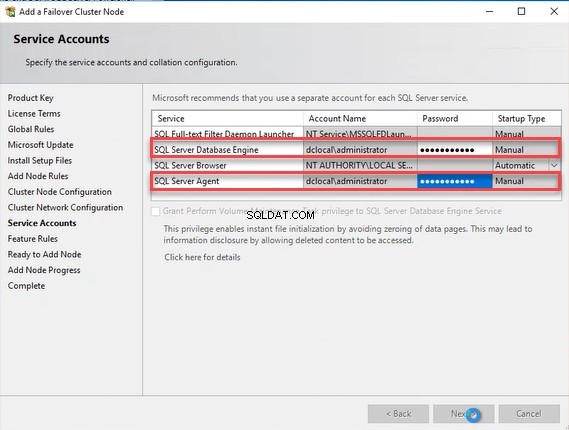
W „Kontach usługi ”, wprowadź hasło odpowiednich kont usługi SQL Server i kliknij Dalej. Zobacz następujący obraz:
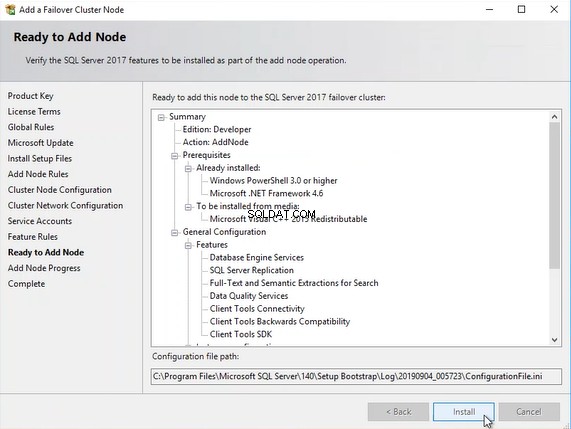
W sekcji „Gotowe do dodania węzła ”, przejrzyj wszystkie ustawienia i kliknij Zainstaluj. Rozpocznie się proces dodawania węzła do istniejącej instancji klastra pracy awaryjnej. Zobacz następujący obraz:
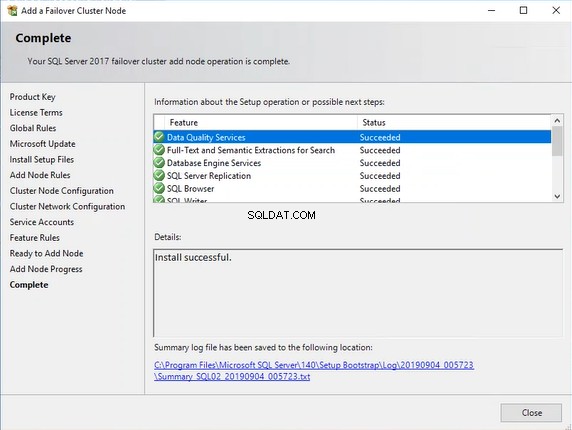
Po zakończeniu procesu pokazuje, czy proces zakończył się pomyślnie, czy nie. Jak widać, instalacja przebiegła pomyślnie. Zobacz następujący obraz:
Aby przejrzeć informacje w wystąpieniu klastra pracy awaryjnej programu SQL Server, otwórz menedżera klastra pracy awaryjnej, uruchamiając następujące polecenie w „Uruchom ”:
Cluadmin.exe
Możesz go również otworzyć w panelu sterowania> „Narzędzia administracyjne ”> „Menedżer klastra pracy awaryjnej ”. Zobacz następujący obraz:
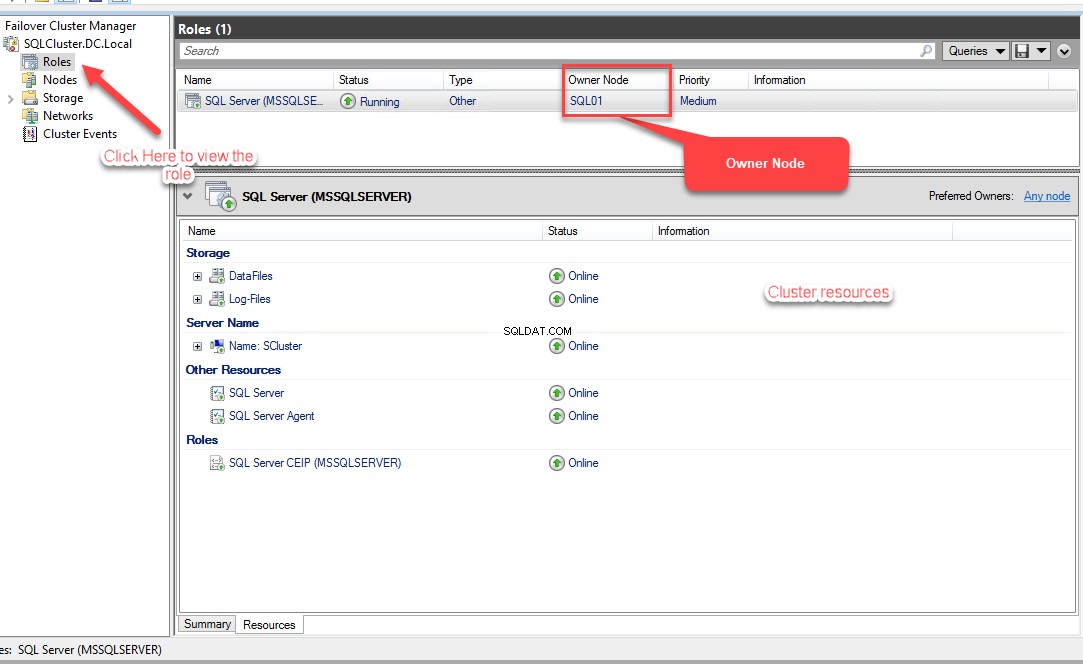
Jak widać na powyższym obrazku, SQL Server (MSSQLSERVER) rola została utworzona, a węzeł właściciela to SQL01 . Możesz zobaczyć informacje o zasobach, które zostały utworzone.
Możesz uzyskać informacje o właścicielu i drugorzędne węzły klastra, wykonując następujące zapytanie:
SELECT CONVERT(VARCHAR(5), nodename)AS [Name of Node], CASE WHEN CONVERT(INT, is_current_owner) = 0 THEN 'No.' ELSE 'YES' END AS [Is Current Owner] FROM sys.dm_os_cluster_nodes
Poniżej znajduje się wynik:
Name of Node Is Current Owner ------------ ---------------- SQL01 YES SQL02 No.
Przetestujmy teraz konfigurację klastra, wykonując ręczne i automatyczne przełączanie awaryjne.
Ręczne przełączanie awaryjne
Ręczne przełączanie awaryjne pozwoli nam zweryfikować, czy klaster został odpowiednio skonfigurowany. Jak wspomniałem, stworzyliśmy dwuwęzłowy klaster. Aby zademonstrować ten proces, przeniosę rolę serwera SQL z węzła podstawowego (SQL01 ) do węzła dodatkowego (SQL02 ). Aby to zrobić, otwórz menedżera klastra pracy awaryjnej.
Zobacz następujący obraz:
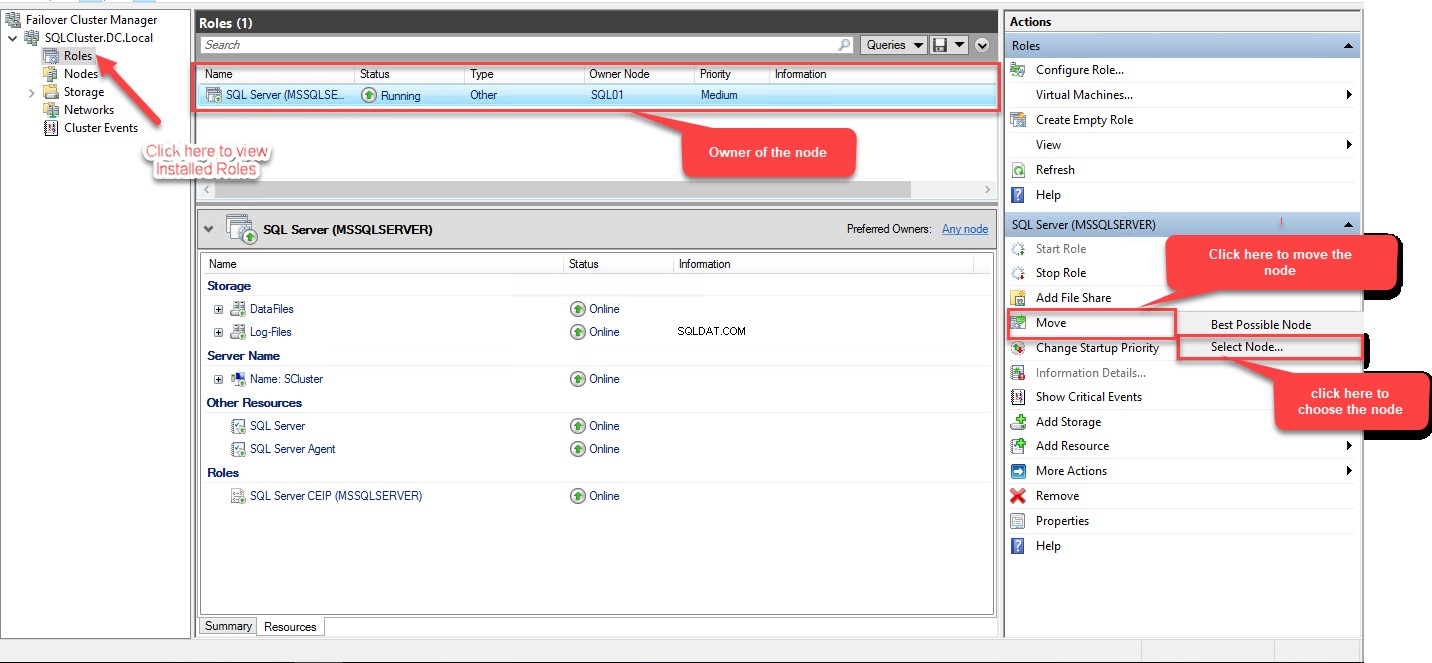
Teraz rozwiń „R olejki ”, wybierz „Przenieś ” i wybierz „Wybierz węzeł ”. „Przenieś rolę klastrowaną otworzy się okno dialogowe. Wybierz SQL02 z „Węzły klastrowane ” listę i kliknij OK. Zobacz następujący obraz:
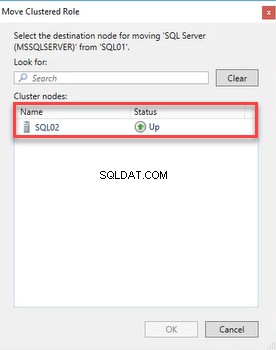
Po zakończeniu procesu przełączania awaryjnego otwórz menedżera klastra pracy awaryjnej. Zobacz następujący obraz:
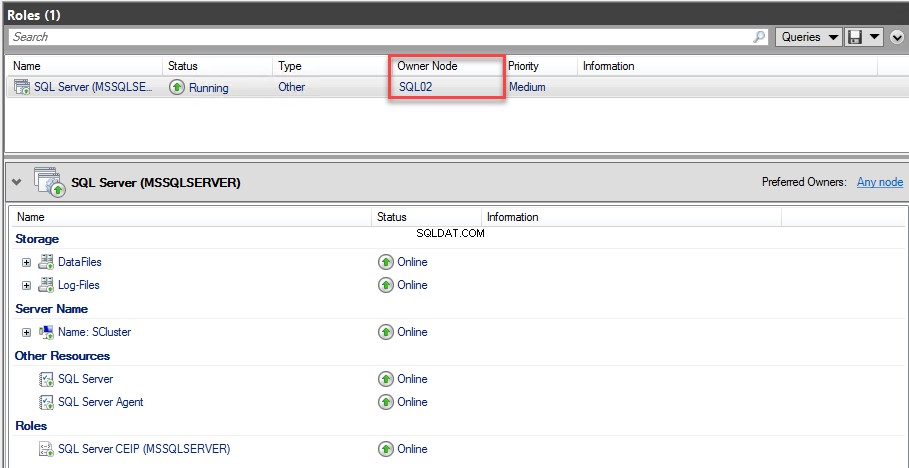
Jak widać, po przełączeniu awaryjnym zmieniono węzeł właściciela. Teraz węzeł właściciela to SQL02 . Możesz to sprawdzić, wykonując następujące zapytanie:
SELECT CONVERT(VARCHAR(5), nodename)AS [Name of Node], CASE WHEN CONVERT(INT, is_current_owner) = 0 THEN 'No.' ELSE 'YES' END AS [Is Current Owner] FROM sys.dm_os_cluster_nodes
Poniżej znajduje się wynik:
Name of Node Is Current Owner ------------ ---------------- SQL01 No SQL02 YES
Alternatywnie możesz wykonać przełączanie awaryjne za pomocą następującego polecenia PowerShell:
Move-ClusterGroup "SQL Server (MSSQLSERVER)" -Node "SQL02"
Testuj automatyczne przełączanie awaryjne
Zweryfikujmy teraz klaster pracy awaryjnej, wywołując automatyczne przełączanie awaryjne. Wcześniej ręcznie przenieśliśmy przełączanie awaryjne do SQL02 Węzeł. Aby wywołać automatyczne przełączanie awaryjne, zamknij SQL02 w dół. Po zakończeniu zamykania zasoby klastra programu SQL Server zostaną przeniesione do węzła SQL01. Zobacz następujący obraz Hyper-V kierownik:
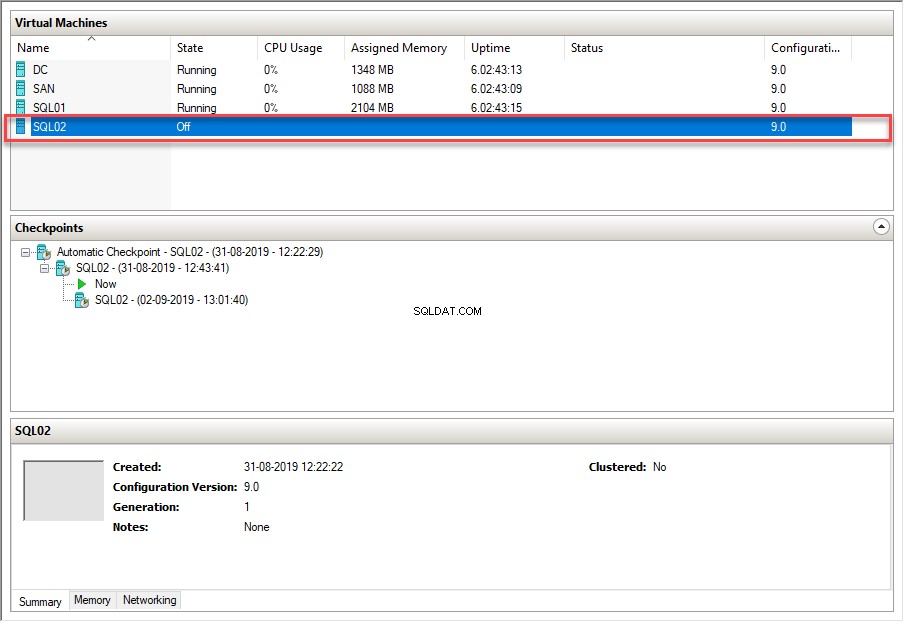
Poniższy obraz przedstawia menedżera klastra pracy awaryjnej w SQL01 węzeł:

Możesz wykonać automatyczne przełączanie awaryjne, wykonując następujące czynności:
- Wyłącz kartę sieciową w dowolnym węźle
- Wyłącz usługi klastra pracy awaryjnej
- Zamknij usługę SQL Server
Podsumowanie
W tym artykule wyjaśniłem krok po kroku proces dodawania węzła do istniejącej instancji klastra pracy awaryjnej SQL Server. W następnym artykule wyjaśnię krok po kroku proces dodawania nowego dysku klastrowego i przenoszenia na niego baz danych użytkowników. Bądź na bieżąco!