Ten artykuł jest próbą przeanalizowania danych wyjściowych sp_spaceused procedura składowana.
Wprowadzenie
Zrozumienie wewnętrznych aspektów użytkowania bazy danych i trendów wzrostu odgrywa kluczową rolę w określaniu odpowiedniego rozmiaru bazy danych. sp_spaceused to prawdopodobnie najczęściej wykonywana przez administratora systemowa procedura składowana służąca do znajdowania miejsca na dysku używanego przez bazę danych. Pomaga to szybko zorientować się w wykorzystaniu bazy danych. Statystyka. sp_spaceused służy do wyświetlania liczby wierszy, rozmiaru danych, rozmiaru indeksu, ilości używanego miejsca, niewykorzystanego miejsca przez każdy obiekt oraz nieprzydzielonego rozmiaru bazy danych. Chociaż patrząc na wartości podane przez sp_spaceused, nie należy myśleć o zmniejszaniu bazy danych, pliku danych lub pliku dziennika. Często nie jesteśmy świadomi tego, co robimy. Często nie wiemy, jakie byłyby skutki wykonywania takich operacji związanych z zasobami. Dane wyjściowe sp_spaceused mówią nam wiele o bieżącej wydajności bazy danych. nieprzydzielone kolumna i nieużywane kolumna poinformuj nas o wolnym miejscu pozostałym w bazie danych i poziomach tabeli.
Ten artykuł dotyczy:
- Zajrzyj do sp_spaceused
- Wpływ ustawienia automatycznego wzrostu na kolumny, nieprzydzielony i nieużywany
- Znajdowanie szczegółów wykorzystania miejsca w bazie danych i na poziomach instancji
- Pomiar zdarzeń związanych z automatycznym wzrostem
- Znajdowanie rozmiarów plików mdf i ldf
- Czynniki decydujące o wydajności bazy danych
- I więcej…
Wewnętrzne elementy sp_spaceused
Przechwyć szczegóły wykorzystania miejsca we wszystkich tabelach
W poniższym języku T-SQL nieudokumentowana procedura składowana sp_MSforeachtable jest używana do przechodzenia przez wszystkie tabele w zakresie bieżącego kontekstu bazy danych, aby uzyskać metryki wykorzystania przestrzeni dla wszystkich tabel w kontekście.
Declare @tbl_sp_spaceused table(
name varchar(100) NULL,
rows bigint NULL,
reserved varchar(20) NULL,
data varchar(20) NULL,
index_size varchar(20) NULL,
unused varchar(20) NULL
)
-- insert output of sp_spaceused to table variable
INSERT INTO @tbl_sp_spaceused ( name, rows, reserved, data, index_size, unused )
EXEC sp_MSforeachtable @command1 = 'EXEC sp_spaceused [?]'
SELECT *
FROM @tbl_sp_spaceused
order by rows desc 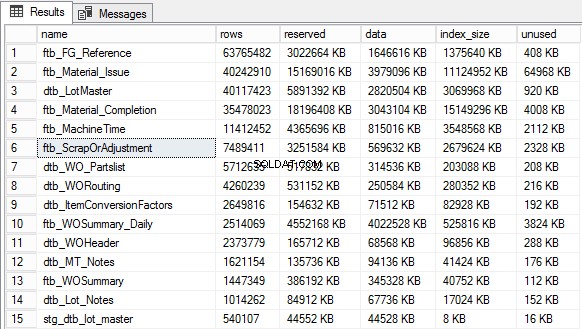
Przechwyć szczegóły wykorzystania miejsca we wszystkich bazach danych
Nieudokumentowana procedura składowana sp_MSforeachDB służy do przechodzenia przez całą bazę danych w zakresie bieżącej instancji SQL w celu uzyskania informacji o wykorzystaniu miejsca we wszystkich bazach danych.
declare @tbl_sp_spaceusedDBs table(
database_name varchar(100) NOT NULL,
database_size varchar(50) NULL,
unallocated varchar(30) NULL,
reserved varchar(20) NULL,
data varchar(20) NULL,
index_size varchar(20) NULL,
unused varchar(20) NULL
)
INSERT INTO @tbl_sp_spaceusedDBs ( database_name, database_size, unallocated, reserved, data, index_size, unused )
EXEC sp_msforeachdb @command1="use ? exec sp_spaceused @oneresultset = 1"
SELECT *
FROM @tbl_sp_spaceusedDBs
ORDER BY database_name, database_size
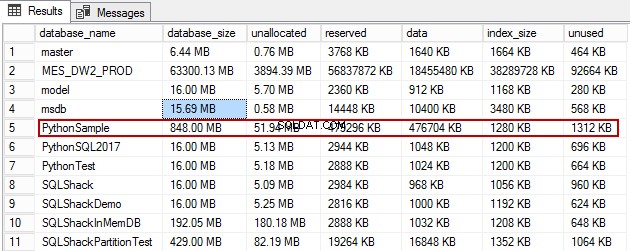
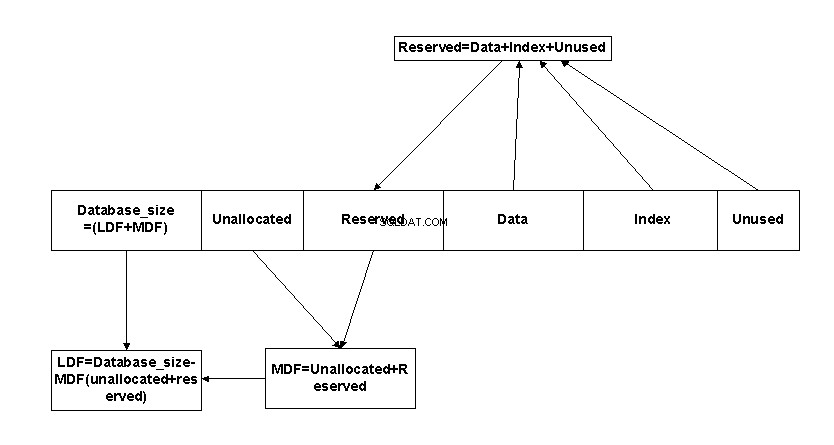
Tutaj nazwa_bazy to nazwa bazy danych; w tym przypadku PythonSample . rozmiar_bazy czy Uprzydzielone+zarezerwowane+dane+indeks+nieużywane =MDF +LDF (=848 MB w tym przypadku). nieprzydzielone miejsce tutaj wynosi 51,94 MB.
W rzeczywistości jest to granica dysku, która została wyznaczona dla bazy danych. Sp_spaceused wyprowadza nieprzydzieloną kolumnę zdefiniowaną na poziomie bazy danych i nie jest zarezerwowana dla żadnej tabeli i może zostać przejęta przez pierwszy obiekt, który ma więcej miejsca na rozwój.
nieprzydzielone spacja to wolne miejsce w pliku danych, dzięki czemu nie musi ono automatycznie powiększać się za każdym razem, gdy wysyłasz zapytanie; Zwykle silnik pamięci masowej SQL Server zarządza automatycznym wzrostem za pomocą mechanizmu znanego jako algorytm Proportional Fill Algorithm. Zarządzanie zakresami odbywa się skutecznie w oparciu o liczbę zapisów w plikach. A jednocześnie, gdy wykorzystana przestrzeń osiągnie próg, wyzwalane jest zdarzenie, które ma na celu dalszy automatyczny wzrost. Ustalenie odpowiedniej wartości nieprzydzielonej przestrzeni zależy od potrzeb i sytuacji oraz charakteru użytkowania bazy danych. Przestrzeń nieprzydzielona to przestrzeń, która nie jest jeszcze używana i jest „do zgarnięcia”. Zasadniczo te zakresy są oznaczone bitem 1 na stronie GAM. Rozumiejąc koncepcję autowzrostu od góry, każdy rodzaj wzrostu może generować dalsze nieprzydzielone rozmiary.
Korzystając z następującego zapytania SQL, możemy zobaczyć, ile razy wygenerowano zdarzenie automatycznego wzrostu, a także czas, przez jaki baza danych była wstrzymana przez proces.
DECLARE @fname NVARCHAR(1000);
-- Get the name of the current default trace
SELECT @fname = CAST(value AS VARCHAR(MAX))
FROM ::fn_trace_getinfo(DEFAULT)
WHERE traceid = 1 AND property = 2;
SELECT
ft.StartTime [Start Time]
,t.name [Event Name]
,DB_NAME(ft.databaseid) [Database Name]
,ft.Filename [File Name]
,(ft.IntegerData*8)/1024.0 [Growth MB]
,(ft.duration/1000) [Duration MS]
FROM ::fn_trace_gettable(@fname, DEFAULT) AS ft
INNER JOIN sys.trace_events AS t ON ft.EventClass = t.trace_event_id
WHERE (ft.EventClass = 92 -- DateFile Auto-growth
OR ft.EventClass = 93) -- LogFile Auto-growth
ORDER BY ft.StartTime
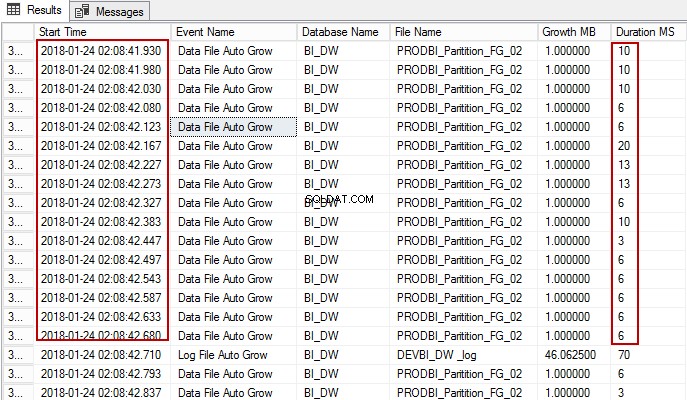
Przyjrzyjmy się, co oznacza każdy z terminów:
Zarezerwowane :Miejsce zarezerwowane do użytku przez obiekty bazy danych =(Dane +Indeks + Nieużywane ) =476704 + 1280 + 1312 =479296 KB. Wskazuje to, jak pełne są obiekty; idealnie, oczekuje się 10% niewykorzystanego miejsca na tabele transakcyjne.
Dane :Rzeczywisty rozmiar danych. Jest to suma wszystkich plików danych w bazie danych.
Indeks :Ilość miejsca zajmowanego przez indeks.
Uwaga:w niektórych przypadkach zauważyłem, że rozmiar indeksu jest większy niż rozmiar rzeczywistych danych. W przypadku indeksów to, co jest potrzebne systemowi, jest zawsze zależne od wydajności bazy danych. Często operacje odczytu są ważniejsze niż operacje zapisu. A w niektórych innych przypadkach pisanie jest ważniejsze niż czytanie. W przypadkach, w których firma zdecydowała, że odczyty są znacznie ważniejsze niż zapisy, system może potrzebować wielu indeksów, aby spełnić wymagania dotyczące wydajności firmy i użytkowników.
Nieużywane :część zarezerwowanej przestrzeni, która nie jest jeszcze używana
Nieużywane są strony w przydzielonych zakresach, ale nie są jeszcze używane przez żaden obiekt. Jak tylko ekstent zostanie przydzielony (jako ekstent jednolity lub współdzielony), otrzymujemy osiem stron zarezerwowanych na ten ekstent. Niektóre strony są używane, a inne nie.
nieużywane i nieprzydzielone kolumny w danych wyjściowych mogą być mylące. Aby wyjaśnić, nieużywane Dane wyjściowe kolumny nie pokazują ilości wolnego miejsca pozostałego w całej bazie danych. Jest to natomiast całkowita ilość miejsca zarezerwowanego dla tabel, ale niewypełnionego danymi. W wielu przypadkach niewykorzystane miejsce można odzyskać, tworząc indeks klastrowy lub zarządzając istniejącymi indeksami.
Dane wyjściowe sp_spaceused można dodatkowo uprościć, aby znaleźć rozmiar pliku .mdf i plików .log. Suma zarezerwowanego i nieprzydzielonego miejsca jest mniej więcej równa rozmiarowi pliku danych — lub pliku MDF. Ponadto odjęcie rozmiaru pliku MDF od rozmiaru bazy danych daje rozmiar pliku dziennika.
Oto dwie formuły:
Rozmiar pliku MDF =zarezerwowane + nieprzydzielone miejsce
Rozmiar pliku dziennika =Database_Size – Rozmiar pliku MDF
SELECT 476704+ 1280+ 1312 'Reserved KB', (479296/1024.00)+51.94 'MDFSizeMB', 848.00 - ((479296/1024.00)+51.94) 'LogSizeMB'
Wyżej wymienione punkty mówią nam, jak każda z kolumn w danych wyjściowych sp_spaceused jest interpretowana, obliczana i analizowana.
Wpływ ustawienia automatycznego wzrostu
Początkowe rozmiary i konfiguracja automatycznego wzrostu mają znaczący wpływ na niewykorzystaną przestrzeń. Ustalenie odpowiednich wartości to wyzwanie. Widziałem wiele przypadków, w których automatyczny wzrost miał rosnąć w procentach. Załóżmy, że automatyczny wzrost jest ustawiony na 25% dla pliku danych o rozmiarze 100 GB. Wystarczą tylko 4 zdarzenia automatycznego wzrostu, aby wypełnić dysk.
Drugim przypadkiem jest przebudowa indeksów. Ta operacja ma bezpośredni wpływ na niewykorzystane miejsce w tabeli, ponieważ dane są przetasowywane między zakresem jednolitym i mieszanym. W kilku przypadkach, podczas przetasowania stron, operacja może wywołać nieprzydzielone miejsce z powodu ustawienia automatycznego wzrostu pliku danych.
Rozważmy scenariusz, w którym ustawienie automatycznego wzrostu nie jest prawidłowo ustawione w bazie danych. To znowu problem:jeśli w bazie danych włączony jest automatyczny wzrost, oznacza to, że rozszerzenie dysku odbywa się automatycznie podczas jakiegoś zdarzenia, nawet jeśli dane nie zajmują całej przestrzeni.
Dobrą praktyką jest zawsze ustawienie odpowiedniego ustawienia automatycznego wzrostu dla pliku danych. Czasami nieprawidłowe ustawienie pliku danych może spowodować fizyczną fragmentację, powodując poważne pogorszenie wydajności systemu. Innymi słowy, jeśli nie masz nieprzydzielonego miejsca, nowe dane będą próbowały znajdować się w pustych lokalizacjach, które mogą być rozproszone. Dotyczy to również pliku dziennika. Nieprzydzielone miejsce w bazie danych pośrednio wpływa na ustawienie automatycznego wzrostu pliku danych i pliku dziennika oraz bezpośrednio wpływa na wydajność. Kluczem jest znalezienie właściwej równowagi.
Zawijanie
- W procesie tworzenia bazy danych, zdefiniowany rozmiar (tzn. jest rozmiarem początkowym) jest niczym innym jak rzeczywistym rozmiarem bazy danych. Ten początkowy rozmiar jest zapisywany w nagłówku strony. Podczas procesu zmniejszania bazy danych proces używa minimalnego rozmiaru jako odniesienie tylko wtedy, gdy rzeczywisty rozmiar danych jest mniejszy niż rozmiar minimalny — rozmiar minimalny znajduje się również w nagłówku strony i można go wyświetlić za pomocą polecenia DBCC PAGE. Ten sam proces jest również odpowiedni dla DBCC SHRINKFILE, który zmniejsza pliki do rozmiarów mniejszych niż ich początkowe rozmiary.
- Nie zaleca się zmniejszania bazy danych w celu zwolnienia miejsca na dysku, chociaż decyzja zależy od scenariusza — nietypowe scenariusze mogą uzasadniać niekonwencjonalne działanie. Należy jednak pamiętać, że zmniejszanie bazy danych powoduje fragmentację bazy danych. Zawsze dobrą praktyką jest przeanalizowanie pierwotnej przyczyny nieprzydzielonego miejsca i niewykorzystane miejsce obiektów. W wielu przypadkach rozszerzenie dysku w celu obsługi wzrostu ilości danych byłoby realną/zalecaną opcją.
- Konfiguracja automatycznego powiększania:gdy program SQL Server wykonuje operację automatycznego powiększania, transakcja, która wyzwoliła zdarzenie automatycznego powiększania, będzie musiała poczekać do zakończenia zdarzenia automatycznego powiększania. Tylko wtedy transakcja może zostać zakończona.
- Zawsze zaleca się ustawianie opcji automatycznego wzrostu w liczbach zamiast procentach.
- Indukcja niewykorzystanego miejsca w tabeli może wynikać z następujących przyczyn:
- Fragmentacja
Gdy dane są pofragmentowane ze względu na ich charakter i typ definicji, generowane jest niewykorzystane miejsce. Ponadto częsta modyfikacja danych (wszystkie operacje UPDATE, INSERT OR DELETE) prowadzi do większej liczby podziałów stron, co z większym prawdopodobieństwem generuje niewykorzystane miejsce w tabeli. - Brak indeksu klastrowego w tabeli
Aby zmniejszyć fragmentację na stercie, można pomyśleć o utworzeniu indeksu klastrowego na stole. Aby zmniejszyć fragmentację indeksu, wykonaj konserwację indeksu, określając wartość avg_fragmentation_in_percent. - Rozmiar danych
W niektórych przypadkach użycie odpowiednich typów danych daje mniejsze wiersze danych, co z kolei umożliwia umieszczenie większej liczby wierszy na stronie. Nie tylko zmniejsza wewnętrzną niewykorzystaną przestrzeń, ale ma również wpływ na wydajność, zmniejszając liczbę podziałów stron.
- Fragmentacja
- Niewykorzystane miejsce może być również wynikiem usunięcia kolumny o zmiennej długości. Użyj polecenia DBCC CLEANTABLE po wprowadzeniu znaczących zmian w kolumnach o zmiennej długości w tabeli lub widoku indeksowanym, aby natychmiast odzyskać nieużywane miejsce. Alternatywnie możesz odbudować indeksy w tabeli lub widoku; jednak jest to operacja bardziej wymagająca zasobów.
- Niewykorzystane miejsce jest stosunkowo większe, gdy ładujemy stosunkowo większe dane (>8 KB). W takich przypadkach kończymy z dużą ilością niewykorzystanego miejsca na stronach danych.
- Po migracji do SharePoint widać znaczną ilość niewykorzystanego miejsca wprowadzonego do baz danych. Odzyskiwanie jest wolniejszym procesem, proces czyszczenia ducha usuwa te strony, a zwolnienie następuje przez pewien czas.
- W niektórych przypadkach wartości sp_spaceused mogą być nieprawidłowe. Chociaż sp_spaceused pobiera informacje z obiektu systemowego, który przechowuje wszystkie oszacowania, czasami może być niedokładne. Jednym z powodów jest to, że podczas migracji bazy danych lub w przypadku nieaktualnych statystyk lub gdy system przechodzi częste modyfikacje DDL, lub po wykonaniu dużych operacji kopiowania zbiorczego. Aby zsynchronizować obiekty systemowe, użyj instrukcji DBCC updateusage(0) lub DBCC CHECKTABLE, aby upewnić się, że sp_spaceused zwraca aktualne dokładne dane. Należy jednak pamiętać, że polecenia DBCC wymagają dużej ilości zasobów; dobrze rozumieć konsekwencje jego użycia. Gdy wykonujemy polecenie DBCC updateusage, aparat bazy danych SQL Server skanuje strony danych w bazie danych i wprowadza niezbędne poprawki do sys.allocation_units i sys.partitions widoki katalogu dotyczące przestrzeni dyskowej używanej przez każdą tabelę.
Referencje
- https://msdn.microsoft.com/en-us/library/cc280360.aspx
- https://docs.microsoft.com/en-us/sql/t-sql/database-console-commands/dbcc-cleantable-transact-sql
- https://docs.microsoft.com/en-us/sql/relational-databases/system-catalog-views/sys-database-files-transact-sql