Dawno minęły czasy, kiedy baza danych była wdrażana jako pojedynczy węzeł lub instancja - potężny, samodzielny serwer, którego zadaniem było obsłużenie wszystkich żądań do bazy danych. Rozwiązaniem było skalowanie w pionie - zamień serwer na inny, jeszcze potężniejszy. W tych czasach nie trzeba było przejmować się wydajnością sieci. Dopóki napływały prośby, wszystko było dobrze.
Jednak obecnie bazy danych są budowane jako klastry z węzłami połączonymi siecią. Nie zawsze jest to szybka sieć lokalna. Ponieważ firmy osiągają skalę globalną, infrastruktura baz danych musi również obejmować cały świat, aby być blisko klientów i zmniejszać opóźnienia. Wiąże się to z dodatkowymi wyzwaniami, z którymi musimy się zmierzyć, projektując środowisko bazodanowe o wysokiej dostępności. W tym poście na blogu przyjrzymy się problemom z siecią, z którymi możesz się spotkać, i przedstawimy kilka sugestii, jak sobie z nimi radzić.
Dwie główne opcje dla MySQL lub MariaDB HA
Ten konkretny temat omówiliśmy dość obszernie w jednym z oficjalnych dokumentów, ale przyjrzyjmy się dwóm głównym sposobom budowania wysokiej dostępności dla MySQL i MariaDB.
Klaster Galera
Galera Cluster to wirtualnie synchroniczna technologia klastrowa dla MySQL. Pozwala budować konfiguracje wielu nagrywarek, które mogą obejmować cały świat. Galera doskonale sprawdza się w środowiskach o niskich opóźnieniach, ale można ją również skonfigurować do pracy z długimi połączeniami WAN. Galera ma wbudowany mechanizm kworum, który zapewnia, że dane nie zostaną naruszone w przypadku partycjonowania sieci niektórych węzłów.
Replikacja MySQL
Replikacja MySQL może być asynchroniczna lub półsynchroniczna. Oba są przeznaczone do budowania klastrów replikacji na dużą skalę. Podobnie jak w każdej innej konfiguracji replikacji master-slave lub podstawowej-wtórnej, może być tylko jeden zapisujący, master. Inne węzły, urządzenia podrzędne, są wykorzystywane do celów przełączania awaryjnego, ponieważ zawierają kopię zestawu danych z masera. Urządzenia podrzędne mogą być również używane do odczytywania danych i odciążania części obciążenia od urządzenia nadrzędnego.
Oba rozwiązania mają swoje ograniczenia i cechy, obydwa borykają się z różnymi problemami. Na oba mogą mieć wpływ niestabilne połączenia sieciowe. Rzućmy okiem na te ograniczenia i jak możemy zaprojektować środowisko, aby zminimalizować wpływ niestabilnej infrastruktury sieciowej.
Klaster Galera — problemy z siecią
Najpierw spójrzmy na klaster Galera. Jak wspomnieliśmy, działa najlepiej w środowisku o niskich opóźnieniach. Jednym z głównych problemów związanych z opóźnieniami w Galera jest sposób, w jaki Galera obsługuje zapisy. Nie będziemy omawiać wszystkich szczegółów w tym blogu, ale dalszą lekturę w naszym samouczku Galera Cluster for MySQL. Najważniejsze jest to, że ze względu na proces certyfikacji zapisów, w którym wszystkie węzły w klastrze muszą uzgodnić, czy można zastosować zapis, czy nie, wydajność zapisu dla pojedynczego wiersza jest ściśle ograniczona przez czas podróży w sieci między zapisami węzeł i najbardziej oddalony węzeł. Tak długo, jak opóźnienie jest akceptowalne i nie masz zbyt wielu hot spotów w swoich danych, konfiguracje WAN mogą działać dobrze. Problem zaczyna się, gdy opóźnienia w sieci od czasu do czasu rosną. Zapisy będą wtedy trwać 3 lub 4 razy dłużej niż zwykle, w wyniku czego bazy danych mogą zacząć być przeciążane długotrwałymi zapisami.
Jedną z wielkich cech Galera Cluster jest jego zdolność do wykrywania stanu klastra i reagowania na partycjonowanie sieci. Jeśli nie można uzyskać dostępu do węzła klastra, zostanie on usunięty z klastra i nie będzie mógł wykonywać żadnych zapisów. Ma to kluczowe znaczenie dla zachowania integralności danych w czasie podziału klastra — tylko większość klastra akceptuje zapisy. Mniejszość będzie narzekać. Aby sobie z tym poradzić, Galera wprowadza szeroką gamę kontroli i konfigurowalnych limitów czasu, aby uniknąć fałszywych alertów w przypadku bardzo przejściowych problemów z siecią. Niestety, jeśli sieć jest zawodna, Galera Cluster nie będzie mógł działać poprawnie - węzły zaczną wychodzić z klastra, dołączają do niego później. Będzie to szczególnie problematyczne, gdy mamy klaster Galera obejmujący sieć WAN – oddzielone części klastra mogą losowo zniknąć, jeśli sieć łącząca się nie będzie działać poprawnie.
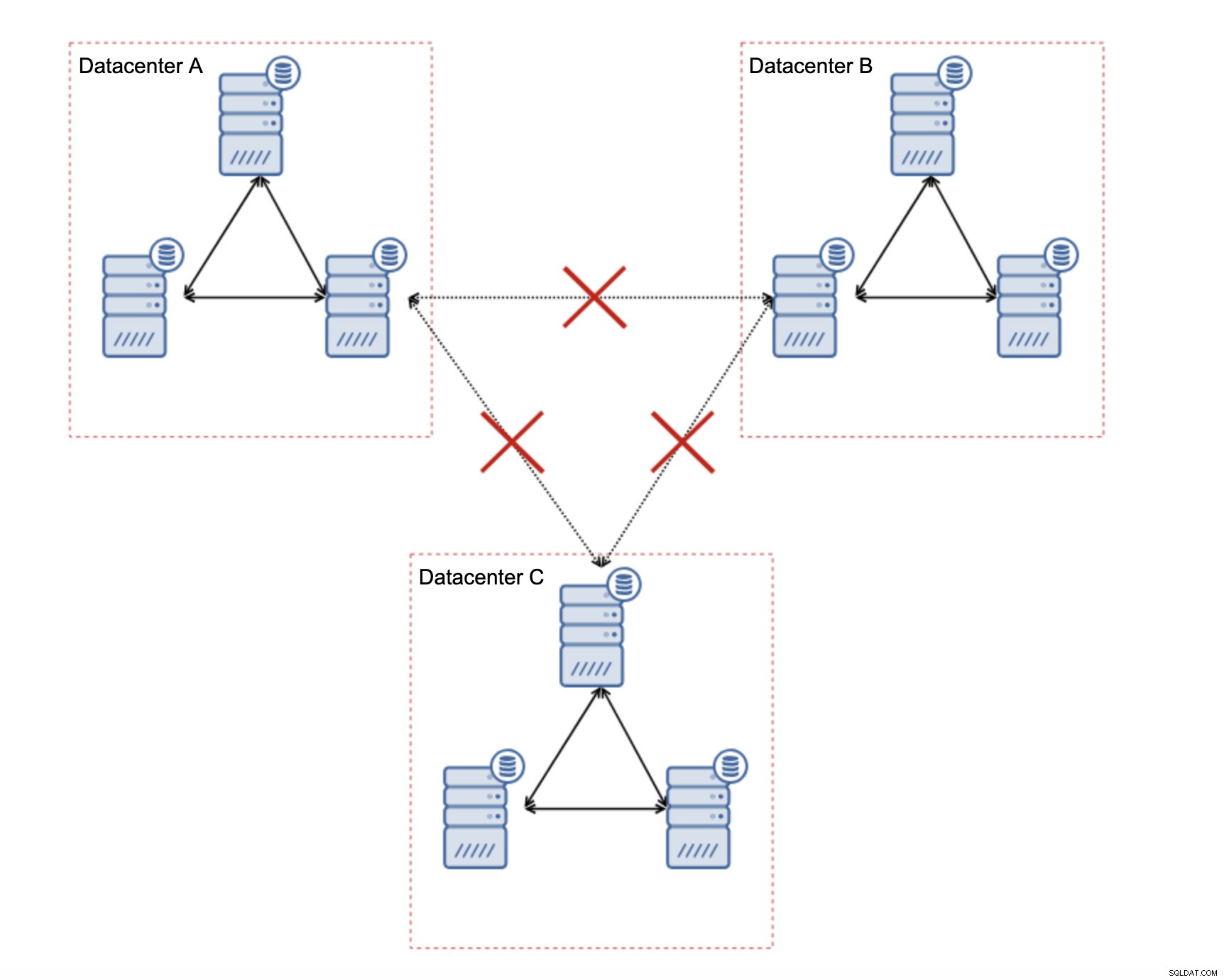
Jak zaprojektować klaster Galera dla niestabilnej sieci?
Po pierwsze, jeśli masz problemy z siecią w jednym centrum danych, niewiele możesz zrobić, chyba że będziesz w stanie jakoś rozwiązać te problemy. Nierzetelna sieć lokalna jest nie do pomyślenia dla Galera Cluster, trzeba rozważyć użycie innego rozwiązania (chociaż szczerze mówiąc, zawodna sieć zawsze będzie problematyczna). Z drugiej strony, jeśli problemy dotyczą tylko połączeń WAN (a jest to jeden z najbardziej typowych przypadków), możliwe jest zastąpienie łączy WAN Galera zwykłą replikacją asynchroniczną (jeśli nie pomogło dostrojenie Galera WAN).
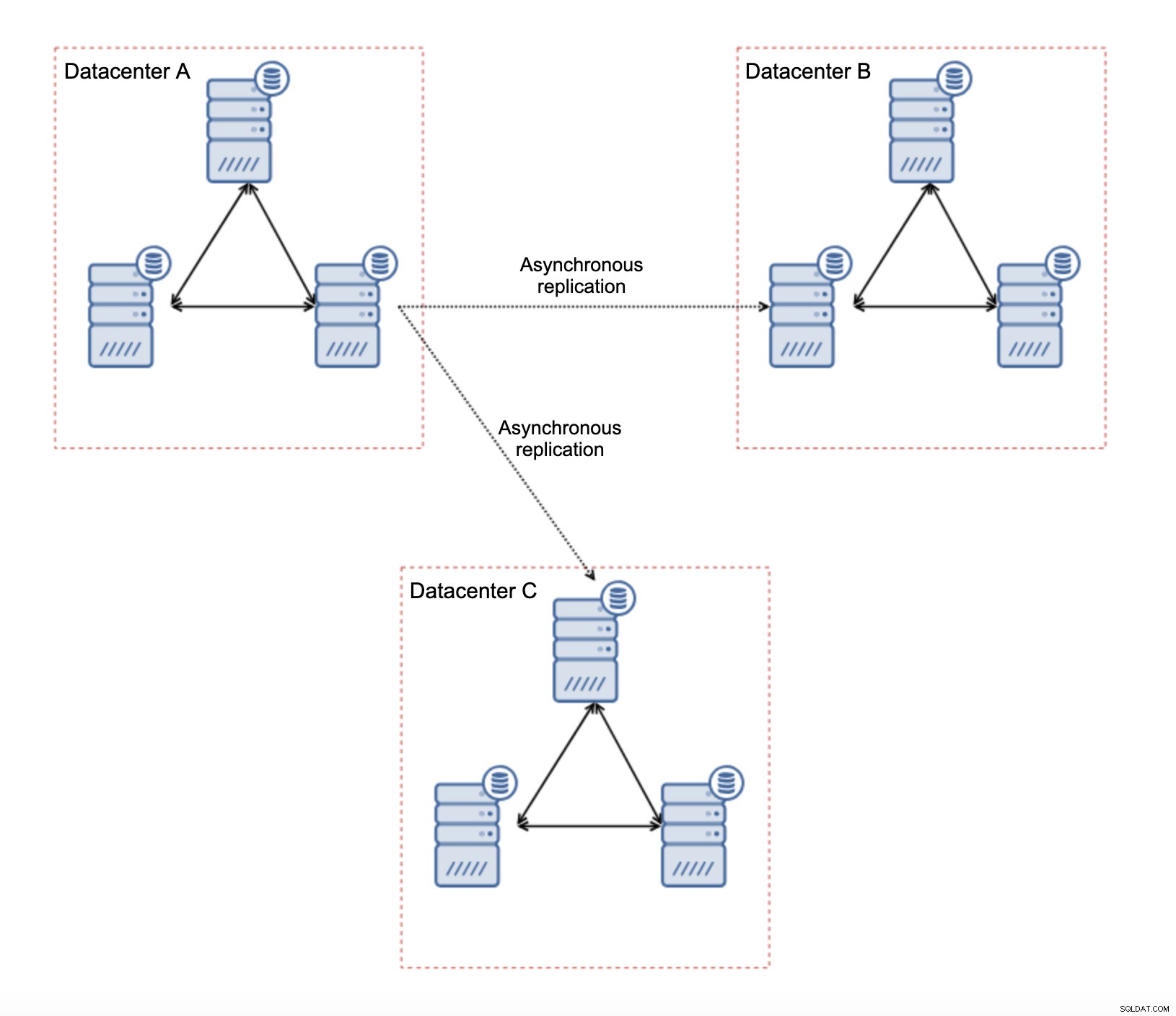
Ta konfiguracja ma kilka nieodłącznych ograniczeń — głównym problemem jest to, że zapisy miały miejsce lokalnie. Teraz wszystkie zapisy będą musiały trafić do „nadrzędnego” centrum danych (w naszym przypadku DC A). Nie jest tak źle, jak się wydaje. Należy pamiętać, że w środowisku zawierającym wyłącznie Galera zapis będzie spowolniony przez opóźnienia między węzłami znajdującymi się w różnych centrach danych. Nawet lokalne zapisy zostaną naruszone. Będzie to mniej więcej takie samo spowolnienie, jak w przypadku konfiguracji asynchronicznej, w której można wysyłać zapisy przez sieć WAN do „głównego” centrum danych.
Korzystanie z replikacji asynchronicznej wiąże się ze wszystkimi problemami typowymi dla replikacji asynchronicznej. Opóźnienie replikacji może stać się problemem – nie żeby Galera była bardziej wydajna, po prostu Galera spowolniłaby ruch poprzez kontrolę przepływu, podczas gdy replikacja nie ma żadnego mechanizmu do ograniczania ruchu na masterze.
Innym problemem jest przełączanie awaryjne:jeśli „główny” węzeł Galera (ten, który działa jako master dla slave w innych centrach danych) ulegnie awarii, należy stworzyć mechanizm przekierowujący slave'y do innego, działającego węzła master. Może to być jakiś skrypt, możliwe jest również wypróbowanie czegoś z VIP, gdzie „podrzędny” klaster Galera jest niewolnikiem wirtualnego adresu IP, który jest zawsze przypisany do aktywnego węzła Galera w klastrze „głównym”.
Główną zaletą takiej konfiguracji jest to, że usuwamy łącze WAN Galera, co oznacza, że nasz „główny” klaster nie zostanie spowolniony przez fakt, że niektóre węzły są odseparowane geograficznie. Jak wspomnieliśmy, tracimy możliwość zapisu we wszystkich centrach danych, ale zapis pod kątem opóźnień w sieci WAN jest taki sam, jak zapis lokalny w klastrze Galera, który obejmuje całą sieć WAN. W rezultacie ogólna latencja powinna się poprawić. Replikacja asynchroniczna jest również mniej podatna na niestabilne sieci. W najgorszym przypadku łącze replikacji zostanie przerwane i zostanie odtworzone, gdy sieci się zbiegną.
Jak zaprojektować replikację MySQL dla niestabilnej sieci?
W poprzedniej sekcji omówiliśmy klaster Galera, a jednym z rozwiązań było zastosowanie replikacji asynchronicznej. Jak to wygląda w zwykłej konfiguracji replikacji asynchronicznej? Przyjrzyjmy się, jak niestabilna sieć może powodować największe zakłócenia w konfiguracji replikacji.
Przede wszystkim latencja - jeden z głównych bolączek Galera Cluster. W przypadku replikacji prawie nie ma problemu. O ile nie używasz replikacji półsynchronicznej, czyli - w takim przypadku zwiększone opóźnienie spowolni zapisy. W replikacji asynchronicznej opóźnienie nie ma wpływu na wydajność zapisu. Może jednak mieć pewien wpływ na opóźnienie replikacji. Nie jest to nic tak znaczącego jak w przypadku Galery, ale możesz spodziewać się większych skoków opóźnień i ogólnie mniej stabilnej wydajności replikacji, jeśli sieć między węzłami cierpi na duże opóźnienia. Wynika to głównie z faktu, że master może równie dobrze obsługiwać kilka zapisów, zanim transfer danych do slave może zostać zainicjowany w sieci o dużym opóźnieniu.
Niestabilność sieci może z pewnością wpłynąć na łącza replikacji, ale znowu nie jest tak krytyczna. Urządzenia podrzędne MySQL spróbują ponownie połączyć się ze swoimi urządzeniami głównymi i rozpocznie się replikacja.
Głównym problemem związanym z replikacją MySQL jest coś, co Galera Cluster rozwiązuje wewnętrznie - partycjonowanie sieci. O partycjonowaniu sieci mówimy jako o stanie, w którym segmenty sieci są od siebie odseparowane. Replikacja MySQL wykorzystuje jeden węzeł zapisujący - master. Bez względu na to, jak zaprojektujesz swoje środowisko, musisz wysłać swoje zapisy do mistrza. Jeśli master nie jest dostępny (z jakichkolwiek powodów), aplikacja nie może wykonać swojej pracy, chyba że działa w trybie tylko do odczytu. Dlatego istnieje potrzeba jak najszybszego wyboru nowego mistrza. Tutaj pojawiają się problemy.
Po pierwsze, jak stwierdzić, który gospodarz jest mistrzem, a który nie. Jednym ze zwykłych sposobów jest użycie zmiennej „tylko do odczytu”, aby odróżnić urządzenia podrzędne od urządzenia nadrzędnego. Jeśli węzeł ma włączoną opcję tylko do odczytu (ustaw tylko do odczytu=1), jest urządzeniem podrzędnym (ponieważ urządzenia podrzędne nie powinny obsługiwać żadnych bezpośrednich zapisów). Jeśli węzeł ma wyłączoną opcję tylko do odczytu (ustaw tylko do odczytu=0), jest to węzeł nadrzędny. Aby było bezpieczniej, powszechnym podejściem jest ustawienie read_only=1 w konfiguracji MySQL - w przypadku restartu bezpieczniej jest, gdy węzeł pojawi się jako slave. Taki „język” może być rozumiany przez serwery proxy, takie jak ProxySQL czy MaxScale.
Rzućmy okiem na przykład.
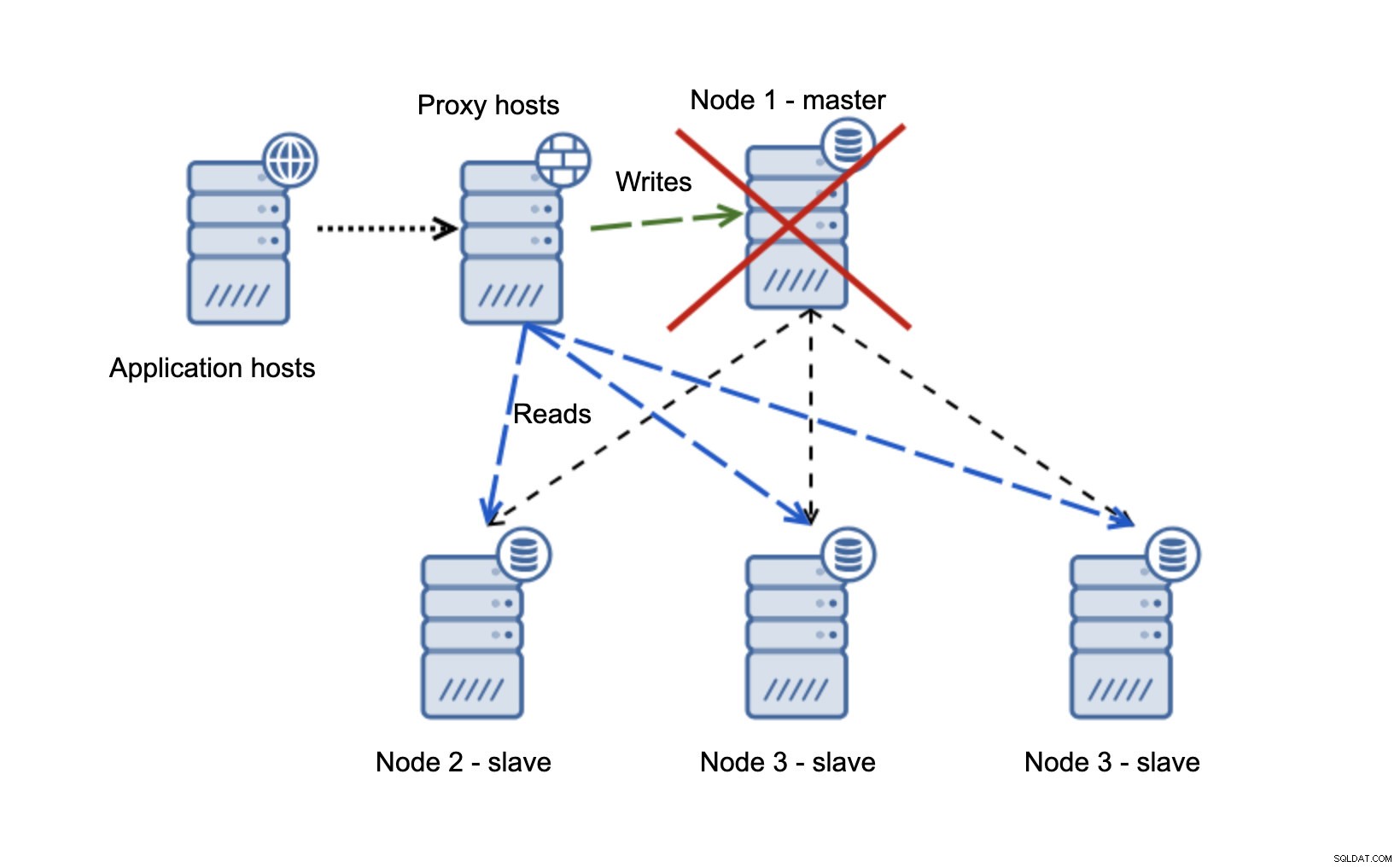
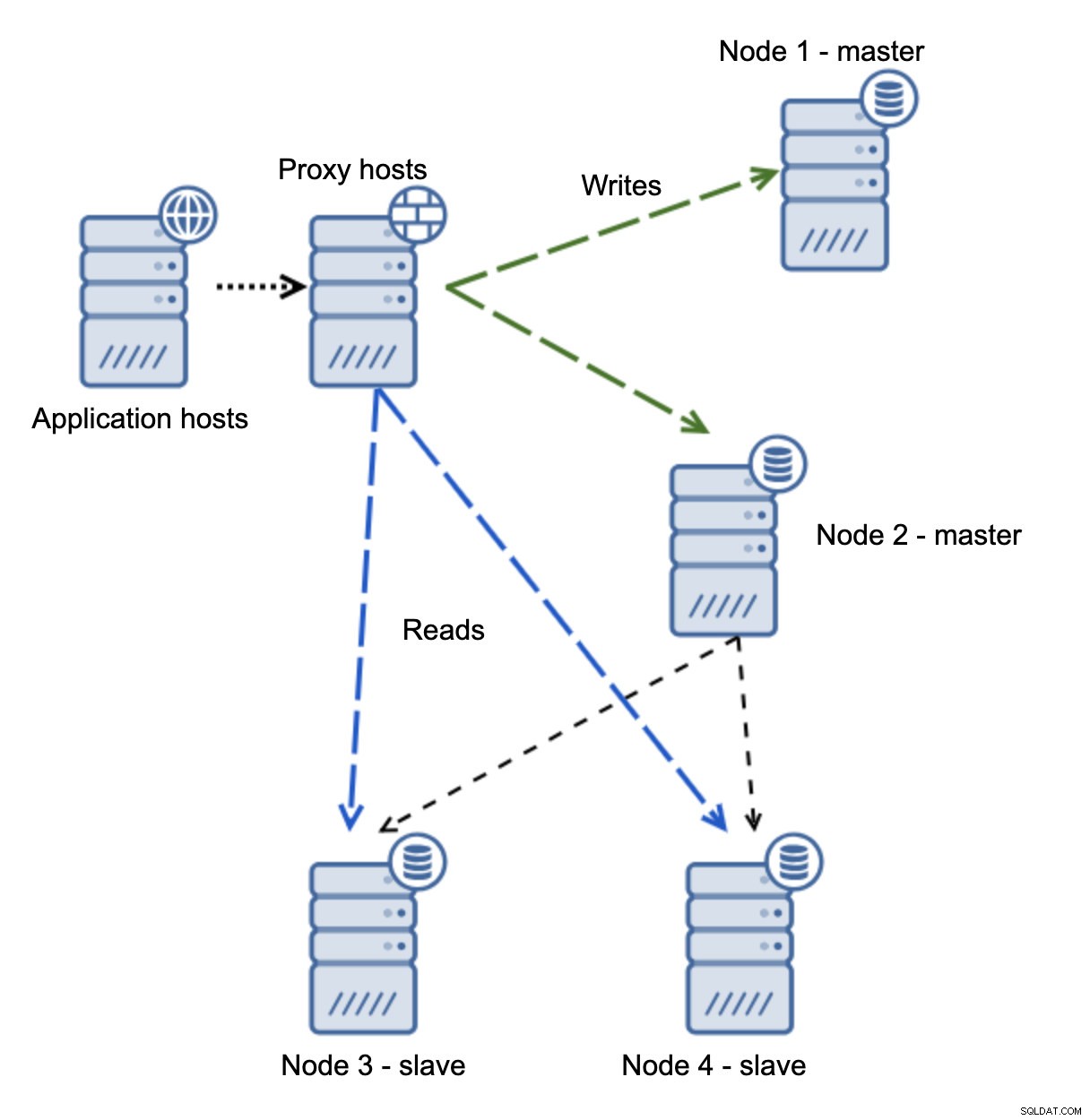
Mamy hosty aplikacji, które łączą się z warstwą proxy. Serwery proxy wykonują podział odczytu/zapisu, wysyłając SELECTy do urządzeń podrzędnych i zapisują do urządzenia nadrzędnego. Jeśli master nie działa, wykonywane jest przełączanie awaryjne, nowy master jest promowany, warstwa proxy to wykrywa i zaczyna wysyłać zapisy do innego węzła.
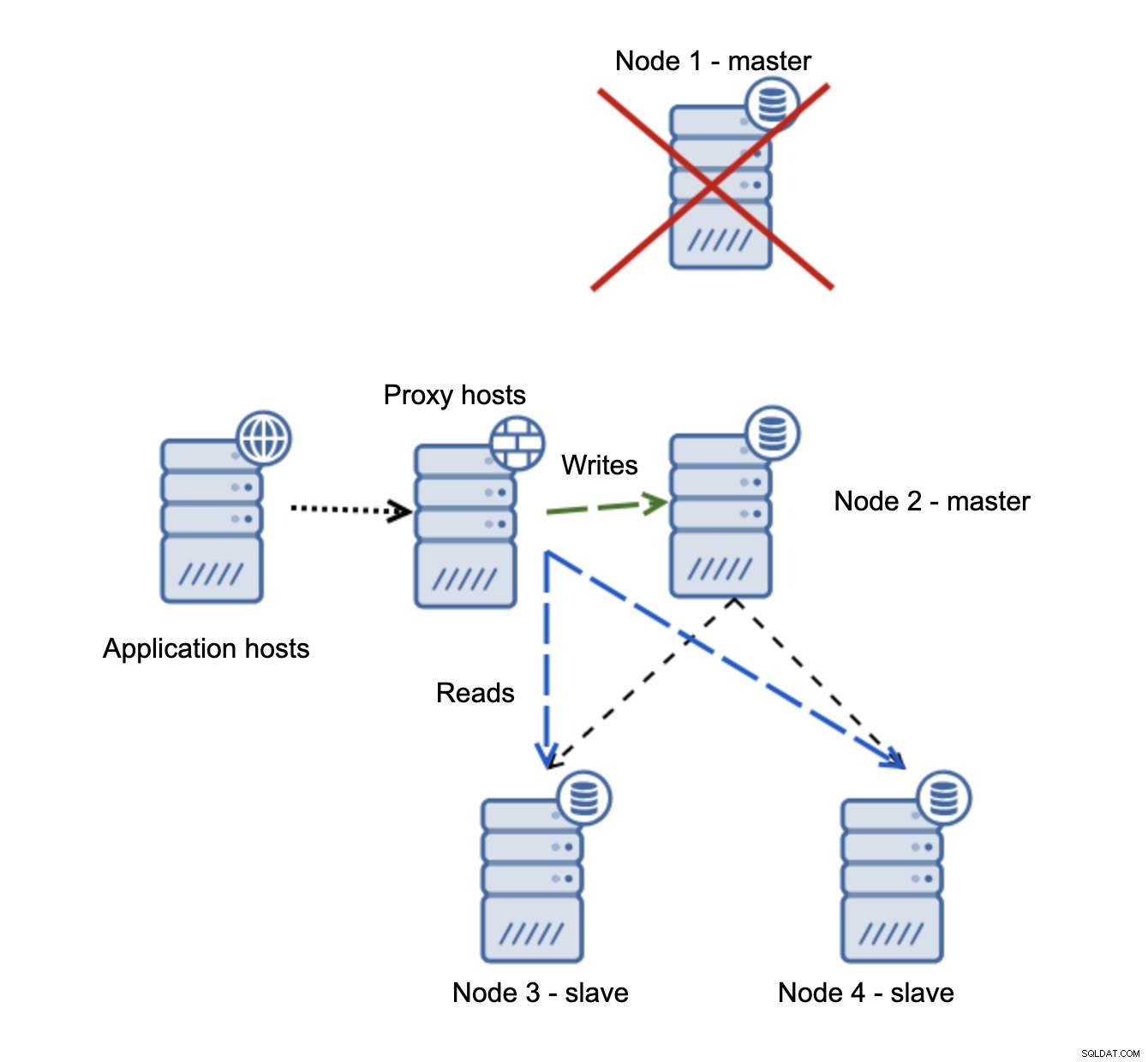
Jeśli node1 uruchomi się ponownie, pojawi się tylko do odczytu=1 i zostanie wykryty jako urządzenie podrzędne. Nie jest idealny, ponieważ nie powiela się, ale jest do zaakceptowania. W idealnym przypadku stary mistrz nie powinien się w ogóle pojawiać, dopóki nie zostanie odbudowany i podporządkowany nowemu mistrzowi.
O wiele bardziej problematyczna sytuacja jest, jeśli mamy do czynienia z partycjonowaniem sieci. Rozważmy tę samą konfigurację:warstwę aplikacji, warstwę proxy i bazy danych.
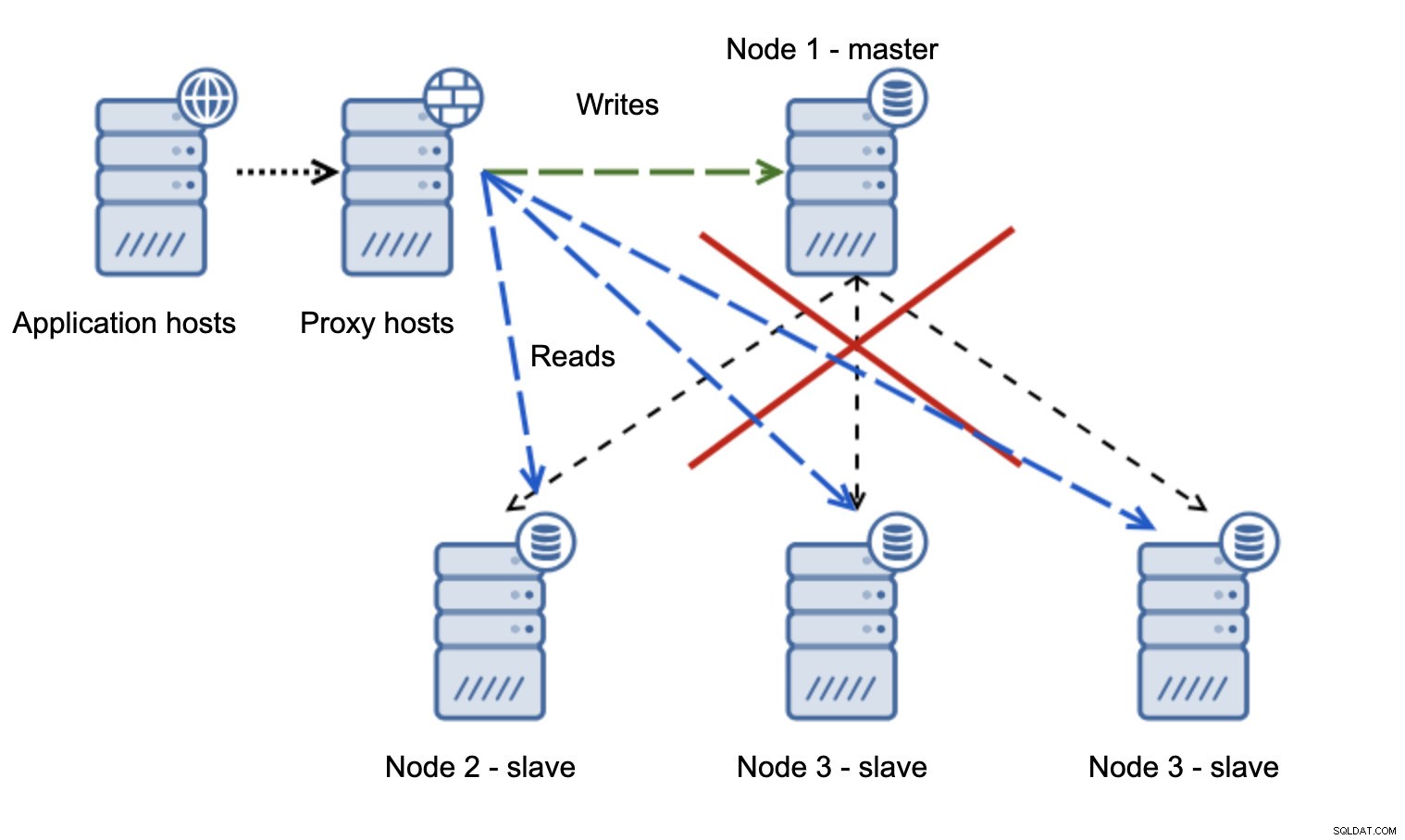
Gdy sieć sprawia, że master jest nieosiągalny, aplikacja nie nadaje się do użytku, ponieważ żadne zapisy nie docierają do miejsca docelowego. Awansuje nowego mistrza, przekierowuje do niego pisarzy. Co się wtedy stanie, jeśli problemy z siecią ustaną i stary master stanie się osiągalny? Nie został zatrzymany, dlatego nadal używa read_only=0:
Skończyłeś w rozszczepionym mózgu, kiedy zapisy były kierowane do dwóch węzłów. Ta sytuacja jest dość zła, ponieważ scalanie rozbieżnych zestawów danych może trochę potrwać i jest to dość złożony proces.
Co można zrobić, aby uniknąć tego problemu? Nie ma srebrnej kuli, ale można podjąć pewne działania, aby zminimalizować prawdopodobieństwo rozszczepienia mózgu.
Przede wszystkim możesz być mądrzejszy w wykrywaniu stanu mistrza. Jak widzą to niewolnicy? Czy mogą się z tego replikować? Być może niektóre urządzenia podrzędne nadal mogą połączyć się z urządzeniem nadrzędnym, co oznacza, że urządzenie nadrzędne działa lub przynajmniej umożliwia jego zatrzymanie, jeśli zajdzie taka potrzeba. A co z warstwą proxy? Czy wszystkie węzły proxy widzą master jako niedostępny? Jeśli niektórzy nadal mogą się połączyć, możesz spróbować wykorzystać te węzły do ssh do mastera i zatrzymać go przed przełączeniem awaryjnym?
Oprogramowanie do zarządzania pracą awaryjną może być również inteligentniejsze w wykrywaniu stanu sieci. Być może wykorzystuje RAFT lub inny protokół klastrowania do zbudowania klastra uwzględniającego kworum. Jeśli oprogramowanie do zarządzania przełączaniem awaryjnym może wykryć podzielony mózg, może również podjąć pewne działania w oparciu o to, na przykład ustawić wszystkie węzły w segmencie podzielonym na tylko do odczytu, zapewniając, że stary master nie będzie wyświetlany jako zapisywalny, gdy sieci się zbiegają.
Możesz również dołączyć narzędzia takie jak Consul lub Etcd do przechowywania stanu klastra. Warstwę proxy można skonfigurować tak, aby używała danych z Consul, a nie stanu zmiennej tylko do odczytu. Wtedy oprogramowanie do zarządzania pracą awaryjną będzie musiało wprowadzić niezbędne zmiany w Consul, tak aby wszystkie serwery proxy wysyłały ruch do prawidłowego, nowego mastera.
Niektóre z tych wskazówek można nawet połączyć, aby wykrywanie awarii było jeszcze bardziej niezawodne. Podsumowując, możliwe jest zminimalizowanie szans, że klaster replikacji ucierpi z powodu zawodnych sieci.
Jak widać, nieważne, czy mówimy o Galera, czy MySQL Replication, niestabilne sieci mogą stać się poważnym problemem. Z drugiej strony, jeśli poprawnie zaprojektujesz środowisko, nadal możesz sprawić, by działało. Mamy nadzieję, że ten wpis na blogu pomoże Ci stworzyć środowiska, które będą działać stabilnie, nawet jeśli sieci nie są.