Strategia indeksowania tabel jest jednym z najważniejszych kluczy dostrajania i optymalizacji wydajności. W SQL Server indeksy (zarówno klastrowe, jak i nieklastrowe) są tworzone przy użyciu struktury B-drzewa, w której każda strona działa jako podwójnie połączony węzeł listy, zawierający informacje o poprzedniej i następnej stronie. Ta struktura B-drzewa, zwana Forward Scan, ułatwia odczytywanie wierszy z indeksu poprzez skanowanie lub wyszukiwanie jego stron od początku do końca. Chociaż skanowanie do przodu jest domyślną i powszechnie znaną metodą skanowania indeksów, SQL Server zapewnia nam możliwość skanowania wierszy indeksu w strukturze B-drzewa od końca do początku. Ta umiejętność nazywa się Skanem Wstecznym. W tym artykule zobaczymy, jak to się dzieje i jakie są zalety i wady metody skanowania wstecznego.
SQL Server daje nam możliwość odczytywania danych z indeksu tabeli poprzez skanowanie węzłów struktury B-drzewa od początku do końca metodą Forward Scan lub odczytywanie węzłów struktury drzewa B od końca do początku za pomocą Metoda skanowania wstecznego. Jak sama nazwa wskazuje, skanowanie wstecz jest wykonywane przy odczycie odwrotnym do kolejności kolumny zawartej w indeksie, co jest realizowane za pomocą opcji DESC w instrukcji sortującej ORDER BY T-SQL, która określa kierunek operacji skanowania.
W określonych sytuacjach SQL Server Engine stwierdza, że odczytywanie danych indeksu od końca do początku przy użyciu metody skanowania wstecz jest szybsze niż odczytywanie ich w normalnej kolejności przy użyciu metody skanowania w przód, co może wymagać kosztownego procesu sortowania przez SQL Silnik. Takie przypadki obejmują użycie funkcji agregującej MAX() i sytuacje, w których sortowanie wyników zapytania jest przeciwne do kolejności indeksu. Główną wadą metody skanowania wstecznego jest to, że SQL Server Query Optimizer zawsze wybierze wykonanie go przy użyciu wykonania planu szeregowego, bez możliwości czerpania korzyści z planów wykonania równoległego.
Załóżmy, że mamy poniższą tabelę, która będzie zawierała informacje o pracownikach firmy. Tabelę można utworzyć za pomocą poniższej instrukcji T-SQL CREATE TABLE:
CREATE TABLE [dbo].[CompanyEmployees](
[ID] [INT] IDENTITY (1,1) ,
[EmpID] [int] NOT NULL,
[Emp_First_Name] [nvarchar](50) NULL,
[Emp_Last_Name] [nvarchar](50) NULL,
[EmpDepID] [int] NOT NULL,
[Emp_Status] [int] NOT NULL,
[EMP_PhoneNumber] [nvarchar](50) NULL,
[Emp_Adress] [nvarchar](max) NULL,
[Emp_EmploymentDate] [DATETIME] NULL,
PRIMARY KEY CLUSTERED
(
[ID] ASC
)ON [PRIMARY]))
Po utworzeniu tabeli wypełnimy ją fikcyjnymi rekordami 10K, korzystając z poniższej instrukcji INSERT:
INSERT INTO [dbo].[CompanyEmployees]
([EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate])
VALUES
(1,'AAA','BBB',4,1,9624488779,'AMM','2006-10-15')
GO 10000 Jeśli wykonamy poniższą instrukcję SELECT w celu pobrania danych z wcześniej utworzonej tabeli, wiersze zostaną posortowane zgodnie z wartościami kolumn ID w kolejności rosnącej, czyli takiej samej jak kolejność indeksów klastrowanych:
SELECT [ID]
,[EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate]
FROM [SQLShackDemo].[dbo].[CompanyEmployees]
ORDER BY [ID] ASC
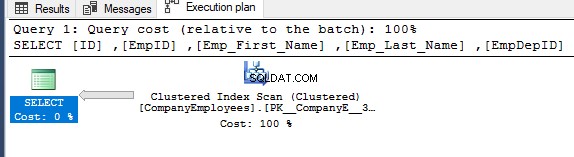
Następnie sprawdzając plan wykonania dla tego zapytania, zostanie wykonane skanowanie indeksu klastrowego w celu uzyskania posortowanych danych z indeksu, jak pokazano w poniższym planie wykonania:
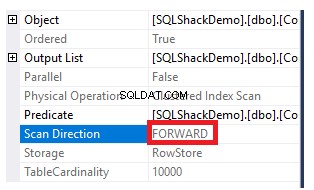
Aby uzyskać kierunek skanowania wykonywanego na indeksie klastrowym, kliknij prawym przyciskiem myszy węzeł skanowania indeksu, aby przejrzeć właściwości węzła. We właściwościach węzła Skanowanie indeksu klastrowego, właściwość Kierunek skanowania wyświetli kierunek skanowania, które jest wykonywane na indeksie w ramach tego zapytania, czyli Skanowanie do przodu, jak pokazano na poniższym obrazku:
Kierunek skanowania indeksu można również pobrać z planu wykonania XML z właściwości ScanDirection w węźle IndexScan, jak pokazano poniżej:

Załóżmy, że musimy pobrać maksymalną wartość identyfikatora z utworzonej wcześniej tabeli CompanyEmployees, korzystając z poniższego zapytania T-SQL:
SELECT MAX([ID]) FROM [dbo].[CompanyEmployees]
Następnie przejrzyj plan wykonania wygenerowany w wyniku wykonania tego zapytania. Zobaczysz, że skanowanie zostanie wykonane na indeksie klastrowym, jak pokazano w poniższym planie wykonania:
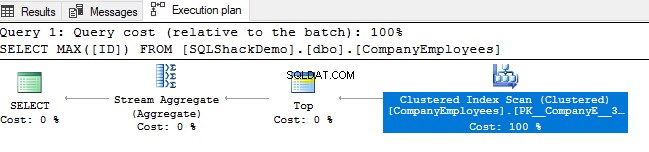
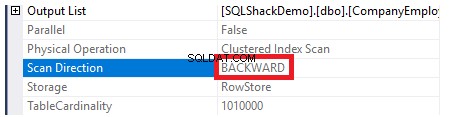
Aby sprawdzić kierunek skanowania indeksu, przejrzymy właściwości węzła Clustered Index Scan. Wynik pokaże nam, że silnik SQL Server woli skanować indeks klastrowany od końca do początku, co w tym przypadku będzie szybsze, aby uzyskać maksymalną wartość kolumny ID, ze względu na fakt, że indeks jest już posortowany według kolumny ID, jak pokazano poniżej:
Ponadto, jeśli spróbujemy pobrać wcześniej utworzone dane tabeli za pomocą poniższej instrukcji SELECT, rekordy zostaną posortowane według wartości kolumn ID, ale tym razem w przeciwieństwie do kolejności indeksów klastrowanych, poprzez określenie opcji sortowania DESC w ORDER Klauzula BY pokazana poniżej:
SELECT [ID]
,[EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate]
FROM [SQLShackDemo].[dbo].[CompanyEmployees]
ORDER BY [ID] DESC
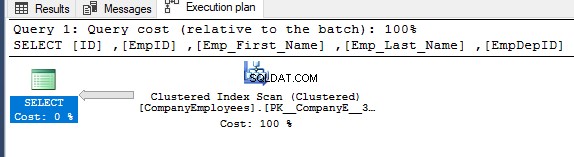
Jeśli sprawdzisz plan wykonania wygenerowany po wykonaniu poprzedniego zapytania SELECT, zobaczysz, że zostanie wykonane skanowanie indeksu klastrowego w celu uzyskania żądanych rekordów tabeli, jak pokazano poniżej:
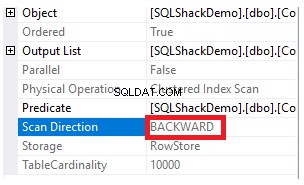
Właściwości węzła Skanowanie indeksu klastrowego pokażą, że kierunek skanowania preferowany przez silnik SQL Server to kierunek skanowania wstecznego, który w tym przypadku jest szybszy ze względu na sortowanie danych przeciwne do rzeczywistego sortowania indeksu klastrowego, biorąc pod uwagę, że indeks jest już posortowany w porządku rosnącym zgodnie z kolumną ID, jak pokazano poniżej:
Porównanie wydajności
Załóżmy, że mamy poniższe instrukcje SELECT, które pobierają informacje o wszystkich pracownikach, którzy zostali zatrudnieni od 2010 roku, dwa razy; za pierwszym razem zwrócony zestaw wyników zostanie posortowany w kolejności rosnącej zgodnie z wartościami kolumny ID, a za drugim razem zwrócony zestaw wyników zostanie posortowany w kolejności malejącej zgodnie z wartościami kolumny ID przy użyciu poniższych instrukcji T-SQL:
SELECT [ID]
,[EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate]
FROM [SQLShackDemo].[dbo].[CompanyEmployees]
WHERE Emp_EmploymentDate >='2010-01-01'
ORDER BY [ID] ASC
OPTION (MAXDOP 1)
GO
SELECT [ID]
,[EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate]
FROM [SQLShackDemo].[dbo].[CompanyEmployees]
WHERE Emp_EmploymentDate >='2010-01-01'
ORDER BY [ID] DESC
OPTION (MAXDOP 1)
GO
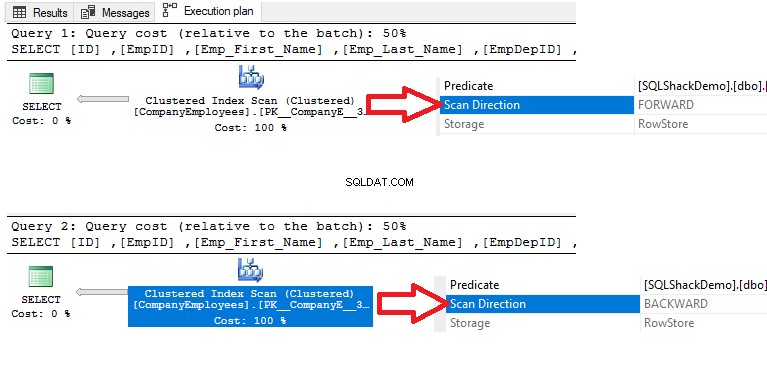
Sprawdzając plany wykonania, które są generowane przez wykonanie dwóch zapytań SELECT, wynik pokaże, że w dwóch zapytaniach zostanie wykonane skanowanie indeksu klastrowego w celu pobrania danych, ale kierunek skanowania w pierwszym zapytaniu będzie Forward Skanuj ze względu na sortowanie danych ASC i Skanuj wstecz w drugim zapytaniu ze względu na użycie sortowania danych DESC, aby zastąpić potrzebę ponownego uporządkowania danych, jak pokazano poniżej:
Ponadto, jeśli sprawdzimy statystyki wykonania IO i TIME dla dwóch zapytań, zobaczymy, że oba zapytania wykonują te same operacje IO i zużywają bliskie wartości wykonania i czasu procesora.
Wartości te pokazują nam, jak sprytny jest silnik SQL Server podczas wybierania najbardziej odpowiedniego i najszybszego kierunku skanowania indeksu w celu pobrania danych dla użytkownika, czyli do przodu w pierwszym przypadku i do tyłu w drugim przypadku, co jasno wynika z poniższych statystyk :

Przejdźmy ponownie do poprzedniego przykładu MAX. Załóżmy, że musimy pobrać maksymalny identyfikator pracowników, którzy zostali zatrudnieni w 2010 roku i później. W tym celu użyjemy następujących instrukcji SELECT, które posortują odczytane dane zgodnie z wartością kolumny ID z sortowaniem ASC w pierwszym zapytaniu i sortowaniem DESC w drugim zapytaniu:
SELECT MAX([Emp_EmploymentDate]) FROM [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate] >='2017-01-01' GROUP BY ID ORDER BY [ID] ASC OPTION (MAXDOP 1) GO SELECT MAX([Emp_EmploymentDate]) FROM [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate] >='2017-01-01' GROUP BY ID ORDER BY [ID] DESC OPTION (MAXDOP 1) GO
Na podstawie planów wykonania wygenerowanych na podstawie wykonania dwóch instrukcji SELECT zobaczysz, że oba zapytania wykonają operację skanowania na indeksie klastrowym, aby pobrać maksymalną wartość identyfikatora, ale w różnych kierunkach skanowania; Forward Scan w pierwszym zapytaniu i Backward Scan w drugim zapytaniu, ze względu na opcje sortowania ASC i DESC, jak pokazano poniżej:
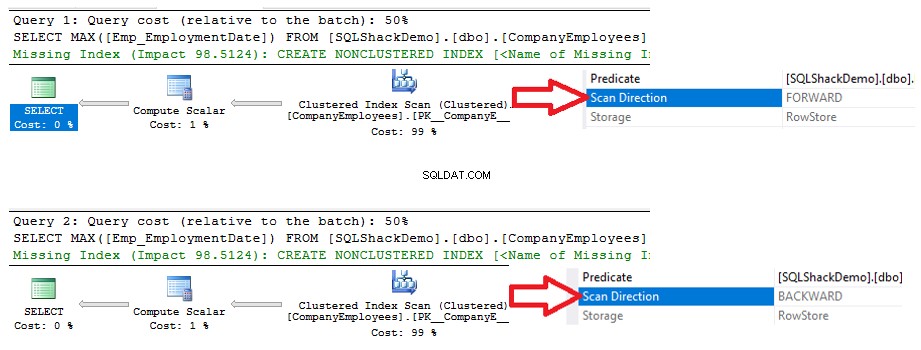
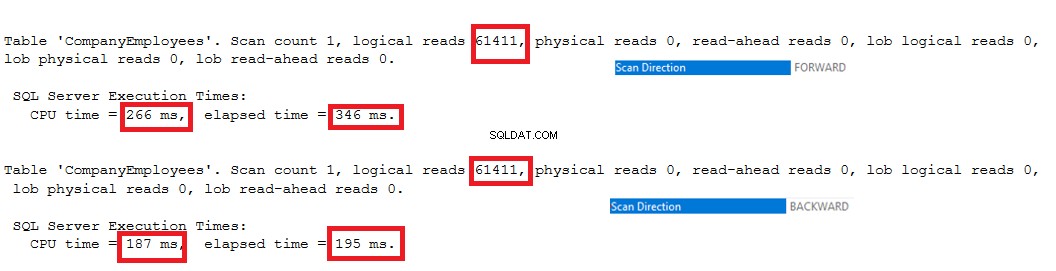
Statystyki IO wygenerowane przez te dwa zapytania nie pokażą żadnej różnicy między dwoma kierunkami skanowania. Jednak statystyki CZASU pokazują dużą różnicę między obliczaniem maksymalnego ID wierszy, gdy wiersze te są skanowane od początku do końca przy użyciu metody Forward Scan, a skanowaniem od końca do początku przy użyciu metody Backward Scan. Z poniższego wyniku jasno wynika, że metoda skanowania wstecznego jest optymalną metodą skanowania w celu uzyskania maksymalnej wartości identyfikatora:
Optymalizacja wydajności
Jak wspomniałem na początku tego artykułu, indeksowanie zapytań jest najważniejszym kluczem w procesie dostrajania i optymalizacji wydajności. W poprzednim zapytaniu, jeśli zorganizujemy dodanie indeksu nieklastrowego w kolumnie EmploymentDate tabeli CompanyEmployees, korzystając z poniższej instrukcji T-SQL CREATE INDEX:
CREATE NONCLUSTERED INDEX IX_CompanyEmployees_Emp_EmploymentDate ON CompanyEmployees (Emp_EmploymentDate) After that, we will execute the same previous queries as shown below: SELECT MAX([Emp_EmploymentDate]) FROM [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate] >='2017-01-01' GROUP BY ID ORDER BY [ID] ASC OPTION (MAXDOP 1) GO SELECT MAX([Emp_EmploymentDate]) FROM [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate] >='2017-01-01' GROUP BY ID ORDER BY [ID] DESC OPTION (MAXDOP 1) GO
Sprawdzając plany wykonania wygenerowane po wykonaniu dwóch zapytań, zobaczysz, że zostanie wykonane wyszukiwanie na nowo utworzonym indeksie nieklastrowym, a oba zapytania przeskanują indeks od początku do końca metodą Forward Scan, bez potrzeby wykonać skanowanie wsteczne, aby przyspieszyć pobieranie danych, chociaż w drugim zapytaniu użyliśmy opcji sortowania DESC. Było to spowodowane bezpośrednim wyszukiwaniem indeksu bez konieczności wykonywania pełnego skanowania indeksu, jak pokazano w porównaniu planów wykonania poniżej:
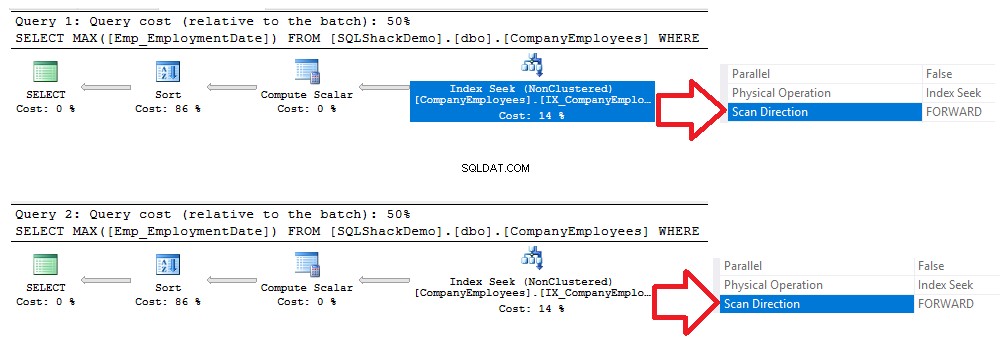
Ten sam wynik można uzyskać ze statystyk IO i TIME wygenerowanych z poprzednich dwóch zapytań, gdzie dwa zapytania będą zużywać taką samą ilość czasu wykonania, operacji CPU i IO, z bardzo małą różnicą, jak pokazano na poniższym zrzucie statystyk :

Przydatne linki:
- Opisane indeksy klastrowe i nieklastrowe
- Utwórz indeksy nieklastrowane
- Dostrajanie wydajności serwera SQL:skanowanie wstecz indeksu
Przydatne narzędzie:
dbForge Index Manager – poręczny dodatek SSMS do analizy stanu indeksów SQL i rozwiązywania problemów z fragmentacją indeksów.