Jeśli chodzi o wydajność, int jest szybszy w prawie wszystkich przypadkach. Procesor został zaprojektowany do wydajnej pracy z wartościami 32-bitowymi.
Z krótszymi wartościami trudno sobie poradzić. Aby odczytać pojedynczy bajt, powiedzmy, procesor musi odczytać 32-bitowy blok, który go zawiera, a następnie zamaskować górne 24 bity.
Aby zapisać bajt, musi odczytać docelowy 32-bitowy blok, nadpisać dolne 8 bitów żądaną wartością bajtu i ponownie zapisać cały 32-bitowy blok.
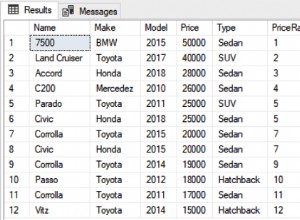
Oczywiście, jeśli chodzi o przestrzeń, oszczędzasz kilka bajtów, używając mniejszych typów danych. Jeśli więc budujesz tabelę z kilkoma milionami wierszy, warto rozważyć krótsze typy danych. (To samo może być dobrym powodem, dla którego powinieneś używać mniejszych typów danych w swojej bazie danych)
A jeśli chodzi o poprawność, int łatwo się nie przelewa. Co jeśli myślisz Twoja wartość zmieści się w jednym bajcie, a potem w pewnym momencie w przyszłości jakaś nieszkodliwa zmiana w kodzie oznacza, że zostaną w niej zapisane większe wartości?
To są niektóre z powodów, dla których int powinien być domyślnym typem danych dla wszystkich danych integralnych. Używaj byte tylko wtedy, gdy faktycznie chcesz przechowywać bajty maszynowe. Używaj skrótów tylko wtedy, gdy masz do czynienia z formatem pliku, protokołem lub podobnym, który faktycznie określa 16-bitowe wartości całkowite. Jeśli masz do czynienia tylko z liczbami całkowitymi w ogóle, ustaw je jako int.