Istnieją dwie uzupełniające się umiejętności, które są bardzo przydatne podczas dostrajania zapytań. Jednym z nich jest umiejętność czytania i interpretowania planów wykonawczych. Druga to wiedza o tym, jak działa optymalizator zapytań, aby przetłumaczyć tekst SQL na plan wykonania. Połączenie tych dwóch rzeczy może pomóc nam wykryć sytuacje, w których oczekiwana optymalizacja nie została zastosowana, co powoduje, że plan wykonania nie jest tak wydajny, jak mógłby być. Brak dokumentacji na temat tego, które dokładnie optymalizacje SQL Server może zastosować (i w jakich okolicznościach) oznacza, że wiele z tego sprowadza się jednak do doświadczenia.
Przykład
Przykładowe zapytanie do tego artykułu jest oparte na pytaniu zadanym kilka miesięcy temu przez SQL Server MVP Fabiano Amorim, w oparciu o rzeczywisty problem, z którym się zetknął. Poniższy schemat i zapytanie testowe jest uproszczeniem rzeczywistej sytuacji, ale zachowuje wszystkie ważne cechy.
CREATE TABLE dbo.T1 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T2 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T3 (pk integer PRIMARY KEY, c1 integer NOT NULL);
GO
CREATE INDEX nc1 ON dbo.T1 (c1);
CREATE INDEX nc1 ON dbo.T2 (c1);
CREATE INDEX nc1 ON dbo.T3 (c1);
GO
CREATE VIEW dbo.V1
AS
SELECT c1 FROM dbo.T1
UNION ALL
SELECT c1 FROM dbo.T2
UNION ALL
SELECT c1 FROM dbo.T3;
GO
-- The test query
SELECT MAX(c1)
FROM dbo.V1; Test 1 – 10 000 wierszy, SQL Server 2005+
Konkretne dane tabeli nie mają tak naprawdę znaczenia w tych testach. Poniższe zapytania po prostu ładują 10 000 wierszy z tabeli liczb do każdej z trzech tabel testowych:
INSERT dbo.T1 (pk, c1) SELECT n, n FROM dbo.Numbers AS N WHERE n BETWEEN 1 AND 10000; INSERT dbo.T2 (pk, c1) SELECT pk, c1 FROM dbo.T1; INSERT dbo.T3 (pk, c1) SELECT pk, c1 FROM dbo.T1;
Po załadowaniu danych plan wykonania utworzony dla zapytania testowego to:
SELECT MAX(c1) FROM dbo.V1;
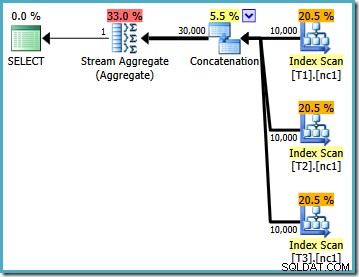
Ten plan wykonania jest dość bezpośrednią implementacją logicznego zapytania SQL (po rozwinięciu odwołania widoku V1). Optymalizator widzi zapytanie po rozwinięciu widoku, prawie tak, jakby zapytanie zostało napisane w całości:
SELECT MAX(c1)
FROM
(
SELECT c1 FROM dbo.T1
UNION ALL
SELECT c1 FROM dbo.T2
UNION ALL
SELECT c1 FROM dbo.T3
) AS V1;
Porównując tekst rozszerzony do planu wykonania, bezpośredniość implementacji optymalizatora zapytań jest jasna. Istnieje skanowanie indeksu dla każdego odczytu tabel podstawowych, operator konkatenacji do implementacji UNION ALL i Stream Aggregate dla końcowego MAX agregat.
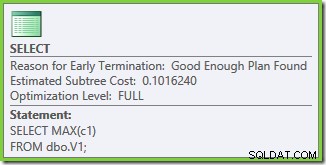
Właściwości planu wykonania pokazują, że rozpoczęto optymalizację opartą na kosztach (poziom optymalizacji to FULL ), ale zakończyła się wcześnie, ponieważ znaleziono „wystarczająco dobry” plan. Szacowany koszt wybranego planu to 0,1016240 magiczne jednostki optymalizujące.
Test 2 – 50 000 wierszy, SQL Server 2008 i 2008 R2
Uruchom następujący skrypt, aby zresetować środowisko testowe do uruchamiania z 50 000 wierszami:
TRUNCATE TABLE dbo.T1; TRUNCATE TABLE dbo.T2; TRUNCATE TABLE dbo.T3; INSERT dbo.T1 (pk, c1) SELECT n, n FROM dbo.Numbers AS N WHERE n BETWEEN 1 AND 50000; INSERT dbo.T2 (pk, c1) SELECT pk, c1 FROM dbo.T1; INSERT dbo.T3 (pk, c1) SELECT pk, c1 FROM dbo.T1; SELECT MAX(c1) FROM dbo.V1;
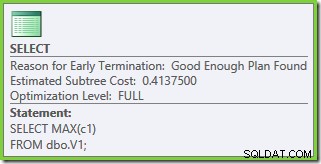
Plan wykonania tego testu zależy od używanej wersji programu SQL Server. W SQL Server 2008 i 2008 R2 otrzymujemy następujący plan:
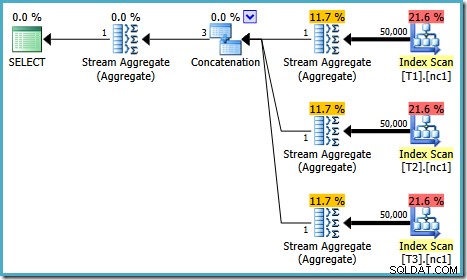
Właściwości planu pokazują, że optymalizacja oparta na kosztach nadal zakończyła się wcześnie z tego samego powodu, co poprzednio. Szacowany koszt jest wyższy niż wcześniej i wynosi 0,41375 jednostek, ale jest to oczekiwane ze względu na wyższą kardynalność tabel podstawowych.
Test 3 – 50 000 wierszy, SQL Server 2005 i 2012
To samo zapytanie uruchomione w 2005 lub 2012 daje inny plan wykonania:
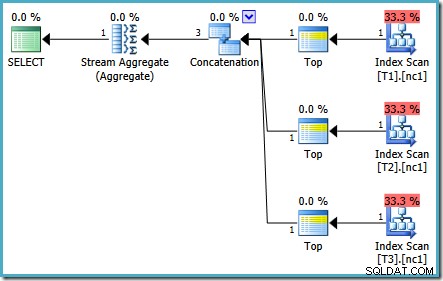
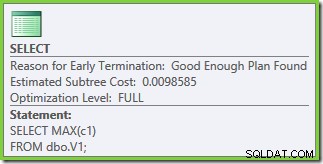
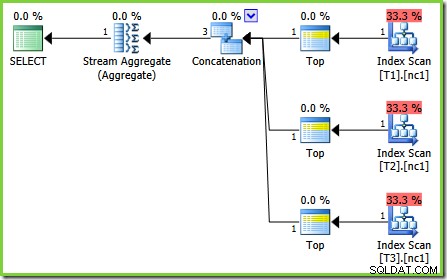
Optymalizacja została ponownie zakończona wcześniej, ale szacowany koszt planu dla 50 000 wierszy na tabelę podstawową spadł do 0,0098585 (od 0.41375 na SQL Server 2008 i 2008 R2).
Wyjaśnienie
Jak być może wiesz, optymalizator zapytań SQL Server dzieli wysiłek związany z optymalizacją na wiele etapów, przy czym późniejsze etapy dodają więcej technik optymalizacji i pozwalają na więcej czasu. Etapy optymalizacji to:
- Plan trywialny
- Optymalizacja oparta na kosztach
- Przetwarzanie transakcji (wyszukaj 0)
- Szybki plan (wyszukaj 1)
- Szybki plan z włączoną równoległością
- Pełna optymalizacja (wyszukiwanie 2)
Żaden z przeprowadzonych tutaj testów nie kwalifikuje się do trywialnego planu, ponieważ agregat i związki mają wiele możliwości wdrożenia, co wymaga decyzji opartej na kosztach.
Przetwarzanie transakcji
Etap przetwarzania transakcji (TP) wymaga, aby zapytanie zawierało co najmniej trzy odwołania do tabeli, w przeciwnym razie optymalizacja oparta na kosztach pomija ten etap i przechodzi bezpośrednio do szybkiego planu. Etap TP jest ukierunkowany na niskokosztowe zapytania nawigacyjne typowe dla obciążeń OLTP. Próbuje ograniczonej liczby technik optymalizacji i ogranicza się do znajdowania planów z zagnieżdżonymi łączeniami pętli (chyba że do wygenerowania prawidłowego planu potrzebne jest połączenie haszujące).
Pod pewnymi względami zaskakujące jest to, że zapytanie testowe kwalifikuje się do etapu, którego celem jest znalezienie planów OLTP. Chociaż zapytanie zawiera wymagane trzy odwołania do tabeli, nie zawiera żadnych złączeń. Wymóg trzech tabel to tylko heurystyka, więc nie będę się zastanawiał.
Które etapy Optymalizatora zostały uruchomione?
Istnieje wiele metod, z których udokumentowana jest porównywanie zawartości sys.dm_exec_query_optimizer_info przed i po kompilacji. Jest to w porządku, ale rejestruje informacje dotyczące całej instancji, więc musisz uważać, aby Twoja kompilacja była jedyną kompilacją zapytań, która ma miejsce między zrzutami.
Nieudokumentowaną (ale dość dobrze znaną) alternatywą, która działa we wszystkich obecnie obsługiwanych wersjach SQL Server, jest włączenie flag śledzenia 8675 i 3604 podczas kompilowania zapytania.
Test 1
Ten test generuje dane wyjściowe znacznika śledzenia 8675 podobne do następujących:

Szacowany koszt 0.101624 po etapie TP jest na tyle niski, że optymalizator nie szuka tańszych planów. Prosty plan, który otrzymujemy, jest całkiem rozsądny, biorąc pod uwagę stosunkowo niską kardynalność tabel podstawowych, nawet jeśli nie jest naprawdę optymalny.
Test 2
Z 50 000 wierszami w każdej tabeli podstawowej, flaga śledzenia wyświetla różne informacje:

Tym razem szacowany koszt po etapie TP wynosi 0,428735 (więcej rzędów =wyższy koszt). To wystarczy, aby zachęcić optymalizatora do etapu Szybkiego Planowania. Dzięki większej liczbie dostępnych technik optymalizacji na tym etapie znajduje się plan o koszcie 0,41375 . Nie oznacza to ogromnej poprawy w porównaniu z planem testowym 1, ale jest niższy niż domyślny próg kosztów dla równoległości i nie wystarcza, aby przejść do pełnej optymalizacji, więc optymalizacja kończy się wcześnie.
Test 3
W przypadku uruchamiania programu SQL Server 2005 i 2012 dane wyjściowe flagi śledzenia to:

Istnieją niewielkie różnice w liczbie zadań uruchamianych między wersjami, ale ważna różnica polega na tym, że w SQL Server 2005 i 2012 etap Szybki plan znajduje plan kosztujący tylko 0,0098543 jednostki. Jest to plan, który zawiera najlepsze operatory zamiast trzech Stream Aggregates poniżej operatora Concatenation widocznego w planach SQL Server 2008 i 2008 R2.
Błędy i nieudokumentowane poprawki
SQL Server 2008 i 2008 R2 zawierają błąd regresji (w porównaniu z 2005), który został naprawiony pod flagą śledzenia 4199, ale nie udokumentowany, o ile wiem. Istnieje dokumentacja dla TF 4199, która zawiera listę poprawek udostępnionych pod osobnymi flagami śledzenia, zanim zostaną objęte 4199, ale jak mówi ten artykuł z bazy wiedzy:
Ta jedna flaga śledzenia może służyć do włączania wszystkich poprawek, które zostały wcześniej wprowadzone dla procesora zapytań pod wieloma flagami śledzenia. Ponadto wszystkie przyszłe poprawki procesora zapytań będą kontrolowane za pomocą tej flagi śledzenia.
Błąd w tym przypadku to jedna z tych „przyszłych poprawek procesora zapytań”. Konkretna reguła optymalizacji, ScalarGbAggToTop , nie ma zastosowania do nowych kruszyw widocznych w planie testu 2. Po włączeniu flagi śledzenia 4199 w odpowiednich kompilacjach SQL Server 2008 i 2008 R2 błąd został naprawiony i uzyskano optymalny plan z testu 3:
-- Trace flag 4199 required for 2008 and 2008 R2 SELECT MAX(c1) FROM dbo.V1 OPTION (QUERYTRACEON 4199);
Wniosek
Gdy już wiesz, że optymalizator może przekształcić skalar MIN lub MAX agregować do TOP (1) na uporządkowanym strumieniu plan pokazany w teście 2 wydaje się dziwny. Agregaty skalarne powyżej skanu indeksu (który może zapewnić porządek, jeśli zostanie o to poproszony) wyróżniają się jako pominięta optymalizacja, która normalnie zostałaby zastosowana.
To jest punkt, o którym mówiłem we wstępie:kiedy już zorientujesz się, co może zrobić optymalizator, może on pomóc Ci rozpoznać przypadki, w których coś poszło nie tak.
Odpowiedzią nie zawsze będzie włączenie flagi śledzenia 4199, ponieważ możesz napotkać problemy, które nie zostały jeszcze naprawione. Możesz również nie chcieć, aby inne poprawki QP objęte flagą śledzenia miały zastosowanie w konkretnym przypadku — poprawki optymalizatora nie zawsze poprawiają sytuację. Gdyby tak było, nie byłoby potrzeby ochrony przed niefortunnymi regresjami planu za pomocą tej flagi.
W innych przypadkach rozwiązaniem może być sformułowanie zapytania SQL przy użyciu innej składni, rozbicie zapytania na bardziej przyjazne dla optymalizatora części lub coś zupełnie innego. Bez względu na to, jaka będzie odpowiedź, warto wiedzieć trochę o wewnętrznych elementach optymalizatora, aby w pierwszej kolejności rozpoznać, że wystąpił problem :)