tl;dr Wiele Include wysadzić zestaw wyników SQL. Wkrótce ładowanie danych przez wiele wywołań bazy danych staje się tańsze niż uruchamianie jednej megainstrukcji. Spróbuj znaleźć najlepszą mieszankę Include i Load oświadczenia.
wygląda na to, że podczas korzystania z dołączania występuje spadek wydajności
To jest niedomówienie! Wiele Include s szybko wysadzić wynik zapytania SQL zarówno pod względem szerokości, jak i długości. Dlaczego tak jest?
Współczynnik wzrostu Include s
(Ta część dotyczy wersji klasycznej Entity Framework, v6 i wcześniejszych)
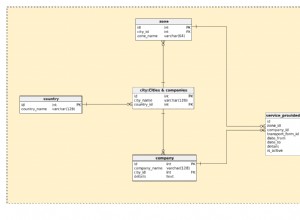
Powiedzmy, że mamy
- jednostka główna
Root - jednostka nadrzędna
Root.Parent - jednostki podrzędne
Root.Children1iRoot.Children2 - instrukcja LINQ
Root.Include("Parent").Include("Children1").Include("Children2")
Tworzy to instrukcję SQL o następującej strukturze:
SELECT *, <PseudoColumns>
FROM Root
JOIN Parent
JOIN Children1
UNION
SELECT *, <PseudoColumns>
FROM Root
JOIN Parent
JOIN Children2
Te <PseudoColumns> składają się z wyrażeń takich jak CAST(NULL AS int) AS [C2], i służą do tego, aby mieć taką samą liczbę kolumn we wszystkich UNION -ed zapytania. Pierwsza część dodaje pseudokolumny dla Child2 , druga część dodaje pseudokolumny dla Child1 .
Oto, co oznacza dla rozmiaru zestawu wyników SQL:
- Liczba kolumn w
SELECTklauzula jest sumą wszystkich kolumn w czterech tabelach - Liczba wierszy to suma rekordów w uwzględnionych kolekcjach podrzędnych
Ponieważ łączna liczba punktów danych to columns * rows , każdy dodatkowy Include wykładniczo zwiększa całkowitą liczbę punktów danych w zestawie wyników. Pozwól mi to zademonstrować, biorąc Root znowu, teraz z dodatkowym Children3 kolekcja. Jeśli wszystkie tabele mają 5 kolumn i 100 wierszy, otrzymujemy:
Jeden Include (Root + 1 kolekcja podrzędna):10 kolumn * 100 wierszy =1000 punktów danych.
Dwa Include s (Root + 2 kolekcje podrzędne:15 kolumn * 200 wierszy =3000 punktów danych.
Trzy Include s (Root + 3 kolekcje podrzędne):20 kolumn * 300 wierszy =6000 punktów danych.
Z 12 Includes oznaczałoby to 78000 punktów danych!
I odwrotnie, jeśli otrzymasz wszystkie rekordy dla każdej tabeli osobno zamiast 12 Includes , masz 13 * 5 * 100 punkty danych:6500, mniej niż 10%!
Teraz te liczby są nieco przesadzone, ponieważ wiele z tych punktów danych będzie null , więc nie mają większego wpływu na rzeczywisty rozmiar zestawu wyników wysyłanego do klienta. Jednak na rozmiar zapytania i zadanie dla optymalizatora zapytań z pewnością negatywnie wpływa rosnąca liczba Include s.
Saldo
Więc używając Includes to delikatna równowaga między kosztem połączeń z bazą danych a ilością danych. Trudno podać regułę, ale już teraz możesz sobie wyobrazić, że ilość danych generalnie szybko przewyższa koszt dodatkowych połączeń, jeśli jest ich więcej niż ~3 Includes dla kolekcji podrzędnych (ale trochę więcej dla nadrzędnych Includes , które tylko poszerzają zbiór wyników).
Alternatywna
Alternatywa dla Include jest ładowanie danych w oddzielnych zapytaniach:
context.Configuration.LazyLoadingEnabled = false;
var rootId = 1;
context.Children1.Where(c => c.RootId == rootId).Load();
context.Children2.Where(c => c.RootId == rootId).Load();
return context.Roots.Find(rootId);
Spowoduje to załadowanie wszystkich wymaganych danych do pamięci podręcznej kontekstu. Podczas tego procesu EF wykonuje naprawę relacji za pomocą którego automatycznie wypełnia właściwości nawigacji (Root.Children itp.) przez załadowane podmioty. Wynik końcowy jest identyczny z instrukcją z Include s, z wyjątkiem jednej ważnej różnicy:kolekcje podrzędne nie są oznaczone jako załadowane w menedżerze stanu jednostki, więc EF spróbuje wyzwolić ładowanie z opóźnieniem, jeśli uzyskasz do nich dostęp. Dlatego ważne jest, aby wyłączyć leniwe ładowanie.
W rzeczywistości będziesz musiał dowiedzieć się, która kombinacja Include i Load oświadczenia działają najlepiej dla Ciebie.
Inne aspekty do rozważenia
Każdy Include zwiększa również złożoność zapytań, więc optymalizator zapytań bazy danych będzie musiał podejmować coraz więcej wysiłku, aby znaleźć najlepszy plan zapytań. W pewnym momencie może się to już nie udać. Ponadto, gdy brakuje niektórych ważnych indeksów (zwłaszcza w przypadku kluczy obcych), wydajność może ucierpieć po dodaniu Include s, nawet z najlepszym planem zapytań.
Rdzeń Entity Framework
Wybuch kartezjański
Z jakiegoś powodu opisane powyżej zachowanie, zapytania UNIONed, zostało porzucone w EF core 3. Teraz tworzy jedno zapytanie ze sprzężeniami. Gdy zapytanie ma kształt gwiazdy, prowadzi to do eksplozji kartezjańskiej (w zestawie wyników SQL). Mogę znaleźć tylko notatkę ogłaszającą tę przełomową zmianę, ale nie mówi, dlaczego.
Podziel zapytania
Aby przeciwdziałać tej eksplozji kartezjańskiej, Entity Framework core 5 wprowadził koncepcję zapytań dzielonych, która umożliwia ładowanie powiązanych danych w wielu zapytaniach. Zapobiega tworzeniu jednego ogromnego, zwielokrotnionego zestawu wyników SQL. Ponadto ze względu na mniejszą złożoność zapytania może skrócić czas potrzebny na pobranie danych nawet w przypadku wielu rund. Może to jednak prowadzić do niespójnych danych w przypadku równoczesnych aktualizacji.
Wiele relacji 1:n poza korzeniem zapytania.