Zasada „Nie powtarzaj się” sugeruje, że powinieneś ograniczyć powtórzenia. W tym tygodniu natknąłem się na przypadek, w którym SUCHY powinien zostać wyrzucony przez okno. Są też inne przypadki (na przykład funkcje skalarne), ale ten był interesujący i dotyczył logiki Bitwise.
Wyobraźmy sobie następującą tabelę:
CREATE TABLE dbo.CarOrders
(
OrderID INT PRIMARY KEY,
WheelFlag TINYINT,
OrderDate DATE
--, ... other columns ...
);
CREATE INDEX IX_WheelFlag ON dbo.CarOrders(WheelFlag); Bity „WheelFlag” reprezentują następujące opcje:
0 = stock wheels 1 = 17" wheels 2 = 18" wheels 4 = upgraded tires
Możliwe kombinacje to:
0 = no upgrade 1 = upgrade to 17" wheels only 2 = upgrade to 18" wheels only 4 = upgrade tires only 5 = 1 + 4 = upgrade to 17" wheels and better tires 6 = 2 + 4 = upgrade to 18" wheels and better tires
Odłóżmy na bok argumenty, przynajmniej na razie, czy powinno to być w pierwszej kolejności zapakowane w jeden TINYINT, czy przechowywane w oddzielnych kolumnach, czy też użyć modelu EAV… naprawienie projektu to osobna kwestia. Chodzi o pracę z tym, co masz.
Aby przykłady były przydatne, wypełnijmy tę tabelę garścią losowych danych. (A dla uproszczenia załóżmy, że ta tabela zawiera tylko zamówienia, które nie zostały jeszcze wysłane.) Spowoduje to wstawienie 50 000 wierszy o mniej więcej równym rozkładzie między sześcioma kombinacjami opcji:
;WITH n AS
(
SELECT n,Flag FROM (VALUES(1,0),(2,1),(3,2),(4,4),(5,5),(6,6)) AS n(n,Flag)
)
INSERT dbo.CarOrders
(
OrderID,
WheelFlag,
OrderDate
)
SELECT x.rn, n.Flag, DATEADD(DAY, x.rn/100, '20100101')
FROM n
INNER JOIN
(
SELECT TOP (50000)
n = (ABS(s1.[object_id]) % 6) + 1,
rn = ROW_NUMBER() OVER (ORDER BY s2.[object_id])
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
) AS x
ON n.n = x.n; Jeśli spojrzymy na podział, możemy zobaczyć ten rozkład. Pamiętaj, że Twoje wyniki mogą się nieznacznie różnić od moich w zależności od obiektów w Twoim systemie:
SELECT WheelFlag, [Count] = COUNT(*) FROM dbo.CarOrders GROUP BY WheelFlag;
Wyniki:
WheelFlag Count --------- ----- 0 7654 1 8061 2 8757 4 8682 5 8305 6 8541
Teraz powiedzmy, że jest wtorek i właśnie dostaliśmy dostawę 18-calowych felg, których wcześniej nie było w magazynie. Oznacza to, że jesteśmy w stanie zrealizować wszystkie zamówienia, które wymagają felg 18-calowych – zarówno tych, które ulepszały opony (6), i tych, które tego nie zrobiły (2). Więc *moglibyśmy* napisać zapytanie podobne do następującego:
SELECT OrderID
FROM dbo.CarOrders
WHERE WheelFlag IN (2,6); Oczywiście w prawdziwym życiu tak naprawdę nie możesz tego zrobić; co, jeśli później zostanie dodanych więcej opcji, takich jak blokady kół, dożywotnia gwarancja na koła lub wiele opcji opon? Nie chcesz pisać serii wartości IN() dla każdej możliwej kombinacji. Zamiast tego możemy napisać operację BITWISE AND, aby znaleźć wszystkie wiersze, w których ustawiony jest drugi bit, na przykład:
DECLARE @Flag TINYINT = 2;
SELECT OrderID
FROM dbo.CarOrders
WHERE WheelFlag & @Flag = @Flag; Daje mi to takie same wyniki jak zapytanie IN(), ale jeśli porównam je za pomocą SQL Sentry Plan Explorer, wydajność jest zupełnie inna:

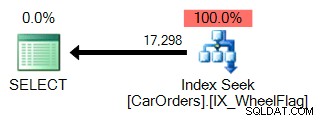
Łatwo zrozumieć, dlaczego. Pierwsza używa indeksu, aby wyizolować wiersze, które spełniają zapytanie, z filtrem w kolumnie WheelFlag:

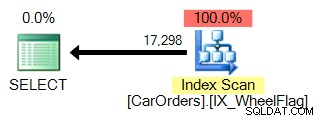
Drugi wykorzystuje skanowanie w połączeniu z niejawną konwersją i strasznie niedokładnymi statystykami. Wszystko dzięki operatorowi BITWISE AND:


Więc co to znaczy? W samym sercu mówi nam to, że operacja BITWISE AND nie jest możliwa do przeprowadzenia .
Ale wszelka nadzieja nie jest stracona.
Jeśli na chwilę zignorujemy zasadę DRY, możemy napisać nieco wydajniejsze zapytanie, będąc nieco nadmiarowym, aby skorzystać z indeksu w kolumnie WheelFlag. Zakładając, że szukamy dowolnej opcji WheelFlag powyżej 0 (brak aktualizacji w ogóle), możemy przepisać zapytanie w ten sposób, informując SQL Server, że wartość WheelFlag musi być co najmniej taka sama jak flaga (co eliminuje 0 i 1 ), a następnie dodając informacje uzupełniające, które również muszą zawierać tę flagę (w ten sposób eliminując 5).
SELECT OrderID FROM dbo.CarOrders WHERE WheelFlag >= @Flag AND WheelFlag & @Flag = @Flag;
Część>=tej klauzuli jest oczywiście objęta częścią BITWISE, więc tutaj naruszamy DRY. Ale ponieważ ta klauzula, którą dodaliśmy, jest sargable, przeniesienie operacji BITWISE AND do drugorzędnego warunku wyszukiwania nadal daje ten sam wynik, a ogólne zapytanie zapewnia lepszą wydajność. Widzimy, że podobny indeks dąży do zakodowanej na sztywno wersji powyższego zapytania i chociaż szacunki są jeszcze bardziej odległe (coś, co można rozwiązać jako osobny problem), odczyty są nadal niższe niż w przypadku samej operacji BITWISE AND:

Widzimy również, że w stosunku do indeksu używany jest filtr, którego nie widzieliśmy przy użyciu samej operacji BITWISE AND:

Wniosek
Nie bój się powtarzać. Są chwile, kiedy ta informacja może pomóc optymalizatorowi; nawet jeśli *dodawanie* kryteriów w celu poprawy wydajności może nie być całkowicie intuicyjne, ważne jest, aby zrozumieć, kiedy dodatkowe klauzule pomagają zmniejszyć ilość danych w celu uzyskania wyniku końcowego, zamiast ułatwiać optymalizatorowi znalezienie dokładnych wierszy samodzielnie.