Słysząc, co robię, ludzie zadają mi to samo pytanie:Czy możesz opracować system, który przewiduje wyniki meczów piłki nożnej? Albo medale olimpijskie? Osobiście nie wierzę zbytnio w przewidywania. Mimo to, gdybyśmy dysponowali dużą ilością danych historycznych i odpowiednich wskaźników, z pewnością moglibyśmy zaprojektować system, który pomoże nam w formułowaniu dokładniejszych założeń. W tym artykule rozważymy model, który może przechowywać wyniki meczów i turniejów.
Model ten koncentruje się głównie na europejskich meczach piłki nożnej (piłce nożnej), statystykach i wynikach, ale można go łatwo dostosować, aby uwzględnić wiele innych dyscyplin sportowych. Moją główną motywacją do napisania tego artykułu były dwa tegoroczne wielkie wydarzenia piłkarskie:Mistrzostwa UEFA Euro 2016, które właśnie się odbyły, oraz Letnie Igrzyska Olimpijskie 2016, które właśnie się odbywają.
Co wiemy przed rozpoczęciem turnieju?
Przed rozpoczęciem turnieju wiemy o nim prawie wszystko — z wyjątkiem najważniejszej rzeczy:kto wygra. Powiedzmy krótko dokładnie to, co już wiemy:
- Daty rozpoczęcia i zakończenia turnieju
- Miejsca, w których odbędą się mecze
- Dokładne godziny rozpoczęcia meczów
- Które drużyny zakwalifikowały się do turnieju
- Gracze w każdej z tych drużyn
- Przeszłe wyniki każdego gracza i ich aktualna forma
Jakie szczegóły meczu chcemy przechowywać?
Turnieje składają się z wielu meczów. Zanim zapiszemy jakiekolwiek szczegóły meczu, musimy:
- Powiąż każdy mecz z turniejem
- Zapisz etap turnieju, kiedy mecz był rozgrywany (np. faza grupowa, półfinały)
Musimy również przechowywać szczegóły dotyczące pojedynczych meczów, w tym:
- Drużyny biorące udział w meczu
- Początkowe składy i zmiany
- Zdarzenia meczowe (w piłce nożnej są to:bramka, kara, faul, żółta kartka itp.)
- Ostateczny wynik
- Działania graczy podczas meczu
Wykorzystamy te dane do przechwycenia wszystkich ważnych wydarzeń związanych z meczami. Porównanie wyników zawodnika przed meczem i w jego trakcie może prowadzić do pewnych wniosków. Może nie bylibyśmy w stanie przewidzieć ostatecznych wyników ich wyników (tj. wygranej lub przegranej), ale statystyki z pewnością mogą pomóc nam w dokonywaniu pewnych założeń.
Przedstawiamy model
Model podzielony jest na cztery główne obszary:
Tournament detailsMatch detailsEventsIndicators and Performance
Tabele poza tymi obszarami to słowniki (sport , phase , position ), katalogi (sport_event , team , player ) i pojedynczą relację wiele-do-wielu (plays ).
Najpierw opiszemy tabele bez kategorii, a następnie przyjrzymy się bliżej każdemu obszarowi.
Tabele bez kategorii
Te tabele są ważne, ponieważ tabele ze wszystkich czterech obszarów używają ich jako słowników lub katalogów.

sport tabela zawiera listę wszystkich sportów, które będziemy przechowywać w naszej bazie danych. Prawdopodobnie będziemy mieli tutaj tylko jeden sport, piłkę nożną mężczyzn, ale ta tabela daje nam elastyczność w dodawaniu podobnych dyscyplin (np. piłki nożnej kobiet), jeśli zajdzie taka potrzeba.

W sport_event tabeli, będziemy przechowywać wydarzenia związane z naszymi sportami. Jednym z przykładów mogą być „Igrzyska Olimpijskie 2016”.
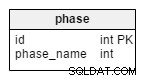
phase table to słownik, który zawiera wszystkie możliwe etapy turnieju. Zawiera wartości takie jak „etap grupowy” , „runda 16” , „ćwierćfinały” , „półfinały” , „finał” .
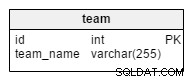
team tabela to, jak można się domyślić, prosta lista wszystkich drużyn. Możliwe wartości to „Chorwacja” , „Polska” , „USA” itp. Jeśli użyjemy bazy danych do przechowywania informacji o rozgrywkach klubowych lub ligowych, otrzymalibyśmy również wartości takie jak „Barcelona” , „Real Madryt” , „Bawaria” , „Manchester United” itp.
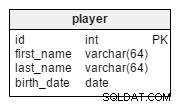
W player tabeli, będziemy przechowywać rekordy wszystkich graczy należących do odpowiednich drużyn.
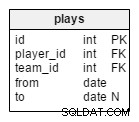
plays stół jest naszą jedyną relacją wiele-do-wielu i dotyczy graczy i drużyn. Zawodnik może jednocześnie należeć do więcej niż jednej drużyny (np. reprezentacji narodowej i klubu), ale podczas turnieju będzie oczywiście grał tylko w jednej drużynie.
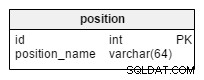
Wreszcie mamy position stół. Ten prosty słownik będzie przechowywać listę wszystkich wymaganych pozycji. W piłce nożnej są to bramkarz, środkowy obrońca, napastnik itp.
Szczegóły turnieju
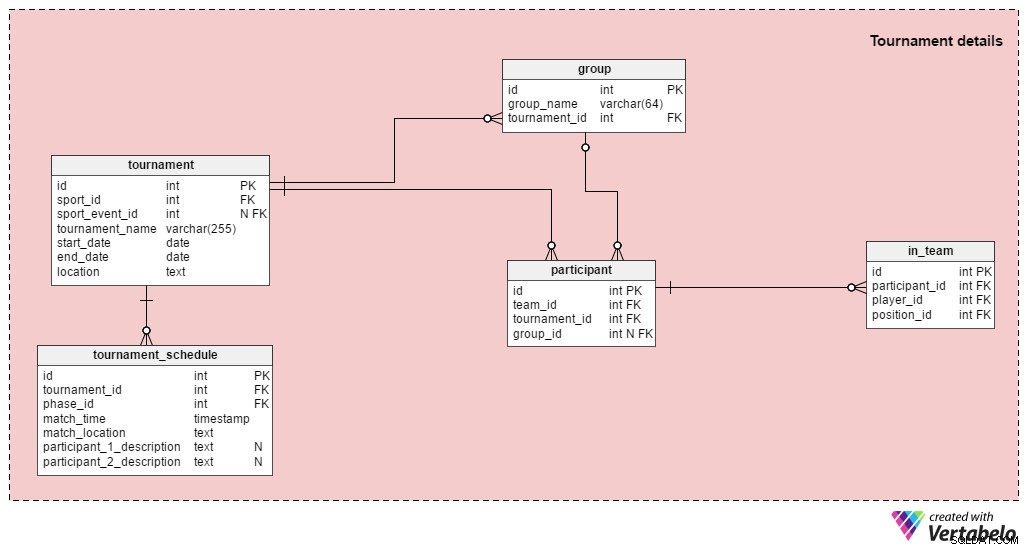
Uwaga: Jeśli chcesz tylko przechowywać wyniki pojedynczych meczów, nie musisz korzystać z tej sekcji.
Turniej składa się z więcej niż jednego meczu; zarówno UEFA Euro 2016, jak i wydarzenia piłkarskie na Letnich Igrzyskach Olimpijskich 2016 są turniejami. Jak powiedzieliśmy wcześniej, możemy przechowywać w naszej bazie danych pojedynczy mecz, ale możemy również powiązać mecze z odpowiednimi turniejami. Stoły w sekcji Turniej to:
tournament– Zawiera wszystkie podstawowe dane turniejowe:sport, datę rozpoczęcia, datę zakończenia itp. Musimy również zapisać nazwę turnieju i opis miejsca, w którym się on odbywa.sport_event_idatrybut jest opcjonalny, ponieważ turniej nie musi być powiązany z większym wydarzeniem (takim jak igrzyska olimpijskie).group– To zawiera listę wszystkich grup w tym turnieju. UEFA Euro 2016 miała sześć grup, od A do F.participant– To są drużyny grające w turnieju; każdy uczestnik może być przypisany do grupy. Większość turniejów rozpoczyna się od fazy grupowej, a następnie przechodzi do fazy pucharowej (np. UEFA Euro, UEFA World Cup, Olympic Football). Niektóre turnieje będą miały tylko fazę grupową (np. ligi krajowe), podczas gdy inne będą miały tylko fazę pucharową (np. puchary krajowe).in_team– Ta tabela zapewnia relację wiele-do-wielu, która przechowuje informacje o graczach zarejestrowanych w tym turnieju i ich oczekiwanych pozycjach.tournament_schedule– Moim zdaniem to najciekawsza tabela w tym dziale. Tutaj znajduje się lista wszystkich gier rozegranych podczas tego turnieju.tournament_idatrybut wskazuje, do którego turnieju należy każdy mecz, aphase_idatrybut określa fazę, w której odbędzie się mecz. Zapisujemy również lokalizację meczu i godzinę rozpoczęcia meczu. Obaj uczestnicy zostaną opisani przez pola tekstowe. Po zakończeniu fazy grupowej poznamy wszystkie pojedynki w rundzie eliminacyjnej. Na przykład na początku UEFA Euro 2016 wiedzieliśmy, że zwycięzca grupy E (1E) zagra z wicemistrzem grupy D (2D). Po rozegraniu wszystkich trzech rund fazy grupowej ta para to Włochy vs. Hiszpania.
Szczegóły meczu
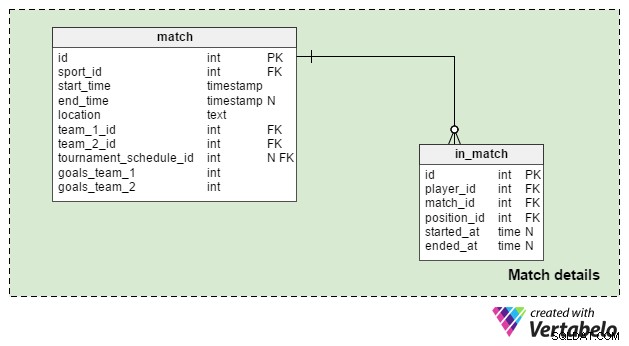
Match details obszar służy do przechowywania danych dla pojedynczych dopasowań. Użyjemy dwóch tabel:
match– Zawiera wszystkie szczegóły dotyczące pojedynczego meczu; ten mecz może być powiązany z turniejem, ale może też być pojedynczą grą. Więctournament_schedule_idatrybut jest opcjonalny i będziemy przechowywaćsport_id,start_timeilocationatrybuty ponownie tutaj. Jeśli mecz jest częścią turnieju, totournament_schedule_idzostanie przypisana wartość.team_1_iditeam_2_idatrybuty to odniesienia do drużyn biorących udział w meczu.goals_team_1igoals_team_2atrybuty zawierają wynik dopasowania. Są obowiązkowe i powinny mieć „0” jako wartość domyślną dla obu.in_match– Ta tabela zawiera listę wszystkich graczy zarejestrowanych na ten mecz; gracze, którzy nie biorą udziału, będą mieli NULL wstarted_atatrybut, podczas gdy gracze, którzy przybyli jako zmienniki, będą mielistarted_at> 0 . Jeśli gracz został zastąpiony, będzie miałended_atatrybut, który pasuje dostarted_atatrybut gracza, który je zastąpił. Jeśli gracz został przez cały mecz, jegoended_atatrybut będzie miał taką samą wartość jakend_timeatrybut.
Wydarzenia meczowe
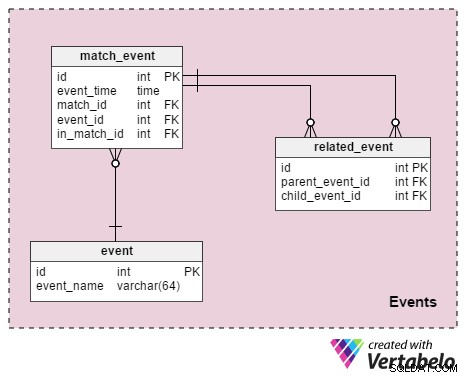
Ta sekcja jest przeznaczona do przechowywania wszystkich szczegółów lub wydarzeń, które miały miejsce podczas gry. A tabele to:
event– To jest słownik, który zawiera listę wszystkich zdarzeń, które chcemy przechowywać. W piłce nożnej są to wartości takie jak „popełnienie faulu” , „przestępstwo” , „żółta kartka” , „czerwona kartka” , „rzut wolny” , „kara” , „cel” , „spalony” , „podstawienie” , „gracz wyrzucony z meczu” .match_event– To ma związek z wydarzeniami z meczu. Przechowamyevent_timea także informacje o graczu związane z tym wydarzeniem (in_match_id).related_event– To właśnie łączy informacje o wydarzeniu. Aby to wyjaśnić, spójrzmy na przykład, w którym gracz A fauluje gracza B. Wstawimy rekord wmatch_eventtabela, która wskazuje, że Gracz A popełnił faul, a druga, która wskazuje, że Gracz B poniósł faul. Dodamy również rekord dorelated_eventtabeli, w której „popełniony faul” będzie rodzicem, a „doznanym faulem” będzie dziecko. Zanotujemy również wyniki faulu:żółtą kartkę, rzut wolny lub rzut karny, a może gol.
Wskaźniki i wydajność
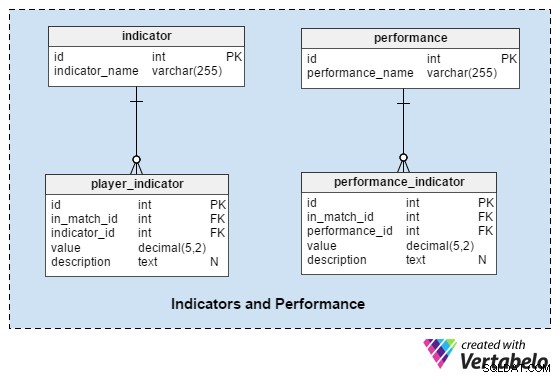
Ta sekcja powinna pomóc nam w analizie graczy i drużyn przed meczem i po nim.
indicator table to słownik z predefiniowanym zestawem wskaźników dla każdego gracza przed każdym meczem. Wskaźniki te powinny opisywać obecną formę gracza. Ta lista może zawierać wartości takie jak:„liczba goli w ostatnich 10 meczach” , „średni dystans pokonany w ostatnich 10 meczach” , „liczba obrońców dla GK w ostatnich 10 meczach” .
performance słownik jest bardzo podobny do indicator , ale użyjemy go do przechowywania tylko wartości związanych z pojedynczym dopasowaniem:„przebyty dystans” , „dokładne podania” itp.
player_indicator i performance_indicator tabele mają prawie identyczną strukturę:
in_match_id– odnosi się do gracza biorącego udział w określonym meczuindicator_id/performance_id– odwołuje się doindicatorlub „słowniki wykonawcze”value– przechowuje wartość tego wskaźnika (np. zawodnik przebył dystans 10,72 km)description– w razie potrzeby posiada dodatkowy opis
Co się wydarzyło podczas meczu?
Po wprowadzeniu wszystkich tych danych mogliśmy łatwo uzyskać szczegóły meczu, wydarzenia i statystyki dla każdego meczu w naszej bazie danych.
To proste zapytanie zwróci podstawowe informacje o nadchodzącym meczu:
SELECT team_1.`team_name`, team_2.`team_name`, `match`.`start_time`, `match`.`location` FROM `match`, `team` AS team_1, `team` AS team_2 WHERE `match`.`team_1_id` = team_1.`id` AND `match`.`team_2_id` = team_2.`id`
Aby uzyskać listę wszystkich wydarzeń na żywo podczas określonego meczu, użyjemy poniższego zapytania:
SELECT `event`.`event_name`, `match_event`.`event_time`, `player`.`first_name`, `player`.`last_name` FROM `match`, `match_event`, `event`, `in_match`, `player` WHERE `match_event`.`match_id` = `match`.`id` AND `event`.`id` = `match_event`.`event_id` AND `in_match`.`id` = `match_event`.`in_match_id` AND `player`.`id` = `in_match`.`player_id` AND `match`.`id` = @match ORDER BY `match_event`.`event_time` ASC
Istnieje wiele dodatkowych zapytań, o których mogę pomyśleć; łatwo jest przeprowadzić analizę, gdy masz dane. Jeśli zmierzyłeś i zapisałeś dużą liczbę wskaźników i danych dotyczących wyników gracza, możesz być w stanie powiązać te parametry z wynikiem końcowym. Osobiście nie wierzę w takie przewidywania; podczas meczów jest czynnik szczęścia, a także wiele innych czynników, których nie możesz poznać, dopóki gra się nie rozpocznie. Mimo to, jeśli masz duży zestaw danych i wiele parametrów, zwiększa się szansa na dokładniejsze prognozy.
Model przedstawiony w tym artykule pozwala nam przechowywać mecze, szczegóły meczów i historię występów każdego gracza. Możemy również ustawić wskaźniki formy dla każdego zawodnika przed meczem. Przechowywanie wystarczającej ilości szczegółów powinno zapewnić nam więcej parametrów, na których możemy oprzeć nasze założenia. Nie mówię, że moglibyśmy przewidzieć wynik gry, ale moglibyśmy się z tym zabawić.
Moglibyśmy również łatwo dostosować ten model, aby przechowywać dane dla innych dyscyplin sportowych. Te zmiany nie powinny być zbyt skomplikowane. Dodawanie sport_id atrybut do słowników powinien załatwić sprawę. Mimo to uważam, że rozsądnie byłoby mieć nową instancję dla każdego innego sportu.