Replikacja MariaDB to jedno z najpopularniejszych rozwiązań wysokiej dostępności dla MariaDB, powszechnie używane przez czołowe firmy, takie jak Booking.com i Google. Jest bardzo łatwy w konfiguracji, z pewnymi kompromisami w zakresie bieżącej konserwacji, takich jak aktualizacje oprogramowania, zmiany schematu, zmiany topologii, przełączanie awaryjne i odzyskiwanie, które zawsze były trudne. Niemniej jednak, z odpowiednim zestawem narzędzi, powinieneś być w stanie z łatwością poradzić sobie z topologią. W tym poście na blogu przyjrzymy się kilku wskazówkom, jak skutecznie monitorować replikację MariaDB przy użyciu ClusterControl.
Korzystanie z przeglądarki topologii
Konfiguracja replikacji składa się z kilku ról. Węzłem w konfiguracji replikacji może być:
- Master — główny zapisujący/odczytujący.
- Backup master — urządzenie podrzędne tylko do odczytu z replikacją półsynchronizowaną, wyłącznie dla nadmiarowości mastera.
- Pośredni master — Replikuj z mastera, podczas gdy inne slave'y replikują z tego węzła.
- Serwer Binlog — Zbieraj/przechowuj tylko binlogi bez udostępniania danych.
- Slave — replikacja z wzorca i zwykle ustawiana jako tylko do odczytu.
- Multi-source slave — replikacja z wielu masterów.
Każda rola ma swoją własną odpowiedzialność i ograniczenia, a podczas pracy z węzłami bazy danych należy zrozumieć poprawną topologię. Odnosi się to również do aplikacji, gdzie aplikacja musi zapisywać tylko w węźle głównym w danym momencie. Dlatego ważne jest, aby mieć przegląd, który węzeł pełni jaką rolę, abyśmy nie zepsuli naszej bazy danych.
W ClusterControl Przeglądarka topologii może dać przegląd topologii replikacji i jej stanu, jak pokazano na poniższym zrzucie ekranu:
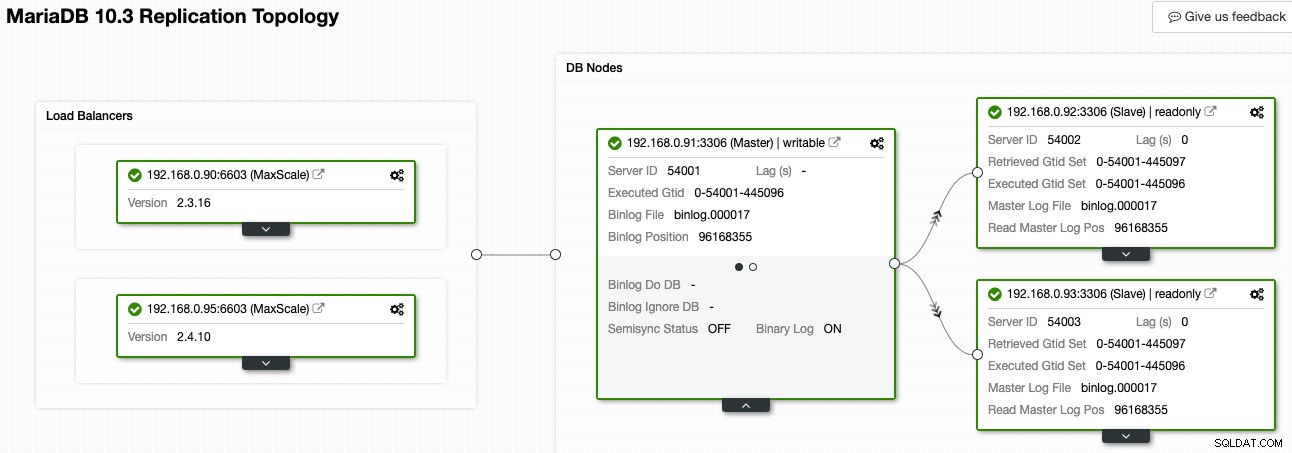
ClusterControl rozumie replikację MariaDB i potrafi wizualizować topologię z poprawnym przepływem danych replikacji, reprezentowanym przez strzałki wskazujące węzły podrzędne. Możemy łatwo odróżnić, który węzeł jest nadrzędny, podrzędny i równoważący obciążenie (MaxScale) w naszej konfiguracji replikacji. Zielone pole wskazuje, że wszystkie ważne usługi działają zgodnie z oczekiwaniami z przypisaną rolą.
Rozważ poniższy zrzut ekranu, na którym kilka naszych węzłów ma problemy:
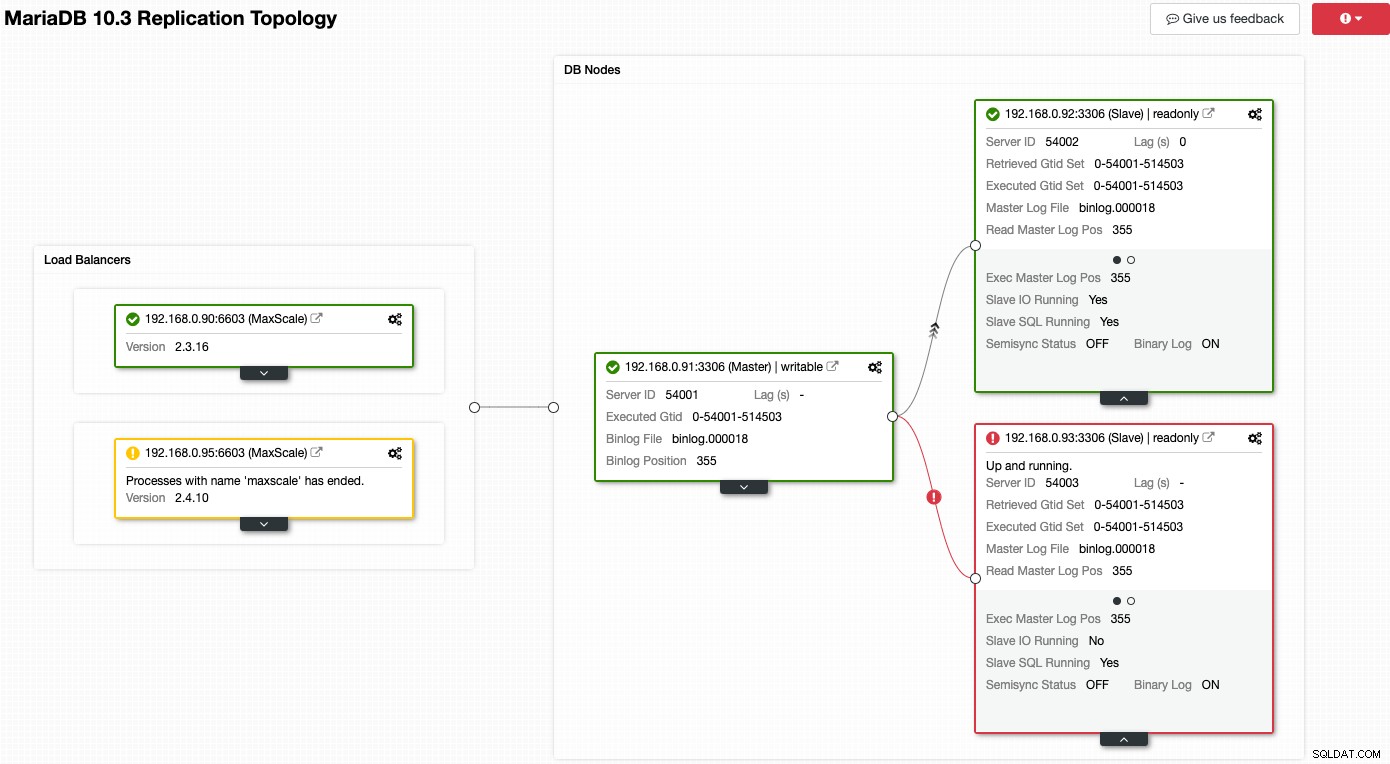
ClusterControl natychmiast poinformuje Cię, co jest nie tak z obecną topologią. Jeden z urządzeń podrzędnych (czerwone pole) wyświetla „Slave IO Running” jako Nie, aby wskazać problem z łącznością do replikacji z urządzenia głównego. Podczas gdy żółte pole pokazuje, że nasza usługa MaxScale nie jest uruchomiona. Możemy również stwierdzić, że wersje MaxScale nie są identyczne dla obu węzłów. Możesz także wykonywać zadania zarządzania, klikając bezpośrednio ikonę koła zębatego (w prawym górnym rogu każdego pola), co zmniejsza ryzyko wybrania niewłaściwego węzła.
Opóźnienie replikacji
To najważniejsza rzecz, jeśli polegasz na spójności replikacji danych. Opóźnienie replikacji występuje, gdy urządzenia podrzędne nie mogą nadążyć za aktualizacjami zachodzącymi na urządzeniu głównym. Niezastosowane zmiany gromadzą się w dziennikach przekaźników urządzeń podrzędnych, a wersja bazy danych na urządzeniach podrzędnych coraz bardziej różni się od wersji głównej.
W ClusterControl histogram opóźnienia replikacji można znaleźć w sekcji Przegląd -> Opóźnienie replikacji, gdzie ClusterControl stale pobiera próbkę wartości Seconds_Behind_Master z danych wyjściowych „SHOW SLAVE STATUS”:
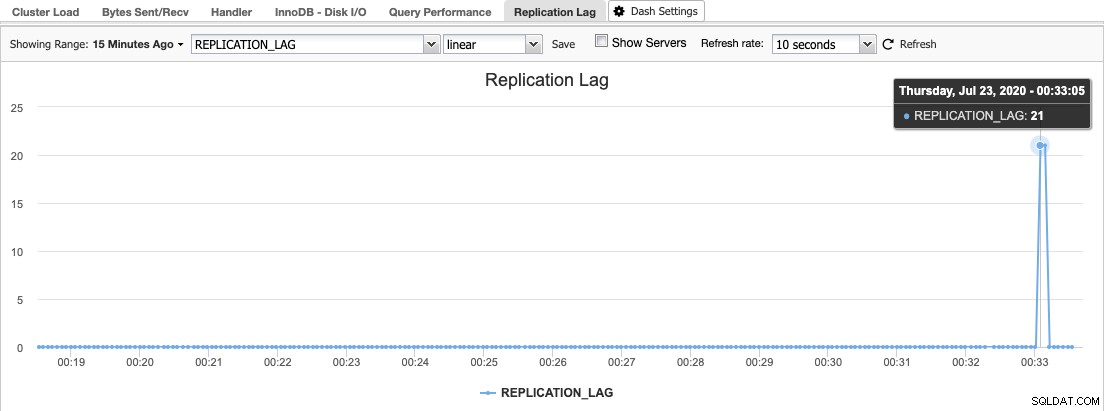
Opóźnienie replikacji ma miejsce, gdy wątek we/wy lub wątek SQL nie jest w stanie sprostać stawianym mu wymaganiom. Jeśli wątek we/wy cierpi, oznacza to, że połączenie sieciowe między urządzeniem głównym a jego urządzeniami podrzędnymi jest wolne lub ma problemy. Możesz rozważyć włączenie protokołu slave_compressed_protocol w celu kompresji ruchu sieciowego lub zgłoszenia do administratora sieci.
Jeśli jest to wątek SQL, problem jest prawdopodobnie spowodowany słabo zoptymalizowanymi zapytaniami, których zastosowanie zajmuje serwer podrzędny zbyt długo. Mogą występować długotrwałe transakcje lub zbyt duża aktywność we/wy. Brak klucza podstawowego w tabelach podrzędnych podczas korzystania z formatu replikacji ROW lub MIXED jest również częstą przyczyną opóźnień w tym wątku. Sprawdź, czy wersje master i slave tabel mają klucz podstawowy.
Więcej wskazówek i sztuczek omówiono w tym poście na blogu, Jak zmniejszyć opóźnienie replikacji we wdrożeniach z wieloma chmurami.
Rozmiar dziennika binarnego/przekaźnika
Ważne jest monitorowanie rozmiaru dysku dzienników binarnych i przekaźnikowych, ponieważ może to zużywać znaczną ilość pamięci w każdym węźle w klastrze replikacji. Zwykle ustawia się zmienną systemową wygasa_logs_days tak, aby automatycznie wygasała binarne pliki dziennika po określonej liczbie dni, na przykład wygasa_logs_days=7. Rozmiar dzienników binarnych jest całkowicie zależny od liczby utworzonych zdarzeń binarnych (przychodzących zapisów) i niewiele wiemy, ile miejsca na dysku zużyłoby, zanim dzienniki wygasną przez MariaDB. Pamiętaj, że jeśli włączysz log_slave_updates na urządzeniach podrzędnych, rozmiar dzienników zostanie prawie podwojony z powodu istnienia zarówno dzienników binarnych, jak i dzienników przekaźnikowych na tym samym serwerze.
W przypadku ClusterControl możemy ustawić próg wykorzystania miejsca na dysku w ClusterControl -> Ustawienia -> Progi, aby uzyskać ostrzeżenie i krytyczne powiadomienia, jak poniżej:
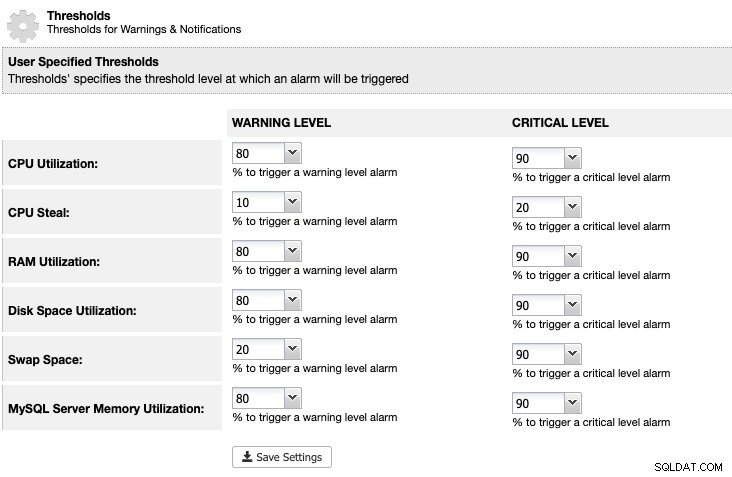
ClusterControl monitoruje całe miejsce na dysku związane z usługami MariaDB, takie jak lokalizacja danych MariaDB katalogu, katalogu dzienników binarnych, a także partycji głównej. Jeśli osiągnąłeś próg, rozważ ręczne przeczyszczenie dzienników binarnych za pomocą polecenia PURGE BINARY LOGS, jak wyjaśniono i omówiono w tym artykule.
Włącz panele monitorowania
ClusterControl udostępnia dwie opcje monitorowania do próbkowania węzłów bazy danych — bez agenta lub oparte na agencie. Wartość domyślna to bez agenta, gdy próbkowanie odbywa się za pośrednictwem protokołu SSH w mechanizmie tylko do ściągania. Monitorowanie oparte na agentach wymaga działającego serwera Prometheus, a wszystkie monitorowane węzły muszą być skonfigurowane z co najmniej trzema eksporterami:
- Eksporter procesów (port 9011)
- Eksporter metryk węzła/systemu (port 9100)
- Eksporter MySQL/MariaDB (port 9104)
Aby włączyć panel monitorowania oparty na agentach, należy przejść do ClusterControl -> Pulpity -> Włącz monitorowanie oparte na agentach. Po włączeniu zobaczysz zestaw pulpitów nawigacyjnych skonfigurowanych dla naszej replikacji MariaDB, co daje nam znacznie lepszy wgląd w naszą konfigurację replikacji. Poniższy zrzut ekranu pokazuje, co można zobaczyć dla węzła głównego:
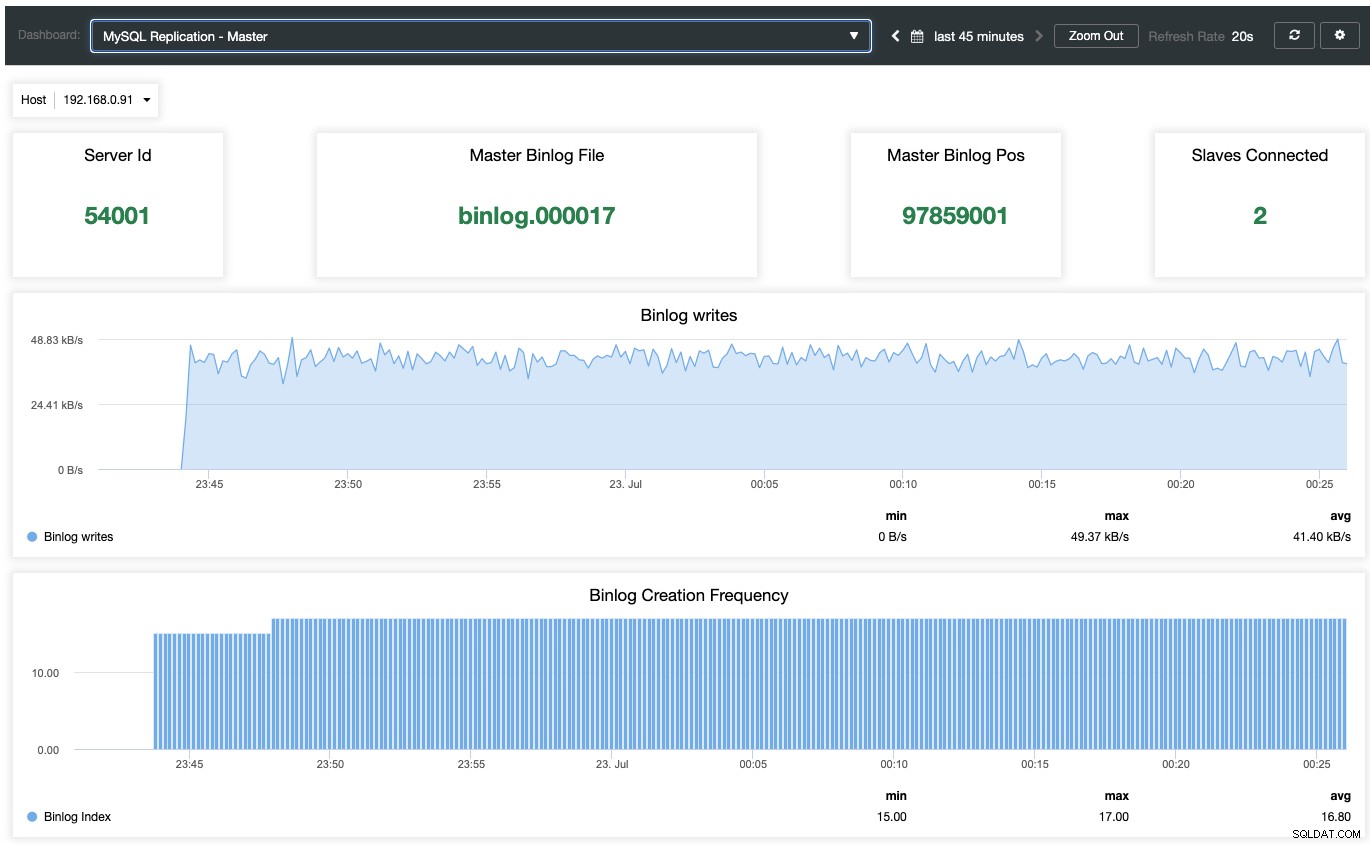
Oprócz standardowych pulpitów monitorowania MariaDB, takich jak ogólne, pamięci podręczne i metryki InnoDB, zostaną przedstawione z pulpitem replikacji. W przypadku węzła master możemy uzyskać wiele przydatnych informacji dotyczących stanu mastera, przepustowości zapisu i częstotliwości tworzenia binlogów.
Podczas gdy dla niewolników, wszystkie ważne stany są próbkowane i podsumowane na poniższym zrzucie ekranu. jeśli wszystko jest zielone, jesteś w dobrych rękach:
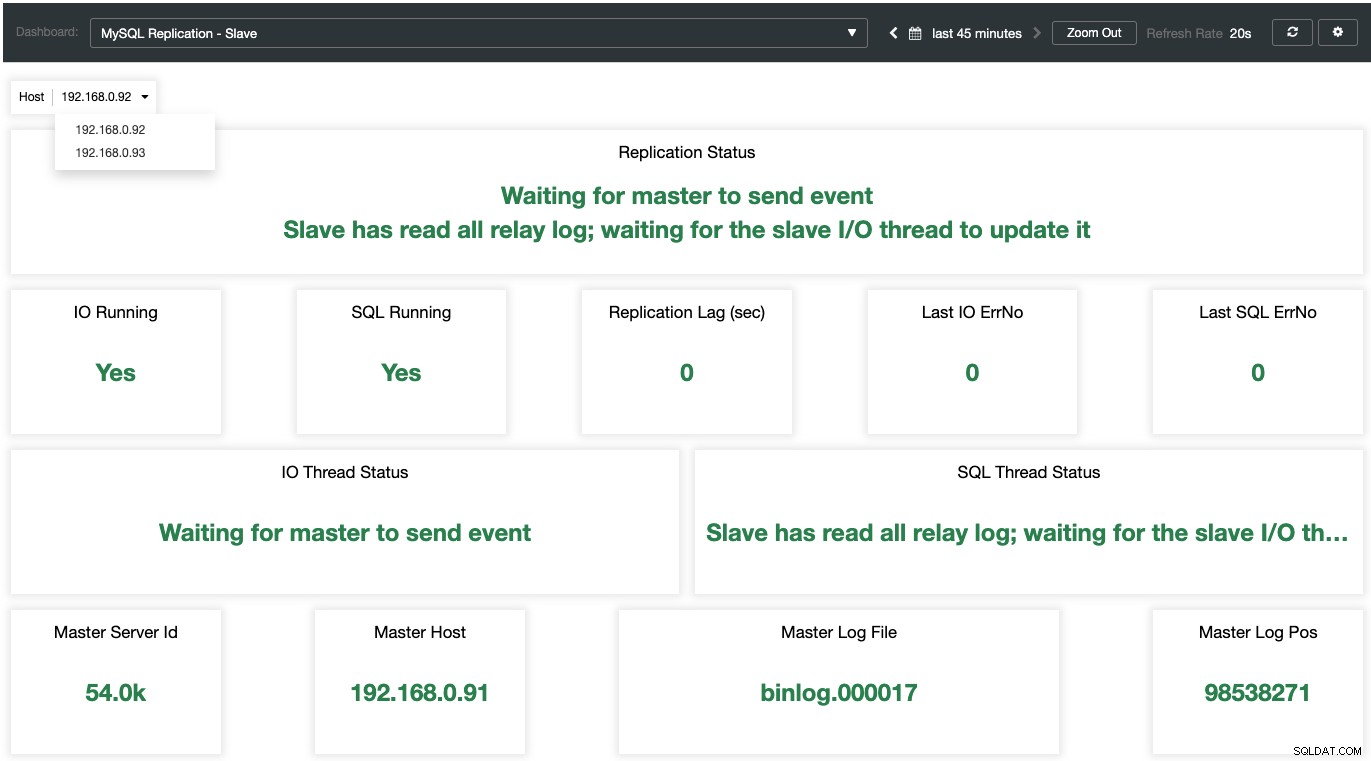
Zrozumienie dziennika błędów MariaDB
MariaDB rejestruje ważne zdarzenia w dzienniku błędów, co jest przydatne do zrozumienia, co się dzieje z serwerem, zwłaszcza przed, w trakcie i po zmianie topologii. ClusterControl zapewnia scentralizowany widok dzienników błędów w ClusterControl -> Logs -> System Logs, pobierając je z każdego węzła bazy danych. Klikasz „Odśwież dzienniki”, aby uruchomić zadanie pobierania najnowszych dzienników z serwera.
Zebrane pliki są reprezentowane w strukturze drzewa nawigacji i obszarze tekstowym z podświetlaniem składni dla lepszej czytelności:
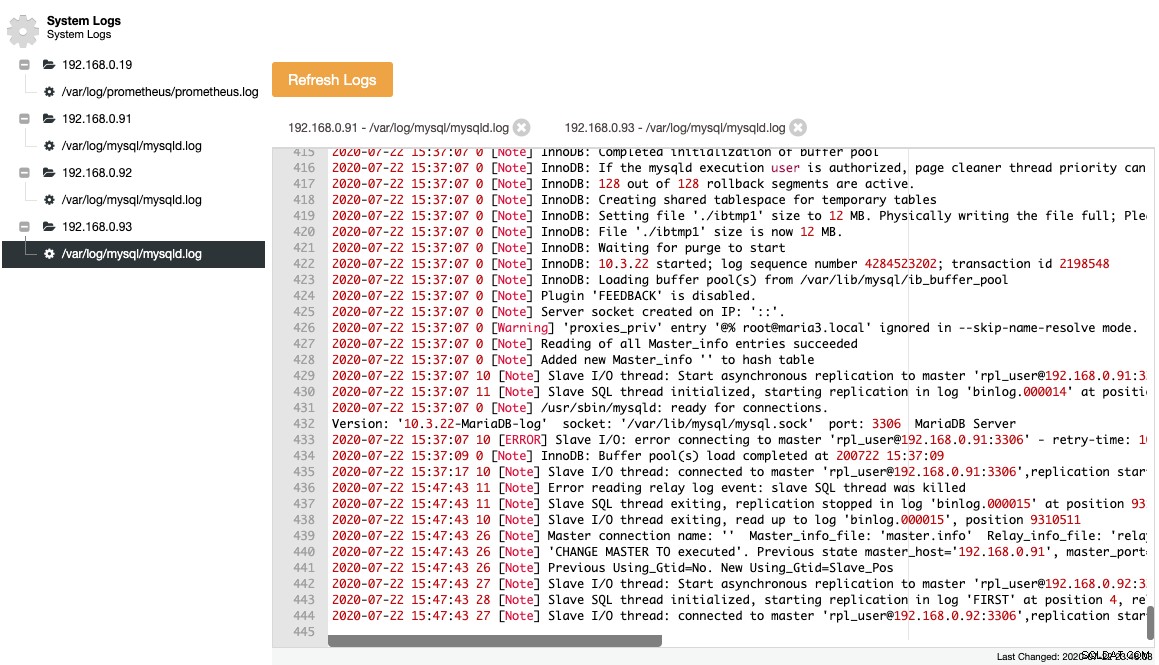
Z powyższego zrzutu ekranu możemy zrozumieć sekwencję zdarzeń i to, co stało się z tym węzłem podczas zdarzenia zmiany topologii. Z ostatnich 12 wierszy powyższego dziennika błędów, urządzenie podrzędne miało błąd podczas łączenia się z urządzeniem nadrzędnym, a ostatni plik dziennika binarnego i pozycja zostały zapisane w dzienniku przed zatrzymaniem. Następnie wykonano nowszą komendę CHANGE MASTER z informacją GTID, jak pokazano w wierszu "Poprzedni Using_Gtid=Nie. Nowy Using_Gtid=Slave_Pos", a następnie replikacja wznawiana zgodnie z oczekiwaniami.
Alert i powiadomienia MariaDB
Monitorowanie jest niekompletne bez alertów i powiadomień. Wszystkie zdarzenia i alarmy generowane przez ClusterControl mogą być wysyłane na e-mail lub inne obsługiwane narzędzia innych firm. W przypadku powiadomień e-mail można skonfigurować, czy rodzaj zdarzeń będzie dostarczany natychmiast, ignorowany lub przetwarzany (dzienny raport podsumowujący):

W przypadku wszystkich zdarzeń o krytycznym znaczeniu zaleca się ustawienie wszystkiego na „Dostarcz”, aby otrzymywać powiadomienia tak szybko, jak to możliwe. Ustaw „Przegląd” na zdarzenia ostrzegawcze, aby mieć pełną świadomość kondycji i stanu klastra.
Możesz zintegrować swoje preferowane narzędzia do komunikacji i przesyłania wiadomości z ClusterControl, korzystając z funkcji Zarządzanie powiadomieniami w ClusterControl -> Integracje -> Powiadomienia stron trzecich. ClusterControl może wysyłać alarmy i zdarzenia do PagerDuty, VictorOps, OpsGenie, Slack, Telegram, ServiceNow lub dowolnych webhooków zarejestrowanych przez użytkownika.
Poniższy zrzut ekranu pokazuje, że wszystkie krytyczne zdarzenia zostaną przekazane do skonfigurowanego kanału telegramu dla naszego klastra replikacji MariaDB 10.3:

ClusterControl obsługuje również integrację chatbota, w ramach której możesz wchodzić w interakcję z usługą kontrolera za pośrednictwem klienta s9s bezpośrednio z narzędzia do przesyłania wiadomości, jak pokazano w tym poście na blogu, Automate Your Database with CCBot:ClusterControl Hubot Integration.
Wnioski
ClusterControl oferuje kompletny zestaw proaktywnych narzędzi do monitorowania klastrów baz danych. Użyj ClusterControl do monitorowania konfiguracji replikacji MariaDB, ponieważ większość funkcji monitorowania jest dostępna bezpłatnie w wersji Community. Nie przegap tego!