Opóźniona replikacja pozwala, aby urządzenie podrzędne replikacji celowo pozostawało w tyle za urządzeniem nadrzędnym o co najmniej określony czas. Przed wykonaniem zdarzenia, urządzenie podrzędne najpierw poczeka, jeśli to konieczne, aż minie podany czas od utworzenia zdarzenia na urządzeniu nadrzędnym. W rezultacie niewolnik będzie odzwierciedlał stan pana jakiś czas temu. Ta funkcja jest obsługiwana od wersji MySQL 5.6 i MariaDB 10.2.3. Może się przydać w przypadku przypadkowego usunięcia danych i powinien być częścią planu odzyskiwania po awarii.
Problem podczas konfigurowania opóźnionej replikacji slave polega na tym, ile opóźnienia powinniśmy wprowadzić. Zbyt mało czasu i ryzykujesz, że złe zapytanie dotrze do twojego opóźnionego niewolnika, zanim będziesz mógł do niego dotrzeć, marnując w ten sposób punkt posiadania opóźnionego niewolnika. Opcjonalnie możesz ustawić opóźnienie tak długie, że opóźniony slave może zająć kilka godzin, aby dogonić miejsce, w którym znajdował się master w momencie błędu.
Na szczęście w przypadku Dockera jego mocną stroną jest izolacja procesów. Uruchamianie wielu instancji MySQL jest całkiem wygodne dzięki Dockerowi. Pozwala nam na posiadanie wielu opóźnionych urządzeń podrzędnych w jednym fizycznym hoście, aby skrócić czas odzyskiwania i zaoszczędzić zasoby sprzętowe. Jeśli uważasz, że 15-minutowe opóźnienie jest zbyt krótkie, możemy mieć inną instancję z 1-godzinnym opóźnieniem lub 6-godzinną dla jeszcze starszej migawki naszej bazy danych.
W tym poście na blogu zamierzamy wdrożyć wiele opóźnionych urządzeń podrzędnych MySQL na jednym fizycznym hoście za pomocą platformy Docker i przedstawimy kilka scenariuszy odzyskiwania. Poniższy diagram ilustruje naszą ostateczną architekturę, którą chcemy zbudować:
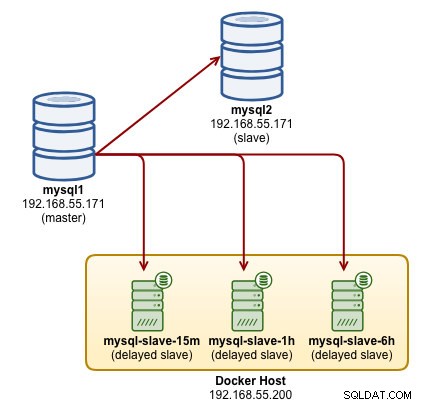
Nasza architektura składa się z już wdrożonej 2-węzłowej replikacji MySQL działającej na serwerach fizycznych (niebieski) i chcielibyśmy skonfigurować kolejne trzy urządzenia podrzędne MySQL (zielone) z następującym zachowaniem:
- 15 minut opóźnienia
- 1 godzina opóźnienia
- 6 godzin opóźnienia
Zwróć uwagę, że będziemy mieć 3 kopie dokładnie tych samych danych na tym samym serwerze fizycznym. Upewnij się, że nasz host Docker ma wymaganą przestrzeń dyskową, więc wcześniej przydziel wystarczającą ilość miejsca na dysku.
Przygotowanie MySQL Master
Najpierw zaloguj się do serwera głównego i utwórz użytkownika replikacji:
mysql> GRANT REPLICATION SLAVE ON *.* TO example@sqldat.com'%' IDENTIFIED BY 'YlgSH6bLLy';Następnie utwórz kopię zapasową kompatybilną z PITR na urządzeniu głównym:
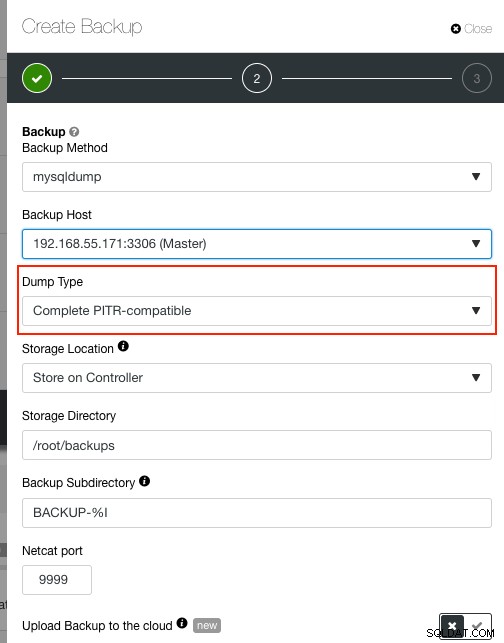
$ mysqldump -uroot -p --flush-privileges --hex-blob --opt --master-data=1 --single-transaction --skip-lock-tables --skip-lock-tables --triggers --routines --events --all-databases | gzip -6 -c > mysqldump_complete.sql.gzJeśli używasz ClusterControl, możesz łatwo wykonać kopię zapasową kompatybilną z PITR. Przejdź do Kopie zapasowe -> Utwórz kopię zapasową i wybierz „Pełna zgodność z PITR” w menu rozwijanym „Typ zrzutu”:
Na koniec przenieś tę kopię zapasową na hosta Docker:
$ scp mysqldump_complete.sql.gz example@sqldat.com:~Ten plik kopii zapasowej będzie używany przez kontenery podrzędne MySQL podczas procesu ładowania podrzędnego, jak pokazano w następnej sekcji.
Opóźnione wdrożenie modułu podrzędnego
Przygotuj nasze katalogi kontenerów Docker. Utwórz 3 katalogi (mysql.conf.d, datadir i sql) dla każdego kontenera MySQL, który zamierzamy uruchomić (możesz użyć pętli, aby uprościć poniższe polecenia):
$ mkdir -p /storage/mysql-slave-15m/mysql.conf.d
$ mkdir -p /storage/mysql-slave-15m/datadir
$ mkdir -p /storage/mysql-slave-15m/sql
$ mkdir -p /storage/mysql-slave-1h/mysql.conf.d
$ mkdir -p /storage/mysql-slave-1h/datadir
$ mkdir -p /storage/mysql-slave-1h/sql
$ mkdir -p /storage/mysql-slave-6h/mysql.conf.d
$ mkdir -p /storage/mysql-slave-6h/datadir
$ mkdir -p /storage/mysql-slave-6h/sqlKatalog "mysql.conf.d" będzie przechowywać nasz niestandardowy plik konfiguracyjny MySQL i zostanie zmapowany do kontenera w /etc/mysql.conf.d. "datadir" to miejsce, w którym chcemy, aby Docker przechowywał katalog danych MySQL, który mapuje do /var/lib/mysql kontenera, a katalog "sql" przechowuje nasze pliki SQL - kopie zapasowe plików w formacie .sql lub .sql.gz do etapu urządzenie podrzędne przed replikacją, a także pliki .sql w celu zautomatyzowania konfiguracji i uruchamiania replikacji.
15-minutowe opóźnione urządzenie podrzędne
Przygotuj plik konfiguracyjny MySQL dla naszego 15-minutowego opóźnionego urządzenia podrzędnego:
$ vim /storage/mysql-slave-15m/mysql.conf.d/my.cnfI dodaj następujące wiersze:
[mysqld]
server_id=10015
binlog_format=ROW
log_bin=binlog
log_slave_updates=1
gtid_mode=ON
enforce_gtid_consistency=1
relay_log=relay-bin
expire_logs_days=7
read_only=ON** Wartość identyfikatora serwera, której użyliśmy dla tego urządzenia podrzędnego, to 10015.
Następnie w katalogu /storage/mysql-slave-15m/sql utwórz dwa pliki SQL, jeden do RESET MASTER (1reset_master.sql) i drugi do ustanowienia łącza replikacji za pomocą instrukcji CHANGE MASTER (3setup_slave.sql).
Utwórz plik tekstowy 1reset_master.sql i dodaj następującą linię:
RESET MASTER;Utwórz plik tekstowy 3setup_slave.sql i dodaj następujące wiersze:
CHANGE MASTER TO MASTER_HOST = '192.168.55.171', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'YlgSH6bLLy', MASTER_AUTO_POSITION = 1, MASTER_DELAY=900;
START SLAVE;MASTER_DELAY=900 to 15 minut (w sekundach). Następnie skopiuj plik kopii zapasowej pobrany z naszego mastera (który został przeniesiony do naszego hosta Docker) do katalogu "sql" i zmień jego nazwę na 2mysqldump_complete.sql.gz:
$ cp ~/mysqldump_complete.tar.gz /storage/mysql-slave-15m/sql/2mysqldump_complete.tar.gzOstateczny wygląd naszego katalogu "sql" powinien wyglądać mniej więcej tak:
$ pwd
/storage/mysql-slave-15m/sql
$ ls -1
1reset_master.sql
2mysqldump_complete.sql.gz
3setup_slave.sqlZwróć uwagę, że poprzedzamy nazwę pliku SQL liczbą całkowitą, aby określić kolejność wykonywania, gdy Docker inicjuje kontener MySQL.
Gdy wszystko będzie gotowe, uruchom kontener MySQL dla naszego 15-minutowego opóźnionego niewolnika:
$ docker run -d \
--name mysql-slave-15m \
-e MYSQL_ROOT_PASSWORD=password \
--mount type=bind,source=/storage/mysql-slave-15m/datadir,target=/var/lib/mysql \
--mount type=bind,source=/storage/mysql-slave-15m/mysql.conf.d,target=/etc/mysql/mysql.conf.d \
--mount type=bind,source=/storage/mysql-slave-15m/sql,target=/docker-entrypoint-initdb.d \
mysql:5.7** Wartość MYSQL_ROOT_PASSWORD musi być taka sama jak hasło roota MySQL na urządzeniu głównym.
Poniższe wiersze są tym, czego szukamy, aby sprawdzić, czy MySQL działa poprawnie i jest podłączony jako slave do naszego mastera (192.168.55.171):
$ docker logs -f mysql-slave-15m
...
2018-12-04T04:05:24.890244Z 0 [Note] mysqld: ready for connections.
Version: '5.7.24-log' socket: '/var/run/mysqld/mysqld.sock' port: 3306 MySQL Community Server (GPL)
2018-12-04T04:05:25.010032Z 2 [Note] Slave I/O thread for channel '': connected to master 'example@sqldat.com:3306',replication started in log 'FIRST' at position 4Następnie możesz zweryfikować status replikacji za pomocą następującej instrukcji:
$ docker exec -it mysql-slave-15m mysql -uroot -p -e 'show slave status\G'
...
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
SQL_Delay: 900
Auto_Position: 1
...W tym momencie nasz kontener podrzędny z 15-minutowym opóźnieniem replikuje się poprawnie, a nasza architektura wygląda mniej więcej tak:
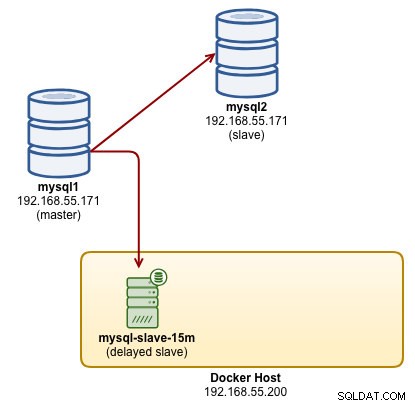
1-godzinne opóźnione urządzenie podrzędne
Przygotuj plik konfiguracyjny MySQL dla naszego 1-godzinnego opóźnionego urządzenia podrzędnego:
$ vim /storage/mysql-slave-1h/mysql.conf.d/my.cnfI dodaj następujące wiersze:
[mysqld]
server_id=10060
binlog_format=ROW
log_bin=binlog
log_slave_updates=1
gtid_mode=ON
enforce_gtid_consistency=1
relay_log=relay-bin
expire_logs_days=7
read_only=ON** Wartość identyfikatora serwera, której użyliśmy dla tego urządzenia podrzędnego, to 10060.
Następnie w katalogu /storage/mysql-slave-1h/sql utwórz dwa pliki SQL, jeden do RESET MASTER (1reset_master.sql) i drugi do ustanowienia łącza replikacji za pomocą instrukcji CHANGE MASTER (3setup_slave.sql).
Utwórz plik tekstowy 1reset_master.sql i dodaj następującą linię:
RESET MASTER;Utwórz plik tekstowy 3setup_slave.sql i dodaj następujące wiersze:
CHANGE MASTER TO MASTER_HOST = '192.168.55.171', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'YlgSH6bLLy', MASTER_AUTO_POSITION = 1, MASTER_DELAY=3600;
START SLAVE;MASTER_DELAY=3600 to 1 godzina (w sekundach). Następnie skopiuj plik kopii zapasowej pobrany z naszego mastera (który został przeniesiony do naszego hosta Docker) do katalogu "sql" i zmień jego nazwę na 2mysqldump_complete.sql.gz:
$ cp ~/mysqldump_complete.tar.gz /storage/mysql-slave-1h/sql/2mysqldump_complete.tar.gzOstateczny wygląd naszego katalogu "sql" powinien wyglądać mniej więcej tak:
$ pwd
/storage/mysql-slave-1h/sql
$ ls -1
1reset_master.sql
2mysqldump_complete.sql.gz
3setup_slave.sqlZwróć uwagę, że poprzedzamy nazwę pliku SQL liczbą całkowitą, aby określić kolejność wykonywania, gdy Docker inicjuje kontener MySQL.
Gdy wszystko będzie gotowe, uruchom kontener MySQL dla naszego 1-godzinnego opóźnionego urządzenia podrzędnego:
$ docker run -d \
--name mysql-slave-1h \
-e MYSQL_ROOT_PASSWORD=password \
--mount type=bind,source=/storage/mysql-slave-1h/datadir,target=/var/lib/mysql \
--mount type=bind,source=/storage/mysql-slave-1h/mysql.conf.d,target=/etc/mysql/mysql.conf.d \
--mount type=bind,source=/storage/mysql-slave-1h/sql,target=/docker-entrypoint-initdb.d \
mysql:5.7** Wartość MYSQL_ROOT_PASSWORD musi być taka sama jak hasło roota MySQL na urządzeniu głównym.
Poniższe wiersze są tym, czego szukamy, aby sprawdzić, czy MySQL działa poprawnie i jest podłączony jako slave do naszego mastera (192.168.55.171):
$ docker logs -f mysql-slave-1h
...
2018-12-04T04:05:24.890244Z 0 [Note] mysqld: ready for connections.
Version: '5.7.24-log' socket: '/var/run/mysqld/mysqld.sock' port: 3306 MySQL Community Server (GPL)
2018-12-04T04:05:25.010032Z 2 [Note] Slave I/O thread for channel '': connected to master 'example@sqldat.com:3306',replication started in log 'FIRST' at position 4Następnie możesz zweryfikować status replikacji za pomocą następującej instrukcji:
$ docker exec -it mysql-slave-1h mysql -uroot -p -e 'show slave status\G'
...
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
SQL_Delay: 3600
Auto_Position: 1
...W tym momencie nasze 15-minutowe i 1-godzinne opóźnione kontenery MySQL podrzędne są replikowane z głównego, a nasza architektura wygląda mniej więcej tak:
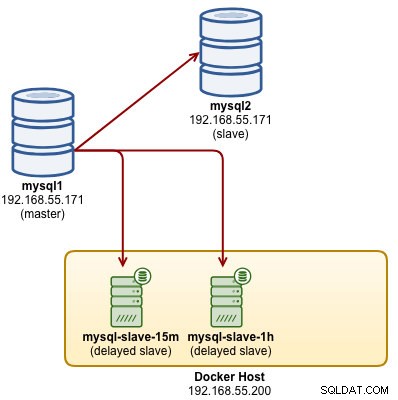
6-godzinne opóźnione urządzenie podrzędne
Przygotuj plik konfiguracyjny MySQL dla naszego urządzenia podrzędnego z 6-godzinnym opóźnieniem:
$ vim /storage/mysql-slave-15m/mysql.conf.d/my.cnfI dodaj następujące wiersze:
[mysqld]
server_id=10006
binlog_format=ROW
log_bin=binlog
log_slave_updates=1
gtid_mode=ON
enforce_gtid_consistency=1
relay_log=relay-bin
expire_logs_days=7
read_only=ON** Wartość identyfikatora serwera, której użyliśmy dla tego urządzenia podrzędnego, to 10006.
Następnie w katalogu /storage/mysql-slave-6h/sql utwórz dwa pliki SQL, jeden do RESET MASTER (1reset_master.sql) i drugi do ustanowienia łącza replikacji za pomocą instrukcji CHANGE MASTER (3setup_slave.sql).
Utwórz plik tekstowy 1reset_master.sql i dodaj następującą linię:
RESET MASTER;Utwórz plik tekstowy 3setup_slave.sql i dodaj następujące wiersze:
CHANGE MASTER TO MASTER_HOST = '192.168.55.171', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'YlgSH6bLLy', MASTER_AUTO_POSITION = 1, MASTER_DELAY=21600;
START SLAVE;MASTER_DELAY=21600 to 6 godzin (w sekundach). Następnie skopiuj plik kopii zapasowej pobrany z naszego mastera (który został przeniesiony do naszego hosta Docker) do katalogu "sql" i zmień jego nazwę na 2mysqldump_complete.sql.gz:
$ cp ~/mysqldump_complete.tar.gz /storage/mysql-slave-6h/sql/2mysqldump_complete.tar.gzOstateczny wygląd naszego katalogu "sql" powinien wyglądać mniej więcej tak:
$ pwd
/storage/mysql-slave-6h/sql
$ ls -1
1reset_master.sql
2mysqldump_complete.sql.gz
3setup_slave.sqlZwróć uwagę, że poprzedzamy nazwę pliku SQL liczbą całkowitą, aby określić kolejność wykonywania, gdy Docker inicjuje kontener MySQL.
Gdy wszystko będzie gotowe, uruchom kontener MySQL dla naszego 6-godzinnego opóźnionego urządzenia podrzędnego:
$ docker run -d \
--name mysql-slave-6h \
-e MYSQL_ROOT_PASSWORD=password \
--mount type=bind,source=/storage/mysql-slave-6h/datadir,target=/var/lib/mysql \
--mount type=bind,source=/storage/mysql-slave-6h/mysql.conf.d,target=/etc/mysql/mysql.conf.d \
--mount type=bind,source=/storage/mysql-slave-6h/sql,target=/docker-entrypoint-initdb.d \
mysql:5.7** Wartość MYSQL_ROOT_PASSWORD musi być taka sama jak hasło roota MySQL na urządzeniu głównym.
Poniższe wiersze są tym, czego szukamy, aby sprawdzić, czy MySQL działa poprawnie i jest podłączony jako slave do naszego mastera (192.168.55.171):
$ docker logs -f mysql-slave-6h
...
2018-12-04T04:05:24.890244Z 0 [Note] mysqld: ready for connections.
Version: '5.7.24-log' socket: '/var/run/mysqld/mysqld.sock' port: 3306 MySQL Community Server (GPL)
2018-12-04T04:05:25.010032Z 2 [Note] Slave I/O thread for channel '': connected to master 'example@sqldat.com:3306',replication started in log 'FIRST' at position 4Następnie możesz zweryfikować status replikacji za pomocą następującej instrukcji:
$ docker exec -it mysql-slave-6h mysql -uroot -p -e 'show slave status\G'
...
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
SQL_Delay: 21600
Auto_Position: 1
...W tym momencie nasze kontenery podrzędne opóźnione o 5 minut, 1 godzinę i 6 godzin replikują się poprawnie, a nasza architektura wygląda mniej więcej tak:
Scenariusz odzyskiwania po awarii
Załóżmy, że użytkownik przypadkowo upuścił niewłaściwą kolumnę na dużą tabelę. Rozważmy następującą instrukcję, która została wykonana na urządzeniu głównym:
mysql> USE shop;
mysql> ALTER TABLE settings DROP COLUMN status;Jeśli masz wystarczająco dużo szczęścia, aby natychmiast to zrealizować, możesz użyć 15-minutowego opóźnionego niewolnika, aby dogonić moment przed katastrofą i awansować go na nadrzędnego lub wyeksportować brakujące dane i przywrócić je na nadrzędnym.
Po pierwsze, musimy znaleźć pozycję dziennika binarnego przed katastrofą. Pobierz czas teraz() na wzorcu:
mysql> SELECT now();
+---------------------+
| now() |
+---------------------+
| 2018-12-04 14:55:41 |
+---------------------+Następnie pobierz aktywny binarny plik dziennika na master:
mysql> SHOW MASTER STATUS;
+---------------+----------+--------------+------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+---------------+----------+--------------+------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| binlog.000004 | 20260658 | | | 1560665e-ed2b-11e8-93fa-000c29b7f985:1-12031,
1b235f7a-d37b-11e8-9c3e-000c29bafe8f:1-62519,
1d8dc60a-e817-11e8-82ff-000c29bafe8f:1-326575,
791748b3-d37a-11e8-b03a-000c29b7f985:1-374 |
+---------------+----------+--------------+------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+Używając tego samego formatu daty, wyodrębnij żądane informacje z dziennika binarnego binlog.000004. Szacujemy czas rozpoczęcia czytania z binlogu około 20 minut temu (2018-12-04 14:35:00) i filtrujemy dane wyjściowe, aby pokazać 25 wierszy przed instrukcją „drop column”:
$ mysqlbinlog --start-datetime="2018-12-04 14:35:00" --stop-datetime="2018-12-04 14:55:41" /var/lib/mysql/binlog.000004 | grep -i -B 25 "drop column"
'/*!*/;
# at 19379172
#181204 14:54:45 server id 1 end_log_pos 19379232 CRC32 0x0716e7a2 Table_map: `shop`.`settings` mapped to number 766
# at 19379232
#181204 14:54:45 server id 1 end_log_pos 19379460 CRC32 0xa6187edd Write_rows: table id 766 flags: STMT_END_F
BINLOG '
tSQGXBMBAAAAPAAAACC0JwEAAP4CAAAAAAEABnNidGVzdAAHc2J0ZXN0MgAFAwP+/gME/nj+PBCi
5xYH
tSQGXB4BAAAA5AAAAAS1JwEAAP4CAAAAAAEAAgAF/+AYwwAAysYAAHc0ODYyMjI0NjI5OC0zNDE2
OTY3MjY5OS02MDQ1NTQwOTY1Ny01MjY2MDQ0MDcwOC05NDA0NzQzOTUwMS00OTA2MTAxNzgwNC05
OTIyMzM3NzEwOS05NzIwMzc5NTA4OC0yODAzOTU2NjQ2MC0zNzY0ODg3MTYzOTswMTM0MjAwNTcw
Ni02Mjk1ODMzMzExNi00NzQ1MjMxODA1OS0zODk4MDQwMjk5MS03OTc4MTA3OTkwNQEAAADdfhim
'/*!*/;
# at 19379460
#181204 14:54:45 server id 1 end_log_pos 19379491 CRC32 0x71f00e63 Xid = 622405
COMMIT/*!*/;
# at 19379491
#181204 14:54:46 server id 1 end_log_pos 19379556 CRC32 0x62b78c9e GTID last_committed=11507 sequence_number=11508 rbr_only=no
SET @@SESSION.GTID_NEXT= '1560665e-ed2b-11e8-93fa-000c29b7f985:11508'/*!*/;
# at 19379556
#181204 14:54:46 server id 1 end_log_pos 19379672 CRC32 0xc222542a Query thread_id=3162 exec_time=1 error_code=0
SET TIMESTAMP=1543906486/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
ALTER TABLE settings DROP COLUMN statusW kilku dolnych wierszach danych wyjściowych mysqlbinlog powinno znajdować się błędne polecenie, które zostało wykonane na pozycji 19379556. Pozycja, którą powinniśmy przywrócić, znajduje się o jeden krok wcześniej, czyli na pozycji 19379491. To jest pozycja binlogu, w której chcemy opóźniony niewolnik do osiągnięcia.
Następnie na wybranym opóźnionym urządzeniu podrzędnym zatrzymaj urządzenie podrzędne opóźnionej replikacji i ponownie uruchom urządzenie podrzędne do ustalonej pozycji końcowej, którą omówiliśmy powyżej:
$ docker exec -it mysql-slave-15m mysql -uroot -p
mysql> STOP SLAVE;
mysql> START SLAVE UNTIL MASTER_LOG_FILE = 'binlog.000004', MASTER_LOG_POS = 19379491;Monitoruj stan replikacji i poczekaj, aż Exec_Master_Log_Pos osiągnie wartość Until_Log_Pos. To może zająć trochę czasu. Po złapaniu powinieneś zobaczyć następujące informacje:
$ docker exec -it mysql-slave-15m mysql -uroot -p -e 'SHOW SLAVE STATUS\G'
...
Exec_Master_Log_Pos: 19379491
Relay_Log_Space: 50552186
Until_Condition: Master
Until_Log_File: binlog.000004
Until_Log_Pos: 19379491
...Na koniec sprawdź, czy brakujące dane, których szukaliśmy, są tam (kolumna „status” nadal istnieje):
mysql> DESCRIBE shop.settings;
+--------+------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------+------------------+------+-----+---------+----------------+
| id | int(10) unsigned | NO | PRI | NULL | auto_increment |
| sid | int(10) unsigned | NO | MUL | 0 | |
| param | varchar(100) | NO | | | |
| value | varchar(255) | NO | | | |
| status | int(11) | YES | | 1 | |
+--------+------------------+------+-----+---------+----------------+Następnie wyeksportuj tabelę z naszego kontenera podrzędnego i przenieś ją na serwer główny:
$ docker exec -it mysql-slave-1h mysqldump -uroot -ppassword --single-transaction shop settings > shop_settings.sqlUpuść problematyczną tabelę i przywróć ją z powrotem do urządzenia głównego:
$ mysql -uroot -p -e 'DROP TABLE shop.settings'
$ mysqldump -uroot -p -e shop < shop_setttings.sqlTeraz przywróciliśmy nasz stół do pierwotnego stanu sprzed katastrofalnego wydarzenia. Podsumowując, opóźniona replikacja może być wykorzystywana do kilku celów:
- W celu ochrony przed błędami użytkownika na urządzeniu głównym. Administrator DBA może cofnąć opóźnionego niewolnika do czasu tuż przed katastrofą.
- Aby przetestować zachowanie systemu w przypadku opóźnienia. Na przykład w aplikacji opóźnienie może być spowodowane dużym obciążeniem urządzenia podrzędnego. Jednak wygenerowanie takiego poziomu obciążenia może być trudne. Opóźniona replikacja może symulować opóźnienie bez konieczności symulowania obciążenia. Może być również używany do debugowania warunków związanych z opóźnionym urządzeniem podrzędnym.
- Aby sprawdzić, jak wyglądała baza danych w przeszłości, bez konieczności ponownego ładowania kopii zapasowej. Na przykład, jeśli opóźnienie wynosi jeden tydzień, a DBA musi zobaczyć, jak wyglądała baza danych przed rozwojem przez ostatnie kilka dni, opóźnione urządzenie podrzędne może zostać sprawdzone.
Ostateczne myśli
Dzięki Dockerowi można wydajnie uruchamiać wiele instancji MySQL na tym samym hoście fizycznym. Możesz użyć narzędzi do aranżacji platformy Docker, takich jak Docker Compose i Swarm, aby uprościć wdrażanie wielokontenerowe, w przeciwieństwie do kroków przedstawionych w tym poście na blogu.