Dlaczego warto wybrać replikację MySQL?
Kilka podstawowych informacji na temat technologii replikacji. Replikacja MySQL nie jest skomplikowana! Jest łatwy do wdrożenia, monitorowania i dostrajania, ponieważ istnieją różne zasoby, z których możesz skorzystać – google jest jednym z nich. Replikacja MySQL nie zawiera wielu zmiennych konfiguracyjnych do dostrojenia. Błędy logiczne SQL_THREAD i IO_THREAD nie są trudne do zrozumienia i naprawienia. Replikacja MySQL jest obecnie bardzo popularna i oferuje prosty sposób implementacji bazy danych o wysokiej dostępności. Potężne funkcje, takie jak GTID (Global Transaction Identifier) zamiast staromodnej pozycji dziennika binarnego lub bezstratna replikacja półsynchroniczna, czynią go bardziej niezawodnym.
Jak widzieliśmy we wcześniejszym poście, opóźnienie sieci jest dużym wyzwaniem przy wyborze rozwiązania o wysokiej dostępności. Korzystanie z replikacji MySQL ma tę zaletę, że nie jest tak wrażliwe na opóźnienia. Nie implementuje żadnej replikacji opartej na certyfikacji, w przeciwieństwie do Galera Cluster wykorzystuje techniki komunikacji grupowej i porządkowania transakcji w celu uzyskania replikacji synchronicznej. W związku z tym nie ma wymogu, aby wszystkie węzły musiały certyfikować zestaw zapisów i nie trzeba czekać na zatwierdzenie na innym urządzeniu podrzędnym lub replice.
Wybór tradycyjnej replikacji MySQL z asynchronicznym podejściem podstawowy-dodatkowy zapewnia szybkość, jeśli chodzi o obsługę transakcji z poziomu głównego; nie musi czekać, aż urządzenia podrzędne zsynchronizują się lub zatwierdzą transakcje. Konfiguracja zazwyczaj ma główny (główny) i co najmniej jeden wtórny (podrzędny). Dlatego jest to system nie współdzielony, w którym wszystkie serwery mają domyślnie pełną kopię danych. Oczywiście są wady. Integralność danych może stanowić problem, jeśli twoje urządzenia podrzędne nie mogą się replikować z powodu błędów wątków SQL i we/wy lub awarii. Alternatywnie, aby rozwiązać problemy z integralnością danych, możesz zdecydować się na implementację replikacji MySQL w wersji półsynchronicznej (lub nazywanej bezstratną replikacją półsynchronizowaną w MySQL 5.7). Działa to tak, że master musi czekać, aż replika potwierdzi wszystkie zdarzenia transakcji. Oznacza to, że musi zakończyć swoje zapisy w dzienniku przekaźników i opróżnić na dysk, zanim odeśle z powrotem do mastera odpowiedź ACK. Przy włączonej replikacji półsynchronicznej wątki lub sesje w masterze muszą czekać na potwierdzenie z repliki. Po otrzymaniu odpowiedzi ACK z repliki może następnie zatwierdzić transakcję. Poniższa ilustracja pokazuje, jak MySQL obsługuje replikację półsynchroniczną.
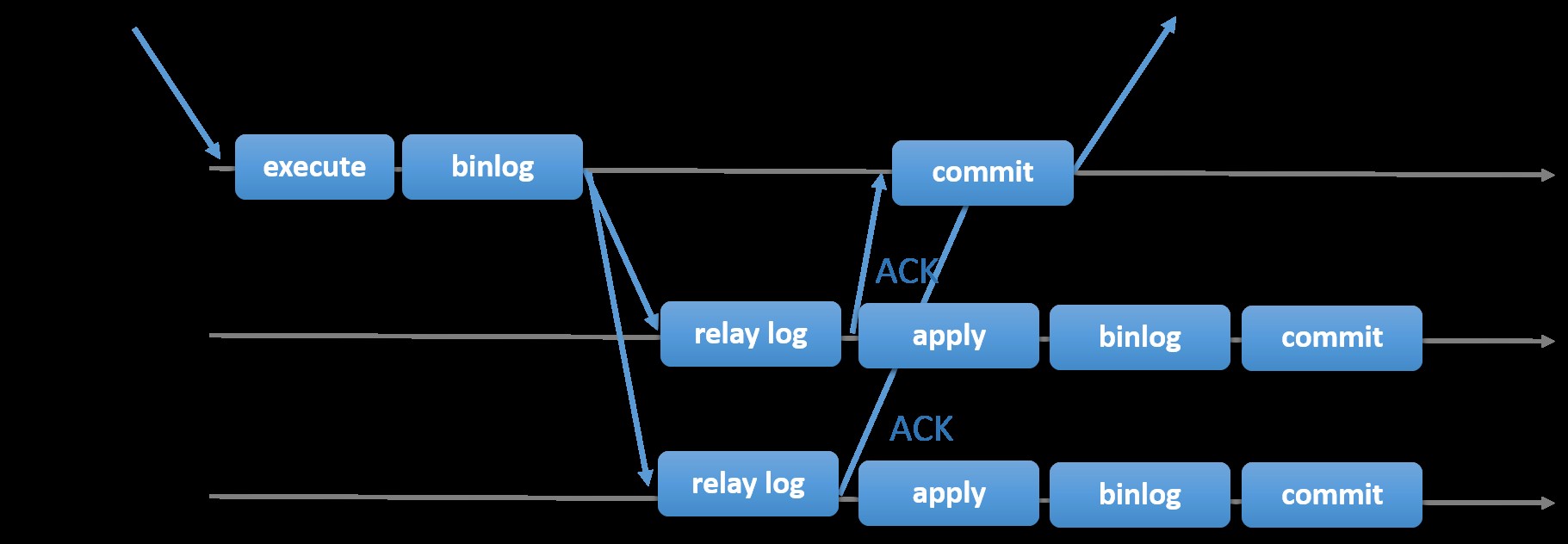 Obraz dzięki uprzejmości dokumentacji MySQL
Obraz dzięki uprzejmości dokumentacji MySQL Dzięki tej implementacji wszystkie zatwierdzone transakcje są już replikowane do co najmniej jednego urządzenia podrzędnego w przypadku awarii urządzenia głównego. Chociaż półsynchroniczny sam w sobie nie stanowi rozwiązania o wysokiej dostępności, ale jest składnikiem Twojego rozwiązania. Najlepiej, gdybyś znał swoje potrzeby i odpowiednio dostroił implementację półsynchronizacji. Dlatego też, jeśli pewna utrata danych jest akceptowalna, możesz zamiast tego użyć tradycyjnej replikacji asynchronicznej.
Replikacja oparta na GTID jest pomocna dla administratorów baz danych, ponieważ upraszcza zadanie przełączania awaryjnego, zwłaszcza gdy urządzenie podrzędne jest wskazywane na innego nadrzędnego lub nowego nadrzędnego. Oznacza to, że przy prostym ustawieniu MASTER_AUTO_POSITION=1 po ustawieniu prawidłowych poświadczeń hosta i replikacji rozpocznie się replikacja z urządzenia głównego bez konieczności znajdowania i określania poprawnych pozycji logów binarnych x i y. Dodanie obsługi replikacji równoległej zwiększa również liczbę wątków replikacji, ponieważ zwiększa szybkość przetwarzania zdarzeń z dziennika przekaźników.
W związku z tym MySQL Replication jest doskonałym komponentem do wyboru w porównaniu z innymi rozwiązaniami HA, jeśli odpowiada Twoim potrzebom.
Topologie replikacji MySQL
Wdrożenie replikacji MySQL w środowisku wielochmurowym z GCP (Google Cloud Platform) i AWS to nadal to samo podejście, jeśli musisz replikować lokalnie.
Istnieją różne topologie, które można skonfigurować i wdrożyć.
Master z replikacją Slave (pojedyncza replikacja)
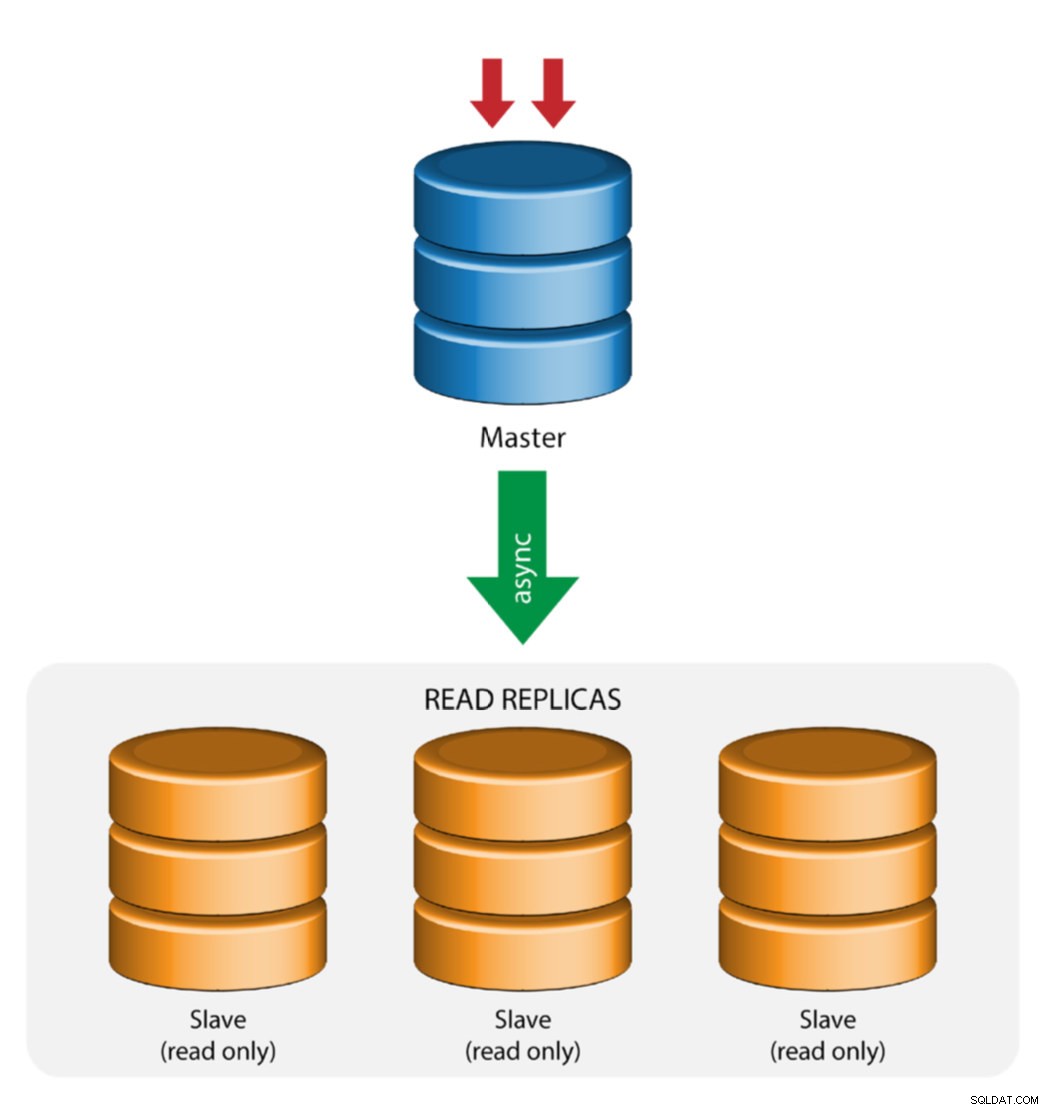
To najprostsza topologia replikacji MySQL. Jeden master otrzymuje zapisy, jeden lub więcej slave'ów replikuje się z tego samego mastera poprzez replikację asynchroniczną lub półsynchroniczną. Jeśli wyznaczony master ulegnie awarii, najbardziej aktualny slave musi zostać promowany jako nowy master. Pozostałe urządzenia podrzędne wznawiają replikację od nowego urządzenia nadrzędnego.
Master z przekaźnikami podrzędnymi (replikacja łańcuchowa)
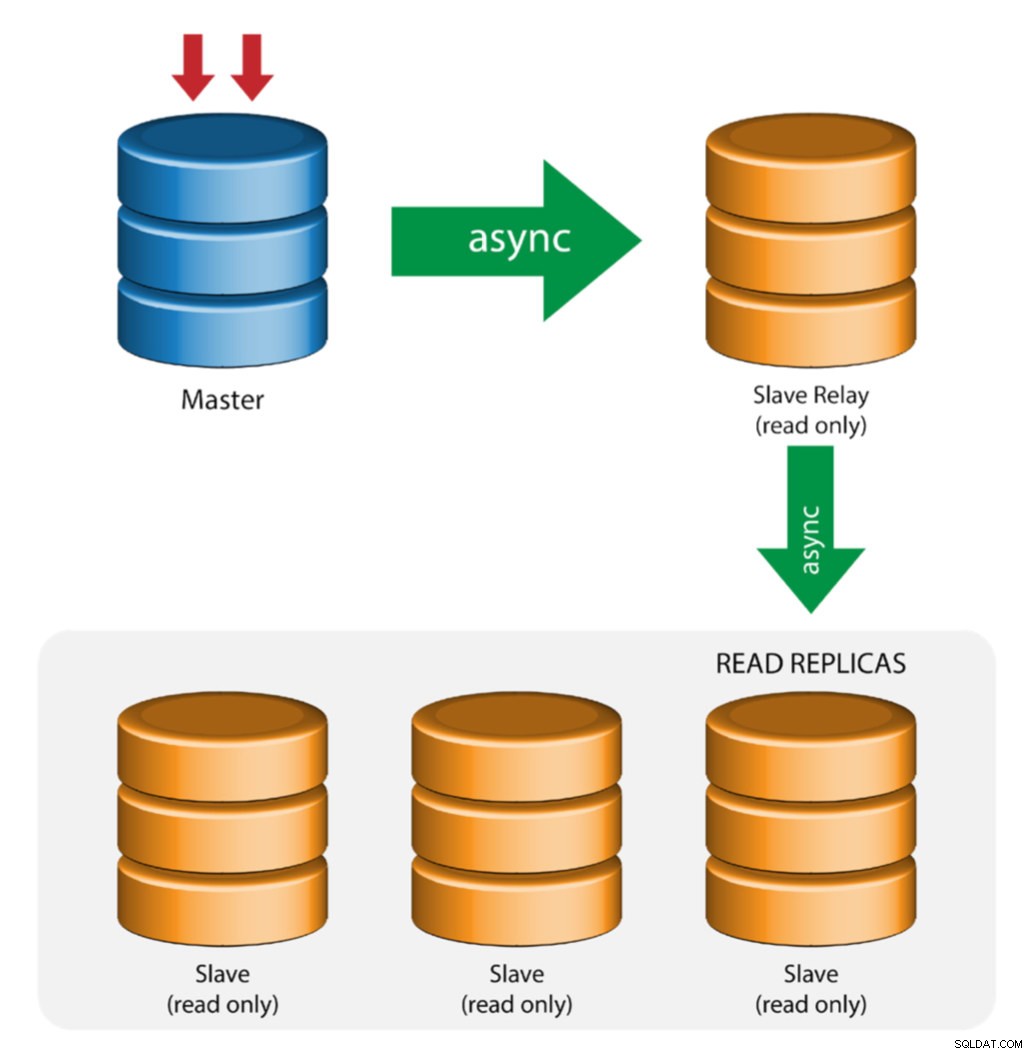
Ta konfiguracja używa pośredniego urządzenia nadrzędnego do działania jako przekaźnik do innych urządzeń podrzędnych w łańcuchu replikacji. Gdy do urządzenia nadrzędnego podłączonych jest wiele urządzeń podrzędnych, interfejs sieciowy urządzenia nadrzędnego może zostać przeciążony. Ta topologia umożliwia replikom do odczytu ściąganie strumienia replikacji z serwera przekazującego w celu odciążenia serwera głównego. Na serwerze przekaźnika podrzędnego należy włączyć logowanie binarne i log_slave_updates, dzięki czemu aktualizacje otrzymywane przez serwer podrzędny z serwera głównego są rejestrowane we własnym logu binarnym urządzenia podrzędnego.
Korzystanie z przekaźnika podrzędnego ma swoje problemy:
- log_slave_updates ma pewien spadek wydajności.
- Opóźnienie replikacji na serwerze przekaźnika podrzędnego wygeneruje opóźnienie na wszystkich jego serwerach podrzędnych.
- Nieuczciwe transakcje na serwerze przekaźnika podrzędnego infekują wszystkie jego serwery podrzędne.
- Jeśli serwer przekazujący podrzędny ulegnie awarii i nie używasz GTID, wszystkie jego podległe przestają się replikować i należy je ponownie zainicjować.
Master z aktywnym masterem (replikacja cykliczna)
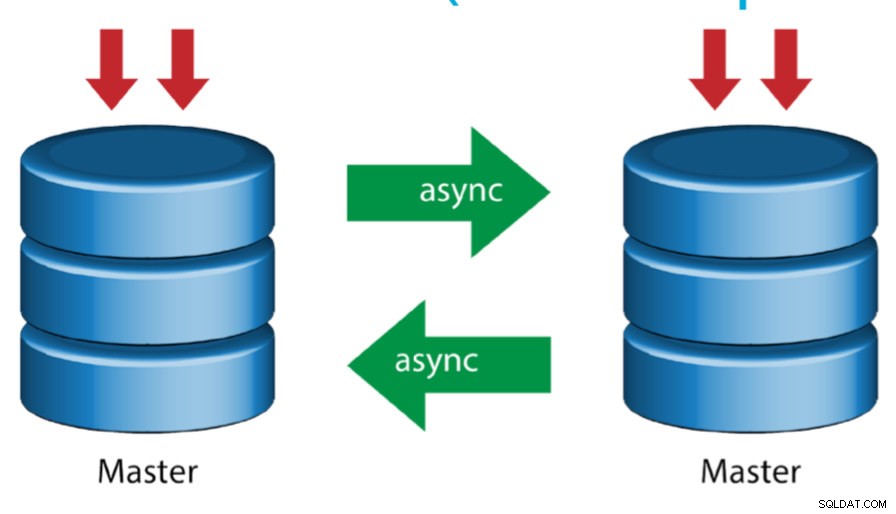
Ta konfiguracja, znana również jako topologia pierścienia, wymaga co najmniej dwóch serwerów MySQL, które działają jako master. Wszyscy mistrzowie otrzymują zapisy i generują binlogi z kilkoma zastrzeżeniami:
- Musisz ustawić przesunięcie automatycznego przyrostu na każdym serwerze, aby uniknąć kolizji kluczy podstawowych.
- Nie ma rozwiązania konfliktu.
- Replikacja MySQL nie obsługuje obecnie żadnego protokołu blokowania między urządzeniem nadrzędnym i podrzędnym, aby zagwarantować niepodzielność rozproszonej aktualizacji na dwóch różnych serwerach.
- Powszechną praktyką jest pisanie tylko do jednego mastera, a drugi master działa jako węzeł hot-standby. Mimo to, jeśli masz niewolników poniżej tego poziomu, musisz ręcznie przełączyć się na nowego mastera, jeśli wyznaczony master zawiedzie.
- ClusterControl obsługuje tę topologię (nie zaleca się stosowania wielu programów zapisujących w konfiguracji replikacji). Zobacz ten poprzedni blog na temat wdrażania za pomocą ClusterControl.
Master z Backup Master (wielokrotna replikacja)
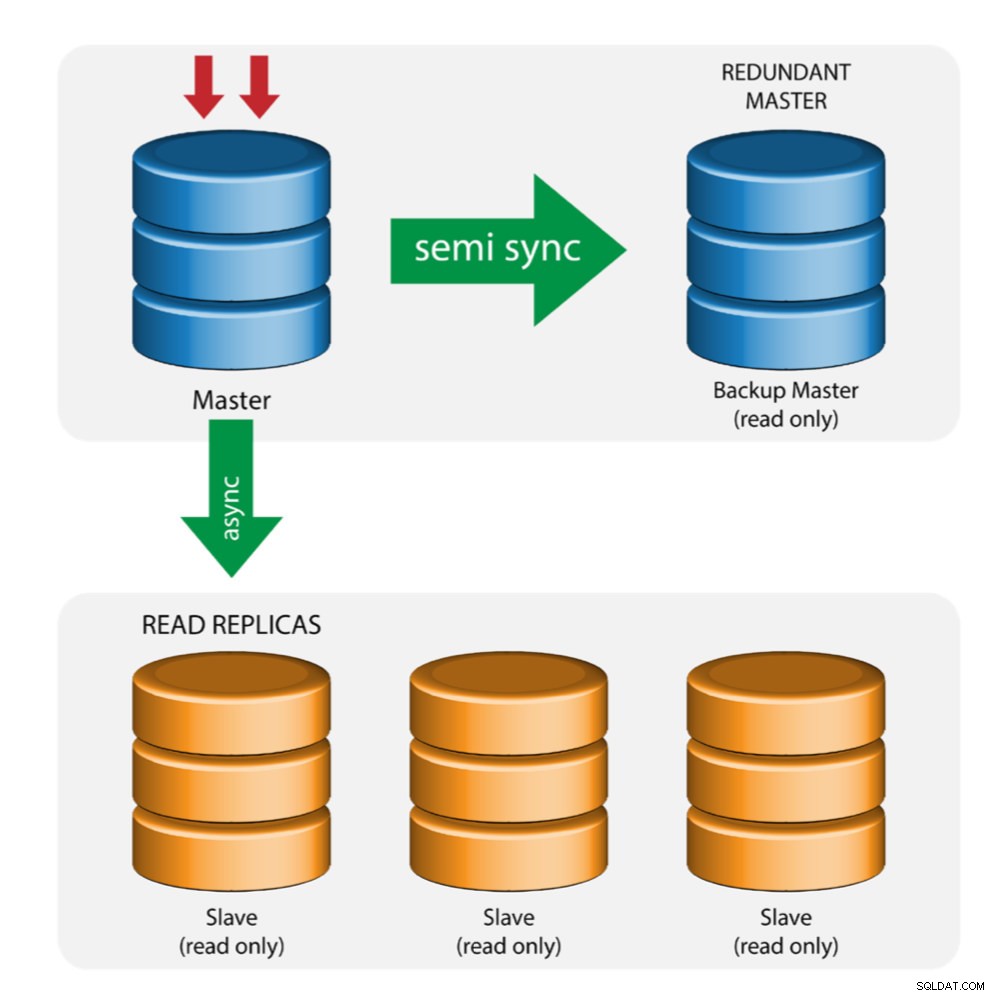
Master przesyła zmiany do zapasowego mastera i do jednego lub więcej slave'ów. Replikacja półsynchroniczna jest używana między masterem a backupem master. Master wysyła aktualizację do kopii zapasowej master i czeka z zatwierdzeniem transakcji. Backup master pobiera aktualizacje, zapisuje w swoim dzienniku przekaźników i opróżnia na dysk. Backup master następnie potwierdza odbiór transakcji do mastera i kontynuuje zatwierdzanie transakcji. Replikacja częściowo zsynchronizowana ma wpływ na wydajność, ale ryzyko utraty danych jest zminimalizowane.
Ta topologia działa dobrze podczas przełączania awaryjnego mastera w przypadku awarii mastera. Backup master działa jako serwer ciepłej gotowości, ponieważ ma największe prawdopodobieństwo posiadania aktualnych danych w porównaniu z innymi urządzeniami slave.
Wiele masterów do jednego slave (replikacja wieloźródłowa)
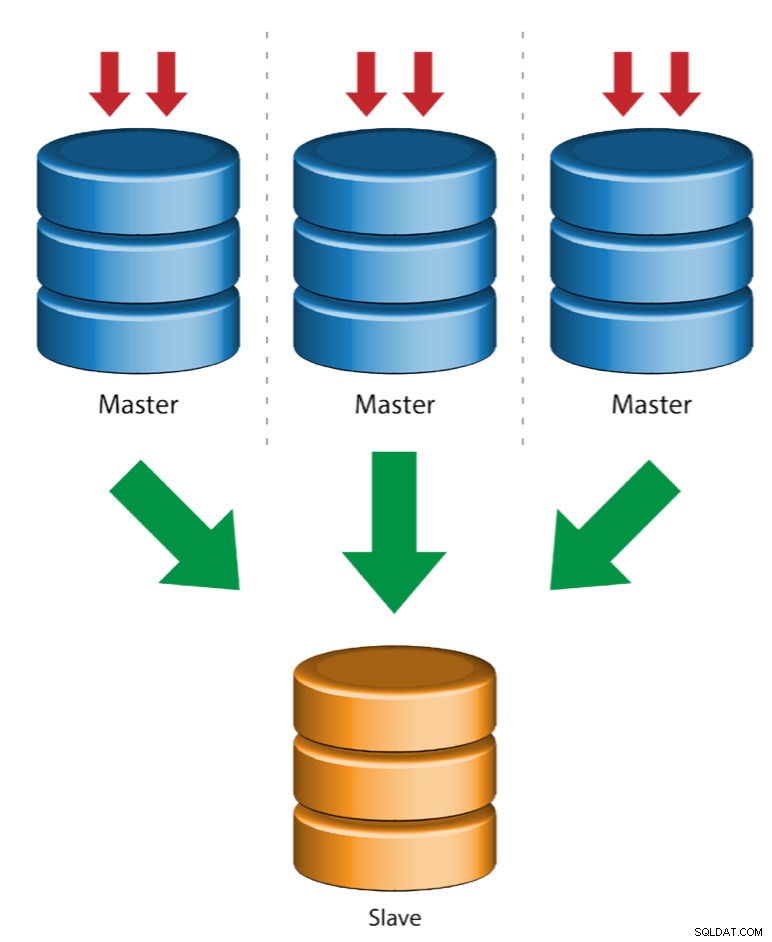
Multi-Source Replication umożliwia podrzędnemu replikacji otrzymywanie transakcji z wielu źródeł jednocześnie. Replikacja z wielu źródeł może być używana do tworzenia kopii zapasowych wielu serwerów na jednym serwerze, łączenia fragmentów tabel i konsolidacji danych z wielu serwerów na jednym serwerze.
MySQL i MariaDB mają różne implementacje replikacji wieloźródłowej, gdzie MariaDB musi mieć identyfikator GTID z identyfikatorem gtid-domain-id skonfigurowanym w celu rozróżnienia transakcji źródłowych, podczas gdy MySQL używa oddzielnego kanału replikacji dla każdego mastera, z którego replikuje się element podrzędny. W MySQL, master w topologii replikacji wieloźródłowej można skonfigurować tak, aby używał replikacji opartej na globalnym identyfikatorze transakcji (GTID) lub replikacji opartej na pozycji dziennika binarnego.
Więcej informacji na temat wieloźródłowej replikacji MariaDB można znaleźć w tym poście na blogu. W przypadku MySQL zapoznaj się z dokumentacją MySQL.
Galera z modułem replikacji (replikacja hybrydowa)
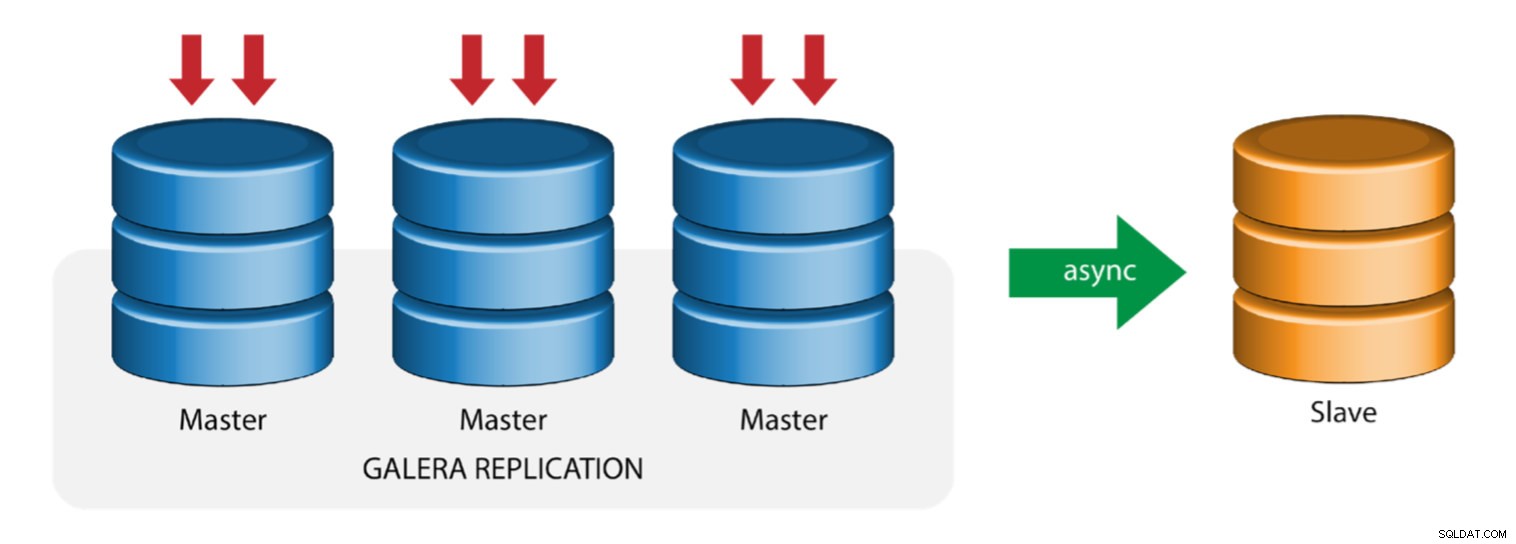
Replikacja hybrydowa to połączenie asynchronicznej replikacji MySQL i wirtualnie synchronicznej replikacji dostarczanej przez Galerę. Wdrożenie jest teraz uproszczone dzięki implementacji GTID w replikacji MySQL, gdzie konfiguracja i wykonywanie przełączania awaryjnego stało się prostym procesem po stronie podrzędnej.
Wydajność klastra Galera jest tak szybka, jak w przypadku najwolniejszego węzła. Posiadanie asynchronicznego urządzenia podrzędnego replikacji może zminimalizować wpływ na klaster, jeśli wysyłasz długotrwałe zapytania typu raportowania/OLAP do urządzenia podrzędnego lub wykonujesz ciężkie zadania wymagające blokad, takie jak mysqldump. Urządzenie podrzędne może również służyć jako kopia zapasowa na żywo do odzyskiwania po awarii na miejscu i poza siedzibą.
Replikacja hybrydowa jest obsługiwana przez ClusterControl i można ją wdrożyć bezpośrednio z interfejsu użytkownika ClusterControl. Aby uzyskać więcej informacji o tym, jak to zrobić, przeczytaj posty na blogu — Replikacja hybrydowa z MySQL 5.6 i Replikacja hybrydowa z MariaDB 10.x.
Przygotowywanie platform GCP i AWS
Problem „rzeczywistego świata”
W tym blogu zademonstrujemy i wykorzystamy topologię „wielokrotnej replikacji”, w której instancje na dwóch różnych platformach chmury publicznej będą komunikować się za pomocą replikacji MySQL w różnych regionach i w różnych strefach dostępności. Ten scenariusz jest oparty na rzeczywistym problemie, w którym organizacja chce zaprojektować swoją infrastrukturę na wielu platformach chmurowych pod kątem skalowalności, nadmiarowości, odporności/odporności na błędy. Podobne koncepcje miałyby zastosowanie dla MongoDB lub PostgreSQL.
Rozważmy organizację amerykańską z oddziałem zamorskim w południowo-wschodniej Azji. Nasz ruch jest duży w regionie Azji. Opóźnienie musi być niskie, gdy obsługuje się zapisy i odczyty, ale jednocześnie region USA może również pobierać rekordy pochodzące z ruchu z Azji.
Przepływ architektury chmury
W tej części omówię projekt architektoniczny. Po pierwsze, chcemy zaoferować wysoce bezpieczną warstwę, dla której nasze węzły Google Compute i AWS EC2 mogą komunikować się, aktualizować lub instalować pakiety z Internetu, bezpieczną, wysoce dostępną w przypadku awarii AZ (Strefa dostępności), która może się replikować i komunikować się z inną platformą w chmurze za pośrednictwem zabezpieczonej warstwy. Zobacz obraz poniżej dla ilustracji:

Na podstawie powyższej ilustracji w ramach platformy AWS wszystkie węzły działają w różnych strefach dostępności. Ma podsieć prywatną i publiczną, w której wszystkie węzły obliczeniowe znajdują się w podsieci prywatnej. W związku z tym może wyjść poza Internet, aby w razie potrzeby pobrać i zaktualizować swoje pakiety systemowe. Ma bramę VPN, dla której musi komunikować się z GCP w tym kanale, z pominięciem Internetu, ale za pośrednictwem bezpiecznego i prywatnego kanału. Podobnie jak GCP, wszystkie węzły obliczeniowe znajdują się w różnych strefach dostępności, używają bramy NAT do aktualizowania pakietów systemowych w razie potrzeby i używają połączenia VPN do interakcji z węzłami AWS, które są hostowane w innym regionie, np. Azji i Pacyfiku (Singapur). Z drugiej strony region z siedzibą w USA jest hostowany w ramach us-east1. Aby uzyskać dostęp do węzłów, jeden węzeł w architekturze służy jako węzeł-bastion, dla którego użyjemy go jako hosta przeskoku i zainstalujemy ClusterControl. Zostanie to omówione w dalszej części tego bloga.
Konfigurowanie środowisk GCP i AWS
Podczas rejestracji pierwszego konta GCP Google udostępnia domyślne konto VPC (Virtual Private Cloud). Dlatego najlepiej jest utworzyć oddzielny VPC niż domyślny i dostosować go do swoich potrzeb.
Naszym celem jest umieszczenie węzłów obliczeniowych w prywatnych podsieciach lub węzły nie zostaną skonfigurowane z publicznym IPv4. Dlatego obie chmury publiczne muszą mieć możliwość komunikowania się ze sobą. Węzły obliczeniowe AWS i GCP działają z różnymi CIDR, jak wspomniano wcześniej. Oto następujący CIDR:
Węzły obliczeniowe AWS: 172.21.0.0/16
Węzły obliczeniowe GCP: 10.142.0.0/20
W tej konfiguracji AWS przydzieliliśmy trzy podsieci, które nie mają bramy internetowej, ale bramę NAT; i jedną podsieć z bramą internetową. Każda z tych podsieci jest hostowana indywidualnie w różnych strefach dostępności (AZ).
ap-southeast-1a =172.21.1.0/24
ap-southeast-1b =172.21.8.0/24
ap-southeast-1c =172.21.24.0/24
W GCP używana jest domyślna podsieć utworzona w VPC pod us-east1, czyli 10.142.0.0/20 CIDR. Dlatego są to kroki, które możesz wykonać, aby skonfigurować platformę chmury wielodostępnej.
-
W tym ćwiczeniu utworzyłem VPC w regionie us-east1 z następującą podsiecią 10.142.0.0/20. Zobacz poniżej:

-
Zarezerwuj statyczny adres IP. To jest adres IP, który będziemy konfigurować jako bramę klienta w AWS
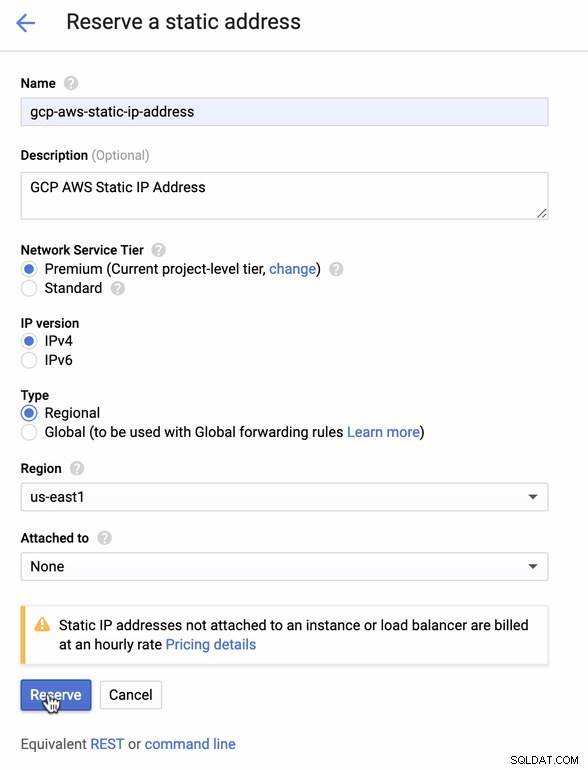
-
Ponieważ mamy podsieci (obsługiwane jako subnet-us-east1 ), przejdź do GCP -> Sieć VPC -> Sieci VPC i wybierz utworzony przez siebie VPC i przejdź do Reguł zapory . W tej sekcji dodaj reguły, określając ruch przychodzący i wychodzący. Zasadniczo są to reguły przychodzące/wychodzące w AWS lub zaporze sieciowej dla połączeń przychodzących i wychodzących. W tej konfiguracji otworzyłem wszystkie protokoły TCP z zakresu CIDR ustawionego w moim AWS i GCP VPC, aby uprościć to na potrzeby tego bloga. Dlatego nie jest to optymalny sposób na zapewnienie bezpieczeństwa. Zobacz obrazek poniżej:
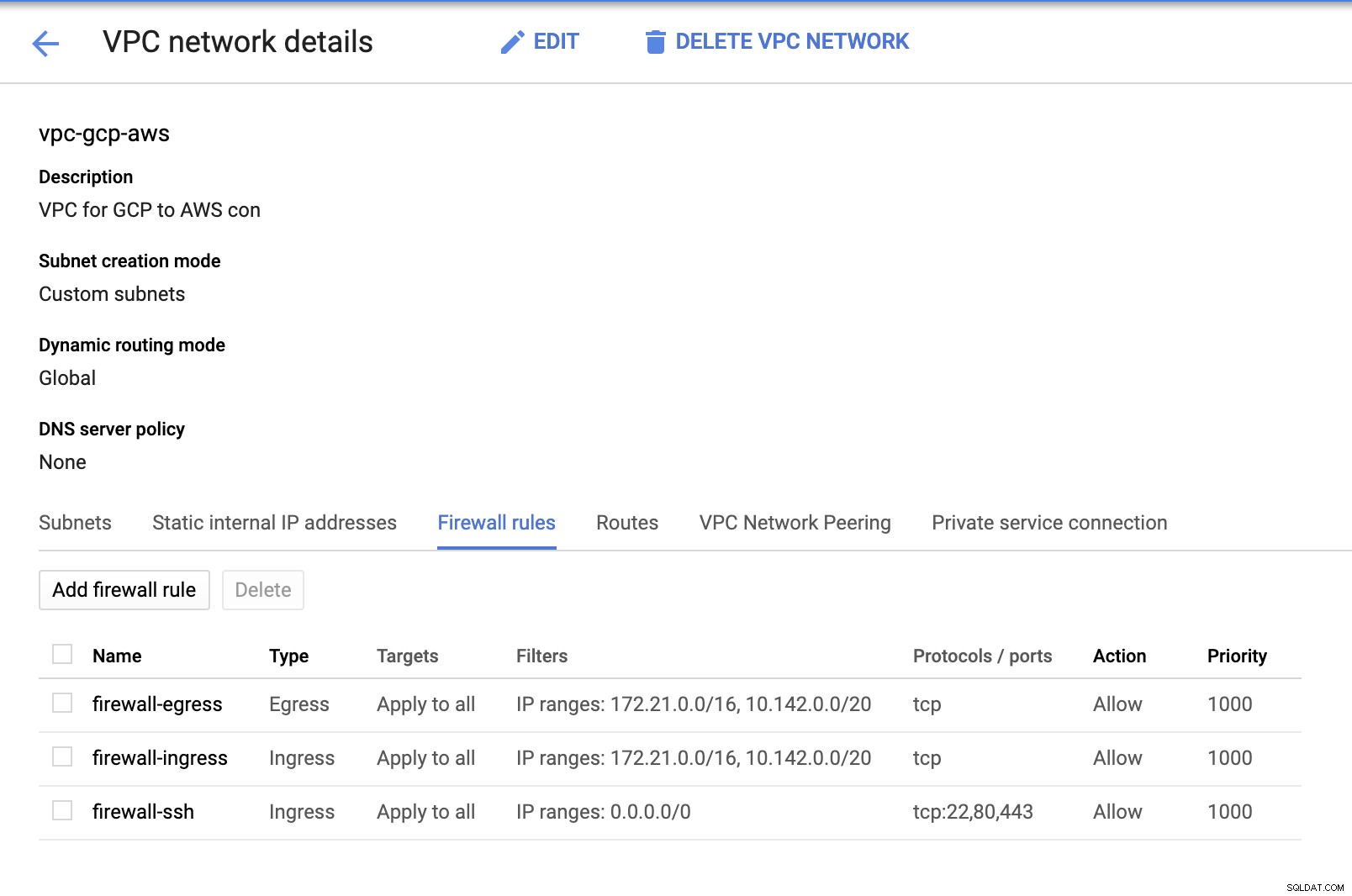
Tutaj firewall-ssh będzie używany do zezwalania na przychodzące połączenia ssh, HTTP i HTTPS.
-
Teraz przejdź na AWS i utwórz VPC. W tym blogu użyłem CIDR (Classless Inter-Domain Routing) 172.21.0.0/16
-
Utwórz podsieci, dla których musisz je przypisać w każdym AZ (Strefa dostępności); i przynajmniej zarezerwuj jedną podsieć dla podsieci publicznej, która będzie obsługiwać bramkę NAT, a reszta jest przeznaczona dla węzłów EC2.

-
Następnie utwórz tabelę tras i upewnij się, że „Cel” i „Cele” są ustawione poprawnie. Na potrzeby tego bloga utworzyłem 2 tabele tras. Taki, który będzie obsługiwał 3 punkty AZ, do których moje węzły obliczeniowe zostaną przypisane indywidualnie i zostanie przydzielony bez bramy internetowej, ponieważ nie będzie miał publicznego adresu IP. Wtedy drugi będzie obsługiwał bramkę NAT i będzie miał bramkę internetową, która będzie znajdować się w publicznej podsieci. Zobacz obrazek poniżej:

i jak wspomniano, moje przykładowe miejsce docelowe dla prywatnej trasy, która obsługuje 3 podsieci, pokazuje, że ma cel NAT Gateway plus cel Virtual Gateway, o którym wspomnę później w kolejnych krokach.

-
Następnie utwórz „Bramę internetową” i przypisz ją do VPC, który został wcześniej utworzony w sekcji AWS VPC. Ta brama internetowa powinna być ustawiona jako miejsce docelowe tylko w publicznej podsieci, ponieważ będzie to usługa, która musi łączyć się z Internetem. Oczywiście nazwa oznacza usługę bramy internetowej.
-
Następnie utwórz „Bramę NAT”. Tworząc „Bramę NAT”, upewnij się, że przypisałeś swój NAT do podsieci dostępnej publicznie. Brama NAT to Twój kanał dostępu do Internetu z Twojej prywatnej podsieci lub węzłów EC2, które nie mają przypisanego publicznego adresu IPv4. Następnie utwórz lub przypisz EIP (elastyczny adres IP), ponieważ w AWS tylko węzły obliczeniowe, które mają przypisany publiczny adres IPv4, mogą łączyć się bezpośrednio z Internetem.
-
Teraz w sekcji VPC -> Bezpieczeństwo -> Grupy zabezpieczeń (SG) , Twój utworzony VPC będzie miał domyślną SG. Dla tej konfiguracji stworzyłem „Reguły przychodzące” ze źródłami przypisanymi do każdego CIDR, tj. 10.142.0.0/20 w GCP i 172.21.0.0/16 w AWS. Zobacz poniżej:

W przypadku „Reguł ruchu wychodzącego” możesz to pozostawić bez zmian, ponieważ przypisywanie reguł do „Reguł ruchu przychodzącego” jest dwustronne, co oznacza, że otworzy się również dla „Reguł ruchu wychodzącego”. Zwróć uwagę, że nie jest to optymalny sposób ustawiania grupy zabezpieczeń; ale aby ułatwić tę konfigurację, poszerzyłem również zakres portów i źródło. Ponadto protokół jest specyficzny tylko dla połączeń TCP, ponieważ nie będziemy zajmować się UDP w tym blogu.
Dodatkowo możesz zostawić swoje VPC -> Bezpieczeństwo -> Listy ACL sieci nietknięty, o ile nie ZAKRYWA żadnych połączeń tcp z CIDR podanego w źródle. -
Następnie skonfigurujemy konfigurację VPN, która będzie hostowana na platformie AWS. W sekcji VPC -> Bramy klienta , utwórz bramę przy użyciu statycznego adresu IP utworzonego wcześniej w poprzednim kroku. Spójrz na poniższy obrazek:
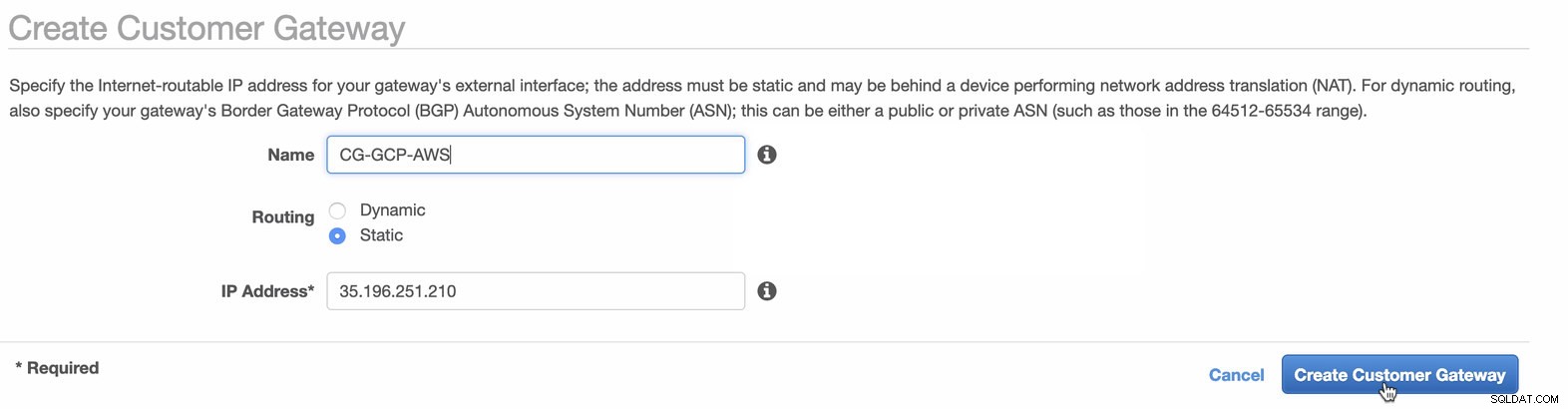
-
Następnie utwórz wirtualną bramę prywatną i dołącz ją do bieżącego VPC, który utworzyliśmy wcześniej w poprzednim kroku. Zobacz obrazek poniżej:

-
Teraz utwórz połączenie VPN, które będzie używane do połączenia lokacja-lokacja między AWS i GCP. Podczas tworzenia połączenia VPN upewnij się, że wybrałeś właściwą wirtualną bramę prywatną i bramę klienta, które utworzyliśmy w poprzednich krokach. Zobacz obrazek poniżej:
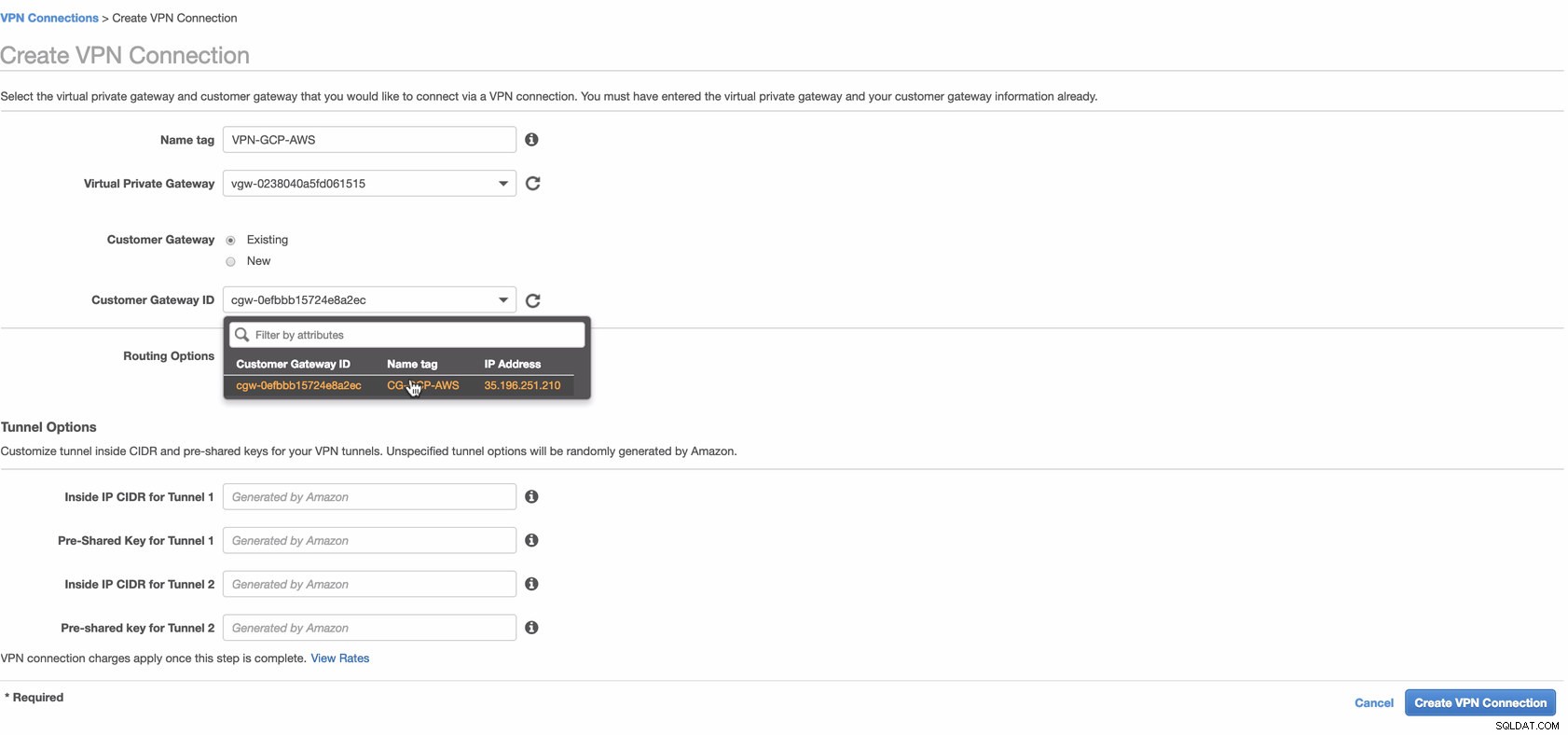
Może to zająć trochę czasu, gdy AWS tworzy połączenie VPN. Gdy Twoje połączenie VPN jest następnie udostępniane, możesz się zastanawiać, dlaczego na karcie Tunel (po wybraniu połączenia VPN) pokaże się, że zewnętrzny adres IP jest na dole. Jest to normalne, ponieważ klient nie nawiązał jeszcze połączenia. Spójrz na przykładowy obraz poniżej:

Gdy połączenie VPN będzie gotowe, wybierz utworzone połączenie VPN i pobierz konfigurację. Zawiera dane uwierzytelniające potrzebne do wykonania poniższych czynności w celu utworzenia połączenia VPN typu lokacja-lokacja z klientem.
Uwaga: W przypadku skonfigurowania sieci VPN, w której IPSEC JEST URUCHAMIANY ale Stan jest W DÓŁ tak jak na obrazku poniżej

jest to prawdopodobnie spowodowane nieprawidłowymi wartościami ustawionymi na określone parametry podczas konfigurowania sesji BGP lub routera w chmurze. Sprawdź to tutaj, aby rozwiązać problem z VPN.
-
Ponieważ mamy gotowe połączenie VPN hostowane w AWS, utwórzmy połączenie VPN w GCP. Wróćmy teraz do GCP i skonfigurujmy tam połączenie klienta. W GCP przejdź do GCP -> Łączność hybrydowa -> VPN . Upewnij się, że wybierasz właściwy region, który znajduje się na tym blogu, używamy us-east1 . Następnie wybierz statyczny adres IP utworzony w poprzednich krokach. Zobacz obrazek poniżej:
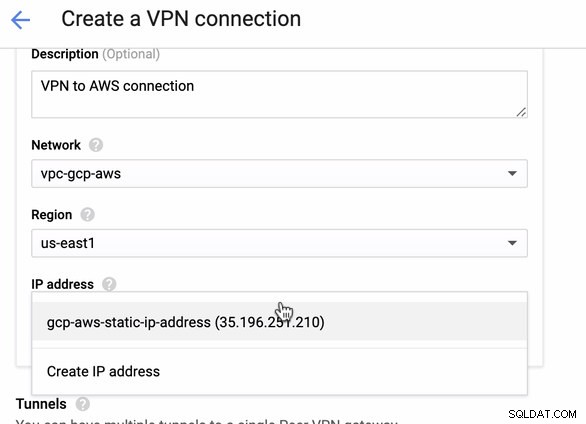
Następnie w tunelach W tym miejscu będziesz musiał skonfigurować na podstawie pobranych danych logowania z połączenia AWS VPN, które utworzyłeś wcześniej. Proponuję sprawdzić ten pomocny przewodnik od Google. Na przykład jeden z konfigurowanych tuneli jest pokazany na poniższym obrazku:
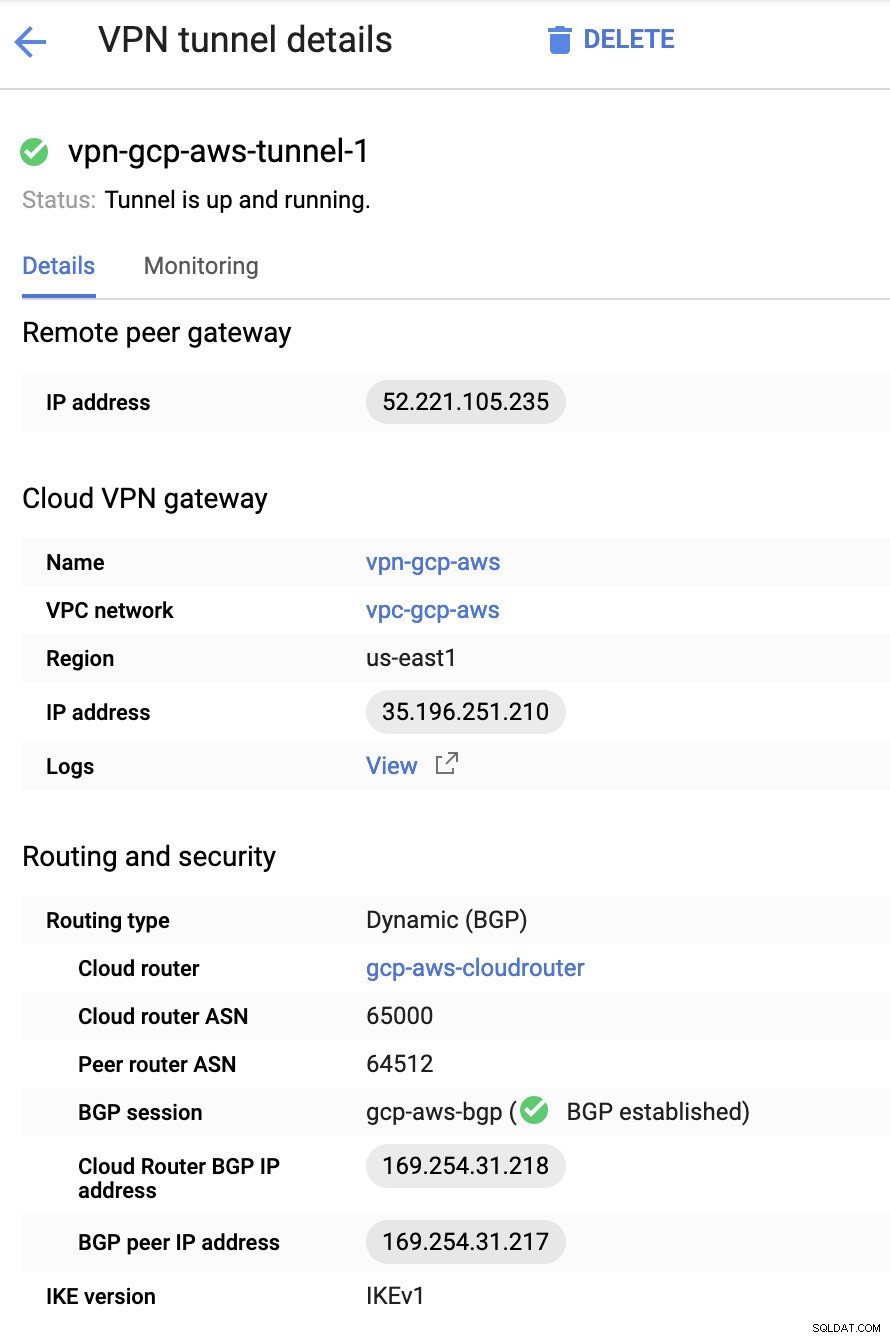
Zasadniczo najważniejsze są tutaj następujące rzeczy:
- Remote Peer Gateway:adres IP — jest to adres IP serwera VPN podany w sekcji Szczegóły tunelu -> Zewnętrzny adres IP . Nie należy tego mylić ze statycznym adresem IP, który stworzyliśmy w ramach GCP. To jest brama Cloud VPN -> adres IP chociaż.
- ASN routera w chmurze — domyślnie AWS używa 65000. Ale prawdopodobnie uzyskasz te informacje z pobranego pliku konfiguracyjnego.
- ASN routera równorzędnego — to jest ASN wirtualnej bramy prywatnej który znajduje się w pobranym pliku konfiguracyjnym.
- Adres IP routera Cloud Router BGP — to jest Brama klienta znaleźć w pobranym pliku konfiguracyjnym.
- Adres IP peera BGP — to jest wirtualna brama prywatna znaleźć w pobranym pliku konfiguracyjnym.
-
Spójrz na przykładowy plik konfiguracyjny, który mam poniżej:
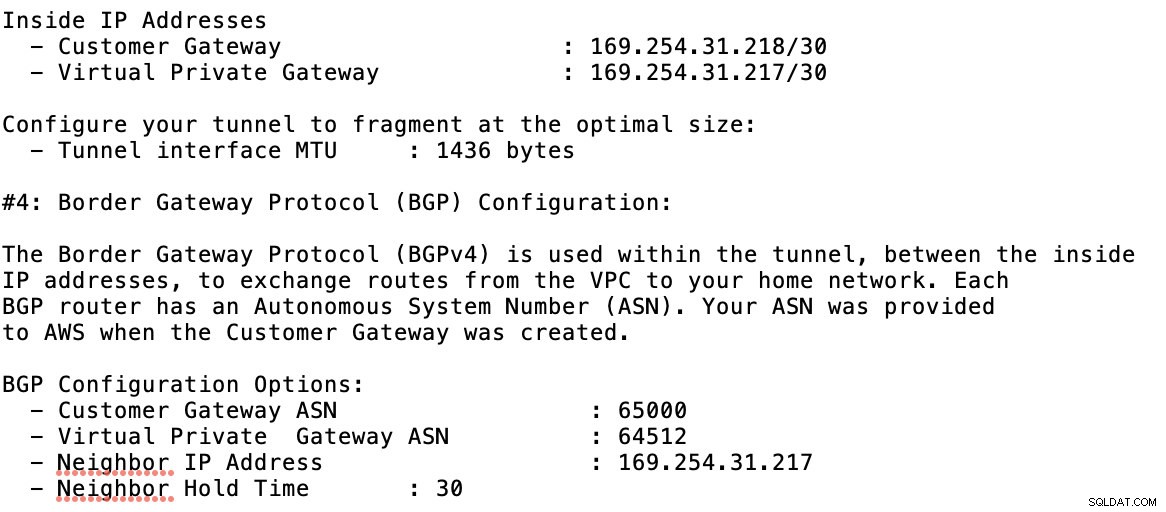
dla których musisz to dopasować podczas dodawania tunelu w ramach GCP -> Łączność hybrydowa -> VPN konfiguracja łączności. Zobacz obrazek poniżej, dla którego utworzyłem router w chmurze i sesję BGP podczas tworzenia przykładowego tunelu:
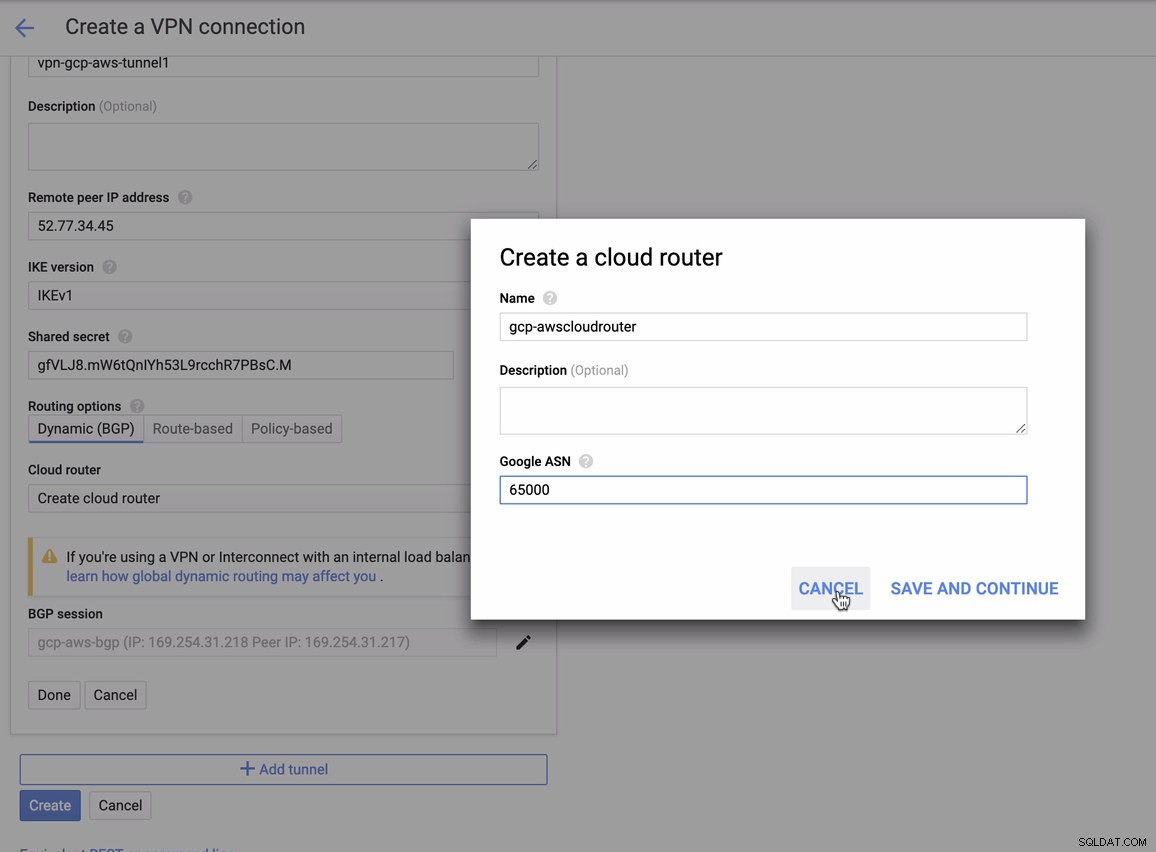
Następnie sesja BGP jako,

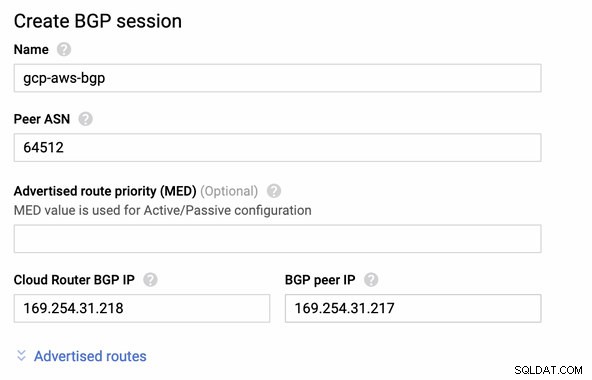
Uwaga: Pobrany plik konfiguracyjny zawiera tunel konfiguracyjny IPSec, dla którego AWS zawiera również dwa (2) serwery VPN gotowe do połączenia. Musisz ustawić oba z nich, aby uzyskać wysoką dostępną konfigurację. Po prawidłowym skonfigurowaniu obu tuneli połączenie AWS VPN na karcie Tunele pokaże, że oba zewnętrzny adres IP są w górze. Zobacz obrazek poniżej:

-
Wreszcie, ponieważ stworzyliśmy bramę internetową i bramę NAT, prawidłowo wypełnij podsieci publiczne i prywatne poprawnym Miejscem docelowym i Cel jak zauważono na zrzucie ekranu z poprzednich kroków. Można to skonfigurować, przechodząc do Usługi -> Sieć i dostarczanie treści -> VPC -> Tabele tras i wybierz utworzone tabele tras wymienione w poprzednich krokach. Zobacz obrazek poniżej:
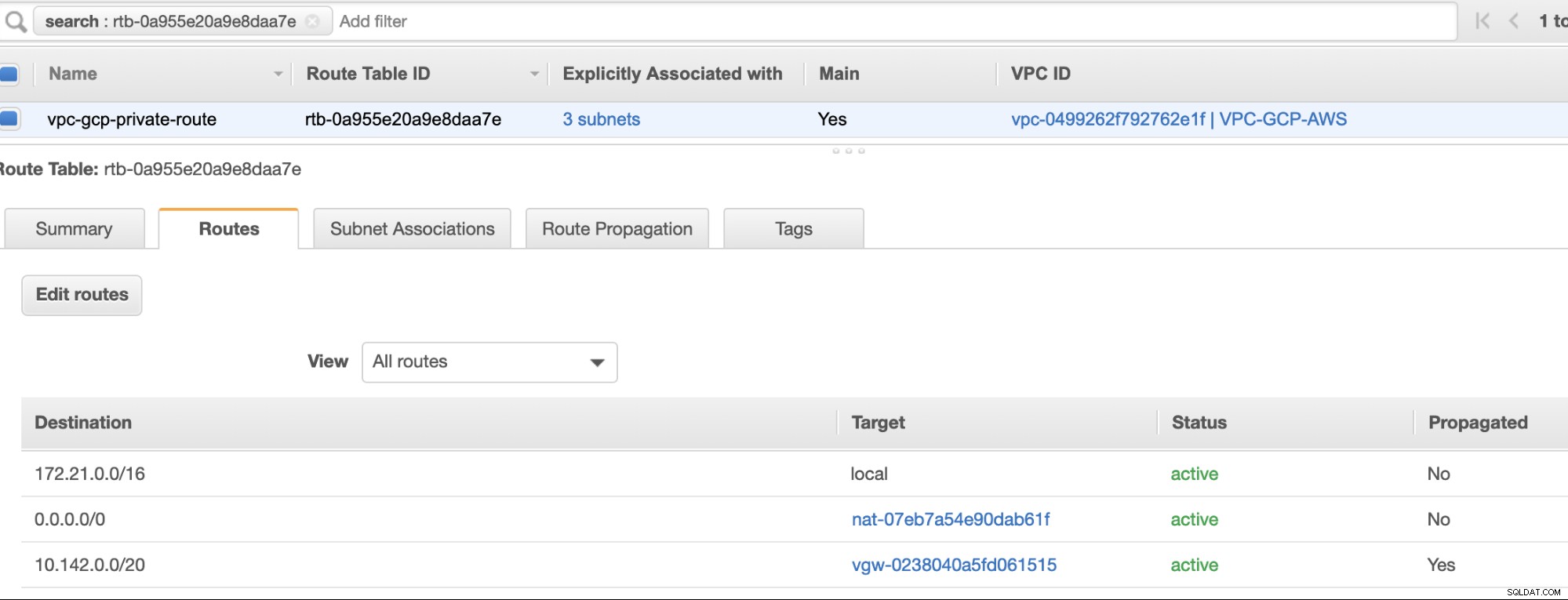
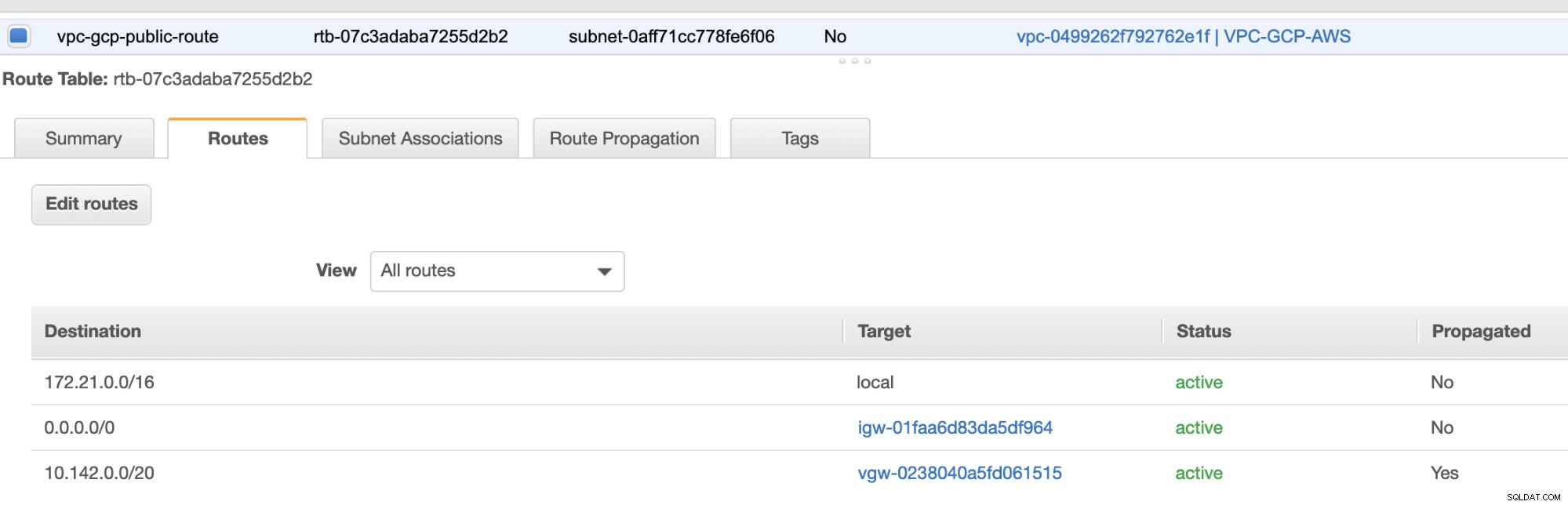
Jak zauważyłeś, igw-01faa6d83da5df964 to brama internetowa, którą stworzyliśmy i jest używana przez trasę publiczną. Podczas gdy tablica tras prywatnych ma miejsce docelowe i miejsce docelowe ustawione na nat-07eb7a54e90dab61f i oba mają Miejsce docelowe ustawić na 0.0.0.0/0, ponieważ pozwala na różne połączenia IPv4. Nie zapomnij również ustawić Propagacji trasy poprawnie dla wirtualnej bramy, jak widać na zrzucie ekranu, która ma cel vgw-0238040a5fd061515 . Po prostu kliknij Propagacja trasy i ustaw ją na Tak, tak jak na poniższym zrzucie ekranu:
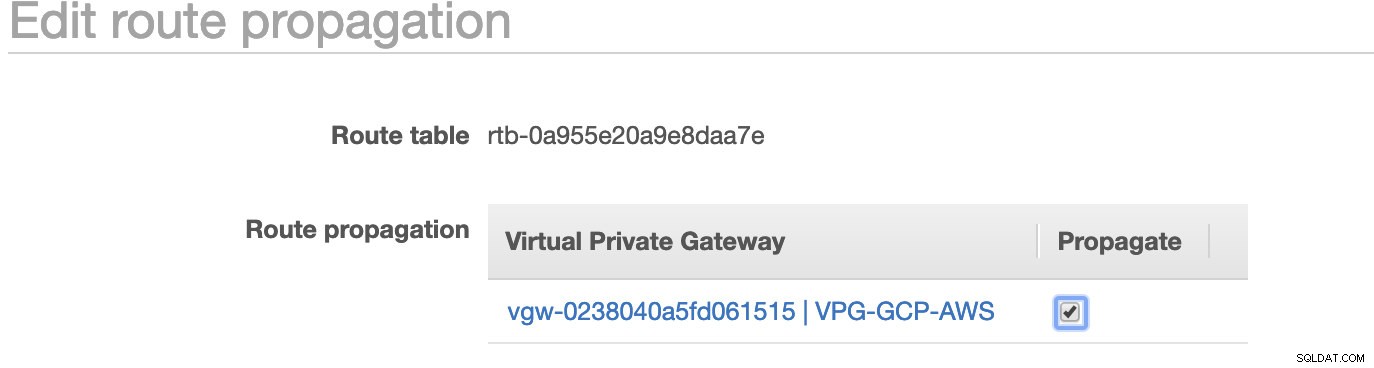
Jest to bardzo ważne, aby połączenie z zewnętrznych połączeń GCP kierowało się do tabel tras w AWS i nie wymagało dalszej pracy ręcznej. W przeciwnym razie GCP nie może nawiązać połączenia z AWS.
Teraz, gdy nasza sieć VPN działa, będziemy kontynuować konfigurowanie naszych prywatnych węzłów, w tym hosta bastionu.
Konfigurowanie węzłów Compute Engine
Skonfigurowanie węzłów Compute Engine/EC2 będzie szybkie i łatwe, ponieważ wszystko zostało już skonfigurowane. Nie będę wchodzić w te szczegóły, ale sprawdź poniższe zrzuty ekranu, ponieważ wyjaśniają konfigurację.
Węzły AWS EC2 :

Węzły obliczeniowe GCP :
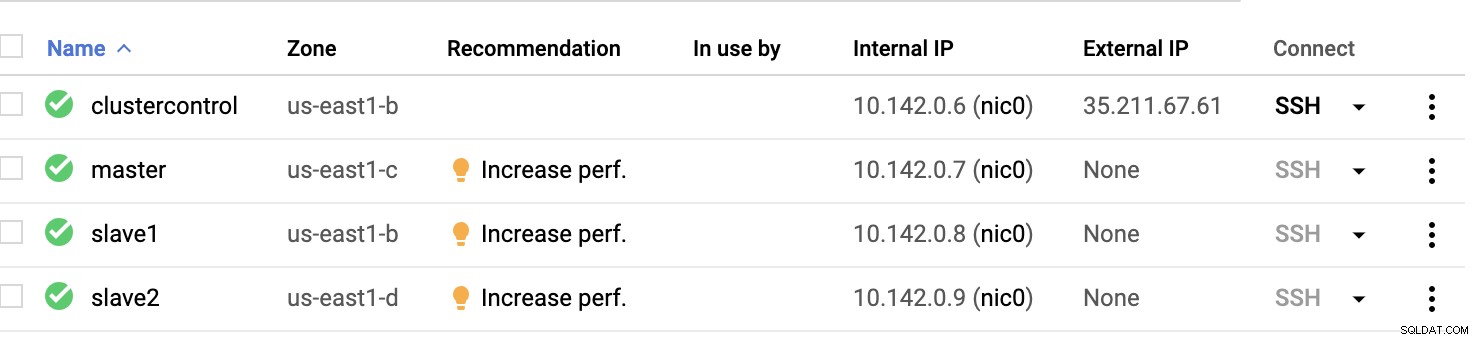
Zasadniczo w tej konfiguracji. Host kontrola klastra będzie bastionem lub hostem skokowym, dla którego zostanie zainstalowany ClusterControl. Oczywiście wszystkie węzły tutaj nie są dostępne przez Internet. Nie mają przypisanego zewnętrznego adresu IPv4, a węzły komunikują się przez bardzo bezpieczny kanał za pomocą VPN.
Wreszcie, wszystkie te węzły od AWS do GCP są skonfigurowane z jednym jednolitym użytkownikiem systemu z dostępem sudo, który jest potrzebny w naszej następnej sekcji. Zobacz, jak ClusterControl może ułatwić Ci życie w wielu chmurach i w wielu regionach.
ClusterControl na ratunek!!!
Obsługa wielu węzłów i na różnych platformach chmury publicznej, a także w innym „regionie” może być „naprawdę bolesnym i zniechęcającym” zadaniem. Jak skutecznie to monitorujesz? ClusterControl działa nie tylko jako szwajcarski nóż, ale także jako wirtualny DBA. Zobaczmy teraz, jak ClusterControl może ułatwić Ci życie.
Tworzenie klastra wielokrotnej replikacji za pomocą ClusterControl
Teraz spróbujmy utworzyć klaster replikacji master-slave MariaDB zgodnie z topologią „Multiple Replication”.
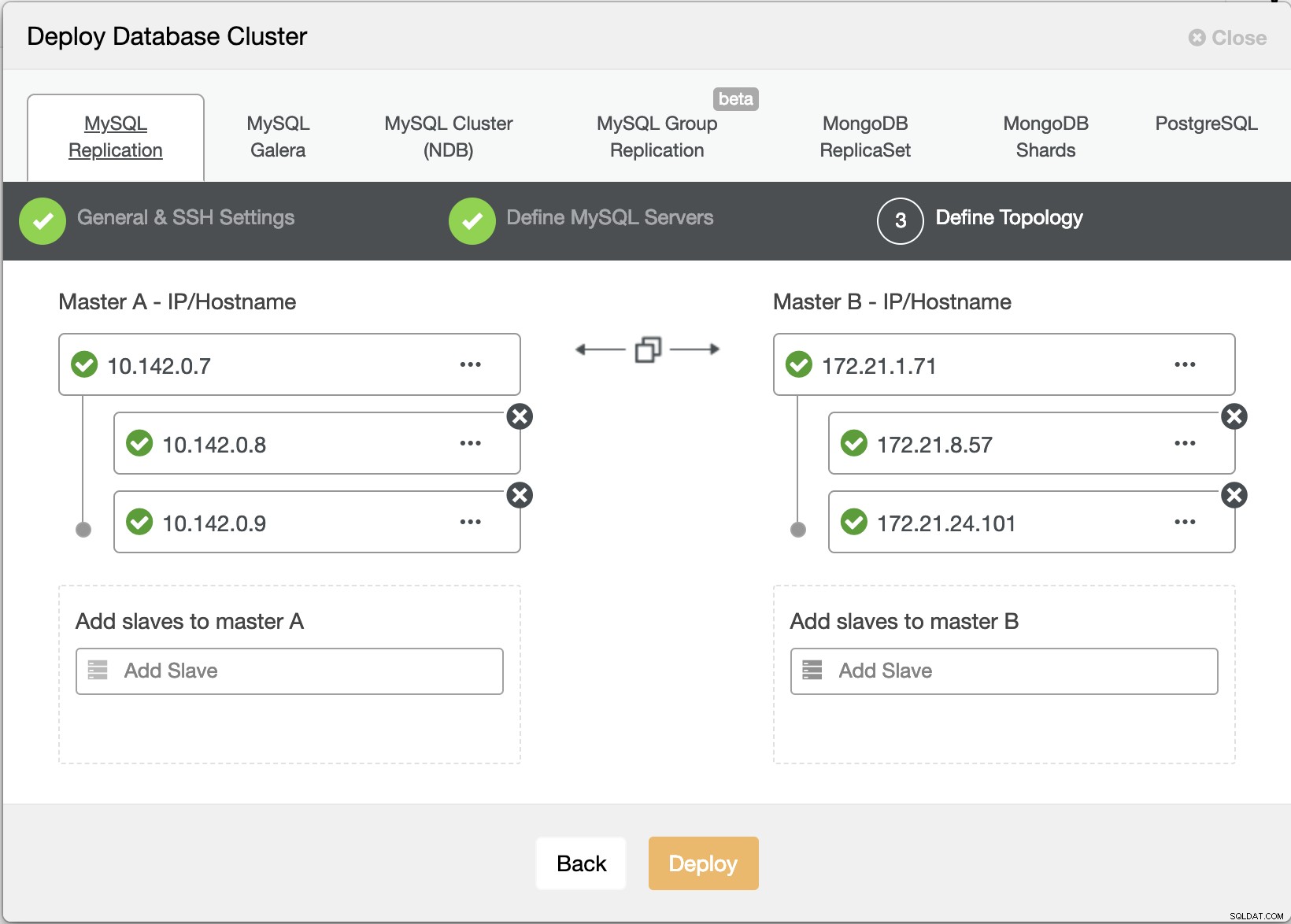 Kreator wdrażania ClusterControl
Kreator wdrażania ClusterControl Naciśnięcie Wdrażanie przycisk zainstaluje pakiety i odpowiednio skonfiguruje węzły. Stąd logiczny widok tego, jak wyglądałaby topologia:
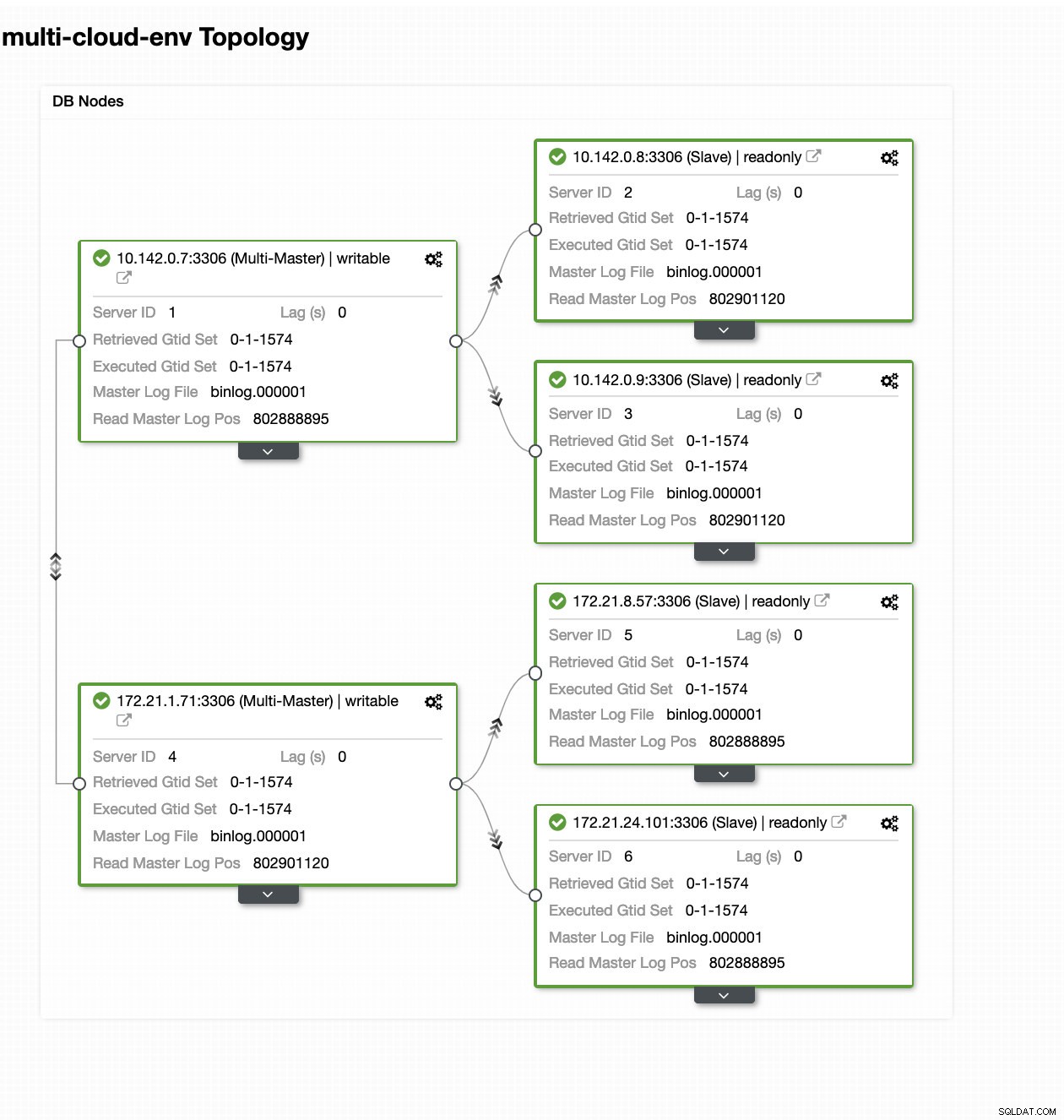 ClusterControl — widok topologii
ClusterControl — widok topologii Węzły 172.21.0.0/16 zakresów adresów IP są replikowane z głównego urządzenia działającego w GCP.
A teraz może spróbujemy załadować kilka zapisów do mastera? Wszelkie problemy z łącznością lub opóźnieniami mogą generować opóźnienie podrzędne, będziesz w stanie to zauważyć za pomocą ClusterControl. Zobacz zrzut ekranu poniżej:
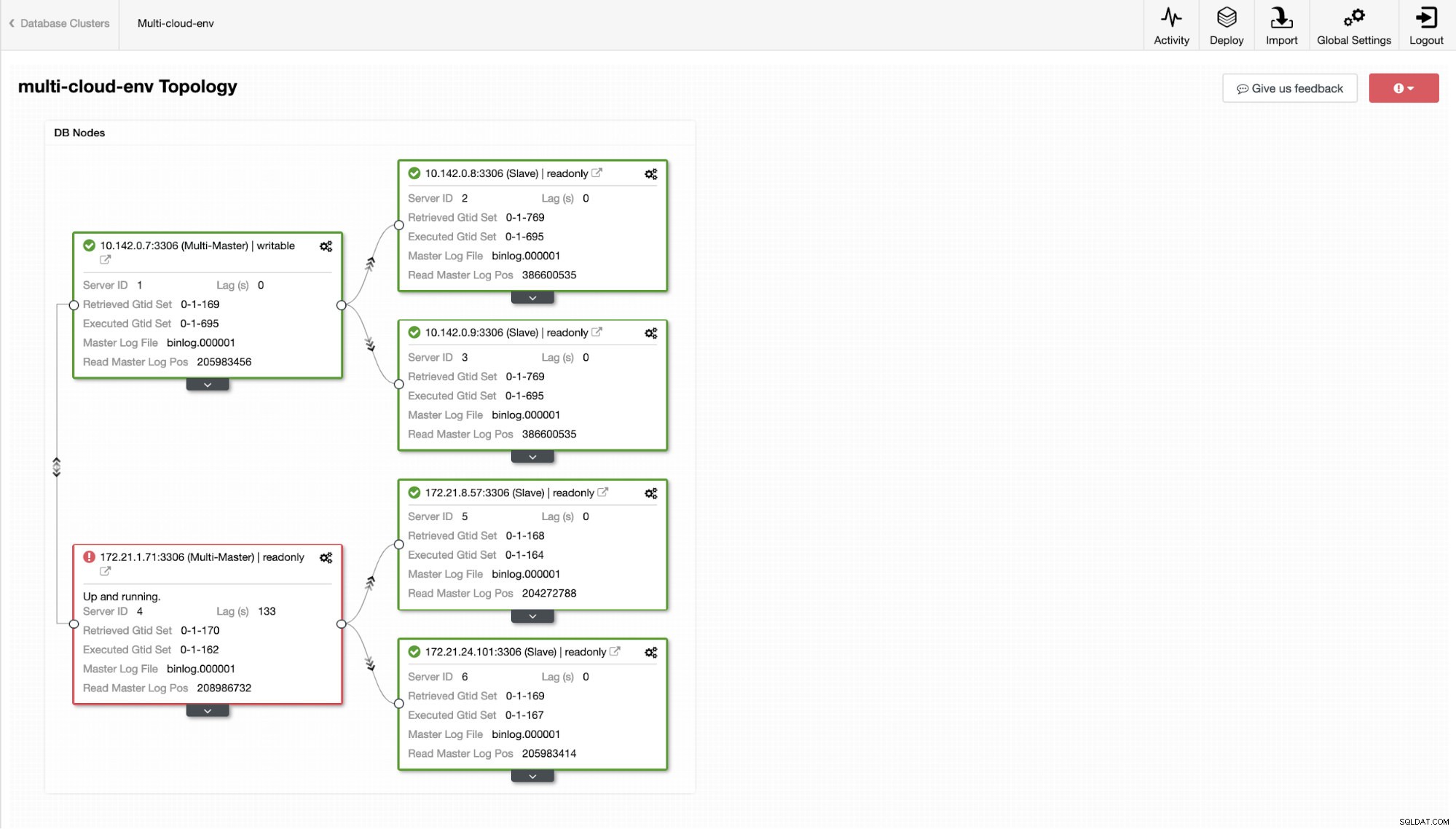
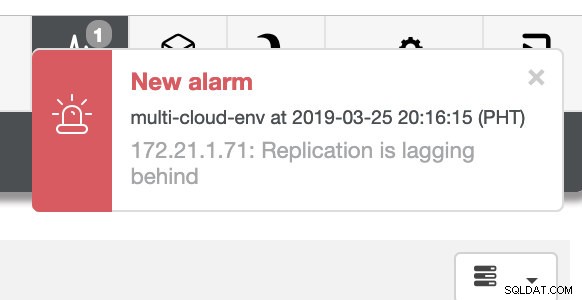
i jak widać w prawym górnym rogu zrzutu ekranu, zmienia kolor na czerwony, co oznacza, że wykryto problemy. W związku z tym wysyłany był alarm, gdy ten problem został wykryty. Zobacz poniżej:
Musimy się w to zagłębić. W celu szczegółowego monitorowania włączyliśmy agentów w instancjach bazy danych. Rzućmy okiem na pulpit nawigacyjny.
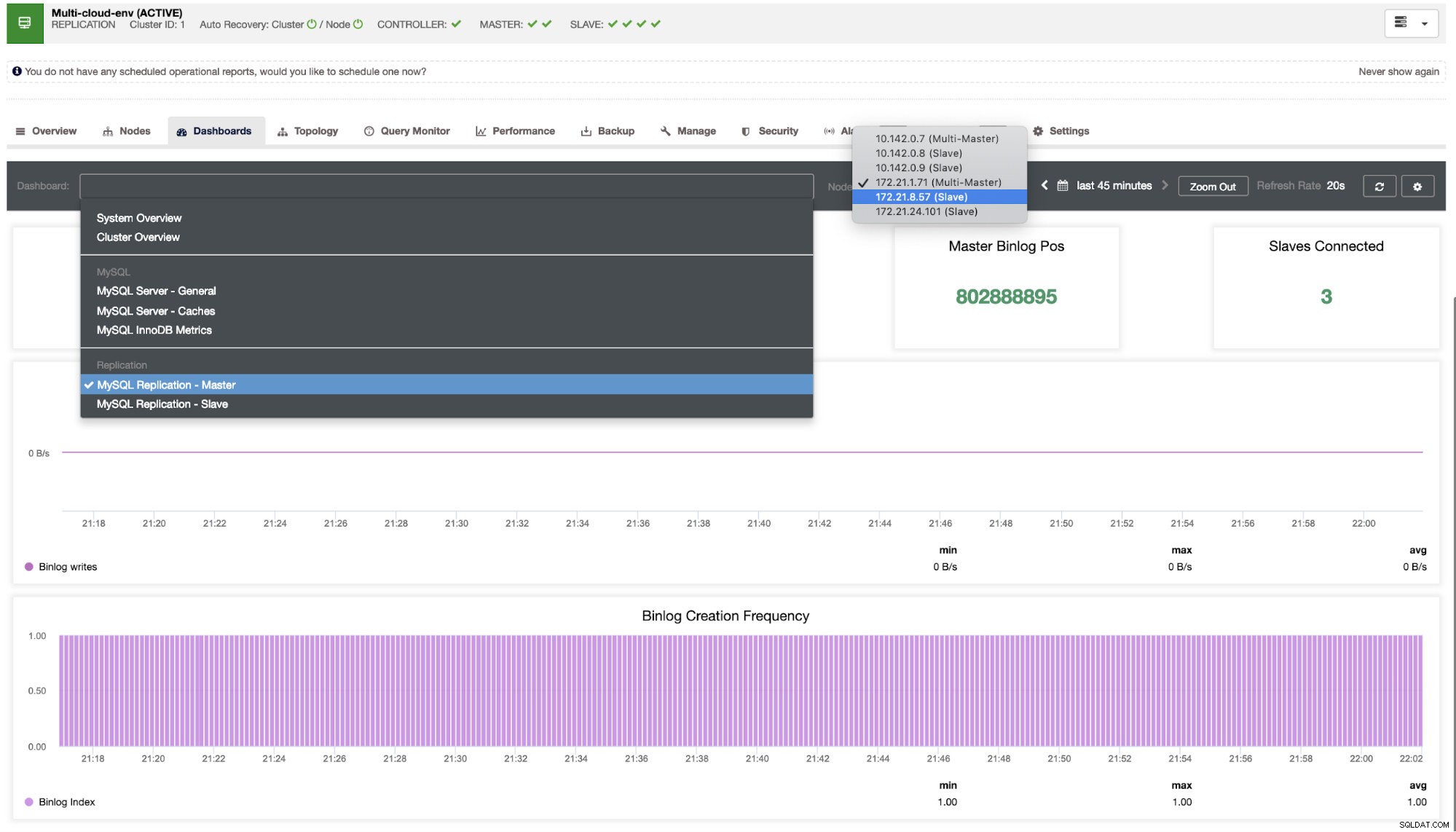
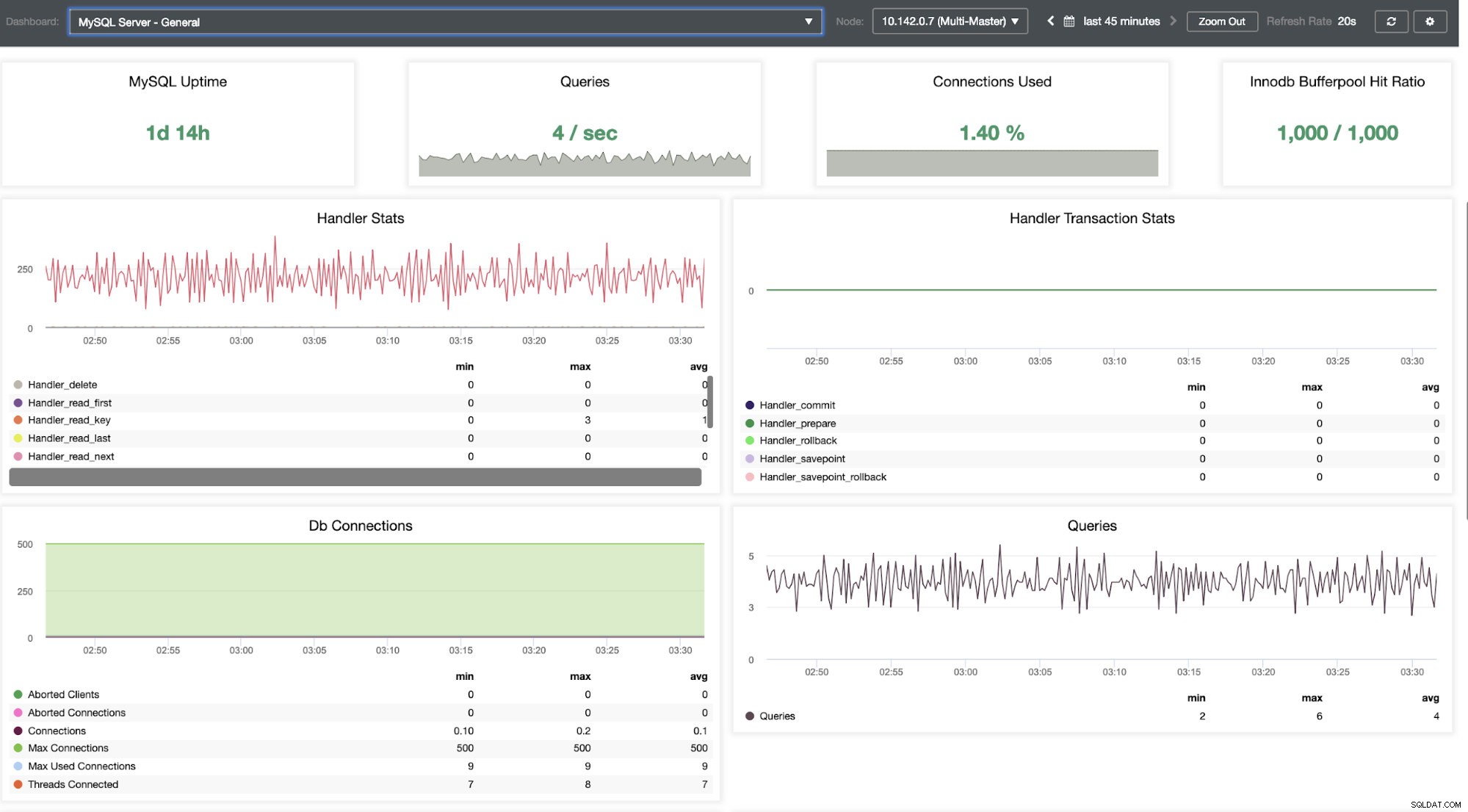
Oferuje super płynne działanie w zakresie monitorowania węzłów.
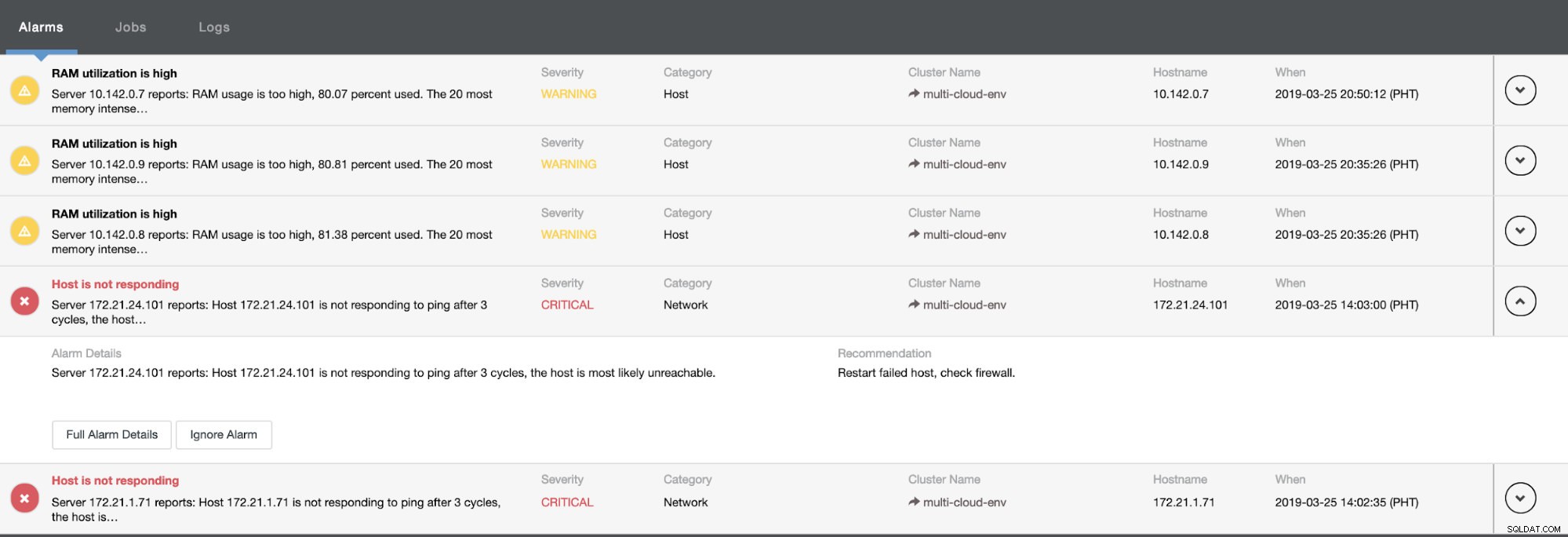
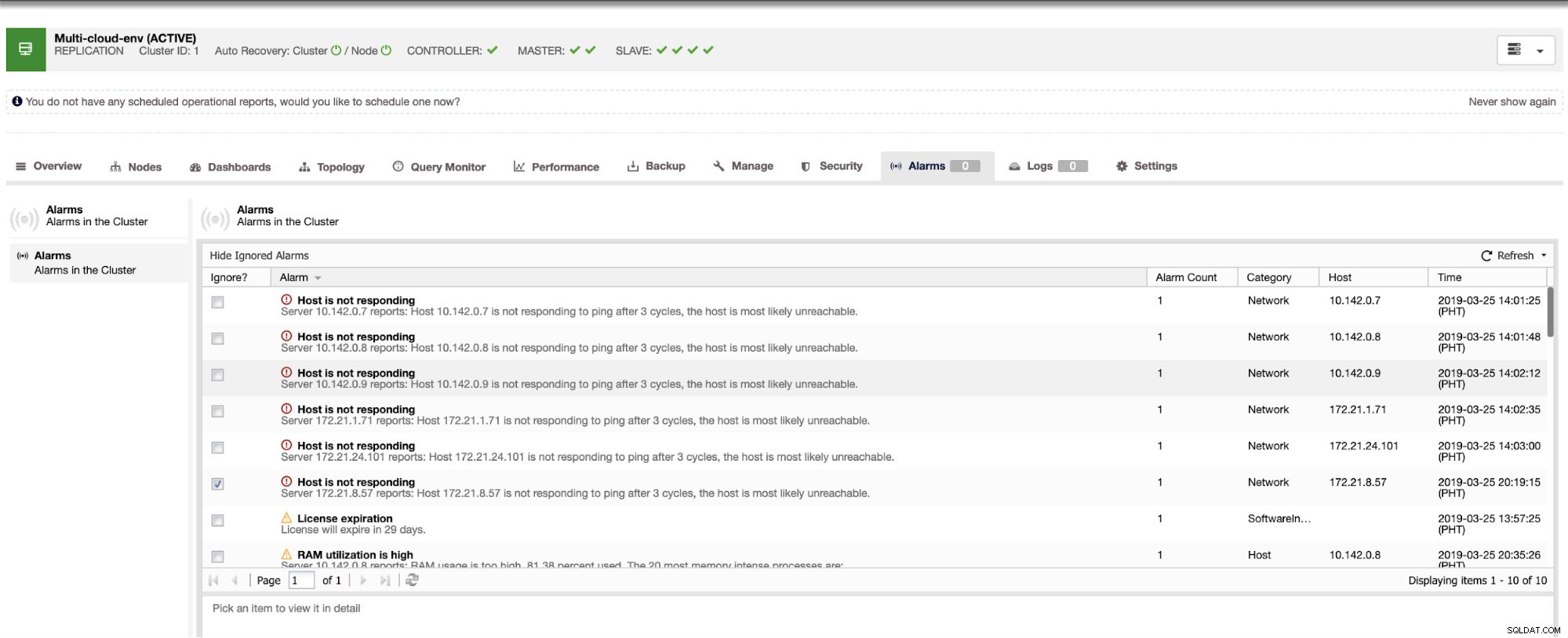
Mówi nam, że wykorzystanie jest wysokie lub host nie odpowiada. Chociaż był to tylko ping brak odpowiedzi, możesz zignorować alert, aby powstrzymać Cię przed bombardowaniem. Dlatego w razie potrzeby możesz go „odignorować”, przechodząc do Cluster -> Alarms w Clustercontrol. Zobacz poniżej:
Zarządzanie awariami i wykonywanie przełączania awaryjnego
Załóżmy, że węzeł główny us-east1 uległ awarii lub wymaga gruntownego remontu z powodu modernizacji systemu lub sprzętu. Załóżmy, że to jest teraz topologia (patrz obrazek poniżej):
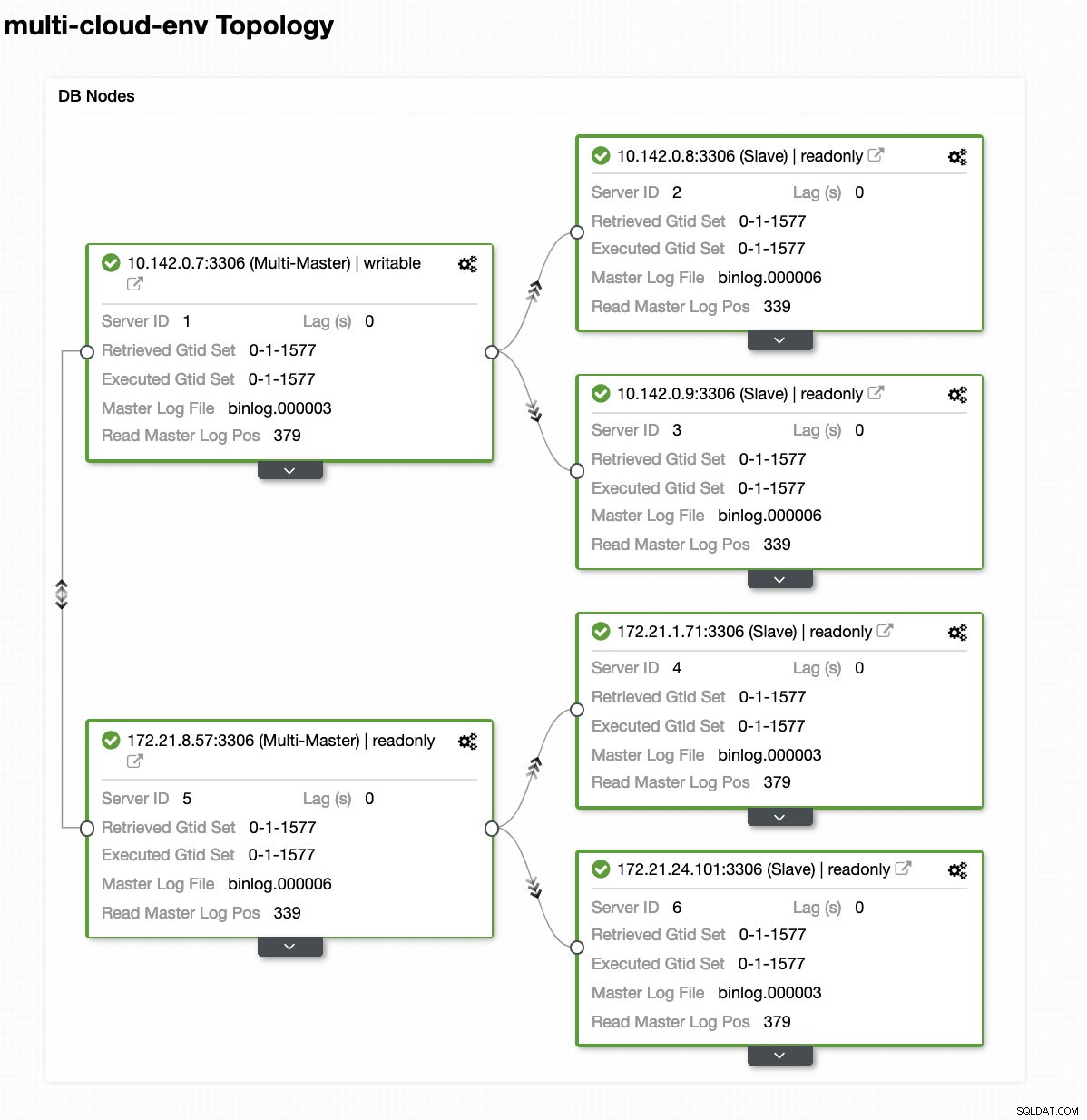
Spróbujmy wyłączyć hosta 10.142.0.7, który jest głównym w regionie us-east1. Zobacz poniższe zrzuty ekranu, jak ClusterControl reaguje na to:
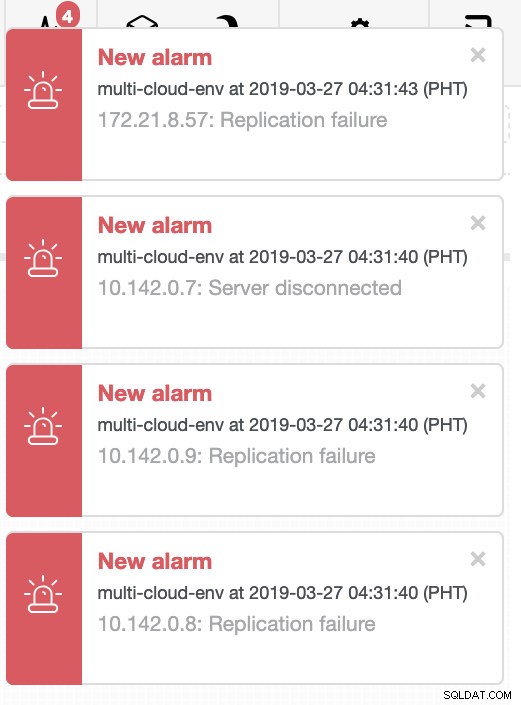
ClusterControl wysyła alarmy po wykryciu anomalii w klastrze. Następnie próbuje przejść awaryjnie do nowego wzorca, wybierając odpowiedniego kandydata (patrz obrazek poniżej):

Następnie odkłada uszkodzony master, który został już wyjęty z klastra (patrz obrazek poniżej):
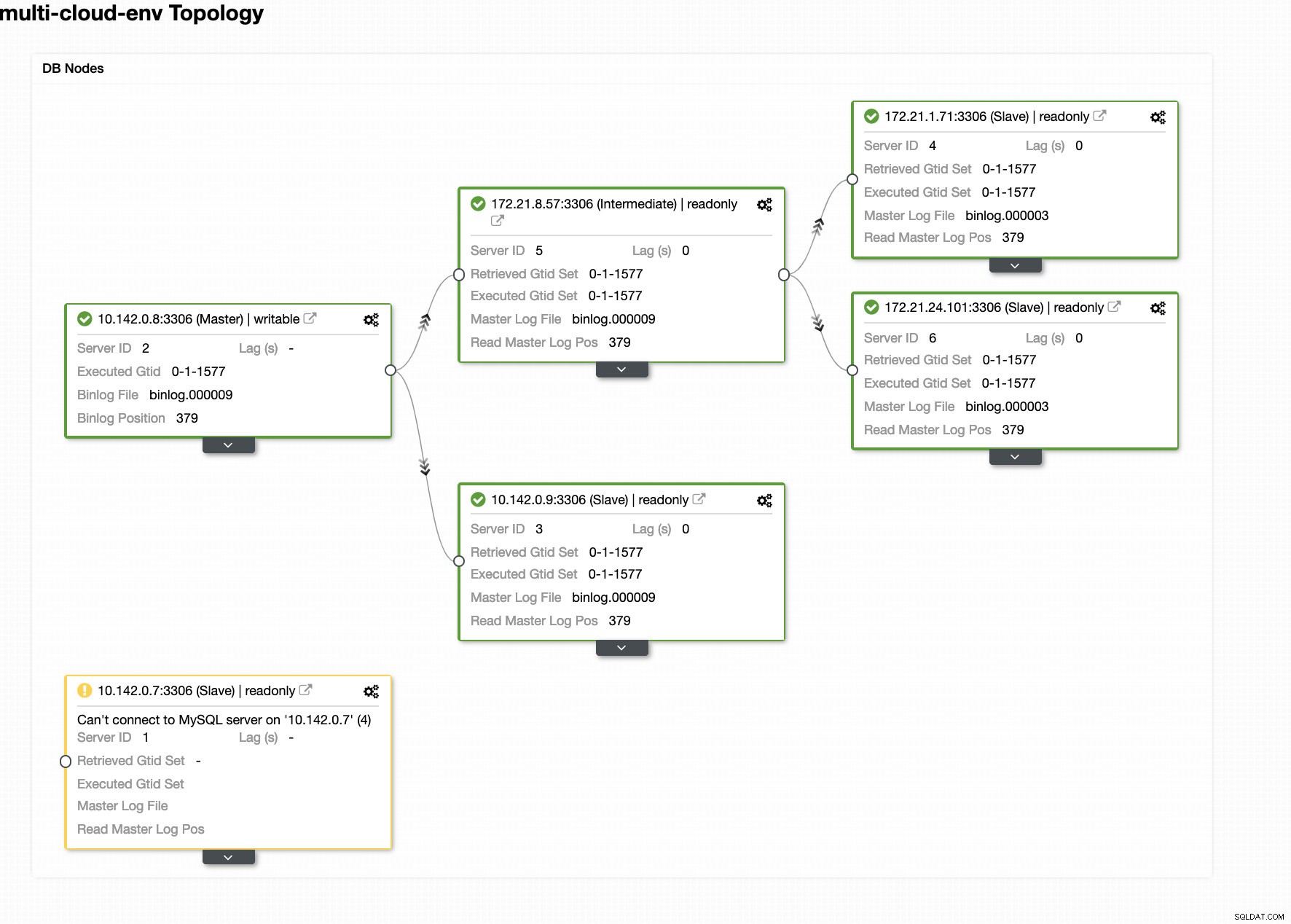
To tylko rzut oka na to, co ClusterControl może zrobić, istnieją inne wspaniałe funkcje, takie jak kopie zapasowe, monitorowanie zapytań, wdrażanie/zarządzanie równoważeniem obciążenia i wiele innych!
Wniosek
Zarządzanie konfiguracją replikacji MySQL w wielu chmurach może być trudne. Należy dołożyć wszelkich starań, aby zabezpieczyć naszą konfigurację, więc miejmy nadzieję, że ten blog daje pomysł, jak zdefiniować podsieci i chronić węzły bazy danych. Poza bezpieczeństwem należy zarządzać wieloma rzeczami i właśnie tutaj ClusterControl może być bardzo pomocny.
Wypróbuj teraz i daj nam znać, jak to działa. Możesz skontaktować się z nami tutaj w dowolnym momencie.