W tym samouczku Hadoop , przedstawimy pełne wprowadzenie do pary klucz-wartość MapReduce.
Przede wszystkim omówimy, czym jest para klucz-wartość w Hadoop, jak generowana jest para klucz-wartość w MapReduce. Na koniec wyjaśnimy generowanie pary klucz-wartość MapReduce na przykładach.
Co to jest para klucz-wartość w Hadoop?
Para klucz-wartość w MapReduce to jednostka rekordu, którą Hadoop MapReduce akceptuje do wykonania.
Używamy Hadoop głównie do analizy danych. Zajmuje się danymi ustrukturyzowanymi, nieustrukturyzowanymi i częściowo ustrukturyzowanymi. Dzięki Hadoop, jeśli schemat jest statyczny, możemy bezpośrednio pracować na kolumnie zamiast na wartości klucza. Ale jeśli schemat nie jest statyczny, będziemy pracować nad wartością klucza.
Wartość kluczy nie jest wewnętrznymi właściwościami danych. Ale są wybierane przez użytkownika analizującego dane.
MapReduce to podstawowy składnik Hadoop, który zapewnia przetwarzanie danych. Wykonuje przetwarzanie, dzieląc zadanie na dwie fazy:Faza mapy i Faza redukcji . Każda faza ma klucz-wartość jako wejście i wyjście.
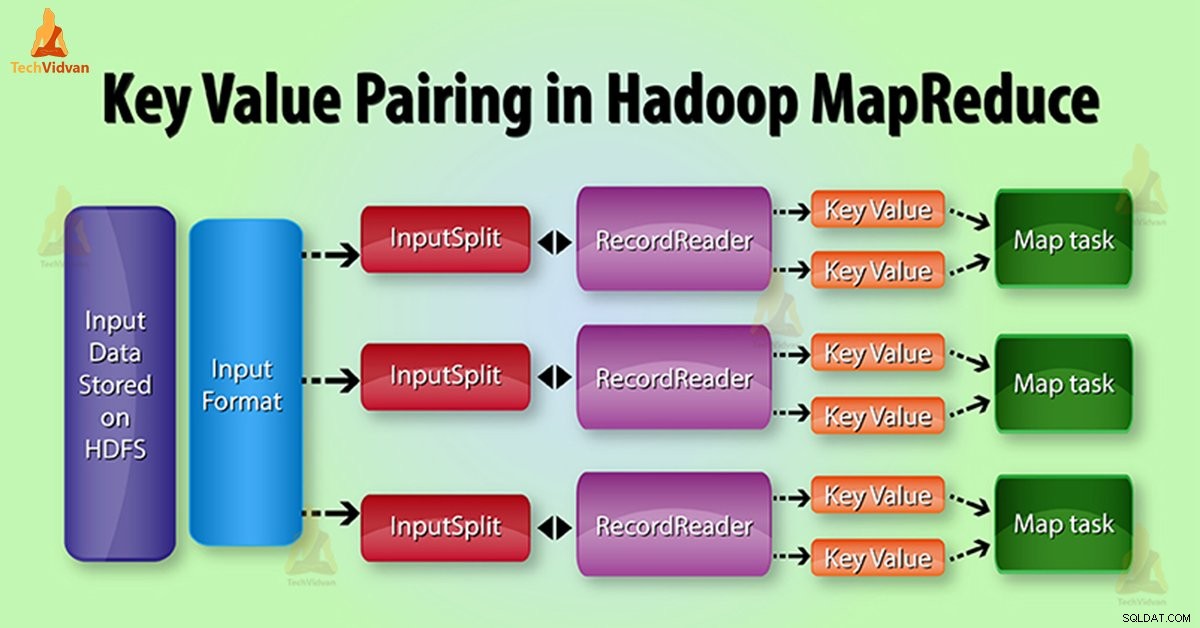
MapReduce Generowanie pary klucz-wartość w Hadoop
W wykonaniu zadania MapReduce, przed wysłaniem danych do mappera , najpierw przekonwertuj go na pary klucz-wartość. Ponieważ program mapujący tylko pary klucz-wartość danych.
Para klucz-wartość w MapReduce jest generowana w następujący sposób:
InputSplit – Jest to logiczna reprezentacja danych, które InputFormat generuje. W programie MapReduce opisuje jednostkę pracy zawierającą pojedyncze zadanie na mapie.
RecordReader – Komunikuje się z InputSplit. Następnie konwertuje dane na pary klucz-wartość odpowiednie do odczytu przez Mapper. RecordReader domyślnie używa TextInputFormat do konwersji danych na pary klucz-wartość.
W wykonywaniu zadania MapReduce funkcja mapy przetwarza określoną parę klucz-wartość. Następnie emituje określoną liczbę par klucz-wartość. Funkcja Zmniejsz przetwarza wartości pogrupowane według tego samego klucza.
Następnie emituje kolejny zestaw par klucz-wartość jako dane wyjściowe. Typy danych wyjściowych Map powinny pasować do typów danych wejściowych Zmniejsz, jak pokazano poniżej:
- Mapa: (K1, V1) -> lista (K2, V2)
- Zmniejsz: {(K2, lista (V2}) -> lista (K3, V3)
Na jakiej podstawie para klucz-wartość jest generowana w Hadoop?
MapReduce Generowanie pary klucz-wartość całkowicie zależy od zestawu danych. Zależy również od wymaganej wydajności. Framework określa parę klucz-wartość w 4 miejscach:mapowanie wejścia/wyjścia, ograniczenie wejścia/wyjścia.
1. Wejście mapy
Wprowadzanie na mapie domyślnie przyjmuje przesunięcie linii jako klucz. Treść linii ma wartość Text. Możemy je modyfikować; używając niestandardowego formatu wejściowego.
2. Wyjście mapy
Mapa odpowiada za filtrowanie danych. Zapewnia również środowisko do grupowania danych na podstawie klucza.
- Klucz– Jest to pole/tekst/obiekt, na którym dane grupują się i agregują w reduktorze .
- Wartość– Jest to pole/tekst/obiekt, który każdy z osobna redukuje uchwyty metody.
3. Zmniejsz dane wejściowe
Dane wyjściowe mapy są wprowadzane w celu zmniejszenia. Więc to to samo, co Map-Output.
4. Zmniejsz wydajność
To całkowicie zależy od wymaganego wyniku.
Przykład pary klucz-wartość MapReduce
Na przykład zawartość pliku, który HDFS sklepy to Chandler to Joey Mark to John . Tak więc teraz, używając InputFormat, zdefiniujemy, jak ten plik będzie dzielony i odczytywany. Domyślnie RecordReader używa TextInputFormat do konwersji tego pliku na parę klucz-wartość.
- Klucz – Jest przesunięty względem początku linii w pliku.
- Wartość – Jest to zawartość linii, z wyłączeniem terminatorów linii.
Tutaj,Klucz wynosi 0 i Wartość to Chandler to Joey Mark to John.
Wniosek
Podsumowując, możemy powiedzieć, że para klucz-wartość to tylko encja rekordu, którą MapReduce akceptuje do wykonania. InputSplit i RecordReader generują parę klucz-wartość. Stąd kluczem jest przesunięcie bajtowe, a wartość jest zawartością linii.
Mam nadzieję, że polubiłeś ten blog. Jeśli masz jakieś sugestie lub zapytania związane z parą klucz-wartość MapReduce, zostaw komentarz w sekcji podanej poniżej.



