Systemy baz danych są kluczowymi składnikami cyklu każdej pomyślnie działającej aplikacji. Każda zaangażowana w nie organizacja ma zatem obowiązek zapewnienia płynnego działania tych DBM poprzez konsekwentne monitorowanie i obsługę drobnych niepowodzeń, zanim przerodzą się one w ogromne komplikacje, które mogą spowodować przestój aplikacji lub spowolnienie działania.
Możesz zapytać, jak możesz stwierdzić, czy baza danych naprawdę będzie miała problem, gdy działa normalnie? Cóż, to właśnie zamierzamy omówić w tym artykule i nazywamy to benchmarkingiem. Analiza porównawcza polega w zasadzie na uruchamianiu pewnego zestawu zapytań z pewnymi danymi testowymi wraz z pewnymi zasobami w celu określenia, czy te parametry spełniają oczekiwany poziom wydajności.
MongoDB nie posiada standardowej metodologii benchmarkingu, dlatego musimy rozwiązać problem testując zapytania na własnym sprzęcie. Chociaż możesz również uzyskać imponujące dane z procesu porównawczego, musisz być ostrożny, ponieważ może to być inny przypadek, gdy uruchamiasz bazę danych z prawdziwymi zapytaniami.
Ideą benchmarkingu jest uzyskanie ogólnego wyobrażenia o tym, jak różne opcje konfiguracji wpływają na wydajność, jak można dostosować niektóre z tych konfiguracji, aby uzyskać maksymalną wydajność i oszacować koszt ulepszenia tej implementacji. Poza tym aplikacje rosną z czasem pod względem liczby użytkowników i prawdopodobnie ilość danych, które mają być obsługiwane, dlatego przed tym czasem trzeba zaplanować trochę wydajności. Po uświadomieniu sobie rosnącego trendu danych, musisz przeprowadzić analizę porównawczą, w jaki sposób spełnisz wymagania tych ogromnych rosnących danych.
Rozważania w analizie porównawczej MongoDB
- Wybierz obciążenia, które są typową reprezentacją współczesnych nowoczesnych aplikacji. Nowoczesne aplikacje z każdym dniem stają się coraz bardziej złożone, co jest przekazywane do struktur danych. Oznacza to, że z czasem zmieniła się również prezentacja danych, na przykład przechowywanie prostych pól w obiektach i tablicach. Praca z tymi danymi przy domyślnych lub raczej nietypowych konfiguracjach baz danych nie jest łatwa, ponieważ może to doprowadzić do problemów, takich jak małe opóźnienia i słaba przepustowość operacji obejmujących złożone dane. Dlatego podczas przeprowadzania testu porównawczego powinieneś używać danych, które są przejrzystą prezentacją Twojej aplikacji.
- Podwójne sprawdzanie zapisów. Zawsze upewnij się, że wszystkie zapisy danych zostały wykonane w sposób uniemożliwiający utratę danych. Ma to na celu poprawę integralności danych poprzez zapewnienie, że dane są spójne i mają największe zastosowanie, szczególnie w środowisku produkcyjnym.
- Zastosuj wolumeny danych, które są reprezentacją zestawów danych „dużych danych”, które z pewnością przekroczą pojemność pamięci RAM dla pojedynczego węzła. Gdy obciążenie testowe jest duże, pomoże to przewidzieć przyszłe oczekiwania dotyczące wydajności bazy danych, dlatego odpowiednio wcześnie rozpocznij planowanie pojemności.
Metodologia
Nasz test porównawczy będzie obejmował pewne duże dane lokalizacyjne, które można pobrać stąd, i będziemy używać oprogramowania Robo3t do manipulowania naszymi danymi i zbierania potrzebnych informacji. Plik zawiera ponad 500 dokumentów, które w zupełności wystarczają do naszego testu. Używamy MongoDB w wersji 4.0 na serwerze dedykowanym Ubuntu Linux 12.04 Intel Xeon-SandyBridge E3-1270-Quadcore 3,4 GHz z 32 GB pamięci RAM, dyskiem obrotowym Western Digital WD Caviar RE4 1 TB i dyskiem SSD Smart XceedIOPS 256 GB. Wstawiliśmy pierwsze 500 dokumentów.
Uruchomiliśmy poniższe polecenia wstawiania
db.getCollection('location').insertMany([<document1, <document2>…<document500>],{w:0})
db.getCollection('location').insertMany([<document1, <document2>…<document500>],{w:1})Zgłoś problem
Problem dotyczący zapisu opisuje poziom potwierdzenia wymagany od MongoDB dla operacji zapisu w tym przypadku do samodzielnej bazy MongoDB. W przypadku operacji o wysokiej przepustowości, jeśli ta wartość jest ustawiona na niską, wywołania zapisu będą tak szybkie, co zmniejszy opóźnienie żądania. Z drugiej strony, jeśli wartość jest ustawiona na wysoką, wywołania zapisu są powolne i w konsekwencji zwiększają opóźnienie zapytania. Prostym wyjaśnieniem tego jest to, że gdy wartość jest niska, nie martwisz się możliwością utraty niektórych zapisów w przypadku awarii mongod, błędu sieci lub anonimowej awarii systemu. Ograniczeniem w tym przypadku będzie to, że nie będziesz pewien, czy te zapisy się powiodły. Z drugiej strony, jeśli problem związany z zapisem jest wysoki, pojawia się monit obsługi błędu, a zatem zapisy zostaną potwierdzone. Potwierdzenie to po prostu potwierdzenie, że serwer zaakceptował zapis do przetworzenia.
 Gdy problem dotyczący zapisu jest ustawiony wysoko
Gdy problem dotyczący zapisu jest ustawiony wysoko  Gdy problem z zapisem jest niski
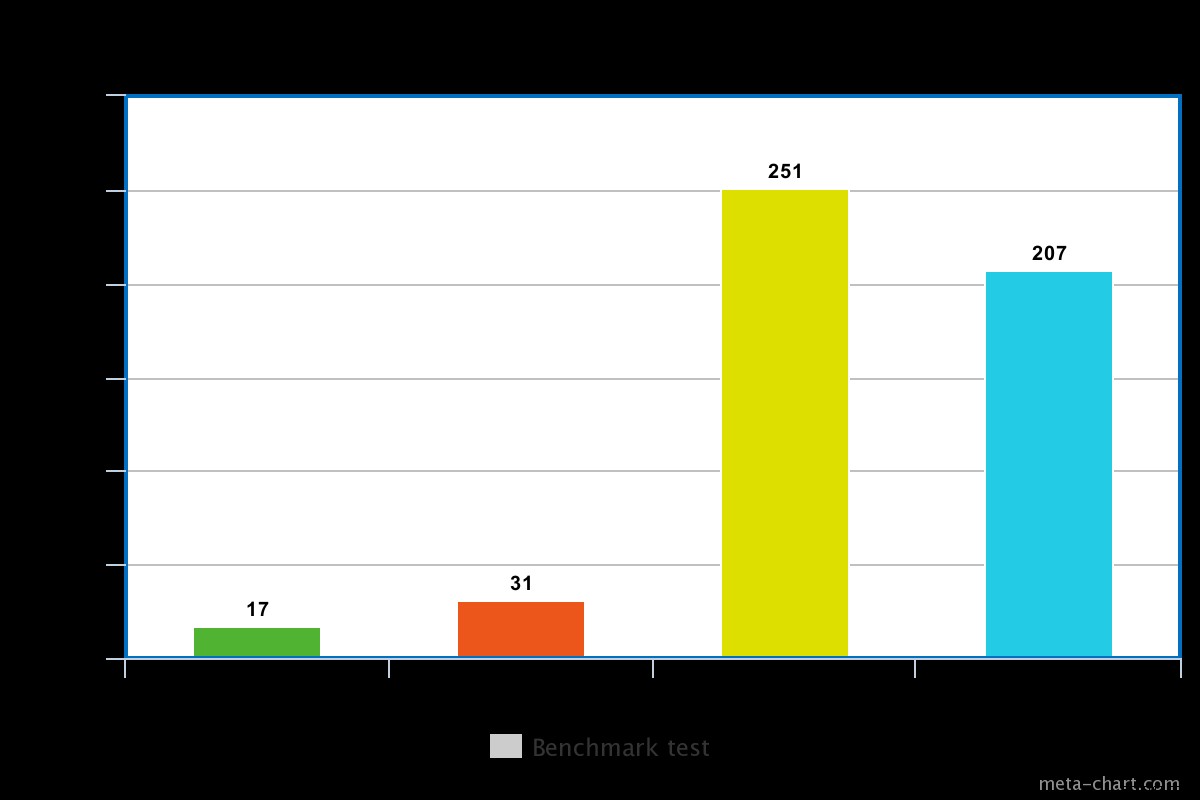
Gdy problem z zapisem jest niski W naszym teście niski poziom obawy o zapis skutkował wykonaniem zapytania w czasie min 0,013ms i max 0,017ms. W takim przypadku podstawowe potwierdzenie zapisu jest wyłączone, ale nadal można uzyskać informacje dotyczące wyjątków gniazd i wszelkich błędów sieciowych, które mogły zostać wyzwolone.
Gdy problem dotyczący zapisu jest ustawiony na wysoki, powrót zajmuje prawie dwa razy więcej czasu, a czas wykonania wynosi 0,027 ms min i 0,031 ms maks. Potwierdzenie w tym przypadku jest gwarantowane, ale nie w 100% dotarło do dziennika dysku. W tym przypadku szanse na utratę zapisu wynoszą zatem 50% z powodu okna 100 ms, w którym dziennik może nie zostać opróżniony na dysk.
Dziennik
Jest to technika zapewniająca brak utraty danych poprzez zapewnienie trwałości w przypadku awarii. Osiąga się to poprzez rejestrowanie z wyprzedzeniem w plikach dziennika na dysku. Jest najbardziej wydajny, gdy problem związany z zapisem jest ustawiony na wysokim poziomie.
W przypadku wirującego dysku czas wykonania z włączonym kronikowaniem jest nieco długi, na przykład w naszym teście wynosił on około 0,251 ms dla tej samej operacji powyżej.

Czas wykonania dla dysku SSD jest jednak nieco krótszy dla tego samego polecenia. W naszym teście było to około 0,207 ms, ale w zależności od charakteru danych czasami może to być 3 razy szybsze niż w przypadku wirującego dysku.

Gdy rejestrowanie jest włączone, potwierdza, że zapisy zostały wykonane w dzienniku, a tym samym zapewnia trwałość danych. W konsekwencji operacja zapisu przetrwa zamknięcie mongod i zapewni, że operacja zapisu będzie trwała.
W przypadku operacji o wysokiej przepustowości można uzyskać połowę czasu zapytań, ustawiając w=0. W przeciwnym razie, jeśli chcesz mieć pewność, że dane zostały zarejestrowane, a raczej będą w przypadku przywrócenia do życia po awarii, musisz ustawić w=1.
 Kilka osób Zostań administratorem danych MongoDB — wprowadzenie MongoDB do produkcjiDowiedz się, co trzeba wiedzieć, aby wdrażać, monitorować, scale MongoDBPobierz za darmo
Kilka osób Zostań administratorem danych MongoDB — wprowadzenie MongoDB do produkcjiDowiedz się, co trzeba wiedzieć, aby wdrażać, monitorować, scale MongoDBPobierz za darmo Replikacja
Potwierdzenie problemu z zapisem można włączyć dla więcej niż jednego węzła, który jest podstawowym i dodatkowym w zestawie replik. Będzie to scharakteryzowane przez jaką liczbę całkowitą ma wartość parametru write. Na przykład, jeśli w =3, Mongod musi zapewnić, że zapytanie otrzyma potwierdzenie od węzła głównego i 2 urządzeń podrzędnych. Jeśli spróbujesz ustawić wartość większą niż jeden, a węzeł nie jest jeszcze zreplikowany, zgłosi błąd, że host musi zostać zreplikowany.
Replikacja ma opóźnienie, tak że czas wykonania zostanie zwiększony. Dla powyższego prostego zapytania, jeśli w=3, średni czas wykonania wzrasta do 270ms. Czynnikiem napędzającym to jest zakres czasu odpowiedzi między węzłami dotkniętymi opóźnieniami sieci, obciążenie komunikacyjne między 3 węzłami i przeciążenie. Poza tym wszystkie trzy węzły czekają, aż się skończą, zanim zwrócą wynik. Dlatego we wdrożeniu produkcyjnym nie będziesz musiał angażować tak wielu węzłów, jeśli chcesz poprawić wydajność. MongoDB odpowiada za wybór, które węzły mają być potwierdzane, chyba że w pliku konfiguracyjnym istnieje specyfikacja za pomocą tagów.
Dysk obrotowy a dysk półprzewodnikowy
Jak wspomniano powyżej, dysk SSD jest dość szybki niż dysk wirujący, w zależności od zaangażowanych danych. Czasami może to być 3 razy szybsze, dlatego warto zapłacić, jeśli zajdzie taka potrzeba. Jednak korzystanie z dysku SSD będzie droższe, zwłaszcza w przypadku dużych ilości danych. MongoDB ma tę zaletę, że obsługuje przechowywanie baz danych w katalogach, które można zamontować, stąd możliwość korzystania z dysku SSD. Wykorzystanie dysku SSD i włączenie księgowania to świetna optymalizacja.
Wniosek
Eksperyment był pewny, że problem związany z zapisem wyłączał skrócenie czasu wykonania zapytania kosztem szansy na utratę danych. Z drugiej strony, gdy problem zapisu jest włączony, czas wykonania jest prawie 2 razy, gdy jest wyłączony, ale istnieje pewność, że dane nie zostaną utracone. Poza tym jesteśmy w stanie uzasadnić, że dysk SSD jest szybszy niż dysk wirujący. Jednak, aby zapewnić trwałość danych w przypadku awarii systemu, wskazane jest włączenie obawy o zapis. Włączając problem dotyczący zapisu dla zestawu replik, nie ustawiaj zbyt dużej liczby, która może spowodować pogorszenie wydajności po zakończeniu aplikacji.



