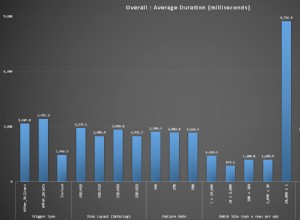
Zaczynając od określonej liczby rekordów, IN orzeczenie nad SELECT staje się szybszy niż na liście stałych.
Zobacz ten artykuł na moim blogu, aby porównać wydajność:
Jeśli kolumna użyta w zapytaniu w IN klauzula jest indeksowana w następujący sposób:
SELECT *
FROM table1
WHERE unindexed_column IN
(
SELECT indexed_column
FROM table2
)
, to zapytanie jest po prostu zoptymalizowane do EXISTS (który używa tylko jednego wpisu dla każdego rekordu z table1 )
Niestety, MySQL nie jest w stanie wykonać HASH SEMI JOIN lub MERGE SEMI JOIN które są jeszcze bardziej wydajne (zwłaszcza jeśli obie kolumny są indeksowane).