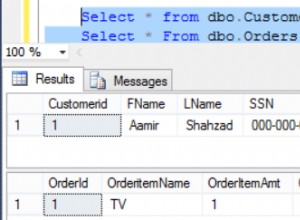
W MySQL możesz użyć FIND_IN_SET() :
SELECT * FROM mytable WHERE FIND_IN_SET('ios ', tags) > 0;
https://dev.mysql .com/doc/refman/5.0/en/string-functions.html#function_find-in-set
Pamiętaj, że FIND_IN_SET oczekuje, że ciągi będą przecinkiem rozdzielone, a nie przecinek i spacja rozdzielony. Więc możesz mieć problemy z ostatnim tagiem. Naprawdę najlepszym sposobem byłoby znormalizowanie tabeli; w przeciwnym razie możesz usunąć spacje z tags kolumna; wreszcie możesz obejść ten problem, dodając spację do tags kolumna:
SELECT * FROM mytable WHERE FIND_IN_SET('ios ', CONCAT(tags,' ')) > 0;
Jeśli liczba tagów jest ograniczona, możesz rozważyć przekonwertowanie kolumny na SET . To znacznie poprawi wydajność.
AKTUALIZUJ
Tyle że spacje źle . Są przed ciągi, a nie po.
A więc:
SELECT * FROM mytable WHERE FIND_IN_SET(' ios', CONCAT(' ', tags)) > 0;
Ale znowu, pozbądź się tych spacji - to same kłopoty :-)
AKTUALIZACJA 2
Powyższe działa, dobrze. Ale to prawie wszystko, co możesz powiedzieć na moją korzyść. Nie tylko rozwiązanie jest dość *nie*wydajne, ale także sprawia, że system jest nie do utrzymania (byłem tam, robiłem to, mam T-shirt i przeżuty tyłek pod tym samym). Więc teraz będę opowiadał się trochę za normalizacją, czyli posiadaniem przynajmniej tych dwóch dodatkowych tabel:
CREATE TABLE tags ( id INTEGER NOT NULL PRIMARY KEY AUTO_INCREMENT,
tagName varchar(32) // I'm a bit of a cheapskate
);
CREATE TABLE has_tag ( tableid INTEGER, tagid INTEGER );
O ile to jest lepsze? Pozwól mi policzyć sposoby.
- możesz łatwo dodać bardziej elastyczne zapytania („ma wszystkie tagi w iOS, C++, ...” lub „ma co najmniej trzy tagi spośród tych:( iOS, Python, SQL, .NET, Haskell )”). Tak, możesz to zrobić za pomocą
FIND_IN_SET, ale uwierz mi, nie spodoba ci się . - masz słownik kontrolowany tagów, co umożliwia sprawdzenie, czy jakiś tag jest znany (a także łatwe generowanie list, takich jak rozwijane pola kombi, lub -- czy ktoś powiedział „Autouzupełnianie jQuery”?).
- zapisuje część nieruchomości na dysku (tagi są zapisywane raz)
- wyszukiwania są szybkie . Jeśli znasz już tagi, których szukasz i wstępnie skompilujesz je w identyfikatory tagów, podczas działania pozostawią one na chodniku gumowe ślady SQL (wyszukiwanie zindeksowane dla liczby całkowitej wartość!). A tagów, które się nie skompilują nie będzie , a dowiesz się o tym jeszcze przed rozpoczęciem wyszukiwania.
- ułatwia zmianę nazw tagów
- może przechowywać dowolny numer tagów (ryzykujesz, że niektóre tagi zostaną skrócone do „iOS Developm” prędzej czy później...)
Uważam, że „pole CSV” jest cenione (lub) wśród Antywzorców SQL ( https://pragprog.com/book/bksqla/sql-antipatterns ) i nie bez powodu.