Mój współpracownik Steve Wright (blog | @SQL_Steve) zadał mi ostatnio pytanie dotyczące dziwnego wyniku, który widział. Aby przetestować niektóre funkcje naszego najnowszego narzędzia, SQL Sentry Plan Explorer PRO, stworzył szeroką i dużą tabelę i uruchamiał wobec niej różne zapytania. W jednym przypadku zwracał dużo danych, ale STATISTICS IO pokazywał, że odbyło się bardzo mało odczytów. Zadzwoniłem do kilku osób na #sqlhelp i ponieważ wydawało mi się, że nikt nie widział tego problemu, pomyślałem, że napiszę o tym na blogu.
TL;DR Wersja
Krótko mówiąc, miej świadomość, że istnieją pewne scenariusze, w których nie możesz polegać na STATISTICS IO powiedzieć ci prawdę. W niektórych przypadkach (ten z udziałem TOP i równoległości), znacznie zaniży liczbę odczytów logicznych. Może to prowadzić do przekonania, że masz bardzo przyjazne dla I/O zapytanie, gdy tego nie zrobisz. Istnieją inne, bardziej oczywiste przypadki — na przykład, gdy masz ukrytą masę operacji we/wy za pomocą skalarnych funkcji zdefiniowanych przez użytkownika. Uważamy, że Eksplorator Planu czyni te przypadki bardziej oczywistymi; ten jest jednak nieco trudniejszy.
Zapytanie problemowe
Tabela ma 37 milionów wierszy, do 250 bajtów na wiersz, około 1 miliona stron i bardzo niską fragmentację (0,42% na poziomie 0, 15% na poziomie 1 i 0 poza tym). Nie ma kolumn obliczanych, żadnych funkcji UDF ani indeksów z wyjątkiem klastrowanego klucza podstawowego na wiodącym INT kolumna. Proste zapytanie zwracające 500 000 wierszy, wszystkie kolumny, przy użyciu TOP i SELECT * :
SET STATISTICS IO ON; SELECT TOP 500000 * FROM dbo.OrderHistory WHERE OrderDate < (SELECT '19961029');
(I tak, zdaję sobie sprawę, że łamię własne zasady i używam SELECT * i TOP bez ORDER BY , ale dla uproszczenia staram się jak najlepiej zminimalizować mój wpływ na optymalizator.)
Wyniki:
(500000 wierszy, których dotyczy problem)Tabela „Historia zamówień”. Liczba skanów 1, odczyty logiczne 23, odczyty fizyczne 0, odczyty z wyprzedzeniem 0, odczyty logiczne lobu 0, odczyty fizyczne lobu 0, odczyty loba z wyprzedzeniem 0.
Zwracamy 500 000 wierszy i zajmuje to około 10 sekund. Od razu wiem, że coś jest nie tak z liczbą odczytów logicznych. Nawet jeśli nie wiedziałem jeszcze o danych źródłowych, mogę stwierdzić z wyników siatki w Management Studio, że pobiera to ponad 23 strony danych, niezależnie od tego, czy pochodzą one z pamięci, czy z pamięci podręcznej, i powinno to znaleźć odzwierciedlenie gdzieś w STATISTICS IO . Patrząc na plan…
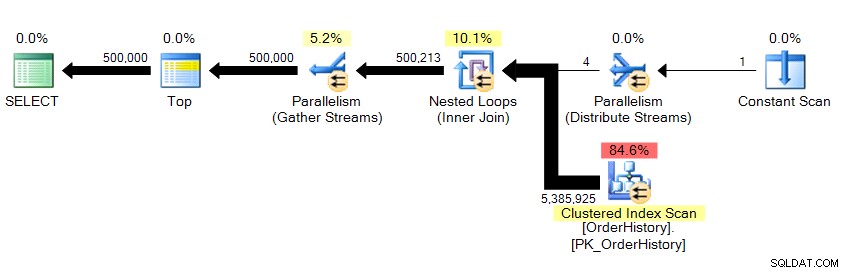
…widzimy, że jest tam równoległość i że przeskanowaliśmy cały stół. Więc jak to możliwe, że są tylko 23 logiczne odczyty?
Inne „identyczne” zapytanie
Jedno z moich pierwszych pytań do Steve'a brzmiało:„Co się stanie, jeśli wyeliminujesz równoległość?” Więc spróbowałem. Wziąłem oryginalną wersję podzapytania i dodałem MAXDOP 1 :
SET STATISTICS IO ON; SELECT TOP 500000 * FROM dbo.OrderHistory WHERE OrderDate < (SELECT '19961029') OPTION (MAXDOP 1);
Wyniki i plan:
(500000 wierszy, których dotyczy problem)Tabela „Historia zamówień”. Liczba skanów 1, odczyty logiczne 149589, odczyty fizyczne 0, odczyty z wyprzedzeniem 0, odczyty logiczne modułu 0, odczyty fizyczne modułu 0, odczyty modułu z wyprzedzeniem 0.
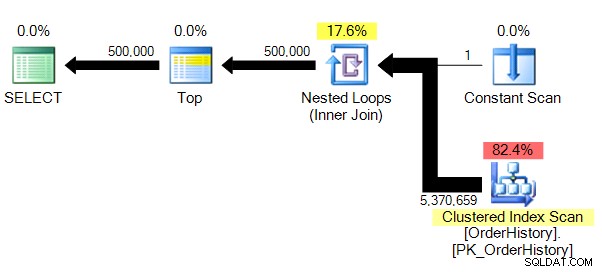
Mamy nieco mniej skomplikowany plan i bez paralelizmu (z oczywistych względów), STATISTICS IO pokazuje nam znacznie bardziej wiarygodne liczby dla logicznej liczby odczytów.
Jaka jest prawda?
Nietrudno zauważyć, że jedno z tych pytań nie mówi całej prawdy. Podczas gdy STATISTICS IO może nie opowiedzieć nam całej historii, może ślad będzie. Jeśli pobierzemy metryki środowiska wykonawczego, generując rzeczywisty plan wykonania w Eksploratorze planów, zobaczymy, że magiczne zapytanie o niskim poziomie odczytu w rzeczywistości pobiera dane z pamięci lub dysku, a nie z chmury magicznego pyłu. W rzeczywistości ma *więcej* odczytów niż inna wersja:

Jasne jest więc, że odczyty mają miejsce, po prostu nie wyświetlają się poprawnie w STATISTICS IO wyjście.
W czym problem?
Cóż, będę całkiem szczery:nie wiem, poza faktem, że równoległość zdecydowanie odgrywa rolę i wydaje się, że jest to jakiś rodzaj rasy. STATISTICS IO (a ponieważ stąd otrzymujemy dane, nasza zakładka Table I/O) pokazuje bardzo mylącą liczbę odczytów. Jasne jest, że zapytanie zwraca wszystkie dane, których szukamy, i z wyników śledzenia jasno wynika, że używa do tego odczytów, a nie osmozy. Zapytałem o to Paula White'a (blog | @SQL_Kiwi) i zasugerował, że tylko niektóre liczniki we/wy przed wątkiem są uwzględniane w sumie (i zgadza się, że jest to błąd).
Jeśli chcesz wypróbować to w domu, potrzebujesz tylko AdventureWorks (powinno to powtórzyć wersje 2008, 2008 R2 i 2012) i następującego zapytania:
SET STATISTICS IO ON; DBCC SETCPUWEIGHT(1000) WITH NO_INFOMSGS; GO SELECT TOP (15000) * FROM Sales.SalesOrderHeader WHERE OrderDate < (SELECT '20080101'); SELECT TOP (15000) * FROM Sales.SalesOrderHeader WHERE OrderDate < (SELECT '20080101') OPTION (MAXDOP 1); DBCC SETCPUWEIGHT(1) WITH NO_INFOMSGS;
(Zauważ, że SETCPUWEIGHT służy tylko do nakłaniania równoległości. Aby uzyskać więcej informacji, zobacz post na blogu Paula White'a na temat kalkulacji kosztów planu).
Wyniki:
Tabela „Nagłówek zamówienia sprzedaży”. Liczba skanów 1, odczyty logiczne 4, odczyty fizyczne 0, odczyty z wyprzedzeniem 0, odczyty logiczne lobu 0, odczyty fizyczne lobu 0, odczyty z wyprzedzeniem lobu 0.Tabela „SalesOrderHeader”. Liczba skanów 1, odczyty logiczne 333, odczyty fizyczne 0, odczyty z wyprzedzeniem 0, odczyty logiczne LOB 0, odczyty fizyczne LOB 0, odczyty LOB z wyprzedzeniem 0.
Paul wskazał na jeszcze prostsze powtórzenie:
SET STATISTICS IO ON; GO SELECT TOP (15000) * FROM Production.TransactionHistory WHERE TransactionDate < (SELECT '20080101') OPTION (QUERYTRACEON 8649, MAXDOP 4); SELECT TOP (15000) * FROM Production.TransactionHistory AS th WHERE TransactionDate < (SELECT '20080101');
Wyniki:
Tabela „Historia transakcji”. Liczba skanów 1, odczyty logiczne 5, odczyty fizyczne 0, odczyty z wyprzedzeniem 0, odczyty logiczne lobu 0, odczyty fizyczne lobu 0, odczyty z wyprzedzeniem lobu 0.Tabela „Historia transakcji”. Liczba skanów 1, odczyty logiczne 110, odczyty fizyczne 0, odczyty z wyprzedzeniem 0, odczyty logiczne lobu 0, odczyty fizyczne lobu 0, odczyty loba z wyprzedzeniem 0.
Wygląda więc na to, że możemy łatwo odtworzyć to do woli za pomocą TOP operatora i wystarczająco niski DOP. Zgłosiłem błąd:
- STATYSTYKI IO zgłasza niedoszacowanie odczytów logicznych dla planów równoległych
A Paul zgłosił dwa inne, nieco powiązane błędy dotyczące paralelizmu, pierwszy w wyniku naszej rozmowy:
- Błąd oszacowania kardynalności z predykatem wypchniętym w wyszukiwaniu [powiązany wpis na blogu]
- Słaba wydajność z równoległością i Top [powiązany wpis na blogu]
(Dla nostalgii, oto sześć innych błędów paralelizmu, które wskazałem kilka lat temu.)
Jaka jest lekcja?
Uważaj, aby ufać jednemu źródłu. Jeśli spojrzysz wyłącznie na STATISTICS IO po zmianie zapytania w ten sposób możesz pokusić się o skupienie się na cudownym spadku liczby odczytów zamiast na zwiększeniu czasu trwania. W tym momencie możesz poklepać się po plecach, wyjść wcześniej z pracy i cieszyć się weekendem, myśląc, że właśnie wywarłeś ogromny wpływ na wydajność zapytania. Oczywiście nic nie może być dalsze od prawdy.