SQL Server oferuje dwie metody zbierania danych diagnostycznych i rozwiązywania problemów dotyczących obciążenia wykonywanego na serwerze:śledzenie SQL i zdarzenia rozszerzone. Począwszy od programu SQL Server 2012, implementacja zdarzeń rozszerzonych zapewnia porównywalne możliwości gromadzenia danych do programu SQL Trace i może być używana do porównywania narzutów ponoszonych przez te dwie funkcje. W tym artykule przyjrzymy się porównaniu „narzutu obserwatora”, który występuje podczas korzystania ze śledzenia SQL i zdarzeń rozszerzonych w różnych konfiguracjach, aby określić wpływ na wydajność, jaki gromadzenie danych może mieć na nasze obciążenie poprzez użycie obciążenia odtwarzania przechwytywanie i rozpowszechnianie powtórki.
Środowisko testowe
Środowisko testowe składa się z sześciu maszyn wirtualnych, jednego kontrolera domeny, jednego serwera SQL Server 2012 Enterprise Edition oraz czterech serwerów klienckich z zainstalowaną usługą klienta Distributed Replay. W tym artykule przetestowano różne konfiguracje hosta, a podobne wyniki uzyskano z trzech różnych konfiguracji, które zostały przetestowane na podstawie współczynnika wpływu. Serwer SQL Server Enterprise Edition jest skonfigurowany z 4 procesorami wirtualnymi i 4 GB pamięci RAM. Pozostałe pięć serwerów jest skonfigurowanych z 1 procesorem wirtualnym i 1 GB pamięci RAM. Usługa kontrolera Distributed Replay została uruchomiona na serwerze SQL Server 2012 Enterprise Edition, ponieważ wymaga licencji Enterprise, aby używać więcej niż jednego klienta do odtwarzania.
Obciążenie testowe
Obciążenie testowe używane do przechwytywania powtórek to obciążenie AdventureWorks Books Online, które stworzyłem w zeszłym roku do generowania próbnych obciążeń dla SQL Server. To obciążenie wykorzystuje przykładowe zapytania z Books Online względem rodziny baz danych AdventureWorks i jest sterowane przez program PowerShell. Obciążenie zostało skonfigurowane na każdym z czterech klientów powtórek i uruchomione z czterema połączeniami z serwerem SQL z każdego z serwerów klienckich w celu wygenerowania 1 GB przechwytywania śladów powtórek. Ślad powtórki został utworzony przy użyciu szablonu TSQL_Replay z programu SQL Server Profiler, wyeksportowany do skryptu i skonfigurowany jako ślad po stronie serwera do pliku. Po przechwyceniu pliku śledzenia powtórek został on wstępnie przetworzony do użycia w funkcji Distributed Replay, a następnie dane powtórek zostały użyte jako obciążenie związane z odtwarzaniem powtórek we wszystkich testach.
Konfiguracja powtórek
Operacja powtórki została skonfigurowana tak, aby używać konfiguracji trybu obciążenia do sterowania maksymalnym obciążeniem testowej instancji programu SQL Server. Ponadto konfiguracja wykorzystuje skróconą skalę czasu myślenia i łączenia, która dostosowuje stosunek czasu między początkiem śladu powtórki a momentem faktycznego wystąpienia zdarzenia do momentu, gdy jest ono odtwarzane podczas operacji powtórki, aby umożliwić odtworzenie zdarzeń o godz. maksymalna skala. Skala stresu dla powtórki jest również konfigurowana per spid. Szczegóły pliku konfiguracyjnego dla operacji odtwarzania były następujące:
<?xml version="1.0" encoding="utf-8"?>
<Options>
<ReplayOptions>
<Server>SQL2K12-SVR1</Server>
<SequencingMode>stress</SequencingMode>
<ConnectTimeScale>1</ConnectTimeScale>
<ThinkTimeScale>1</ThinkTimeScale>
<HealthmonInterval>60</HealthmonInterval>
<QueryTimeout>3600</QueryTimeout>
<ThreadsPerClient>255</ThreadsPerClient>
<EnableConnectionPooling>Yes</EnableConnectionPooling>
<StressScaleGranularity>spid</StressScaleGranularity>
</ReplayOptions>
<OutputOptions>
<ResultTrace>
<RecordRowCount>No</RecordRowCount>
<RecordResultSet>No</RecordResultSet>
</ResultTrace>
</OutputOptions>
</Options> Podczas każdej z operacji powtórki, liczniki wydajności były zbierane w pięciosekundowych odstępach dla następujących liczników:
- Procesor\% czasu procesora\_Całkowity
- SQL Server\SQL Statistics\Batch Requests/s
Liczniki te będą używane do pomiaru ogólnego obciążenia serwera oraz charakterystyki przepustowości każdego z testów w celu porównania.
Konfiguracje testowe
W programie Distributed Replay przetestowano w sumie siedem różnych konfiguracji:
- Podstawa
- Śledzenie po stronie serwera
- Profiler na serwerze
- Profiluj zdalnie
- Rozszerzone wydarzenia do event_file
- Wydarzenia rozszerzone do ring_buffer
- Wydarzenia rozszerzone do event_stream
Każdy test został powtórzony trzy razy, aby zapewnić spójność wyników w różnych testach i zapewnić średni zestaw wyników do porównania. W przypadku początkowych testów podstawowych nie skonfigurowano żadnego dodatkowego zbierania danych dla wystąpienia programu SQL Server, ale domyślne kolekcje danych dostarczane z programem SQL Server 2012 pozostały włączone:śledzenie domyślne i sesja zdarzeń system_health. Odzwierciedla to ogólną konfigurację większości serwerów SQL, ponieważ generalnie nie zaleca się wyłączania domyślnej sesji śledzenia lub kondycji systemu ze względu na korzyści, jakie zapewniają administratorom baz danych. Test ten został wykorzystany do określenia ogólnej linii bazowej dla porównania z testami, w których wykonywano dodatkowe gromadzenie danych. Pozostałe testy są oparte na szablonie TSQL_SPs, który jest dostarczany z programem SQL Server Profiler i zbiera następujące zdarzenia:
- Audyt bezpieczeństwa\Logowanie do audytu
- Audyt bezpieczeństwa\Wylogowanie z audytu
- Sesje\Istniejące połączenie
- Procedury przechowywane\RPC:Uruchamianie
- Procedury przechowywane\SP:Zakończono
- Procedury przechowywane\SP:Rozpoczęcie
- Procedury przechowywane\SP:StmtStarting
- TSQL\SQL:Uruchamianie wsadowe
Ten szablon został wybrany na podstawie obciążenia użytego do testów, które obejmuje głównie partie SQL przechwycone przez SQL:BatchStarting zdarzenie, a następnie kilka zdarzeń przy użyciu różnych metod hierarchyid , które są przechwytywane przez SP:Starting , SP:StmtStarting i SP:Completed wydarzenia. Skrypt śledzenia po stronie serwera został wygenerowany z szablonu przy użyciu funkcji eksportu w programie SQL Server Profiler, a jedyne zmiany wprowadzone w skrypcie polegały na ustawieniu maxfilesize parametr na 500 MB, włącz przewijanie pliku śledzenia i podaj nazwę pliku, do którego został zapisany ślad.
Testy trzeci i czwarty wykorzystywały program SQL Server Profiler do zbierania tych samych zdarzeń, co śledzenie po stronie serwera w celu pomiaru obciążenia wydajności śledzenia przy użyciu aplikacji Profiler. Testy te zostały uruchomione przy użyciu SQL Profiler lokalnie na SQL Server i zdalnie z oddzielnego klienta, aby upewnić się, czy istnieje różnica w narzutach poprzez posiadanie Profilera działającego lokalnie lub zdalnie.
W końcowych testach wykorzystano Extended Events zebrano te same zdarzenia i te same kolumny w oparciu o sesję zdarzeń utworzoną za pomocą mojego skryptu konwersji Trace to Extended Events dla SQL Server 2012. Testy obejmowały ocenę pliku event_file, ring_buffer i nowego dostawcy przesyłania strumieniowego w SQL Server 2012 oddzielnie, aby określić obciążenie, jakie każdy cel może nałożyć na wydajność serwera. Ponadto sesja zdarzenia została skonfigurowana z domyślnymi opcjami bufora pamięci, ale została zmieniona, aby określić NO_EVENT_LOSS dla EVENT_RETENTION_MODE opcja dla testów event_file i ring_buffer w celu dopasowania zachowania śledzenia po stronie serwera do pliku, co gwarantuje również brak utraty zdarzeń.
Wyniki
Z jednym wyjątkiem wyniki testów nie były zaskakujące. Test bazowy był w stanie wykonać obciążenie związane z odtwarzaniem w ciągu trzynastu minut i trzydziestu pięciu sekund, a podczas testów średnio 2345 żądań wsadowych na sekundę. Przy uruchomionym Trace po stronie serwera operacja odtwarzania zakończyła się w 16 minut i 40 sekund, co oznacza spadek wydajności o 18,1%. Profiler Traces miał ogólnie najgorsze wyniki i wymagał 149 minut, gdy Profiler był uruchamiany lokalnie na serwerze oraz 123 minut i 20 sekund, gdy Profiler był uruchamiany zdalnie, co dało odpowiednio 90,8% i 87,6% spadek wydajności. Testy Extended Events osiągnęły najlepsze wyniki, zabierając 15 minut i 15 sekund dla pliku event_file oraz 15 minut i 40 sekund dla celu ring_buffer, co skutkowało pogorszeniem wydajności o 10,4% i 11,6%. Średnie wyniki dla wszystkich testów są przedstawione w Tabeli 1 i przedstawione na Rysunku 2:
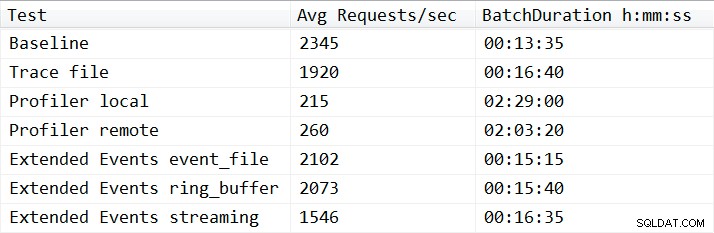
Tabela 1 – Średnie wyniki wszystkich testów
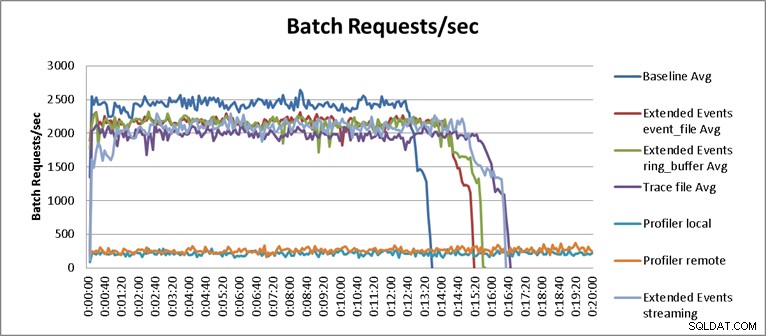
Rysunek 2 – Wykres wyników
Test strumieniowania zdarzeń rozszerzonych nie jest całkiem sprawiedliwym wynikiem w kontekście testów, które zostały przeprowadzone i wymaga nieco więcej wyjaśnień, aby zrozumieć wynik. Z wyników tabeli widać, że testy strumieniowe dla zdarzeń rozszerzonych zakończyły się w szesnaście minut i trzydzieści pięć sekund, co oznacza 34,1% pogorszenie wydajności. Jeśli jednak przybliżymy wykres i zmienimy jego skalę, jak pokazano na rysunku 3, zobaczymy, że strumieniowanie miało początkowo znacznie większy wpływ na wydajność, a następnie zaczęło działać w sposób podobny do innych testów zdarzeń rozszerzonych :
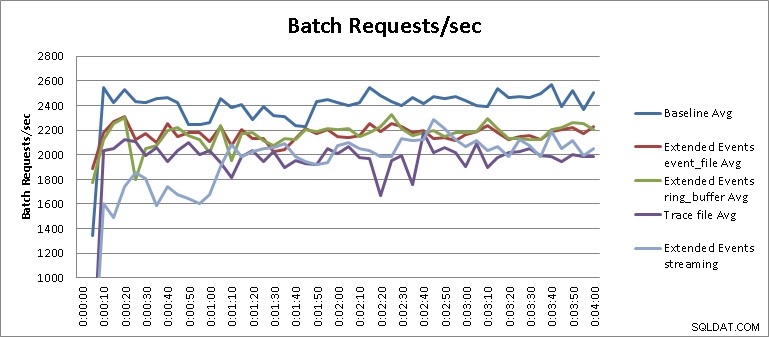
Rysunek 3 – Wyniki w powiększeniu
Wyjaśnienie tego można znaleźć w projekcie nowego docelowego przesyłania strumieniowego zdarzeń rozszerzonych w programie SQL Server 2012. Jeśli bufory pamięci wewnętrznej dla strumienia zdarzenia_zapełniają się i nie są zużywane przez aplikację kliencką wystarczająco szybko, aparat bazy danych wymusi rozłączenie event_stream, aby zapobiec poważnemu wpływowi na wydajność serwera. Powoduje to zgłoszenie błędu w SQL Server 2012 Management Studio podobnego do błędu na rysunku 4:
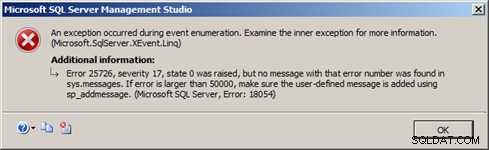
Rysunek 4 – event_stream rozłączony przez serwer
(Microsoft.SqlServer.XEvent.Linq)
Błąd 25726, ważność 17, stan 0 został zgłoszony, ale nie znaleziono komunikatu o tym numerze błędu w sys.wiadomości. Jeśli błąd jest większy niż 50000, upewnij się, że komunikat zdefiniowany przez użytkownika został dodany przy użyciu sp_addmessage.
(Microsoft SQL Server, błąd:18054)
Wnioski
Wszystkie metody zbierania danych diagnostycznych z programu SQL Server wiążą się z „narzutem obserwatora” i mogą mieć wpływ na wydajność obciążenia przy dużym obciążeniu. W przypadku systemów działających w programie SQL Server 2012 zdarzenia rozszerzone zapewniają najmniejsze obciążenie i zapewniają podobne możliwości dla zdarzeń i kolumn jak śledzenie SQL (niektóre zdarzenia w śledzeniu SQL są łączone w inne zdarzenia w zdarzeniach rozszerzonych). Jeśli śledzenie SQL jest konieczne do przechwytywania danych zdarzeń — co może mieć miejsce do czasu przekodowania narzędzi innych firm w celu wykorzystania danych zdarzeń rozszerzonych — śledzenie po stronie serwera do pliku przyniesie najmniejsze obciążenie wydajnościowe. SQL Server Profiler to narzędzie, którego należy unikać na ruchliwych serwerach produkcyjnych, o czym świadczy dziesięciokrotny wzrost czasu trwania i znaczne zmniejszenie przepustowości w przypadku powtórek.
Chociaż wyniki wydają się faworyzować zdalne uruchamianie programu SQL Server Profiler, gdy trzeba użyć programu Profiler, nie można ostatecznie wyciągnąć tego wniosku na podstawie określonych testów, które zostały uruchomione w tym scenariuszu. Należy przeprowadzić dodatkowe testy i zbieranie danych, aby określić, czy wyniki zdalnego programu Profiler były wynikiem przełączania niższego kontekstu w wystąpieniu programu SQL Server, czy też sieci między maszynami wirtualnymi odgrywały rolę w mniejszym wpływie na wydajność zdalnego gromadzenia. Celem tych testów było pokazanie znacznego obciążenia, jakie ponosi Profiler, niezależnie od tego, gdzie Profiler był uruchamiany. Wreszcie strumień zdarzeń na żywo w zdarzeniach rozszerzonych ma również duże obciążenie, gdy jest faktycznie połączony podczas zbierania danych, ale jak pokazano w testach, aparat bazy danych odłączy strumień na żywo, jeśli opóźni się w zdarzeniach, aby zapobiec poważnemu wpływowi na wydajność serwera.