To pytanie zostało wysłane do #sqlhelp przez Jake'a Manske, a zwrócił moją uwagę Erik Darling.
Nie przypominam sobie, żebym kiedykolwiek miał problem z wydajnością z sys.partitions . Moją pierwszą myślą (wtórował Joey D'Antoni) było to, że filtr na data_compression kolumna powinna unikaj nadmiarowego skanowania i skróć czas wykonywania zapytań o około połowę. Jednak ten predykat nie jest spychany w dół i powód, dla którego wymaga trochę rozpakowania.
Dlaczego sys.partitions działa wolno?
Jeśli spojrzysz na definicję sys.partitions , jest to w zasadzie to, co opisał Jake – UNION ALL wszystkich partycji magazynu kolumn i magazynu wierszy, z TRZY wyraźne odniesienia do sys.sysrowsets (źródło skrócone tutaj):
CREATE VIEW sys.partitions AS
WITH partitions_columnstore(...cols...)
AS
(
SELECT ...cols...,
cmprlevel AS data_compression ...
FROM sys.sysrowsets rs OUTER APPLY OpenRowset(TABLE ALUCOUNT, rs.rowsetid, 0, 0, 0) ct
-------- *** ^^^^^^^^^^^^^^ ***
LEFT JOIN sys.syspalvalues cl ...
WHERE ... sysconv(bit, rs.status & 0x00010000) = 1 -- Consider only columnstore base indexes
),
partitions_rowstore(...cols...)
AS
(
SELECT ...cols...,
cmprlevel AS data_compression ...
FROM sys.sysrowsets rs
-------- *** ^^^^^^^^^^^^^^ ***
LEFT JOIN sys.syspalvalues cl ...
WHERE ... sysconv(bit, rs.status & 0x00010000) = 0 -- Ignore columnstore base indexes and orphaned rows.
)
SELECT ...cols...
from partitions_rowstore p OUTER APPLY OpenRowset(TABLE ALUCOUNT, p.partition_id, 0, 0, p.object_id) ct
union all
SELECT ...cols...
FROM partitions_columnstore as P1
LEFT JOIN
(SELECT ...cols...
FROM sys.sysrowsets rs OUTER APPLY OpenRowset(TABLE ALUCOUNT, rs.rowsetid, 0, 0, 0) ct
------- *** ^^^^^^^^^^^^^^ ***
) ...
Ten pogląd wydaje się sklecony, prawdopodobnie z powodu obaw o kompatybilność wsteczną. Z pewnością można by go przepisać, aby był bardziej wydajny, w szczególności, aby odwoływać się tylko do sys.sysrowsets i TABLE ALUCOUNT przedmioty raz. Ale teraz niewiele możemy z tym zrobić.
Kolumna cmprlevel pochodzi z sys.sysrowsets (przydatny byłby prefiks aliasu w odwołaniu do kolumny). Mógłbyś mieć nadzieję, że orzeczenie przeciwko kolumnie tam logicznie wydarzy się przed jakimkolwiek OUTER APPLY i może zapobiec jednemu ze skanów, ale tak się nie dzieje. Uruchamiam następujące proste zapytanie:
SELECT * FROM sys.partitions AS p INNER JOIN sys.objects AS o ON p.object_id = o.object_id WHERE o.is_ms_shipped = 0;
Daje następujący plan, gdy w bazach danych znajdują się indeksy magazynu kolumn (kliknij, aby powiększyć):
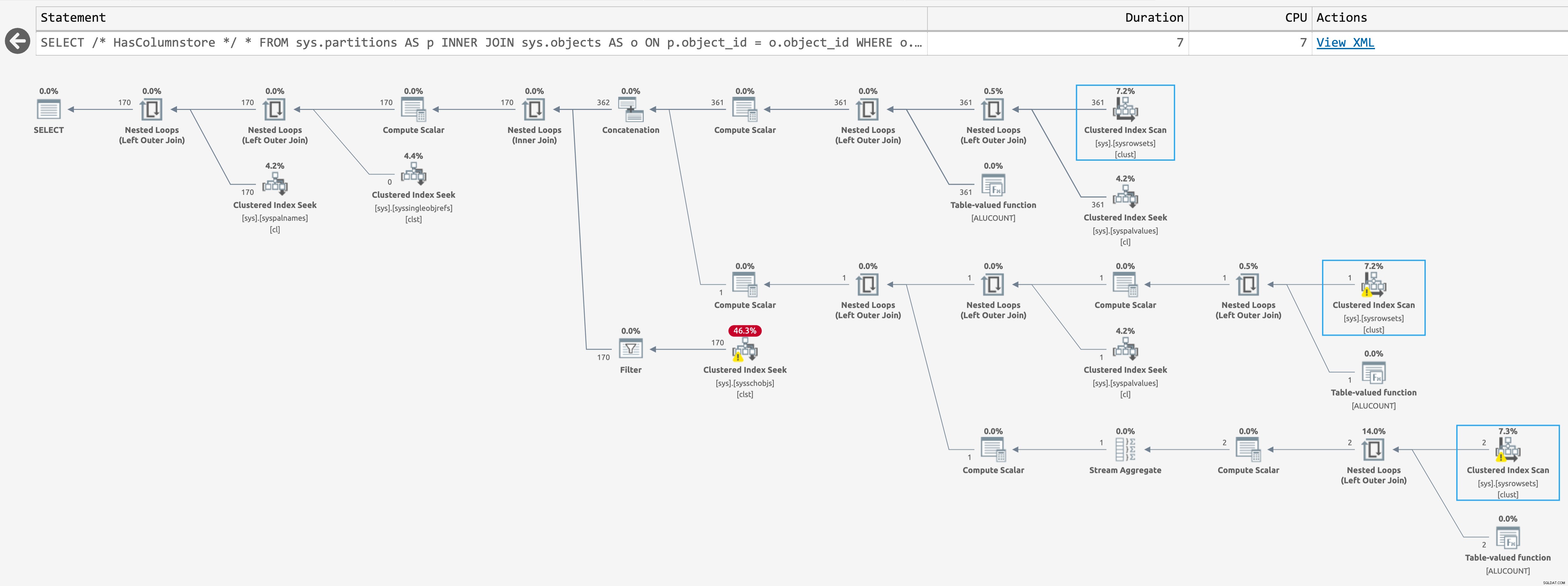 Plan dla sys.partitions z obecnymi indeksami magazynu kolumn
Plan dla sys.partitions z obecnymi indeksami magazynu kolumn
I następujący plan, gdy go nie ma (kliknij, aby powiększyć):
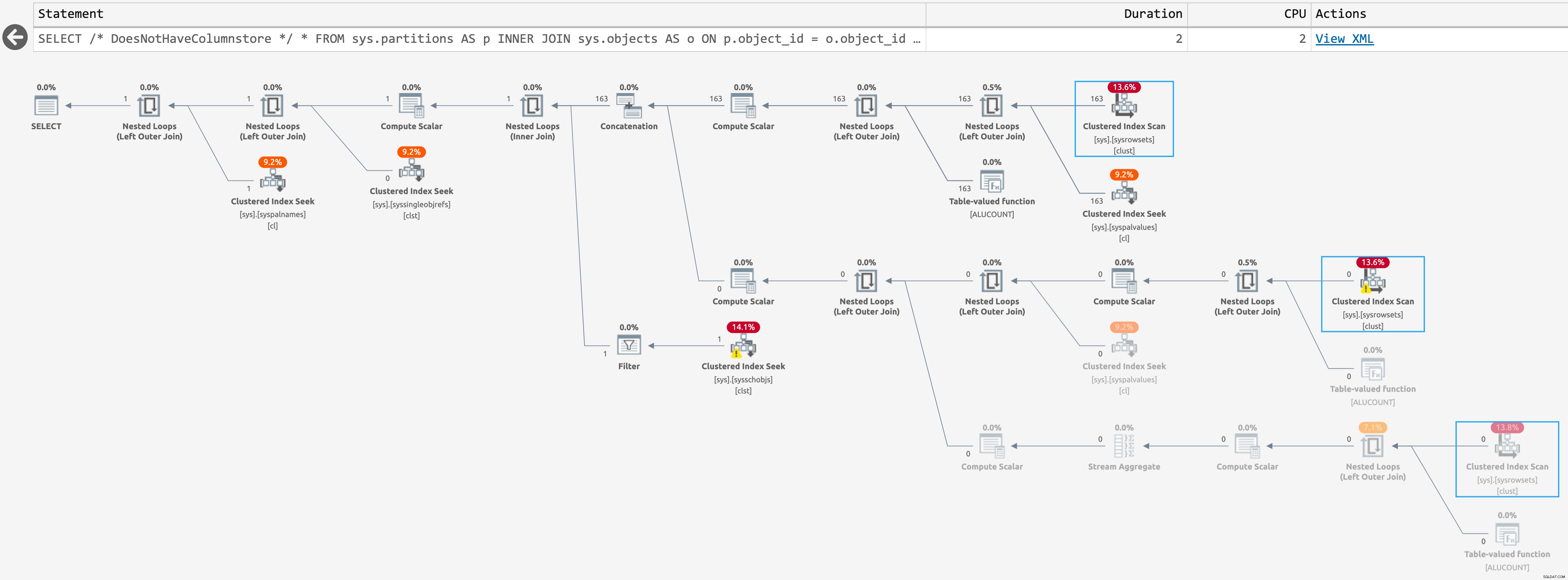 Plan dla sys.partitions bez indeksów magazynu kolumn
Plan dla sys.partitions bez indeksów magazynu kolumn
Są to ten sam szacunkowy plan, ale SentryOne Plan Explorer jest w stanie podświetlić, kiedy operacja jest pomijana w czasie wykonywania. Dzieje się tak w przypadku trzeciego skanowania w tym drugim przypadku, ale nie wiem, czy istnieje sposób na dalsze zmniejszenie liczby skanów w czasie wykonywania; drugie skanowanie ma miejsce nawet wtedy, gdy zapytanie zwraca zero wierszy.
W przypadku Jake'a ma dużo obiektów, więc wykonanie tego skanu nawet dwa razy jest zauważalne, bolesne i jednorazowo za dużo. I szczerze mówiąc nie wiem czy TABLE ALUCOUNT , wewnętrzne i nieudokumentowane wywołanie pętli zwrotnej, musi również wielokrotnie skanować niektóre z tych większych obiektów.
Patrząc wstecz na źródło, zastanawiałem się, czy istnieje jakikolwiek inny predykat, który można by przekazać do widoku, który mógłby wymusić kształt planu, ale naprawdę nie sądzę, aby było coś, co mogłoby mieć wpływ.
Czy zadziała inny widok?
Moglibyśmy jednak wypróbować zupełnie inny pogląd. Szukałem innych widoków, które zawierały odniesienia do obu sys.sysrowsets i ALUCOUNT , a na liście pojawia się wiele, ale tylko dwa są obiecujące:sys.internal_partitions i sys.system_internals_partitions .
sys.internal_partitions
Próbowałem sys.internal_partitions po pierwsze:
SELECT * FROM sys.internal_partitions AS p INNER JOIN sys.objects AS o ON p.object_id = o.object_id WHERE o.is_ms_shipped = 0;
Ale plan nie był dużo lepszy (kliknij, aby powiększyć):
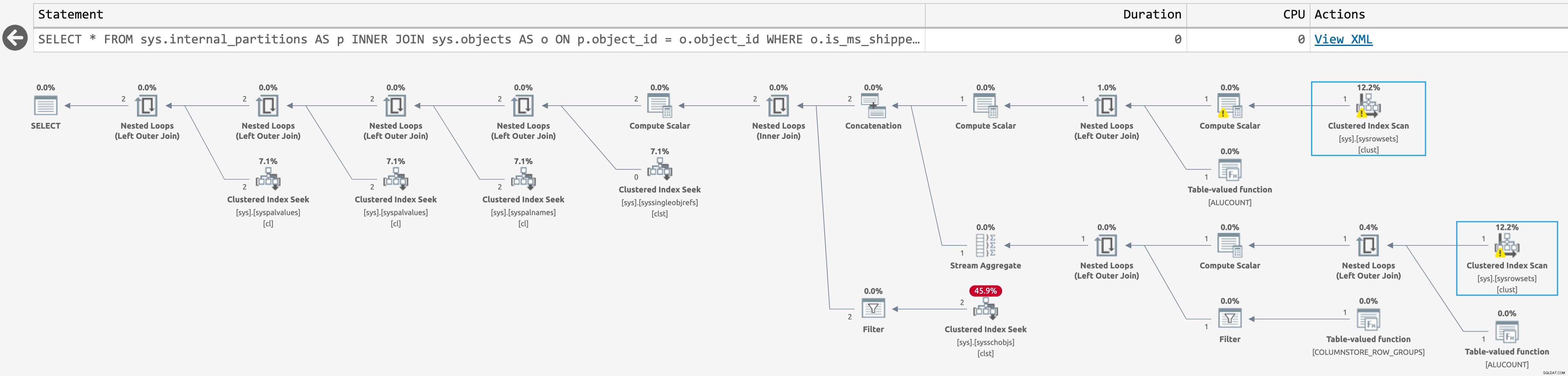 Plan dla sys.internal_partitions
Plan dla sys.internal_partitions
Istnieją tylko dwa skany dla sys.sysrowsets tym razem, ale skany i tak są nieistotne, ponieważ zapytanie nie zbliża się do utworzenia wierszy, które nas interesują. Widzimy tylko wiersze dla obiektów związanych z magazynem kolumn (jak stwierdza dokumentacja).
sys.system_internals_partitions
Spróbujmy sys.system_internals_partitions . Nie przejmuję się tym, ponieważ nie jest to obsługiwane (patrz ostrzeżenie tutaj), ale wytrzymaj ze mną przez chwilę:
SELECT * FROM sys.system_internals_partitions AS p INNER JOIN sys.objects AS o ON p.object_id = o.object_id WHERE o.is_ms_shipped = 0;
W bazie danych z indeksami magazynu kolumn znajduje się skan pod kątem sys.sysschobjs , ale teraz tylko jeden skanuj z sys.sysrowsets (kliknij, aby powiększyć):
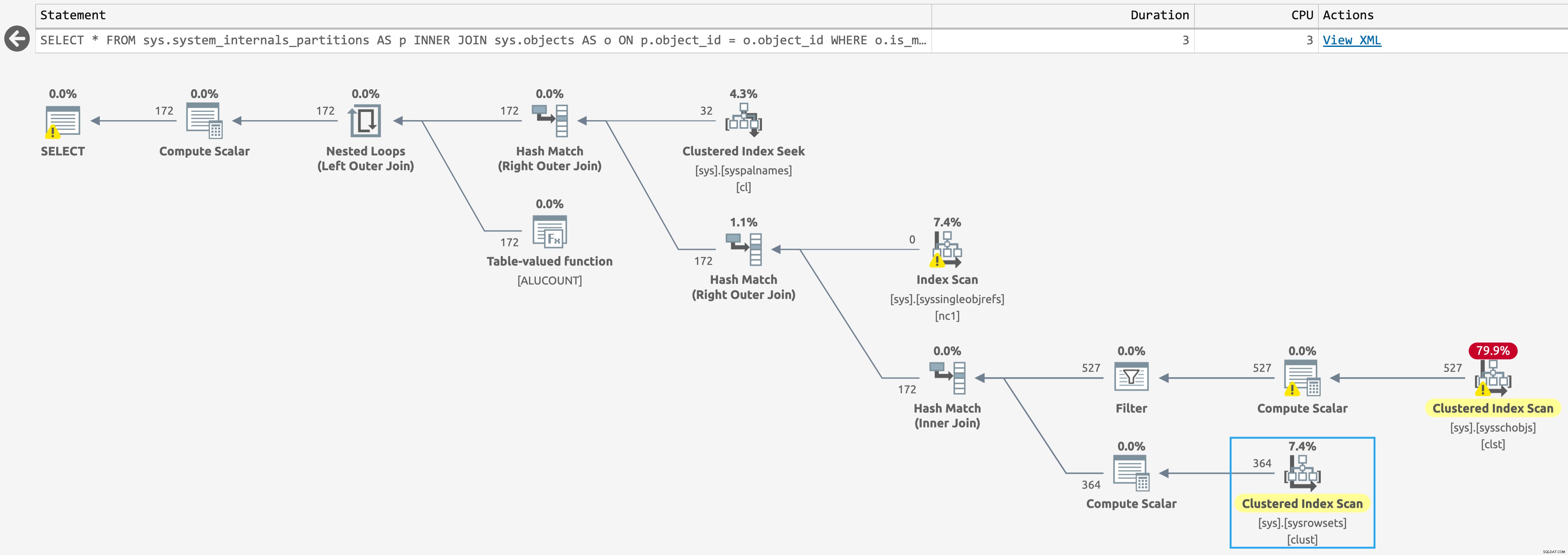 Plan dla sys.system_internals_partitions z obecnymi indeksami magazynu kolumn
Plan dla sys.system_internals_partitions z obecnymi indeksami magazynu kolumn
Jeśli uruchomimy to samo zapytanie w bazie danych bez indeksów magazynu kolumn, plan jest jeszcze prostszy, z wyszukiwaniem w sys.sysschobjs (kliknij, aby powiększyć):
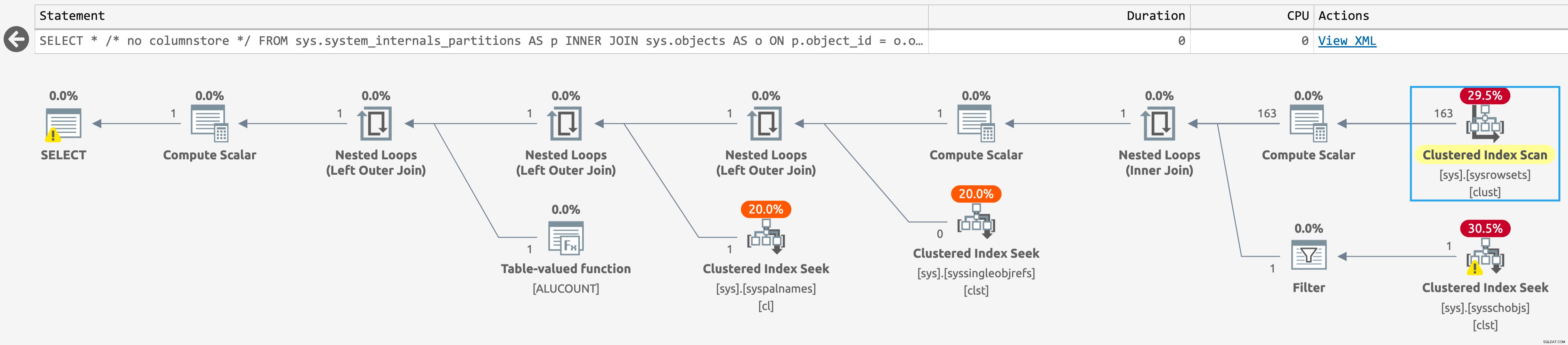 Plan dla sys.system_internals_partitions, bez indeksów magazynu kolumn
Plan dla sys.system_internals_partitions, bez indeksów magazynu kolumn
Jednak to nie jest do końca czego szukamy, a przynajmniej nie do końca tego, czego szukał Jake, ponieważ zawiera również artefakty z indeksów magazynu kolumn. Jeśli dodamy te filtry, rzeczywisty wynik będzie teraz pasował do naszego wcześniejszego, znacznie droższego zapytania:
SELECT *
FROM sys.system_internals_partitions AS p
INNER JOIN sys.objects AS o ON p.object_id = o.object_id
WHERE o.is_ms_shipped = 0
AND p.is_columnstore = 0
AND p.is_orphaned = 0;
Jako bonus, skanowanie przeciwko sys.sysschobjs stał się wyszukiwaniem nawet w bazie danych z obiektami magazynu kolumn. Większość z nas nie zauważy tej różnicy, ale jeśli jesteś w scenariuszu takim jak Jake, możesz (kliknij, aby powiększyć):
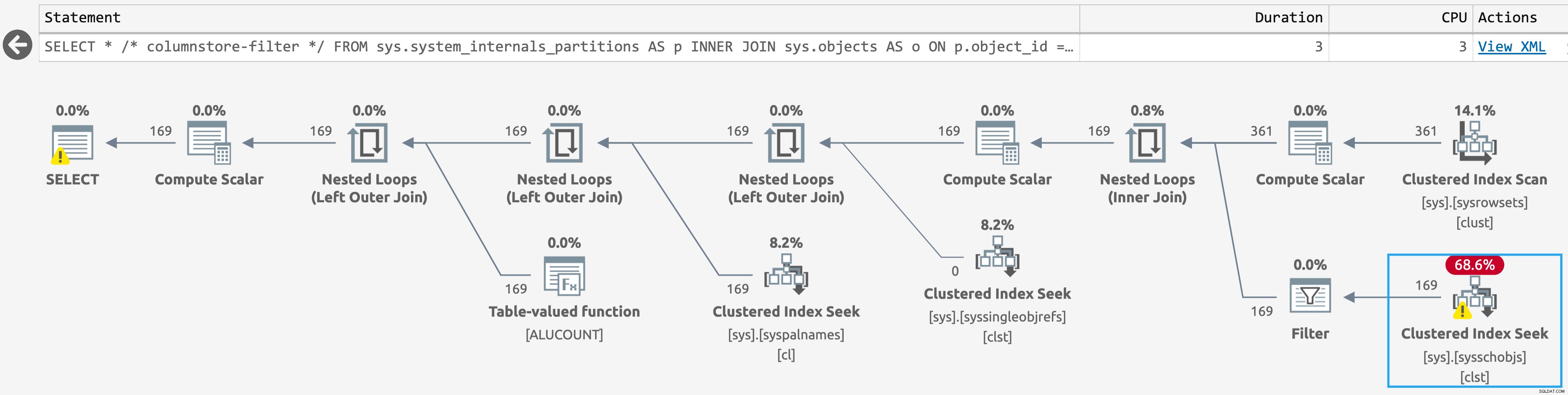 Prostszy plan dla sys.system_internals_partitions, z dodatkowymi filtrami
Prostszy plan dla sys.system_internals_partitions, z dodatkowymi filtrami
sys.system_internals_partitions udostępnia inny zestaw kolumn niż sys.partitions (niektóre są zupełnie inne, inne mają nowe nazwy), więc jeśli zużywasz dane wyjściowe, będziesz musiał się do nich dostosować. Będziesz także chciał sprawdzić, czy zwraca wszystkie potrzebne informacje w indeksach magazynu wierszy, zoptymalizowanych pod kątem pamięci i magazynu kolumn, i nie zapomnij o tych nieznośnych stosach. I na koniec przygotuj się na pominięcie s w internals wiele, wiele razy.
Wniosek
Jak wspomniałem powyżej, ten widok systemowy nie jest oficjalnie obsługiwany, więc jego funkcjonalność może ulec zmianie w dowolnym momencie; można go również przenieść w ramach dedykowanego połączenia administratora (DAC) lub całkowicie usunąć z produktu. Możesz użyć tego podejścia, jeśli sys.partitions nie działa dobrze, ale upewnij się, że masz plan tworzenia kopii zapasowych. I upewnij się, że jest to udokumentowane jako coś, co testujesz regresją, kiedy zaczynasz testować przyszłe wersje SQL Server lub po aktualizacji, na wszelki wypadek.