Podczas gdy Jeff Atwood i Joe Celko zdają się sądzić, że koszt identyfikatorów GUID to nic wielkiego (zob. wpis na blogu Jeffa „Klucze podstawowe:identyfikatory kontra identyfikatory GUID” oraz ten wątek na grupie dyskusyjnej zatytułowany „Identity vs. Uniqueidentifier”), inni eksperci – a dokładniej eksperci ds. indeksów i architektury, skupiający się na przestrzeni SQL Server – zwykle nie zgadzają się z tym. Na przykład Kimberly Tripp omawia niektóre szczegóły w swoim poście „Przestrzeń dyskowa jest tania – TO NIE JEST CZĘŚĆ!”, w którym wyjaśnia, że wpływ nie dotyczy tylko miejsca na dysku i fragmentacji, ale, co ważniejsze, rozmiaru indeksu i pamięci. ślad stopy.
To, co mówi Kimberly, jest naprawdę prawdziwe – cały czas natrafiam na uzasadnienie „miejsce na dysku jest tanie” dla identyfikatorów GUID (przykład z zeszłego tygodnia). Istnieją inne uzasadnienia dla identyfikatorów GUID, w tym potrzeba generowania unikalnych identyfikatorów poza bazą danych (a czasami przed faktycznym utworzeniem wiersza) oraz potrzeba unikalnych identyfikatorów w oddzielnych systemach rozproszonych (i gdzie zakresy tożsamości nie są praktyczne). Ale naprawdę chcę obalić mit, że identyfikatory GUID nie kosztują tak dużo, ponieważ tak, i musisz wziąć pod uwagę te koszty w swojej decyzji.
Rozpocząłem tę misję, aby przetestować wydajność różnych rozmiarów kluczy, biorąc pod uwagę te same dane w tej samej liczbie wierszy, z tymi samymi indeksami i mniej więcej tym samym obciążeniem (odtworzenie *dokładnie* tego samego obciążenia może być dość trudne). Nie tylko chciałem zmierzyć podstawowe rzeczy, takie jak rozmiar indeksu i fragmentacja indeksu, ale także skutki, jakie mają one w dalszej kolejności, takie jak:
- wpływ na wykorzystanie puli buforów
- częstotliwość „złych” podziałów stron
- ogólny wpływ na realistyczny czas trwania obciążenia
- wpływ na średnie czasy działania poszczególnych zapytań
- wpływ na czas działania po wyzwalaczach
- wpływ na wykorzystanie tempdb
Do zbadania tych danych użyję różnych technik, w tym zdarzeń rozszerzonych, śledzenia domyślnego, DMV związanych z tempdb i doradcy wydajności SQL Sentry.
Konfiguracja
Najpierw utworzyłem milion klientów, których należy umieścić w tabeli początkowej za pomocą wbudowanych metadanych SQL Server; zapewniłoby to, że „przypadkowi” klienci będą składać się z tych samych danych naturalnych w każdym teście.
CREATE TABLE dbo.CustomerSeeds(rn INT PRIMARY KEY CLUSTERED, FirstName NVARCHAR(64), LastName NVARCHAR(64), E-mail NVARCHAR(320) NOT NULL UNIQUE, Active BIT); INSERT dbo.CustomerSeeds WITH (TABLOCKX) (rn, FirstName, LastName, EMail, [Active])SELECT rn =ROW_NUMBER() OVER (ORDER BY n), fn, ln, em, aFROM (SELECT TOP (1000000) fn, ln , em, a =MAX(a), n =MAX(NEWID()) FROM ( SELECT fn, ln, em, a, r =ROW_NUMBER() OVER (PARTITION BY em ORDER BY em) FROM ( SELECT TOP (2000000) fn =LEFT(o.nazwa, 64), ln =LEFT(c.nazwa, 64), em =LEFT(o.nazwa, LEN(c.nazwa)%5+1) + '.' + LEFT(c. nazwa, LEN(o.nazwa)%5+2) + '@' + PRAWY(c.nazwa, LEN(o.nazwa+c.nazwa)%12 + 1) + LEWY(RTRIM(SPRAWDZENIE(NEWID()) ),3) + '.com', a =PRZYPADEK GDY c.name LIKE '%y%' TO 0 JESZCZE 1 ZAKOŃCZ Z sys.all_objects AS o CROSS JOIN sys.all_columns AS c ORDER BY NEWID() ) AS x ) AS y GDZIE r =1 GRUPA WG fn, ln, em ZAMÓW WG n) AS z ZAMÓW WG rn;GO SELECT TOP (10) * FROM dbo.CustomerSeeds ZAMÓW WG rn;GO
Twój przebieg może się różnić, ale w moim systemie ta populacja zajęła 86 sekund. Dziesięć reprezentatywnych wierszy (kliknij, aby powiększyć):
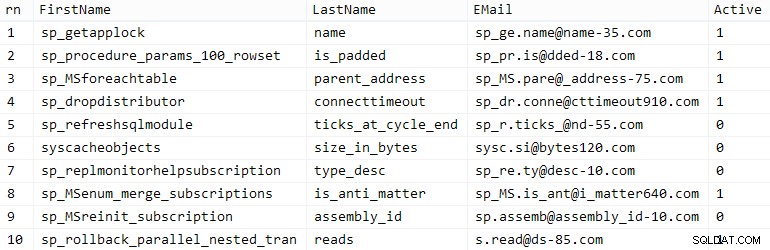 Przykładowi klienci
Przykładowi klienci
Następnie potrzebowałem tabel do przechowywania danych źródłowych dla każdego przypadku użycia, z kilkoma dodatkowymi indeksami symulującymi jakąś rzeczywistość, i wymyśliłem krótkie przyrostki, aby później ułatwić wszelkiego rodzaju diagnostykę:
| typ danych | domyślny | kompresja | przyrostek przypadku użycia |
|---|---|---|---|
| INT | TOŻSAMOŚĆ | brak | I |
| INT | TOŻSAMOŚĆ | strona + wiersz | Ic |
| WIELKIE | TOŻSAMOŚĆ | brak | B |
| WIELKIE | TOŻSAMOŚĆ | strona + wiersz | Bc |
| UNIKALNY IDENTYFIKATOR | NEWID() | brak | G |
| UNIKALNY IDENTYFIKATOR | NEWID() | strona + wiersz | Gc |
| UNIKALNY IDENTYFIKATOR | NEWSEQUENTIALID() | brak | S |
| UNIKALNY IDENTYFIKATOR | NEWSEQUENTIALID() | strona + wiersz | Sc |
Tabela 1:przypadki użycia, typy danych i przyrostki
W sumie osiem tabel, wszystkie pochodzące z tego samego szablonu (zmieniłbym po prostu komentarze, aby pasowały do przypadku użycia i zastąpiłem $use_case$ z odpowiednim przyrostkiem z powyższej tabeli):
CREATE TABLE dbo.Customers_$use_case$ -- I,Ic,B,Bc,G,Gc,S,Sc( CustomerID INT NOT NULL IDENTITY(1,1), --CustomerID BIGINT NOT NULL IDENTITY(1, 1), --CustomerID UNIQUEIDENTIFIER NOT NULL DEFAULT NEWID(), --CustomerID UNIQUEIDENTIFIER NOT NULL DEFAULT NEWSEQUENTIALID(), Imię NVARCHAR(64) NOT NULL, Nazwisko NVARCHAR(64) NOT NULL, E-mail NVARCHAR(320) NOT NULL, Aktywny BIT NOT NULL DEFAULT 1, Utworzono DATETIME NOT NULL DEFAULT SYSDATETIME(), Zaktualizowano DATETIME NULL, OGRANICZENIE C_PK_Customers_$use_case$ PRIMARY KEY (CustomerID)) --WITH (DATA_COMPRESSION =PAGE)GO;UTWÓRZ UNIKALNY INDEKS C_Email_Customers_$use_case$ Customers_$use_case$(EMail) --WITH (DATA_COMPRESSION =PAGE); INDEKS GOCREATE C_Active_Customers_$use_case$ ON dbo.Customers_$use_case$ (Imię, Nazwisko, e-mail) WHERE Aktywny =1 --WITH (DATA_COMPRESSION =PAGE);GOCREATE INDEKS C_Name_Customers_$use_case$ ON dbo.Customers_$use_case$(Nazwisko, Imię) INCLUDE (EMAIL) --WITH (DATA_COMPRESSION =PAGE);GOPo utworzeniu tabel przystąpiłem do ich wypełniania i mierzenia wielu wskaźników, o których wspomniałem powyżej. Zrestartowałem usługę SQL Server pomiędzy każdym testem, aby upewnić się, że wszystkie zaczynają się od tej samej linii bazowej, że DMV zostaną zresetowane itp.
Niekwestionowane wstawki
Moim ostatecznym celem było wypełnienie tabeli 1 000 000 wierszy, ale najpierw chciałem zobaczyć wpływ typu danych i kompresji na surowe wstawki bez rywalizacji. Wygenerowałem następujące zapytanie – które wypełniło tabelę pierwszymi 200 000 kontaktów, 2000 wierszy naraz – i uruchomiłem je dla każdej tabeli:
DECLARE @i INT =1;WHILE @i <=100BEGIN WSTAW dbo.Customers_$use_case$(Imię, Nazwisko, E-mail, Aktywny) SELECT Imię, Nazwisko, E-mail, Aktywny FROM dbo.CustomerSeeds AS c ORDER BY rn OFFSET 2000 * (@i-1) RZĘDY POBIERZ TYLKO NASTĘPNE 2000 RZĘDÓW; SET @i +=1;ENDWyniki (kliknij, aby powiększyć):
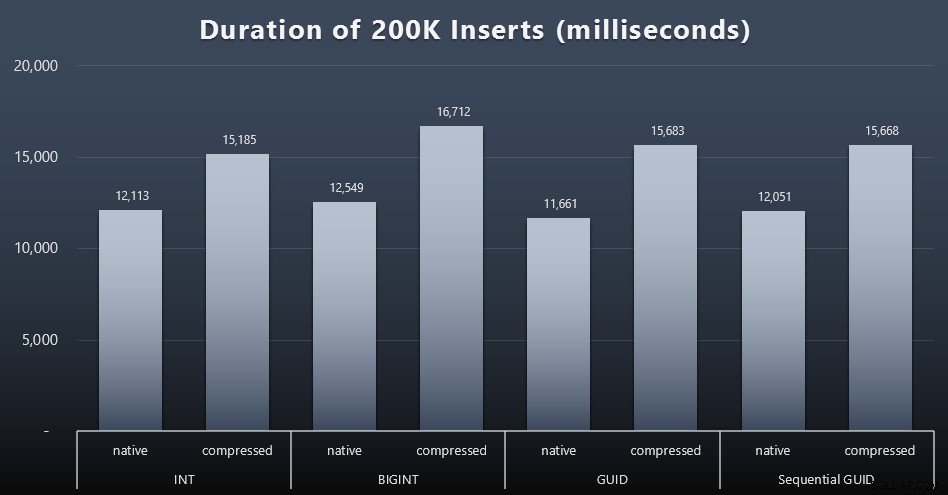
Każda sprawa zajęła około 12 sekund (bez kompresji) i 16 sekund (z kompresją), bez wyraźnego zwycięzcy w żadnym z trybów przechowywania. Efekt kompresji (głównie na obciążenie procesora) jest dość spójny, ale ponieważ działa ona na szybkim dysku SSD, wpływ we/wy różnych typów danych jest znikomy. W rzeczywistości kompresja przeciwko BIGINT wydawała się mieć największy wpływ (i to ma sens, ponieważ każda pojedyncza wartość poniżej 2 miliardów zostałaby skompresowana).
Więcej kontrowersyjnych zadań
Następnie chciałem zobaczyć, jak mieszane obciążenie będzie konkurować o zasoby i ogólnie działać z każdym typem danych. Więc stworzyłem te procedury (zastępując
$use_case$i$data_type$odpowiednio dla każdego testu):-- losowe pojedyncze aktualizacje danych w więcej niż jednym indeksie PROCEDURA TWORZENIA [dbo].[Customers_$use_case$_RandomUpdate] @Customers_$use_case$ $data_type$ASBEGIN USTAWIĆ NOCOUNT ON; UPDATE dbo.Customers_$use_case$ SET LastName =COALESCE(STUFF(LastName, 4, 1, 'x'),'x') WHERE CustomerID =@Customers_$use_case$;ENDGO -- odczyty ("paginacja") - obsługa wielu sorts — użyj dynamicznego SQL do oddzielnego śledzenia statystyk zapytań CREATE PROCEDURE [dbo].[Customers_$use_case$_Page] @PageNumber INT =1, @PageSize INT =100, @sort SYSNAMEASBEGIN SET NOCOUNT ON; DECLARE @sql NVARCHAR(MAX) =N'SELECT IDKlienta, Imię, Nazwisko, E-mail, Aktywny, Utworzony, Zaktualizowany FROM dbo.Customers_$use_case$ ORDER BY ' + @sort + N' OFFSET ((@pn-1)*@ ps) ROWS FETCH NEXT @ps ROWS ONLY;'; EXEC sys.sp_executesql @sql, N'@pn INT, @ps INT', @PageNumber, @PageSize;ENDGONastępnie stworzyłem stanowiska, które wielokrotnie, z niewielkimi opóźnieniami, wywoływały te procedury, a także – jednocześnie – kończyły zapełnianie pozostałych 800 000 kontaktów. Ten skrypt tworzy wszystkie 32 zadania, a także wyświetla dane wyjściowe, które można później wykorzystać do asynchronicznego wywołania wszystkich zadań dla określonego testu:
USE msdb;GO DECLARE @typ TABLE(use_case VARCHAR(2), data_type SYSNAME);INSERT @typ(use_case, data_type) VALUES('I', N'INT'), ('Ic',N'INT '),('B', N'BIGINT'), ('Bc', N'BIGINT'),('G', N'UNIKALNY IDENTYFIKATOR'), ('Gc', N'UNIKALNY IDENTYFIKATOR'),('S ', N'UNIKALNY IDENTYFIKATOR'), ('Sc', N'UNIKALNY IDENTYFIKATOR'); DECLARE @jobs TABLE(nazwa SYSNAME, cmd NVARCHAR(MAX));INSERT @jobs(nazwa, cmd) VALUES( N'Losowe obciążenie aktualizacji', N'DECLARE @CustomerID $data_type$, @i INT =1; WHILE @i <=500 BEGIN SELECT TOP (1) @CustomerID =CustomerID FROM dbo.Customers_$use_case$ ORDER BY NEWID(); EXEC dbo.Customers_$use_case$_RandomUpdate @Customers_$use_case$ =@CustomerID; WAITFOR DELAY ''00:00 :01''; SET @i +=1; END'),( N'Wypełnij klientów', N'SET QUOTED_IDENTIFIER ON; DECLARE @i INT =101; WHILE @i <=500 BEGIN INSERT dbo.Customers_$use_case$ (Imię, Nazwisko, E-mail, Aktywne) SELECT Imię, Nazwisko, E-mail, Aktywny FROM dbo.CustomerSeeds AS c ORDER BY rn OFFSET 2000 * (@i-1) ROWS FETCH NEXT 2000 ROWS ONLY; CZEKAJ NA OPÓŹNIENIE ''00:00:01''; SET @i +=1; END'),( N'Obciążenie stronicowania 1', N'DECLARE @i INT =1, @sql NVARCHAR(MAX); WHILE @i <=1001 BEGIN -- sortuj według CustomerID SET @sql =N ''EXEC dbo.Customers_$use_case$_Page @PageNumber =@i, @sort =N''''CustomerID'''';''; EXEC sys.sp_executesql @sql, N''@i INT'', @i; CZEKAJ NA OPÓŹNIENIE ''00:00:01''; USTAW @i +=2; END'),( N'Obciążenie stronicowania 2', N'DECLARE @i INT =1, @sql NVARCHAR(MAX); WHILE @i <=1001 BEGIN -- sortuj według nazwiska, imienia SET @sql =N''EXEC dbo.Customers_$use_case$_Page @PageNumber =@i, @sort =N''''Nazwisko, Imię'''';''; EXEC sys.sp_executesql @sql, N''@i INT'', @i; CZEKAJ NA OPÓŹNIENIE ''00:00:01''; USTAW @i +=2; END'); ZADEKLARUJ @n NAZWA SYS, @c NVARCHAR(MAX); DECLARE c CURSOR LOCAL FAST_FORWARD FORSELECT name =t.use_case + N' ' + j.name, cmd =REPLACE(REPLACE(j.cmd, N'$use_case$', t.use_case), N'$data_type$', t .data_type) FROM @typ AS t CROSS JOIN @jobs AS j; OTWARTE c; POBIERZ c DO @n, @c; WHILE @@FETCH_STATUS <> -1BEGIN JEŚLI ISTNIEJE (WYBIERZ 1 Z msdb.dbo.sysjobs WHERE nazwa =@n) BEGIN EXEC msdb.dbo.sp_delete_job @job_name =@n; END EXEC msdb.dbo.sp_add_job @job_name =@n, @enabled =0, @notify_level_eventlog =0, @category_id =0, @owner_login_name =N'sa'; EXEC msdb.dbo.sp_add_jobstep @job_name =@n, @step_name =@n, @command =@c, @database_name =N'ID'; EXEC msdb.dbo.sp_add_jobserver @job_name =@n, @server_name =N'(lokalne)'; PRINT 'EXEC msdb.dbo.sp_start_job @job_name =N''' + @n + ''';'; FETCH c INTO @n, @c;ENDPomiar czasu pracy w każdym przypadku był banalny – mogłem sprawdzić daty rozpoczęcia/zakończenia w
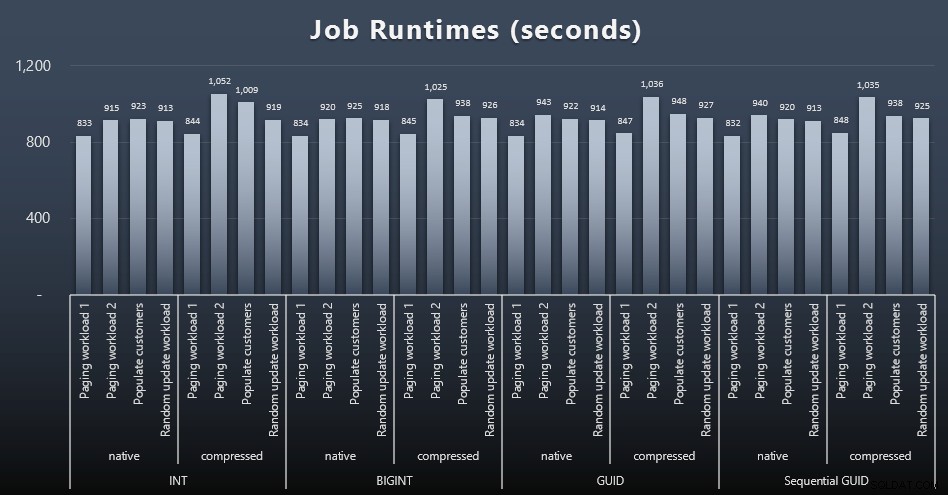
msdb.dbo.sysjobhistorylub ściągnij je z SQL Sentry Event Manager. Oto wyniki (kliknij, aby powiększyć):
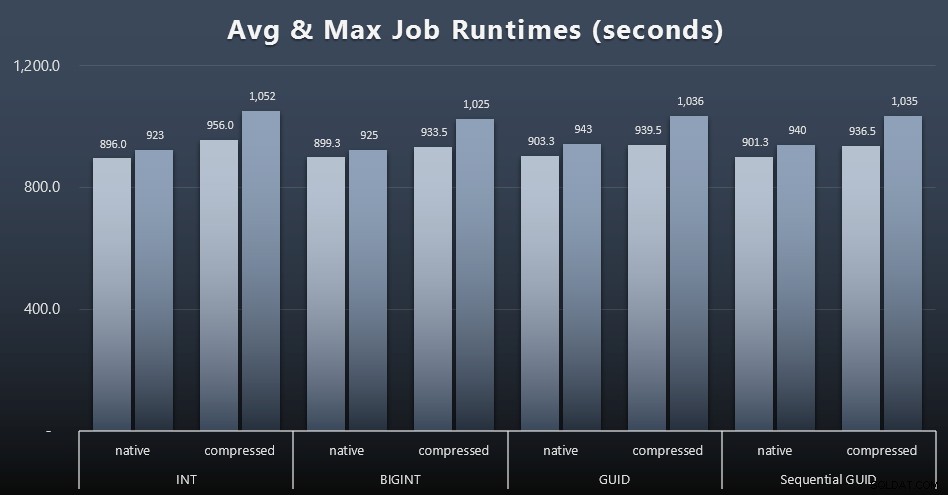
A jeśli chcesz mieć trochę mniej do strawienia, spójrz na średnie i maksymalne czasy pracy w czterech zadaniach (kliknij, aby powiększyć):
Ale nawet na tym drugim wykresie nie ma tak naprawdę wystarczającej wariancji, aby stanowić przekonującą argumentację za lub przeciw któremukolwiek z podejść.
Czasy wykonawcze zapytań
Wziąłem kilka metryk z
sys.dm_exec_query_statsisys.dm_exec_trigger_statsaby określić, jak długo trwały średnio poszczególne zapytania.
Populacja
Pierwsze 200 000 klientów zostało załadowanych dość szybko – w mniej niż 20 sekund – ze względu na brak konkurencyjnych obciążeń. Jednak gdy cztery zadania działały jednocześnie, wystąpił znaczący wpływ na czasy zapisu ze względu na współbieżność. Ukończenie pozostałych 800 000 wierszy wymagało średnio co najmniej o rząd wielkości więcej czasu. Oto wyniki uśrednienia każdego wkładu z 2000 klientów (kliknij, aby powiększyć):
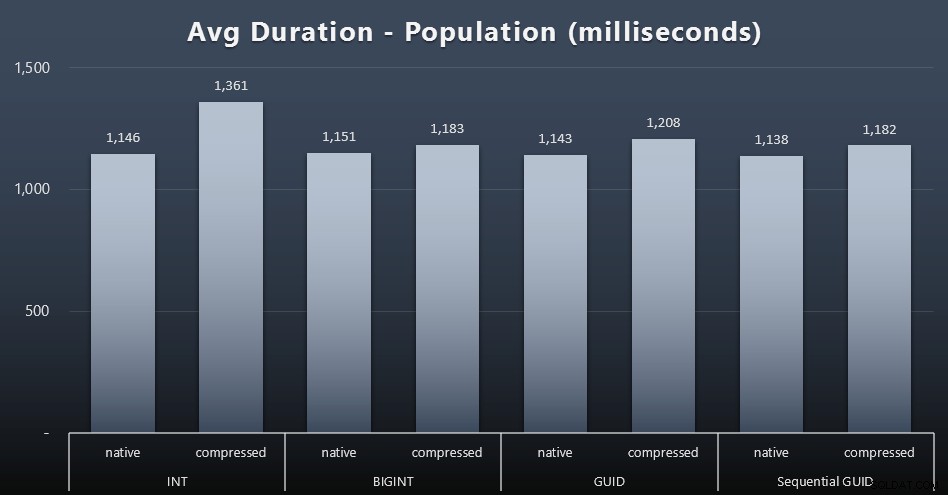
Widzimy tutaj, że kompresja INT była jedyną prawdziwą wartością odstającą – mam kilka teorii na ten temat, ale jeszcze nic nie przekonuje.
Obciążenia stronicowania
Wydaje się, że na średnie czasy wykonywania zapytań stronicowania znacząco wpłynęła współbieżność w porównaniu z moimi testami prowadzonymi w izolacji. Oto wyniki (kliknij, aby powiększyć):
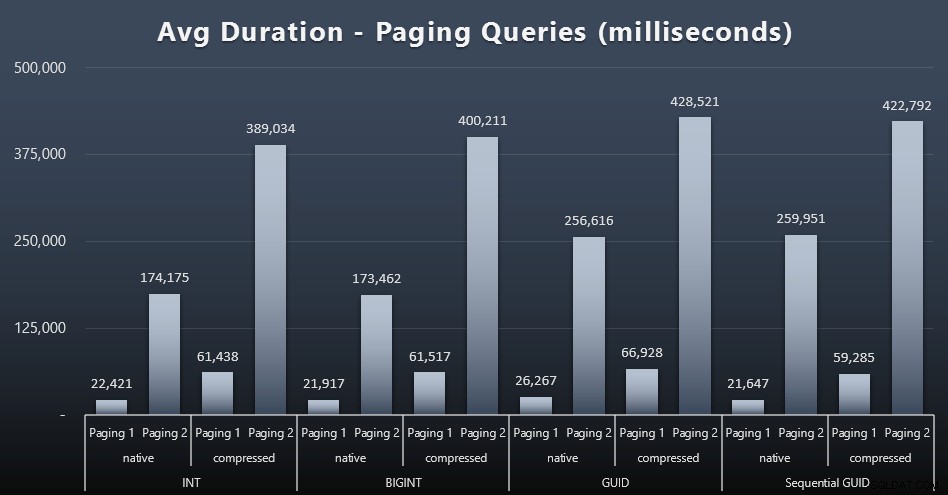
(Paging 1 =zamówienie według ID klienta, Paging 2 =zamówienie według nazwiska, imienia.)
Widzimy, że zarówno w przypadku Stronicowania 1 (kolejność według ID klienta), jak i Stronicowania 2 (kolejność według nazw), istnieje znaczny wpływ na czas działania ze względu na kompresję (do ~700%). Oba identyfikatory GUID wydają się być najwolniejszymi końmi w tym wyścigu, a NEWID() działa najgorzej.
Aktualizuj zadania
Aktualizacje singletona były dość szybkie, nawet przy dużej współbieżności, ale nadal istniały pewne zauważalne różnice spowodowane kompresją, a nawet zaskakujące różnice między typami danych (kliknij, aby powiększyć):
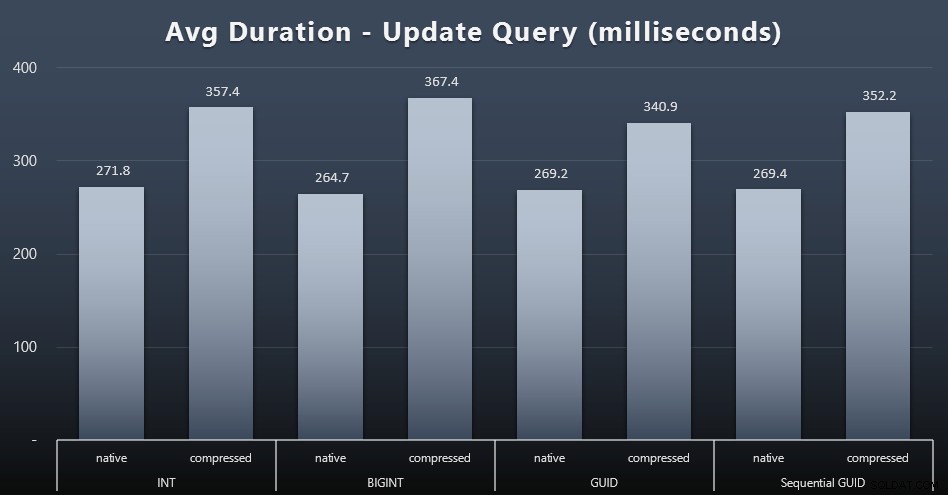
Przede wszystkim aktualizacje wierszy zawierających wartości GUID były w rzeczywistości szybsze niż aktualizacje zawierające INT/BIGINT, gdy była używana kompresja. W przypadku pamięci natywnej różnice były mniej godne uwagi (ale INT nadal był tam przegrany).
Statystyki wyzwalania
Oto średnie i maksymalne czasy działania dla prostego wyzwalacza w każdym przypadku (kliknij, aby powiększyć):
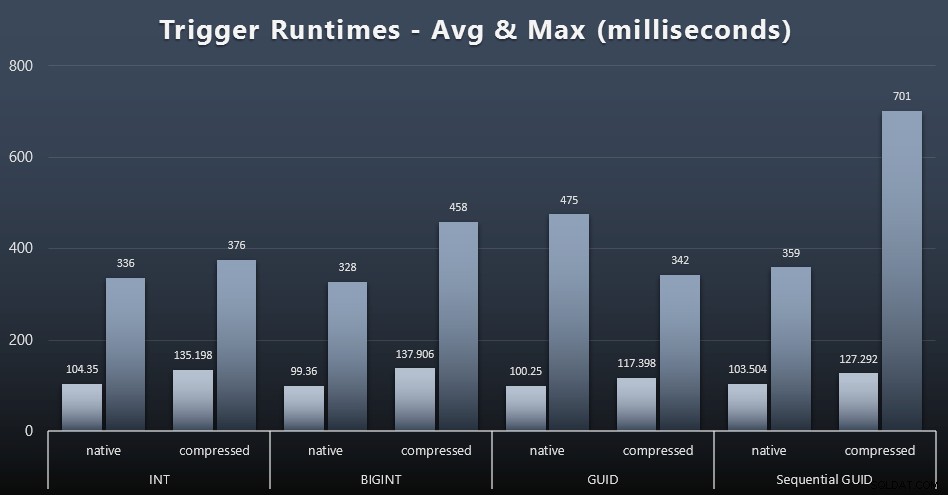
Wydaje się, że kompresja ma tutaj znacznie większy wpływ niż wybór typu danych (chociaż byłoby to prawdopodobnie bardziej widoczne, gdyby część mojego obciążenia aktualizacyjnego zaktualizowała wiele wierszy, zamiast składać się wyłącznie z wyszukiwań jednowierszowych). Maksymalna wartość dla sekwencyjnego identyfikatora GUID jest wyraźnie wartością odstającą, której nie badałem (można stwierdzić, że jest nieistotna na podstawie średniej, która nadal jest zgodna z całą tablicą).
Na co czekały te zapytania?
Po każdym obciążeniu przyjrzałem się również górnym oczekiwaniom w systemie, odrzucając oczywiste oczekiwania w kolejce/czasomierzu (opisane przez Paula Randala) i nieistotne działania oprogramowania monitorującego (takie jak TRACEWRITE ). Oto 3 najlepsze oczekiwania w każdym przypadku (kliknij, aby powiększyć):
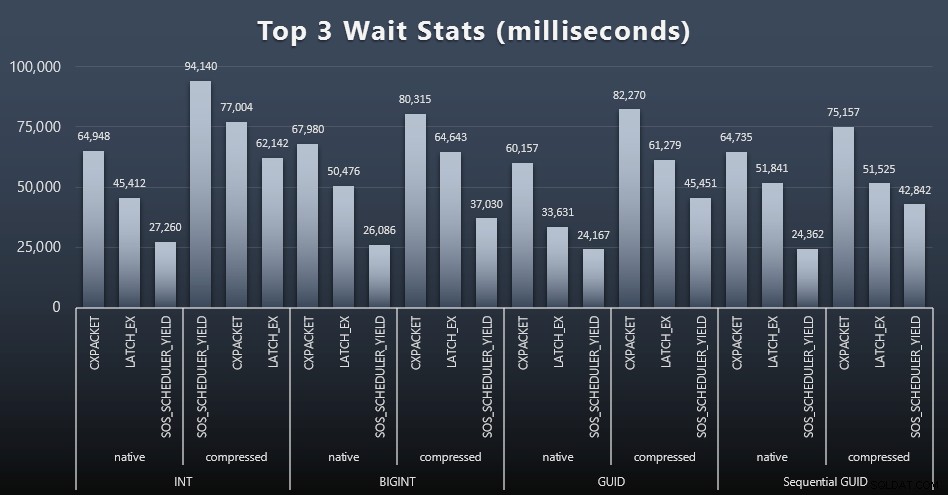
W większości przypadków oczekiwania to CXPACKET, następnie LATCH_EX, a następnie SOS_SCHEDULER_YIELD. W przypadku użycia liczb całkowitych i kompresji przejął jednak SOS_SCHEDULER_YIELD, co sugeruje pewną nieefektywność algorytmu kompresji liczb całkowitych (co może być zupełnie niezwiązane z algorytmem używanym do ściskania BIGINT-ów do INT). Nie badałem tego dalej, ani nie znalazłem uzasadnienia dla śledzenia oczekiwania na pojedyncze zapytanie.
Miejsce na dysku / fragmentacja
Chociaż zwykle zgadzam się, że nie chodzi o miejsce na dysku, nadal jest to metryka, którą warto przedstawić. Nawet w tym bardzo uproszczonym przypadku, w którym istnieje tylko jedna tabela, a klucz nie występuje we wszystkich innych powiązanych tabelach (które z pewnością istniałyby w prawdziwej aplikacji), różnica jest znacząca. Najpierw spójrzmy na reserved kolumna z sp_spaceused (kliknij, aby powiększyć):
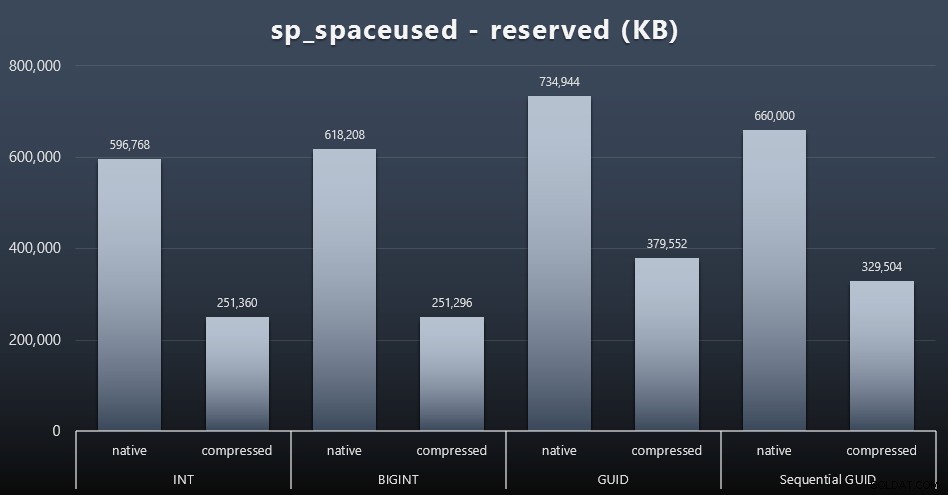
Tutaj BIGINT zajmował tylko trochę więcej miejsca niż INT, a GUID (zgodnie z oczekiwaniami) miał większy skok. Sekwencyjny identyfikator GUID miał mniej znaczący wzrost wykorzystywanej przestrzeni i był skompresowany znacznie lepiej niż tradycyjny identyfikator GUID. Znowu nie ma tu niespodzianek – GUID jest większy niż liczba, kropka. Teraz zwolennicy GUID mogą argumentować, że cena, jaką płacisz w postaci miejsca na dysku, nie jest tak wysoka (18% w porównaniu z BIGINT bez kompresji, około 50% z kompresją). Pamiętaj jednak, że jest to pojedyncza tabela składająca się z 1 miliona wierszy. Wyobraź sobie, jak to ekstrapoluje, gdy masz 10 milionów klientów, a wielu z nich ma 10, 30 lub 500 zamówień – te klucze mogą się powtarzać w tuzinie innych tabel i zajmować tę samą dodatkową przestrzeń w każdym wierszu.
Kiedy spojrzałem na fragmentację po każdym obciążeniu (pamiętaj, że nie jest przeprowadzana żadna konserwacja indeksu) za pomocą tego zapytania:
SELECT index_id, FROM sys.dm_db_index_physical_stats (DB_ID(), OBJECT_ID('dbo.Customers_$use_case$'), -1, 0, 'DETAILED'); Wyniki dały znacznie mniej interesujące wizualizacje; wszystkie indeksy nieklastrowe były podzielone na ponad 99%. Indeksy klastrowe były jednak albo bardzo mocno pofragmentowane, albo wcale nie pofragmentowane (kliknij, aby powiększyć):
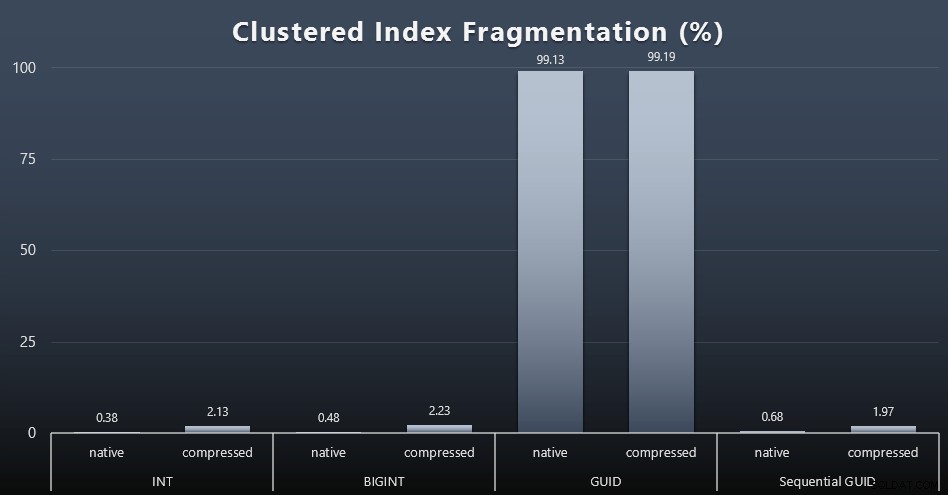
Fragmentacja to kolejna metryka, która często oznacza znacznie mniej, gdy mówimy o dyskach SSD, ale ważne jest, aby pamiętać o tym samym, ponieważ nie wszystkie systemy mogą sobie pozwolić na błogą nieświadomość wpływu, jaki fragmentacja może mieć na wzorce we/wy. Uważam, że przy użyciu niesekwencyjnych identyfikatorów GUID w systemie bardziej związanym z wejściami/wyjściami, wpływ samej tej fragmentacji byłby drastycznie wzmocniony na większość innych metryk w tym teście.
Wykorzystanie puli buforów
W tym miejscu rozsądek co do ilości miejsca na dysku używanego przez Twoje tabele naprawdę się opłaca – im większe są Twoje tabele, tym więcej miejsca zajmują w puli buforów. Przenoszenie danych do i z puli buforów jest kosztowne, i znowu jest to bardzo uproszczony przypadek, w którym testy były prowadzone w izolacji i nie było innych aplikacji i baz danych w instancji rywalizujących o cenną pamięć.
Jest to prosta miara następującego zapytania na końcu każdego obciążenia:
SELECT total_kb FROM sys.dm_os_memory_broker_clerks WHERE clerk_name =N'Pula buforowa';
Wyniki (kliknij, aby powiększyć):
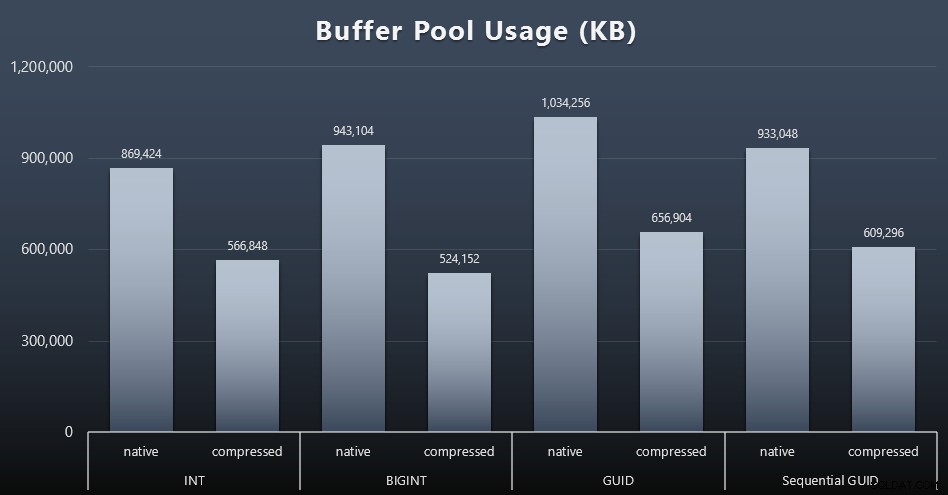
Chociaż większość tego wykresu wcale nie jest zaskakująca – GUID zajmuje więcej miejsca niż BIGINT, BIGINT więcej niż INT – uznałem za interesujące, że sekwencyjny GUID zajmuje mniej miejsca niż BIGINT, nawet bez kompresji. Zrobiłem notatkę, aby przeprowadzić pewne analizy śledcze na poziomie strony, aby określić, jaki rodzaj wydajności ma miejsce tutaj pod okładkami.
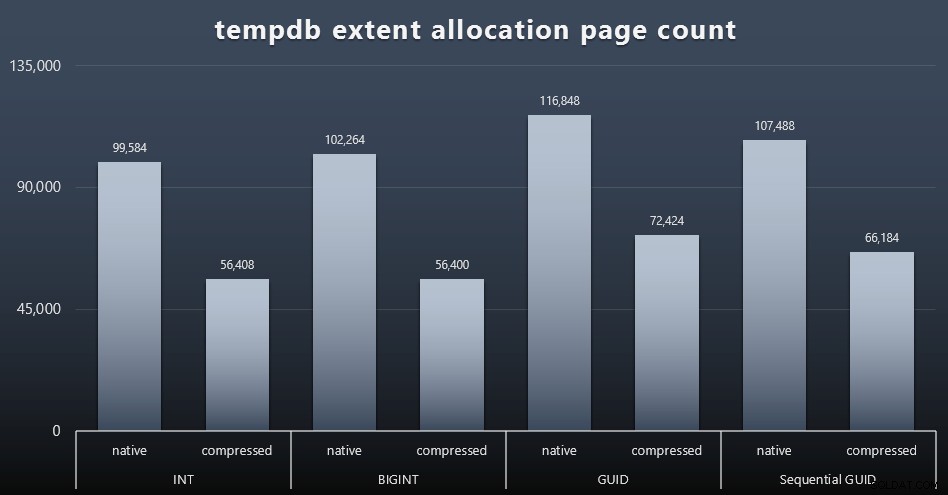
Użycietempdb
Nie jestem pewien, czego się tutaj spodziewałem, ale po każdym obciążeniu zebrałem zawartość trzech DMV dotyczących wykorzystania przestrzeni kosmicznej związanych z tempdb, sys.dm_db_file|session|task_space_usage . Jedynym, który wydawał się wykazywać jakąkolwiek zmienność w oparciu o typ danych, był sys.dm_db_file_space_usage extent_allocation_page_count . To pokazuje, że – przynajmniej w mojej konfiguracji i tym konkretnym obciążeniu – GUID-y przeprowadzą tempdb przez nieco dokładniejszy trening (kliknij, aby powiększyć):
„Złe” podziały stron
Jedną z rzeczy, które chciałem zmierzyć, był wpływ na podziały stron – nie normalne podziały stron (kiedy dodajesz nową stronę), ale kiedy faktycznie musisz przenosić dane między stronami, aby zrobić miejsce na więcej wierszy. Jonathan Kehayias mówi o tym bardziej szczegółowo w swoim poście na blogu „Śledzenie problematycznych podziałów stron w rozszerzonych zdarzeniach programu SQL Server 2012 – naprawdę nie tym razem!”, który stanowi również podstawę sesji rozszerzonych zdarzeń, której użyłem do przechwytywania danych:
UTWÓRZ SESJĘ ZDARZENIA [BadPageSplits] NA SERWERZE DODAJ ZDARZENIE sqlserver.transaction_log (operacja WHERE =11 AND database_id =10) DODAJ DOCELOWY pakiet0.histogram ( SET filtering_event_name ='sqlserver.transaction_log', source_type ='alloc_unit' source =);SESJA WYDARZENIA BRAMKARZA [BadPageSplits] NA STAN SERWERA =START;GO
I zapytanie, którego użyłem do wykreślenia tego:
SELECT t.name, SUM(tab.split_count)FROM ( SELECT n.value('(value)[1]', 'bigint') AS alloc_unit_id, n.value('(@count)[1]' , 'bigint') AS split_count FROM ( SELECT CAST (target_data as XML) target_data FROM sys.dm_xe_sessions AS s INNER JOIN sys.dm_xe_session_targets AS t ON s.address =t.event_session_address WHERE 'tSgetBname 's. ='histogram' ) AS x CROSS APPLY target_data.nodes('HistogramTarget/Slot') as q(n)) AS tabINNER JOIN sys.allocation_units AS au ON tab.alloc_unit_id =au.allocation_unit_idINNER JOIN sys.partitions AS p ON au. container_id =p.partition_idINNER DOŁĄCZ DO sys.tables AS t ON p.object_id =t.[object_id]GROUP BY t.name; A oto wyniki (kliknij, aby powiększyć):
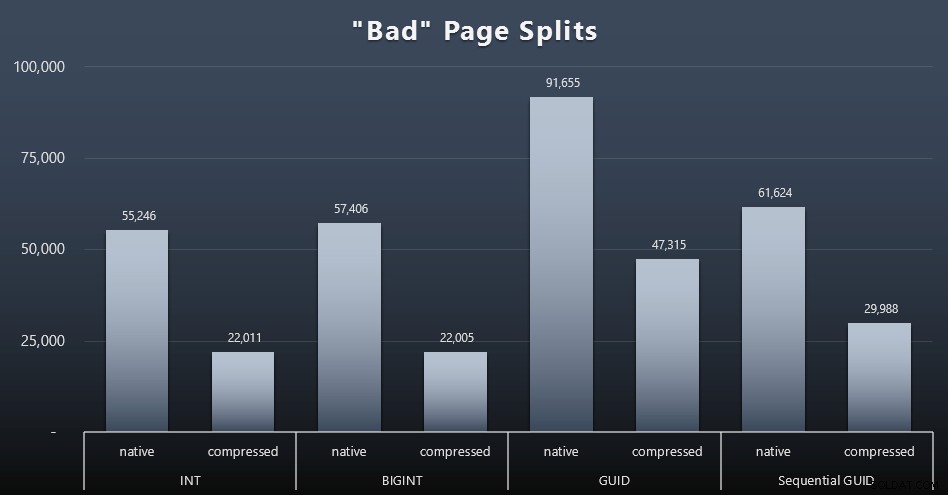
Chociaż zauważyłem już, że w moim scenariuszu (w którym pracuję na szybkich dyskach SSD) niepodważalna różnica w aktywności we/wy nie wpływa bezpośrednio na ogólny czas działania, nadal jest to metryka, którą warto wziąć pod uwagę – szczególnie jeśli nie masz dysków SSD lub jeśli Twoje obciążenie jest już powiązane we/wy.
Wniosek
Chociaż te testy otworzyły mi nieco szerzej oczy na temat tego, jak długofalowe postrzeganie, które miałem, zostało zmienione przez bardziej nowoczesny sprzęt, nadal jestem zagorzałym przeciwnikiem marnowania miejsca na dysku lub w pamięci. Chociaż starałem się zademonstrować równowagę i pozwolić, aby GUID świeciły, z perspektywy wydajności niewiele jest tutaj, aby wspierać przełączanie z INT/BIGINT na dowolną formę UNIQUEIDENTIFIER – chyba że jest to potrzebne z innych mniej namacalnych powodów (takich jak tworzenie klucza w aplikacji lub utrzymywanie unikalnych wartości kluczy w różnych systemach). Krótkie podsumowanie, pokazujące, że NEWID() jest najgorszym wyborem spośród wielu metryk, w których występowała znaczna różnica (w większości przypadków NEWSEQUENTIALID() była na drugim miejscu)):
| Dane | Wyczyścić przegranych? |
|---|---|
| Niekwestionowane wstawki | – remis – |
| Równoczesne obciążenie | – remis – |
| Indywidualne zapytania – populacja | INT (skompresowany) |
| Indywidualne zapytania – stronicowanie | NEWID() / NEWSEQUENTIALID() |
| Indywidualne zapytania – aktualizacja | INT (natywna) / BIGINT (skompresowana) |
| Indywidualne zapytania – PO wyzwalaczu | – remis – |
| Miejsce na dysku | NEWID() |
| Fragmentacja indeksu klastrowego | NEWID() |
| Wykorzystanie puli buforów | NEWID() |
| Użycie tempdb | NEWID() |
| „Złe” podziały stron | NEWID() |
Tabela 2:Najwięksi przegrani
Zachęcamy do samodzielnego przetestowania tych rzeczy; Mogę skompilować mój pełny zestaw skryptów, jeśli chcesz je uruchomić we własnym środowisku. Krótkotrwały cel tego całego postu jest dość prosty:oprócz przewidywalnego wpływu na przestrzeń dyskową należy wziąć pod uwagę wiele ważnych wskaźników, więc nie należy ich używać jako argumentu w obu kierunkach.
Nie chcę, żeby ten sposób myślenia ograniczał się do kluczy per se. Naprawdę należy o tym pomyśleć za każdym razem, gdy dokonuje się wyboru typu danych. Widzę datetime często wybierane, na przykład, gdy tylko date lub smalldatetime jest potrzebne. W przypadku tabel transakcyjnych to również może spowodować wiele zmarnowanego miejsca na dysku, a to sprowadza się również do niektórych innych zasobów.
W przyszłym teście chciałbym porównać wyniki dla znacznie większej tabeli (> 2 miliardy wierszy). Mogę to zasymulować za pomocą INT, ustawiając ziarno tożsamości na -2 miliardy, co pozwala na ~4 miliardy wierszy. Chciałbym, aby porównania obciążenia i miejsca na dysku/śladu pamięci obejmowały więcej niż jedną tabelę, ponieważ jedną z zalet chudego klucza jest to, że jest on reprezentowany w dziesiątkach powiązanych tabel. Monitorowałem zdarzenia autogrowu, ale ich nie było, ponieważ baza danych była wystarczająco duża, aby pomieścić wzrost, i nie myślałem o mierzeniu rzeczywistego użycia dziennika w istniejącym pliku dziennika, więc chciałbym przetestować ponownie z domyślnymi wartościami rozmiaru dziennika i automatycznego wzrostu, tym razem mierząc DBCC SQLPERF(LOGSPACE); . Interesujące byłoby również odbudowanie czasu i pomiar wykorzystania dziennika w wyniku tych operacji. Na koniec chciałbym, aby I/O było bardziej istotnym czynnikiem, znajdując serwer z mechanicznymi dyskami twardymi — wiem, że jest ich wiele, ale w niektórych sklepach jest ich dość rzadko.