Podział na strony jest powszechnym przypadkiem użycia w aplikacjach klienckich i internetowych na całym świecie. Google wyświetla 10 wyników na raz, Twój bank internetowy może wyświetlać 20 rachunków na stronę, a oprogramowanie do śledzenia błędów i kontroli źródła może wyświetlać 50 elementów na ekranie.
Chciałem przyjrzeć się powszechnemu podejściu do stronicowania w SQL Server 2012 – OFFSET / FETCH (standardowy odpowiednik zastrzeżonej klauzuli LIMIT w MySQL) – i zaproponować odmianę, która doprowadzi do bardziej liniowej wydajności stronicowania w całym zestawie, a nie tylko do optymalnej na początku. To niestety wszystko, co przetestuje wiele sklepów.
Co to jest paginacja w SQL Server?
Na podstawie indeksowania tabeli, potrzebnych kolumn i wybranej metody sortowania paginacja może być stosunkowo bezbolesna. Jeśli szukasz „pierwszych” 20 klientów, a indeks klastrowy obsługuje to sortowanie (np. indeks klastrowy w kolumnie IDENTITY lub DateCreated), zapytanie będzie stosunkowo wydajne. Jeśli potrzebujesz obsługiwać sortowanie, które wymaga indeksów nieklastrowanych, a zwłaszcza jeśli masz kolumny potrzebne do danych wyjściowych, które nie są objęte indeksem (nieważne, jeśli nie ma indeksu obsługującego), zapytania mogą stać się droższe. I nawet to samo zapytanie (z innym parametrem @PageNumber) może stać się znacznie droższe, ponieważ @PageNumber staje się wyższy – ponieważ może być wymagane więcej odczytów, aby dostać się do tego „wycinka” danych.
Niektórzy powiedzą, że postęp do końca zestawu jest czymś, co można rozwiązać, rzucając więcej pamięci na problem (aby wyeliminować wszelkie fizyczne operacje we/wy) i/lub używając buforowania na poziomie aplikacji (więc nie będziesz w ogóle bazy danych). Załóżmy na potrzeby tego postu, że więcej pamięci nie zawsze jest możliwe, ponieważ nie każdy klient może dodać pamięć RAM do serwera, na którym brakuje miejsca na pamięć lub nie ma pod jego kontrolą, albo po prostu pstryknąć palcami i mieć gotowe nowsze, większe serwery iść. Zwłaszcza, że niektórzy klienci korzystają z wersji Standard Edition, a więc są ograniczone do 64 GB (SQL Server 2012) lub 128 GB (SQL Server 2014) lub korzystają z jeszcze bardziej limitowanych edycji, takich jak Express (1 GB) lub jednej z wielu ofert w chmurze.
Chciałem więc przyjrzeć się typowemu podejściu do stronicowania w SQL Server 2012 — OFFSET / FETCH — i zasugerować odmianę, która doprowadzi do bardziej liniowej wydajności stronicowania w całym zestawie, zamiast być optymalna tylko na początku. To niestety wszystko, co przetestuje wiele sklepów.
Konfiguracja danych paginacji / Przykład
Pożyczę z innego postu, Złe nawyki :Skupiając się tylko na miejscu na dysku podczas wybierania kluczy, w którym wypełniłem poniższą tabelę 1 000 000 wierszy losowych (ale nie do końca realistycznych) danych klientów:
CREATE TABLE [dbo].[Customers_I] ( [CustomerID] [int] IDENTITY(1,1) NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT ((1)), [Created] [datetime] NOT NULL DEFAULT (sysdatetime()), [Updated] [datetime] NULL, CONSTRAINT [C_PK_Customers_I] PRIMARY KEY CLUSTERED ([CustomerID] ASC) ); GO CREATE NONCLUSTERED INDEX [C_Active_Customers_I] ON [dbo].[Customers_I] ([FirstName] ASC, [LastName] ASC, [EMail] ASC) WHERE ([Active] = 1); GO CREATE UNIQUE NONCLUSTERED INDEX [C_Email_Customers_I] ON [dbo].[Customers_I] ([EMail] ASC); GO CREATE NONCLUSTERED INDEX [C_Name_Customers_I] ON [dbo].[Customers_I] ([LastName] ASC, [FirstName] ASC) INCLUDE ([EMail]); GO
Ponieważ wiedziałem, że będę tutaj testował I/O i będę testował zarówno ciepłą, jak i zimną pamięć podręczną, uczyniłem test przynajmniej trochę bardziej sprawiedliwym, przebudowując wszystkie indeksy, aby zminimalizować fragmentację (co byłoby zrobione mniej zakłócająco, ale regularnie, w większości obciążonych systemów, które wykonują wszelkiego rodzaju konserwację indeksu):
ALTER INDEX ALL ON dbo.Customers_I REBUILD WITH (ONLINE = ON);
Po przebudowie fragmentacja wynosi teraz 0,05% – 0,17% dla wszystkich indeksów (poziom indeksu =0), strony są wypełnione w ponad 99%, a liczba wierszy / liczba stron dla indeksów jest następująca:
| Indeks | Liczba stron | Liczba wierszy |
|---|---|---|
| C_PK_Customers_I (indeks klastrowy) | 19 210 | 1 000 000 |
| C_Email_Customers_I | 7344 | 1 000 000 |
| C_Active_Customers_I (indeks filtrowany) | 13 648 | 815 235 |
| C_Name_Customers_I | 16 824 | 1 000 000 |
Indeksy, liczniki stron, liczniki wierszy
To oczywiście nie jest superszeroki stół i tym razem pominąłem kompresję. Być może zbadam więcej konfiguracji w przyszłym teście.
Jak skutecznie podzielić zapytanie SQL na strony
Koncepcja paginacji – pokazująca użytkownikowi tylko wiersze na raz – jest łatwiejsza do wizualizacji niż wyjaśnienia. Pomyśl o indeksie fizycznej książki, który może zawierać wiele stron odniesień do punktów w książce, ale uporządkowanych alfabetycznie. Dla uproszczenia załóżmy, że na każdej stronie indeksu mieści się dziesięć pozycji. To może wyglądać tak:
Teraz, jeśli przeczytałem już strony 1 i 2 indeksu, wiem, że aby dostać się na stronę 3, muszę pominąć 2 strony. Ale ponieważ wiem, że na każdej stronie jest 10 pozycji, mogę myśleć o tym jako o pominięciu 2 x 10 pozycji i rozpoczęciu od 21. pozycji. Lub, ujmując to inaczej, muszę pominąć pierwsze (10*(3-1)) pozycje. Aby uczynić to bardziej ogólnym, mogę powiedzieć, że aby zacząć od strony n, muszę pominąć pierwsze (10 * (n-1)) elementy. Aby dostać się na pierwszą stronę, pomijam 10*(1-1) pozycji, aby kończyć się na pozycji 1. Aby dostać się na drugą stronę, pomijam 10*(2-1) pozycji, aby kończyć się na pozycji 11. I tak wł.
Mając te informacje, użytkownicy będą formułować zapytanie stronicowania takie jak to, biorąc pod uwagę, że klauzule OFFSET / FETCH dodane w SQL Server 2012 zostały specjalnie zaprojektowane tak, aby pominąć tak wiele wierszy:
SELECT [a_bunch_of_columns] FROM dbo.[some_table] ORDER BY [some_column_or_columns] OFFSET @PageSize * (@PageNumber - 1) ROWS FETCH NEXT @PageSize ROWS ONLY;
Jak wspomniałem powyżej, działa to dobrze, jeśli istnieje indeks, który obsługuje ORDER BY i obejmuje wszystkie kolumny w klauzuli SELECT (oraz, w przypadku bardziej złożonych zapytań, klauzule WHERE i JOIN). Jednak koszty sortowania mogą być przytłaczające bez żadnego indeksu pomocniczego, a jeśli kolumny wyjściowe nie zostaną uwzględnione, albo skończysz z całą gamą wyszukiwań kluczy, albo możesz nawet uzyskać skan tabeli w niektórych scenariuszach.
Najlepsze praktyki dotyczące sortowania paginacji SQL
Biorąc pod uwagę powyższą tabelę i indeksy, chciałem przetestować te scenariusze, w których chcemy wyświetlić 100 wierszy na stronie i wyświetlić wszystkie kolumny w tabeli:
- Domyślne –
ORDER BY CustomerID(indeks klastrowy). Jest to najwygodniejsza kolejność dla osób zajmujących się bazą danych, ponieważ nie wymaga dodatkowego sortowania i zawiera wszystkie dane z tej tabeli, które mogą być potrzebne do wyświetlenia. Z drugiej strony może to nie być najbardziej wydajny indeks do użycia, jeśli wyświetlasz podzbiór tabeli. Zamówienie może również nie mieć sensu dla użytkowników końcowych, zwłaszcza jeśli CustomerID jest identyfikatorem zastępczym bez zewnętrznego znaczenia. - Książka telefoniczna –
ORDER BY LastName, FirstName(obsługujący indeks nieklastrowy). Jest to najbardziej intuicyjne porządkowanie dla użytkowników, ale wymagałoby indeksu nieklastrowego do obsługi zarówno sortowania, jak i pokrycia. Bez indeksu pomocniczego cała tabela musiałaby zostać zeskanowana. - Zdefiniowane przez użytkownika –
ORDER BY FirstName DESC, EMail(brak indeksu pomocniczego). Reprezentuje to możliwość wyboru przez użytkownika dowolnej kolejności sortowania, o czym ostrzega Michael J. Swart w „Wzorach projektowych interfejsu użytkownika, które nie są skalowane”.
Chciałem przetestować te metody i porównać plany i metryki, gdy – zarówno w scenariuszach z ciepłą i zimną pamięcią podręczną – patrząc na stronę 1, stronę 500, stronę 5000 i stronę 9999. Stworzyłem te procedury (różniące się tylko klauzulą ORDER BY):
CREATE PROCEDURE dbo.Pagination_Test_1 -- ORDER BY CustomerID
@PageNumber INT = 1,
@PageSize INT = 100
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerID, FirstName, LastName,
EMail, Active, Created, Updated
FROM dbo.Customers_I
ORDER BY CustomerID
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.Pagination_Test_2 -- ORDER BY LastName, FirstName
CREATE PROCEDURE dbo.Pagination_Test_3 -- ORDER BY FirstName DESC, EMail W rzeczywistości prawdopodobnie będziesz mieć tylko jedną procedurę, która używa dynamicznego SQL (jak w moim przykładzie „zlewu kuchennego”) lub wyrażenia CASE do dyktowania kolejności.
W obu przypadkach najlepsze wyniki można uzyskać, używając opcji OPCJA (RECOMPILE) w zapytaniu, aby uniknąć ponownego użycia planów, które są optymalne dla jednej opcji sortowania, ale nie dla wszystkich. Stworzyłem tutaj osobne procedury, aby usunąć te zmienne; Dodałem OPTION (RECOMPILE), aby te testy trzymały się z dala od wąchania parametrów i innych problemów z optymalizacją bez wielokrotnego opróżniania pamięci podręcznej całego planu.
Alternatywne podejście do stronicowania SQL Server dla lepszej wydajności
Nieco innym podejściem, którego nie widzę zbyt często wdrożonego, jest zlokalizowanie „strony”, na której się znajdujemy, używając tylko klucza klastrowania, a następnie dołączenie do niego:
;WITH pg AS ( SELECT [key_column] FROM dbo.[some_table] ORDER BY [some_column_or_columns] OFFSET @PageSize * (@PageNumber - 1) ROWS FETCH NEXT @PageSize ROWS ONLY ) SELECT t.[bunch_of_columns] FROM dbo.[some_table] AS t INNER JOIN pg ON t.[key_column] = pg.[key_column] -- or EXISTS ORDER BY [some_column_or_columns];
Jest to oczywiście bardziej szczegółowy kod, ale miejmy nadzieję, że jasne jest, do czego można zmusić SQL Server:unikanie skanowania lub przynajmniej odkładanie wyszukiwania do czasu, gdy znacznie mniejszy zestaw wyników zostanie zmniejszony. Paul White (@SQL_Kiwi) zbadał podobne podejście w 2010 roku, zanim OFFSET/FETCH został wprowadzony we wczesnych wersjach beta SQL Server 2012 (po raz pierwszy pisałem o tym na blogu później w tym samym roku).
Biorąc pod uwagę powyższe scenariusze, stworzyłem jeszcze trzy procedury, z jedyną różnicą między kolumnami określonymi w klauzulach ORDER BY (potrzebujemy teraz dwóch, jednej dla samej strony i jednej dla uporządkowania wyniku):
CREATE PROCEDURE dbo.Alternate_Test_1 -- ORDER BY CustomerID
@PageNumber INT = 1,
@PageSize INT = 100
AS
BEGIN
SET NOCOUNT ON;
;WITH pg AS
(
SELECT CustomerID
FROM dbo.Customers_I
ORDER BY CustomerID
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
SELECT c.CustomerID, c.FirstName, c.LastName,
c.EMail, c.Active, c.Created, c.Updated
FROM dbo.Customers_I AS c
WHERE EXISTS (SELECT 1 FROM pg WHERE pg.CustomerID = c.CustomerID)
ORDER BY c.CustomerID OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.Alternate_Test_2 -- ORDER BY LastName, FirstName
CREATE PROCEDURE dbo.Alternate_Test_3 -- ORDER BY FirstName DESC, EMail Uwaga:To może nie działać tak dobrze, jeśli klucz podstawowy nie jest klastrowany – część sztuczki, która sprawia, że działa to lepiej, gdy można użyć indeksu pomocniczego, jest to, że klucz klastrowania jest już w indeksie, więc wyszukiwanie jest często unikane.
Testowanie sortowania kluczy klastrowania
Najpierw przetestowałem przypadek, w którym nie spodziewałem się dużej rozbieżności między dwiema metodami – sortowanie według klucza grupowania. Uruchomiłem te instrukcje wsadowo w SQL Sentry Plan Explorer i obserwowałem czas trwania, odczyty i plany graficzne, upewniając się, że każde zapytanie zaczynało się od całkowicie zimnej pamięci podręcznej:
SET NOCOUNT ON; -- default method DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 1; DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 500; DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 5000; DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 9999; -- alternate method DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 1; DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 500; DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 5000; DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 9999;
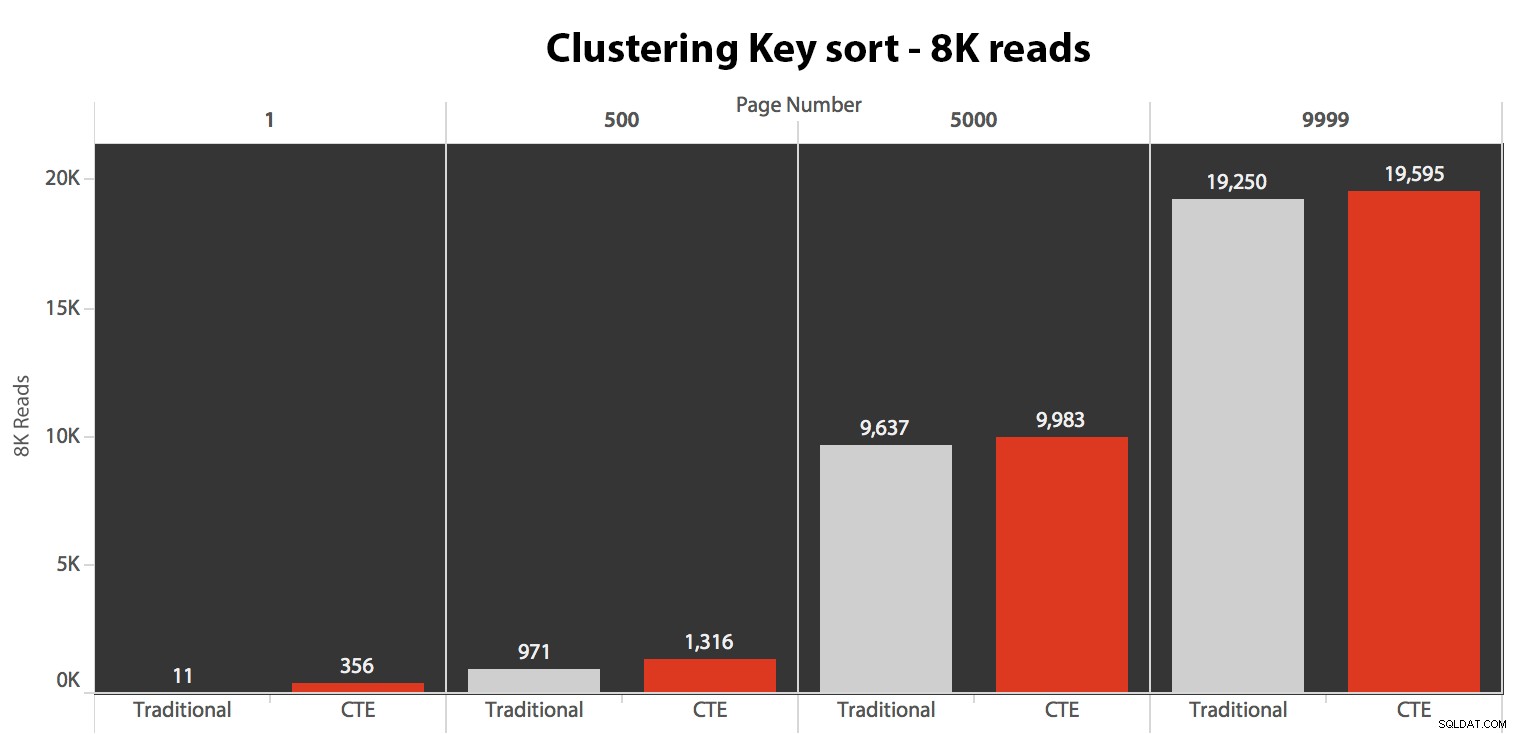
Wyniki tutaj nie były zdumiewające. W przypadku ponad 5 wykonań pokazano tutaj średnią liczbę odczytów, pokazując nieistotne różnice między dwoma zapytaniami, dla wszystkich numerów stron, przy sortowaniu według klucza klastrowania:
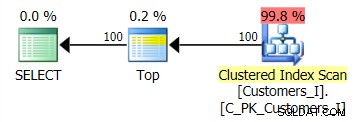
Plan dla metody domyślnej (jak pokazano w Eksploratorze planów) we wszystkich przypadkach był następujący:
Chociaż plan metody opartej na CTE wyglądał tak:
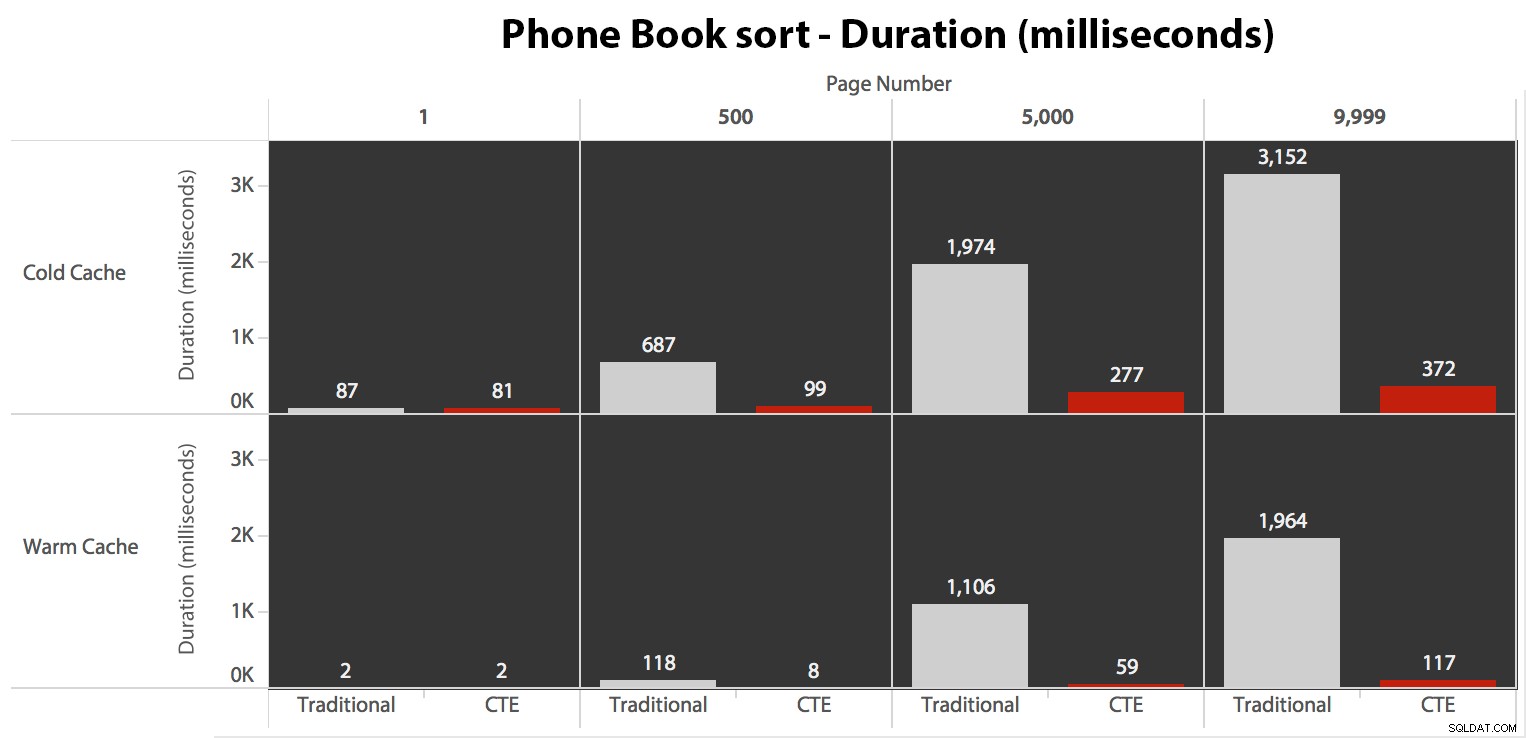
Teraz, podczas gdy operacje we/wy były takie same, niezależnie od buforowania (tylko znacznie więcej odczytów z wyprzedzeniem w scenariuszu z zimną pamięcią podręczną), zmierzyłem czas trwania z zimną pamięcią podręczną, a także z ciepłą pamięcią podręczną (gdzie skomentowałem polecenia DROPCLEANBUFFERS i wielokrotnie uruchamiał zapytania przed pomiarem). Te czasy trwania wyglądały tak:
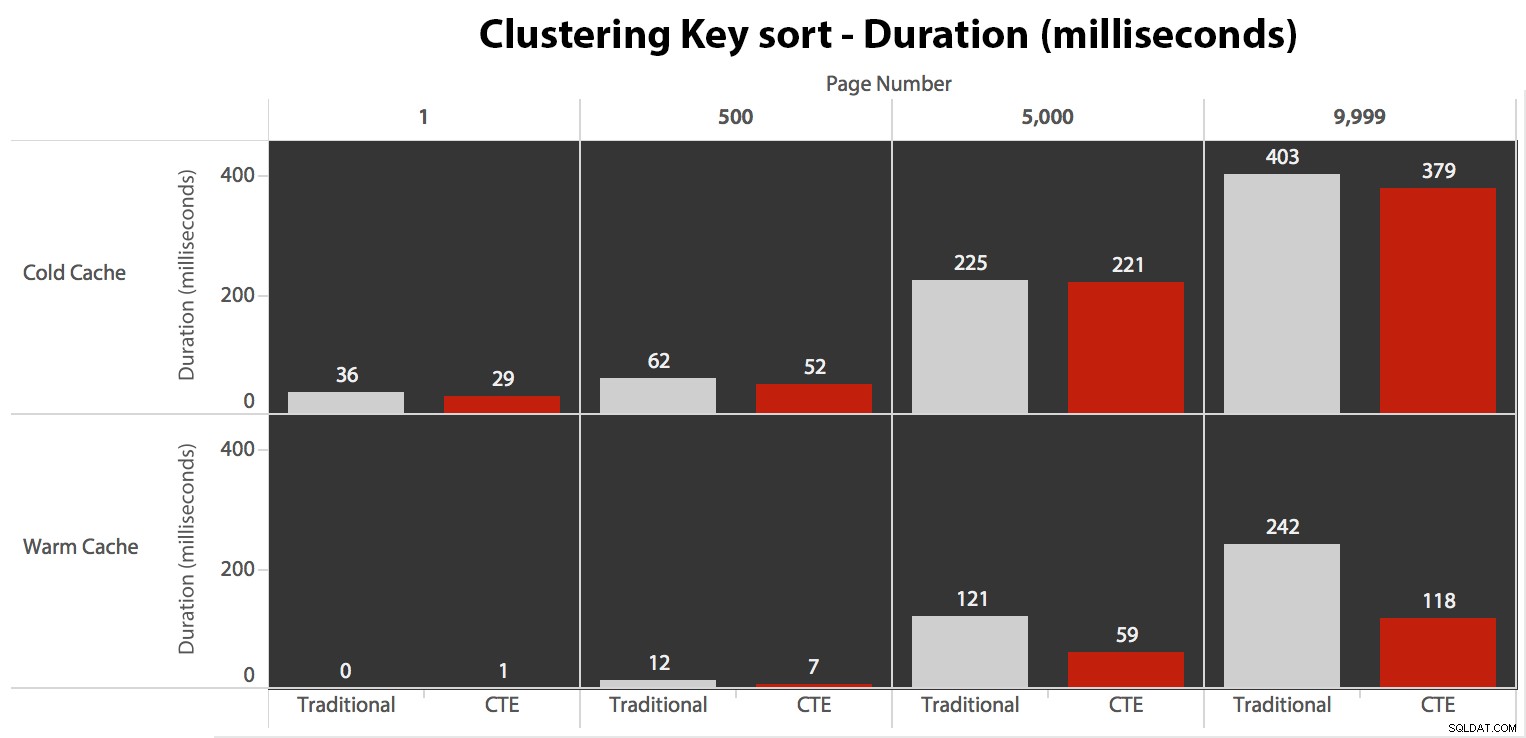
Chociaż możesz zobaczyć wzór, który pokazuje, że czas trwania rośnie wraz ze wzrostem numeru strony, pamiętaj o skali:aby trafić w wiersze 999 801 -> 999 900, mówimy o pół sekundy w najgorszym przypadku i 118 milisekundach w najlepszym przypadku. Podejście CTE wygrywa, ale nie za dużo.
Testowanie sortowania książki telefonicznej
Następnie przetestowałem drugi przypadek, w którym sortowanie było obsługiwane przez nieobejmujący indeks na LastName, FirstName. Powyższe zapytanie właśnie zmieniło wszystkie wystąpienia Test_1 do Test_2 . Oto odczyty przy użyciu zimnej pamięci podręcznej:
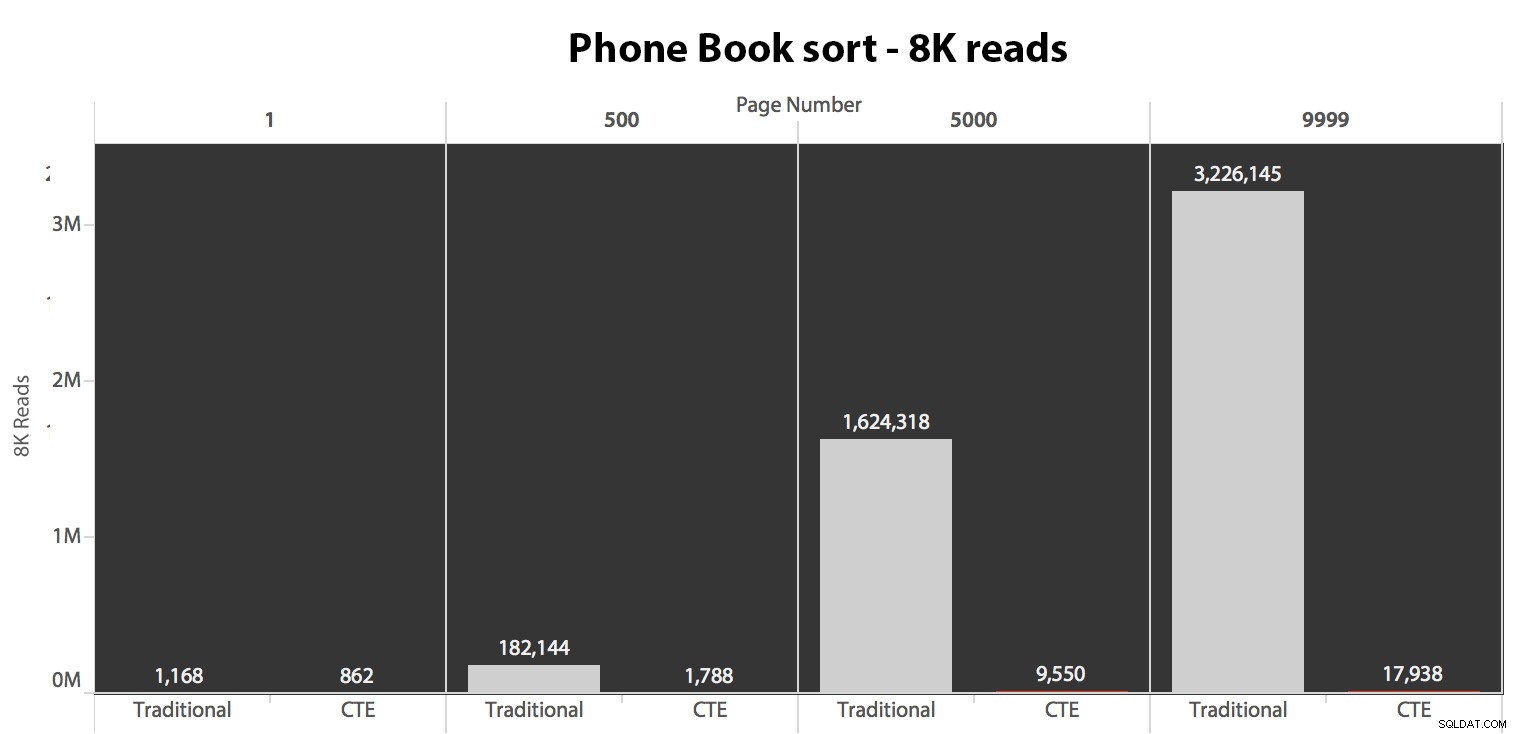
(Odczyty w ciepłej pamięci podręcznej przebiegały według tego samego wzoru – rzeczywiste liczby różniły się nieznacznie, ale nie na tyle, aby uzasadnić oddzielny wykres.)
Kiedy nie używamy indeksu klastrowego do sortowania, jasne jest, że koszty we/wy związane z tradycyjną metodą OFFSET/FETCH są znacznie gorsze niż w przypadku pierwszej identyfikacji kluczy w CTE i pobrania pozostałych kolumn tylko dla tego podzbioru.
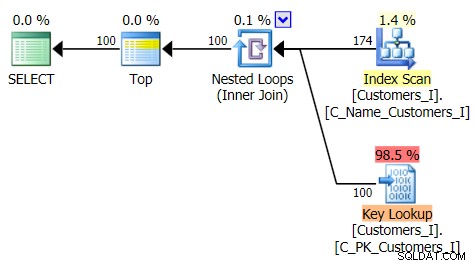
Oto plan tradycyjnego podejścia do zapytań:
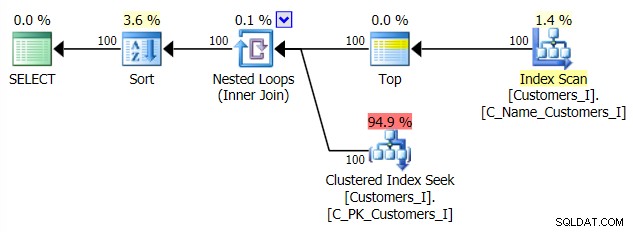
I plan mojego alternatywnego podejścia do CTE:
Wreszcie, czasy trwania:
Tradycyjne podejście pokazuje wyraźny wzrost czasu trwania w miarę zbliżania się do końca paginacji. Podejście CTE również pokazuje nieliniowy wzór, ale jest znacznie mniej wyraźny i zapewnia lepszy czas przy każdym numerze strony. Widzimy 117 milisekund na przedostatnią stronę, w porównaniu z tradycyjnym podejściem, które trwa prawie dwie sekundy.
Testowanie sortowania zdefiniowanego przez użytkownika
Wreszcie zmieniłem zapytanie, aby używało Test_3 procedury składowane, testujące przypadek, w którym sortowanie zostało zdefiniowane przez użytkownika i nie miało indeksu pomocniczego. We/wy były spójne w każdym zestawie testów; wykres jest tak nieciekawy, że po prostu podlinkuję do niego. Krótko mówiąc:we wszystkich testach było nieco ponad 19 000 odczytów. Powodem jest to, że każda odmiana musiała wykonać pełne skanowanie ze względu na brak indeksu wspierającego kolejność. Oto plan tradycyjnego podejścia:
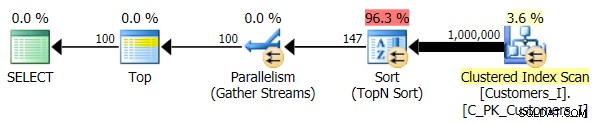
I chociaż plan zapytania w wersji CTE wygląda niepokojąco bardziej skomplikowanie…
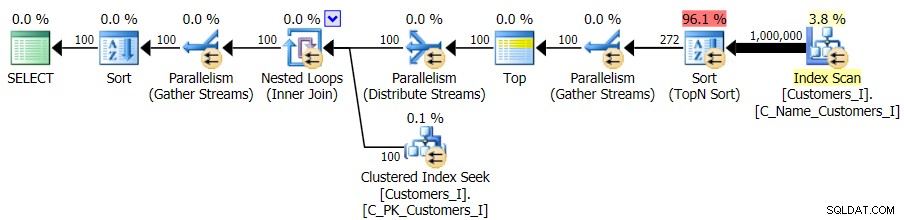
… prowadzi to do skrócenia czasu trwania we wszystkich przypadkach z wyjątkiem jednego. Oto czasy trwania:
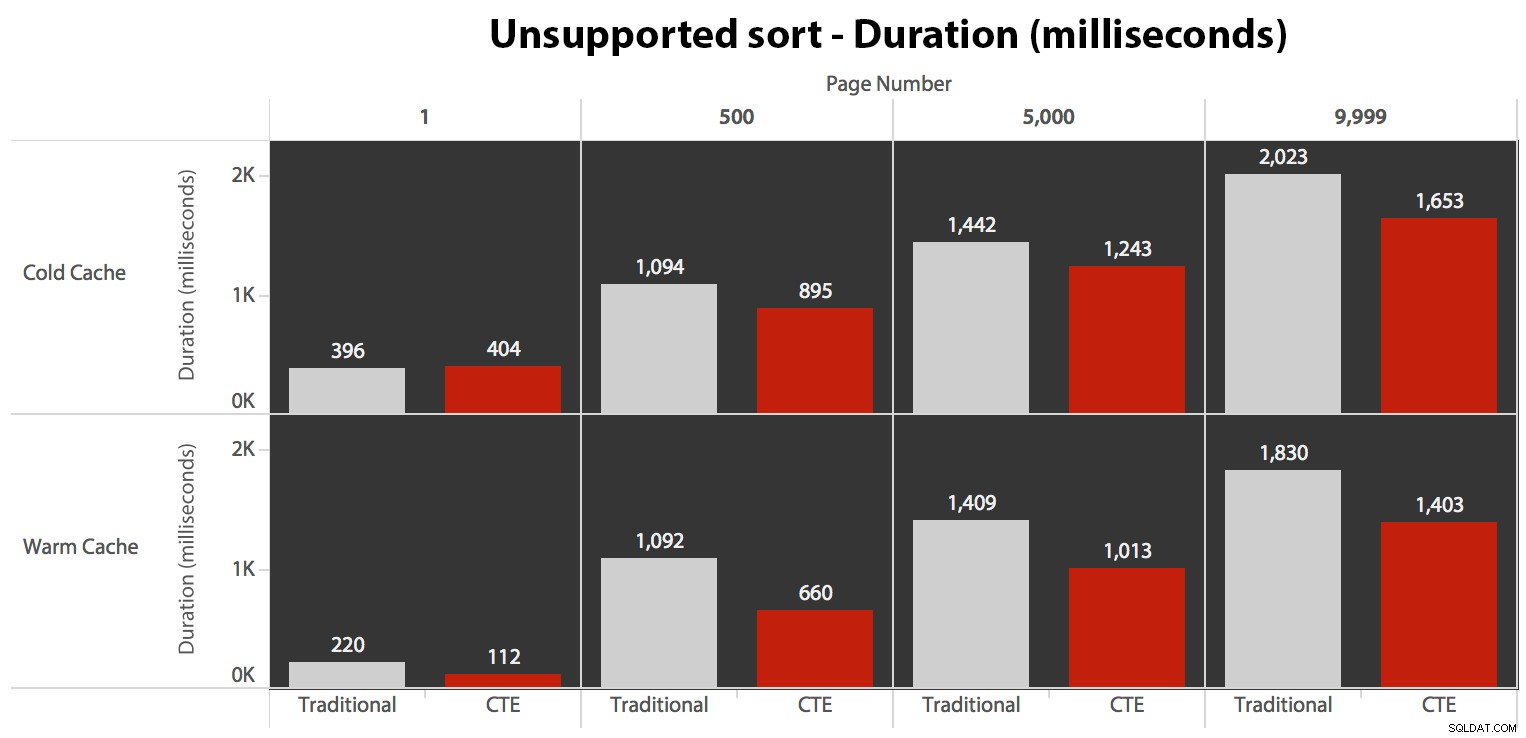
Widać, że nie możemy tutaj uzyskać liniowej wydajności przy użyciu żadnej z metod, ale CTE wychodzi na górę z dobrym marginesem (od 16% do 65% lepiej) w każdym pojedynczym przypadku, z wyjątkiem zapytania zimnej pamięci podręcznej względem pierwszego strona (gdzie straciła aż o 8 milisekund). Warto również zauważyć, że tradycyjnej metodzie w ogóle nie pomaga ciepła pamięć podręczna w „środku” (strony 500 i 5000); dopiero pod koniec zestawu warto wspomnieć o jakiejkolwiek efektywności.
Większa głośność
Po indywidualnym przetestowaniu kilku wykonań i obliczeniu średnich, pomyślałem, że sensowne byłoby również przetestowanie dużej liczby transakcji, które w pewnym stopniu symulowałyby rzeczywisty ruch w zajętym systemie. Utworzyłem więc zadanie z 6 krokami, po jednym dla każdej kombinacji metody zapytania (tradycyjne stronicowanie vs. CTE) i typu sortowania (klucz grupowania, książka telefoniczna i nieobsługiwane), ze 100-stopniową sekwencją trafienia na cztery numery stron powyżej , 10 razy każdy i 60 innych numerów stron wybranych losowo (ale takie same dla każdego kroku). Oto jak wygenerowałem skrypt tworzenia pracy:
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX), @job SYSNAME = N'Paging Test', @step SYSNAME, @command NVARCHAR(MAX);
;WITH t10 AS (SELECT TOP (10) number FROM master.dbo.spt_values),
f AS (SELECT f FROM (VALUES(1),(500),(5000),(9999)) AS f(f))
SELECT @sql = STUFF((SELECT CHAR(13) + CHAR(10)
+ N'EXEC dbo.$p$_Test_$v$ @PageNumber = ' + RTRIM(f) + ';'
FROM
(
SELECT f FROM
(
SELECT f.f FROM t10 CROSS JOIN f
UNION ALL
SELECT TOP (60) f = ABS(CHECKSUM(NEWID())) % 10000
FROM sys.all_objects
) AS x
) AS y ORDER BY NEWID()
FOR XML PATH(''),TYPE).value(N'.[1]','nvarchar(max)'),1,0,'');
IF EXISTS (SELECT 1 FROM msdb.dbo.sysjobs WHERE name = @job)
BEGIN
EXEC msdb.dbo.sp_delete_job @job_name = @job;
END
EXEC msdb.dbo.sp_add_job
@job_name = @job,
@enabled = 0,
@notify_level_eventlog = 0,
@category_id = 0,
@owner_login_name = N'sa';
EXEC msdb.dbo.sp_add_jobserver
@job_name = @job,
@server_name = N'(local)';
DECLARE c CURSOR LOCAL FAST_FORWARD FOR
SELECT step = p.p + '_' + v.v,
command = REPLACE(REPLACE(@sql, N'$p$', p.p), N'$v$', v.v)
FROM
(SELECT v FROM (VALUES('1'),('2'),('3')) AS v(v)) AS v
CROSS JOIN
(SELECT p FROM (VALUES('Alternate'),('Pagination')) AS p(p)) AS p
ORDER BY p.p, v.v;
OPEN c; FETCH c INTO @step, @command;
WHILE @@FETCH_STATUS <> -1
BEGIN
EXEC msdb.dbo.sp_add_jobstep
@job_name = @job,
@step_name = @step,
@command = @command,
@database_name = N'IDs',
@on_success_action = 3;
FETCH c INTO @step, @command;
END
EXEC msdb.dbo.sp_update_jobstep
@job_name = @job,
@step_id = 6,
@on_success_action = 1; -- quit with success
PRINT N'EXEC msdb.dbo.sp_start_job @job_name = ''' + @job + ''';'; Oto wynikowa lista kroków zadania i jedna z właściwości kroku:
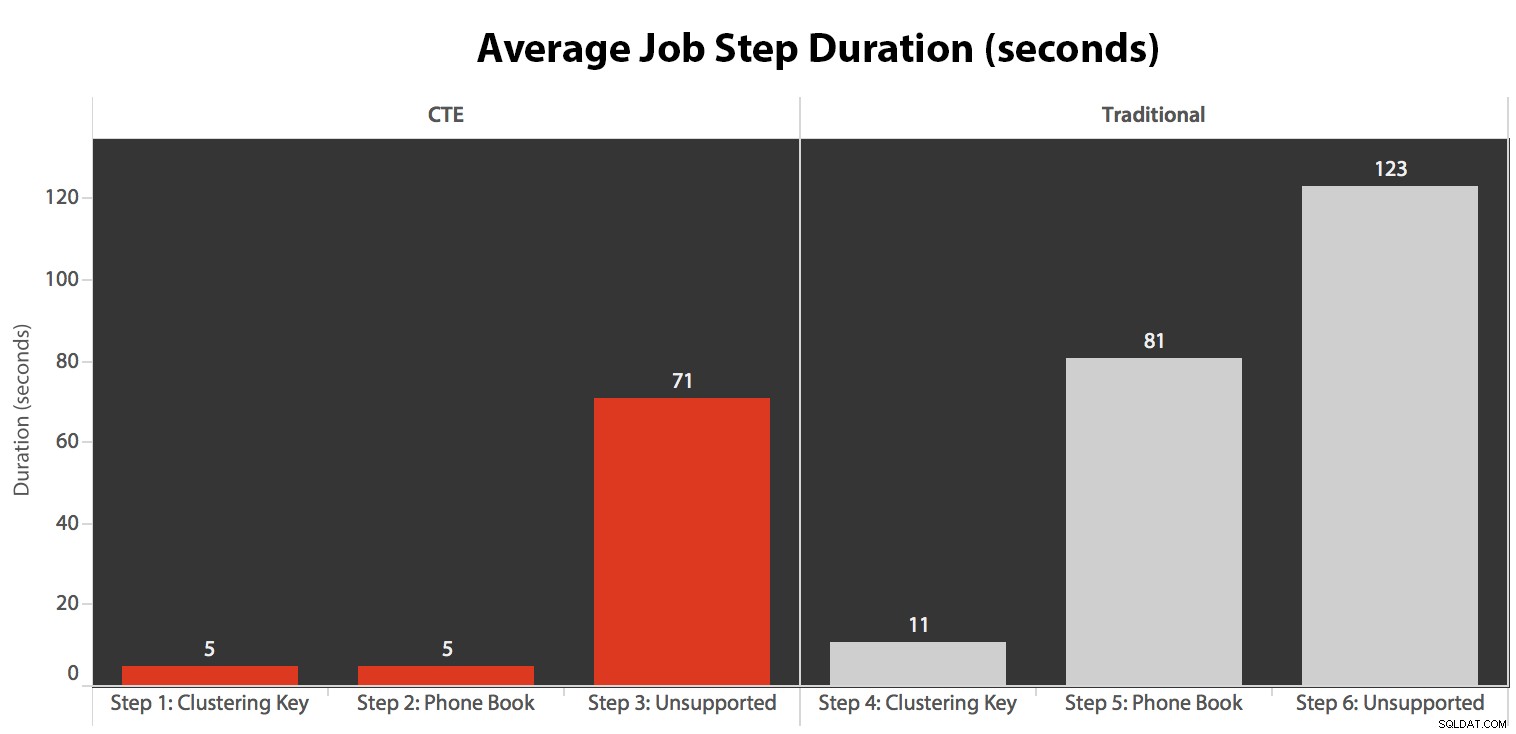
Uruchomiłem zadanie pięć razy, a następnie przejrzałem historię zadań i oto średnie czasy wykonywania każdego kroku:
Skorelowałem również jedno z wykonań w kalendarzu SQL Sentry Event Manager…
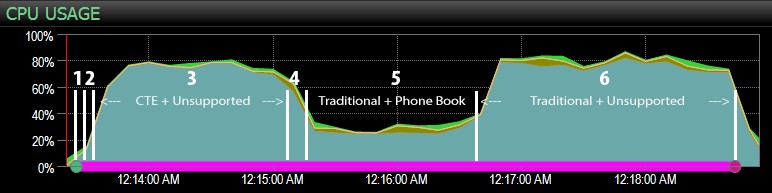
…z pulpitem nawigacyjnym SQL Sentry i ręcznie oznaczanym z grubsza miejscem przebiegu każdego z sześciu kroków. Oto wykres wykorzystania procesora po stronie pulpitu Windows:
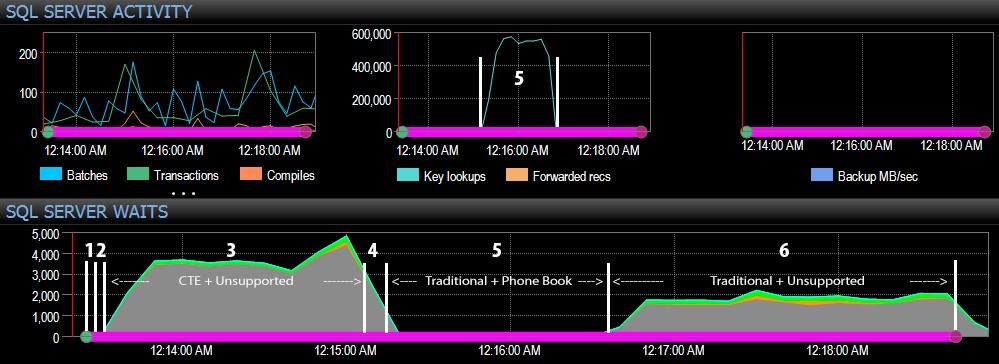
Natomiast po stronie pulpitu nawigacyjnego SQL Server interesujące metryki znajdowały się na wykresach Wyszukiwania kluczy i Oczekiwania:
Najciekawsze obserwacje tylko z czysto wizualnej perspektywy:
- CPU jest dość gorący, około 80%, podczas kroku 3 (CTE + brak indeksu wspierającego) i kroku 6 (tradycyjny + brak indeksu wspierającego);
- Czasy oczekiwania CXPACKET są stosunkowo wysokie podczas kroku 3 i w mniejszym stopniu podczas kroku 6;
- możesz zobaczyć ogromny skok w wyszukiwaniu kluczy, do prawie 600 000, w ciągu około jednej minuty (co odpowiada krokowi 5 – tradycyjne podejście z indeksem w stylu książki telefonicznej).
W przyszłym teście – podobnie jak w moim poprzednim poście na temat identyfikatorów GUID – chciałbym przetestować to w systemie, w którym dane nie mieszczą się w pamięci (łatwe do symulacji) i gdzie dyski są wolne (nie tak łatwe do symulacji) , ponieważ niektóre z tych wyników prawdopodobnie korzystają z rzeczy, których nie ma każdy system produkcyjny – szybkich dysków i wystarczającej ilości pamięci RAM. Powinienem również rozszerzyć testy, aby uwzględnić więcej odmian (używając wąskich i szerokich kolumn, wąskich i szerokich indeksów, indeksu książki telefonicznej, który faktycznie obejmuje wszystkie kolumny wyjściowe oraz sortowanie w obu kierunkach). Pełzanie zakresu zdecydowanie ograniczyło zakres moich testów dla tego pierwszego zestawu testów.
Jak poprawić stronicowanie SQL Server
Paginacja nie zawsze musi być bolesna; SQL Server 2012 z pewnością sprawia, że składnia jest łatwiejsza, ale jeśli po prostu podłączysz natywną składnię, nie zawsze zobaczysz duże korzyści. Tutaj pokazałem, że nieco bardziej szczegółowa składnia przy użyciu CTE może prowadzić do znacznie lepszej wydajności w najlepszym przypadku i prawdopodobnie pomijalnych różnic w wydajności w najgorszym przypadku. Oddzielając lokalizację danych od pobierania danych na dwa różne etapy, możemy zobaczyć ogromną korzyść w niektórych scenariuszach, poza wyższymi oczekiwaniami CXPACKET w jednym przypadku (a nawet wtedy zapytania równoległe kończyły się szybciej niż inne zapytania wyświetlające niewiele lub wcale, więc prawdopodobnie nie będą „złymi” CXPACKET, przed którymi wszyscy ostrzegają).
Mimo to, nawet szybsza metoda jest powolna, gdy nie ma indeksu pomocniczego. Chociaż możesz pokusić się o zaimplementowanie indeksu dla każdego możliwego algorytmu sortowania, jaki może wybrać użytkownik, możesz rozważyć zapewnienie mniejszej liczby opcji (ponieważ wszyscy wiemy, że indeksy nie są bezpłatne). Na przykład, czy Twoja aplikacja bezwzględnie musi obsługiwać sortowanie według LastName rosnąco *i* LastName malejąco? Jeśli chcą przejść bezpośrednio do klientów, których nazwiska zaczynają się na Z, czy nie mogą przejść do *ostatniej* strony i cofnąć się? To bardziej decyzja biznesowa i dotycząca użyteczności niż techniczna, po prostu zachowaj ją jako opcję przed umieszczeniem indeksów w każdej kolumnie sortowania w obu kierunkach, aby uzyskać najlepszą wydajność nawet dla najbardziej niejasnych opcji sortowania.